Recognition: unknown
TRIAGE: Evaluating Prospective Metacognitive Control in LLMs under Resource Constraints
Pith reviewed 2026-05-14 19:24 UTC · model grok-4.3
The pith
Language models lack the ability to prospectively plan task selection and compute allocation under fixed token budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
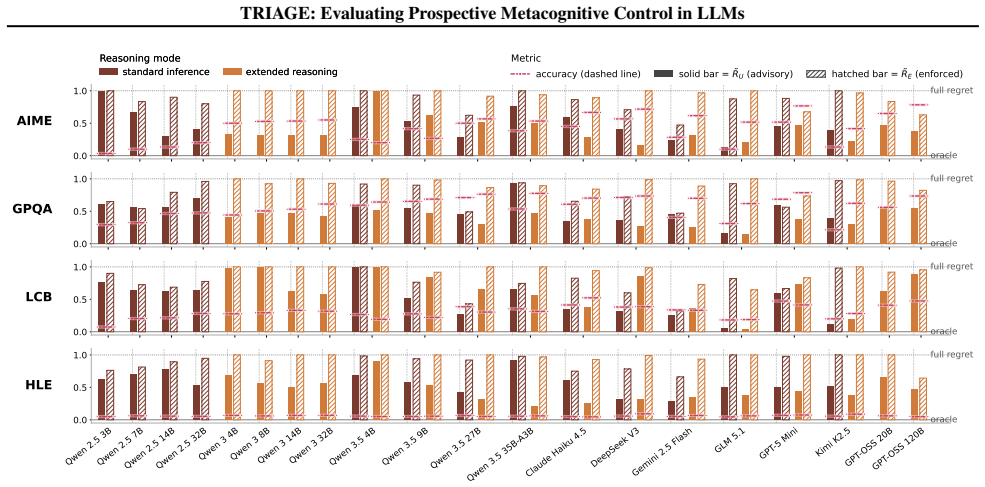
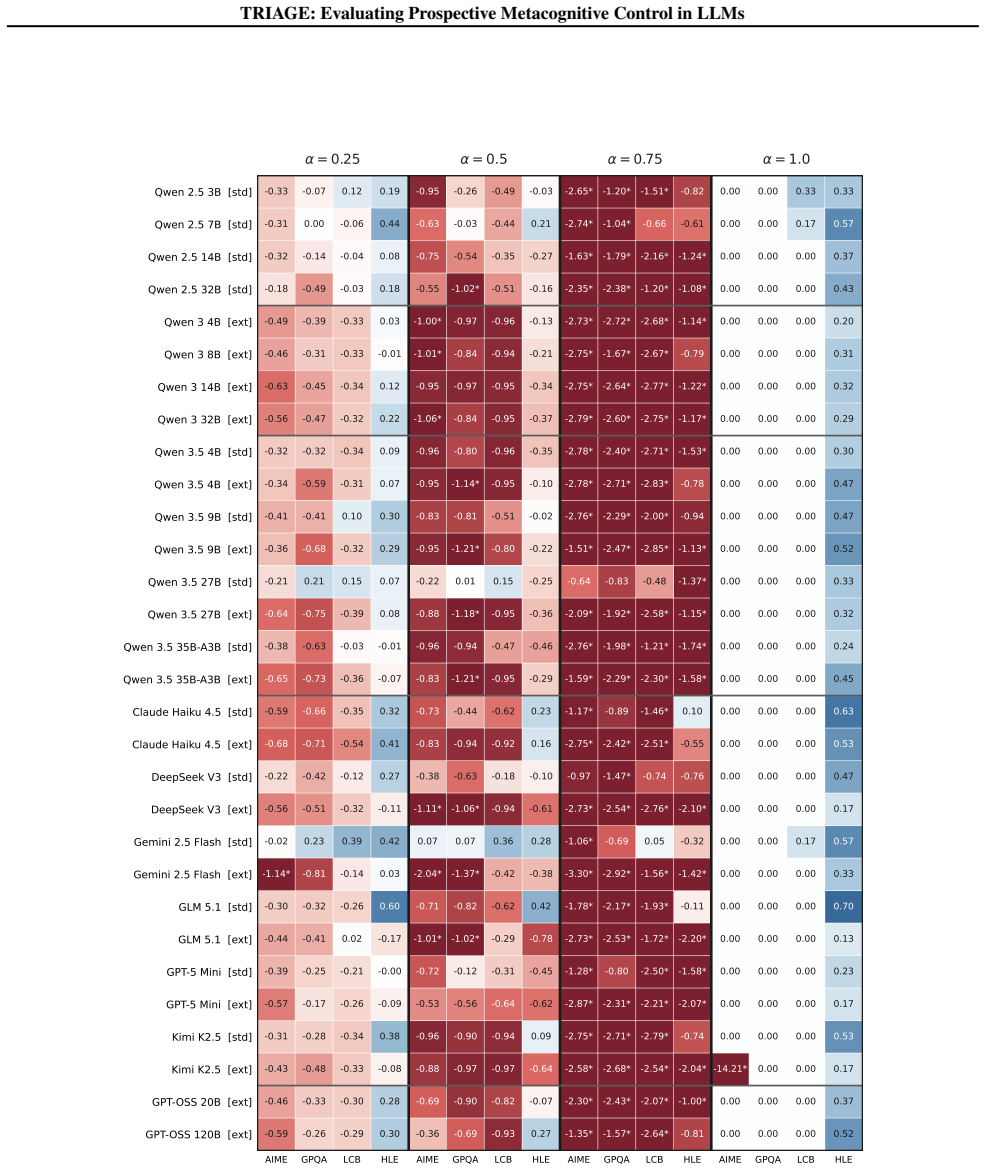
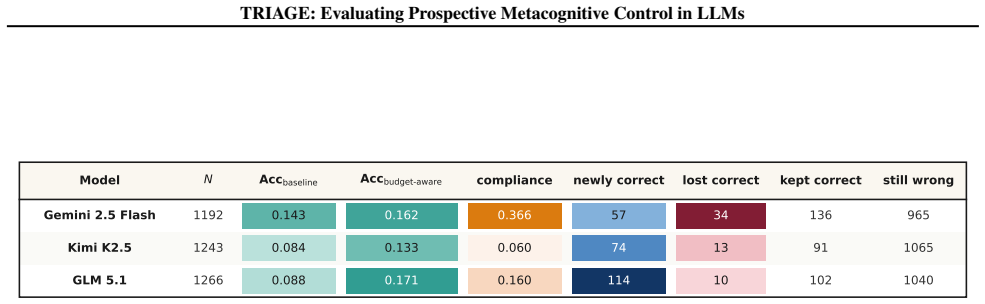
TRIAGE measures prospective metacognitive control by requiring models to commit to a single ordered plan that jointly encodes selection, sequencing, and per-problem token allocation under a budget calibrated to the model's baseline cost; the resulting triage efficiency ratio quantifies how closely the plan matches the value an oracle with full knowledge of solvability and cost would achieve.
What carries the argument
The TRIAGE efficiency ratio, computed by scoring a model's committed plan against an oracle that knows each problem's solvability and exact cost for that model.
If this is right
- Agents built on models with stronger prospective control could complete more problems within the same token budget by avoiding low-yield tasks.
- The measured capability is distinct from single-task accuracy and directly affects deployment cost in queued problem settings.
- Both reasoning-enabled and base models show the same deficit, suggesting the gap is not fixed by adding chain-of-thought at inference time.
- Closing the gap would require training objectives that reward joint planning over isolated problem solving.
Where Pith is reading between the lines
- Models that improve on TRIAGE could be paired with lighter verification steps, freeing tokens for harder problems.
- The framework could be extended to dynamic queues where new problems arrive after partial execution.
- Training data that includes explicit triage examples might narrow the gap faster than accuracy-only fine-tuning.
- Human performance on analogous triage tasks could serve as an upper bound for future model comparisons.
Load-bearing premise
An oracle that already knows the model's success rate and cost on every problem supplies a fair and unbiased benchmark without introducing hindsight bias or selection effects from the budget calibration.
What would settle it
A model that repeatedly produces plans whose achieved value reaches at least 85 percent of the oracle optimum across held-out task pools of varying difficulty would falsify the reported gaps.
Figures





read the original abstract
Deploying language models as autonomous agents requires more than per-task accuracy: when an agent faces a queue of problems under a finite token budget, it must decide which to attempt, in what order, and how much compute to commit to each, all before any execution feedback is available. This is the prospective form of metacognitive control studied for decades in human cognition, yet whether language models possess it remains untested. We introduce TRIAGE, an evaluation framework in which a model receives a task pool and a token budget calibrated to its own baseline cost, and commits to a single ordered plan that jointly encodes selection, sequencing, and per-problem allocation. Plans are scored against an oracle with full knowledge of the model's solvability and cost on each problem, yielding a triage efficiency ratio on a common scale. We evaluate frontier and open-source models, with and without reasoning enabled, across competition mathematics, graduate-level science, code generation, and expert multidisciplinary knowledge, and find that current language models exhibit substantial gaps in prospective metacognitive control, revealing a previously unmeasured capability dimension with direct implications for resource-efficient agent deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TRIAGE, a framework to evaluate prospective metacognitive control in LLMs. A model is given a task pool and a token budget calibrated to its baseline cost on those tasks. It must produce one ordered plan encoding selection, sequencing, and allocation decisions before any execution. The plan is scored against an oracle possessing full knowledge of the model's solvability and costs per problem, producing a triage efficiency ratio. Evaluations across math, science, code, and knowledge tasks indicate substantial gaps in current models' prospective control abilities.
Significance. If the central findings hold, the work identifies a new, previously unmeasured capability dimension relevant to resource-efficient deployment of LLMs as agents. The framework offers a concrete, scalable method to quantify selection, sequencing, and allocation reasoning under constraints, with direct implications for practical agent systems. The multi-domain evaluation and comparison of frontier and open-source models with and without reasoning are strengths.
major comments (1)
- [Abstract] The triage efficiency ratio is defined against an oracle with complete knowledge of solvability and per-problem costs, while the model's plan is formed prospectively without feedback. This creates an information asymmetry that may cause the reported gaps to partly reflect the oracle's hindsight rather than a pure deficit in metacognitive control. The token budget is calibrated to the model's baseline cost on the evaluation task pool, which embeds task-specific statistics unavailable at planning time.
minor comments (2)
- The abstract reports high-level findings without specific quantitative results, error bars, or detailed task descriptions, which limits immediate assessment of effect sizes.
- Clarify whether the baseline cost measurement uses the same task pool or a held-out set to avoid circularity in calibration.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of TRIAGE's significance. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] The triage efficiency ratio is defined against an oracle with complete knowledge of solvability and per-problem costs, while the model's plan is formed prospectively without feedback. This creates an information asymmetry that may cause the reported gaps to partly reflect the oracle's hindsight rather than a pure deficit in metacognitive control. The token budget is calibrated to the model's baseline cost on the evaluation task pool, which embeds task-specific statistics unavailable at planning time.
Authors: The information asymmetry is a deliberate feature of the evaluation design. The oracle establishes the theoretical maximum triage efficiency given the model's actual solvability and per-problem costs, providing a normalized measure of how closely the prospective plan approaches optimality. This approach is standard in planning and resource-allocation benchmarks to quantify deviation from the best achievable outcome under uncertainty. The gaps therefore capture limitations in the model's prospective selection, sequencing, and allocation reasoning. Regarding budget calibration, the total token budget is derived from the model's baseline costs on the pool to ensure realism and model-specificity; however, at planning time the model is given only the aggregate budget and task pool, with no per-task cost or solvability information disclosed. We will revise the abstract and methods section to explicitly clarify this design rationale and the oracle's role as an upper-bound reference. revision: yes
Circularity Check
No significant circularity in TRIAGE evaluation framework
full rationale
The paper defines the triage efficiency ratio by scoring a model's single pre-execution plan against an independent oracle that holds full knowledge of solvability and per-problem costs on the task pool. Token-budget calibration to the model's measured baseline cost on the same pool serves only as normalization to place results on a common scale; it does not embed the target ratio or any fitted parameter into the reported metric. No equations, self-citations, or uniqueness claims reduce the central result to a definition, a prior fit, or an author-supplied ansatz. The evaluation draws on external benchmarks across mathematics, science, code, and knowledge domains, keeping the derivation self-contained against verifiable external oracles.
Axiom & Free-Parameter Ledger
free parameters (1)
- token budget calibration
axioms (1)
- domain assumption Prospective metacognitive control (planning before any execution feedback) is a necessary capability for resource-efficient autonomous agents.
Reference graph
Works this paper leans on
-
[1]
Snell, Charlie and Lee, Jaehoon and Xu, Kelvin and Kumar, Aviral , booktitle =. Scaling. 2025 , note =
work page 2025
-
[2]
Reasoning on a Budget: A Survey of Adaptive and Controllable Test-Time Compute in
Alomrani, Mohammad Ali and Zhang, Yingxue and Li, Derek and Sun, Qianyi and Pal, Soumyasundar and Zhang, Zhanguang and Hu, Yaochen and Ajwani, Rohan Deepak and Valkanas, Antonios and Karimi, Raika and Cheng, Peng and Wang, Yunzhou and Liao, Pengyi and Huang, Hanrui and Wang, Bin and Hao, Jianye and Coates, Mark , journal =. Reasoning on a Budget: A Survey...
-
[3]
Chen, Xingyu and Xu, Jiahao and Liang, Tian and He, Zhiwei and Pang, Jianhui and Yu, Dian and Song, Linfeng and Liu, Qiuzhi and Zhou, Mengfei and Zhang, Zhuosheng and Wang, Rui and Tu, Zhaopeng and Mi, Haitao and Yu, Dong , journal =. Do
-
[4]
Thoughts Are All Over the Place: On the Underthinking of o1-Like
Wang, Yue and Liu, Qiuzhi and Xu, Jiahao and Liang, Tian and Chen, Xingyu and He, Zhiwei and Song, Linfeng and Yu, Dian and Li, Juntao and Zhang, Zhuosheng and Wang, Rui and Tu, Zhaopeng and Mi, Haitao and Yu, Dong , booktitle =. Thoughts Are All Over the Place: On the Underthinking of o1-Like. 2025 , note =
work page 2025
-
[5]
arXiv preprint arXiv:2502.08235 , year =
The Danger of Overthinking: Examining the Reasoning-Action Dilemma in Agentic Tasks , author =. arXiv preprint arXiv:2502.08235 , year =
-
[6]
Behavioral and Brain Sciences , volume =
Resource-rational analysis: Understanding human cognition as the optimal use of limited computational resources , author =. Behavioral and Brain Sciences , volume =. 2020 , doi =
work page 2020
-
[7]
The Psychology of Learning and Motivation , editor =
Metamemory: A theoretical framework and new findings , author =. The Psychology of Learning and Motivation , editor =. 1990 , publisher =
work page 1990
-
[8]
Language Models (Mostly) Know What They Know
Language Models (Mostly) Know What They Know , author =. arXiv preprint arXiv:2207.05221 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Kirichenko, Polina and Ibrahim, Mark and Chaudhuri, Kamalika and Bell, Samuel J. , booktitle =. 2025 , note =
work page 2025
-
[10]
arXiv preprint arXiv:2512.24661 , year =
Do Large Language Models Know What They Are Capable Of? , author =. arXiv preprint arXiv:2512.24661 , year =
-
[11]
Han, Tingxu and Wang, Zhenting and Fang, Chunrong and Zhao, Shiyu and Ma, Shiqing and Chen, Zhenyu , booktitle =. Token-Budget-Aware. 2025 , note =
work page 2025
-
[12]
Li, Zheng and Dong, Qingxiu and Ma, Jingyuan and Zhang, Di and Jia, Kai and Sui, Zhifang , journal =
-
[13]
Jin, Yunho and Wu, Chun-Feng and Brooks, David and Wei, Gu-Yeon , booktitle =. 2023 , note =
work page 2023
- [14]
-
[15]
Evidence for Limited Metacognition in
Ackerman, Christopher , booktitle =. Evidence for Limited Metacognition in. 2026 , note =
work page 2026
-
[16]
Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =
Metacognitive and control strategies in study-time allocation , author =. Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =. 2000 , doi =
work page 2000
-
[17]
Jain, Naman and Han, King and Gu, Alex and Li, Wen-Ding and Yan, Fanjia and Zhang, Tianjun and Wang, Sida and Solar-Lezama, Armando and Sen, Koushik and Stoica, Ion , journal =
-
[18]
Humanity's last exam , author=. arXiv preprint arXiv:2501.14249 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [19]
-
[20]
Advances in Neural Information Processing Systems , volume=
Large Language Models Must Be Taught to Know What They Don't Know , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
arXiv preprint arXiv:2505.13763 , year=
Language Models Are Capable of Metacognitive Monitoring and Control of Their Internal Activations , author=. arXiv preprint arXiv:2505.13763 , year=
-
[22]
Current Directions in Psychological Science , year=
Metacognition and Uncertainty Communication in Humans and Large Language Models , author=. Current Directions in Psychological Science , year=
- [23]
-
[24]
Valmeekam, Karthik and Marquez, Matthew and Olmo, Alberto and Sreedharan, Sarath and Kambhampati, Subbarao , booktitle=. 2023 , note=
work page 2023
-
[25]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author=. arXiv preprint arXiv:2406.12045 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
International Conference on Learning Representations , year=
Mialon, Gr\'. International Conference on Learning Representations , year=
-
[27]
Journal of Applied Meteorology , volume=
A New Vector Partition of the Probability Score , author=. Journal of Applied Meteorology , volume=
-
[28]
Psychological Review , volume =
Koriat, Asher and Goldsmith, Morris , title =. Psychological Review , volume =. 1996 , doi =
work page 1996
-
[29]
Journal of Memory and Language , volume =
Metcalfe, Janet and Kornell, Nate , title =. Journal of Memory and Language , volume =. 2005 , doi =
work page 2005
-
[30]
Journal of Experimental Psychology: Applied , volume =
Ackerman, Rakefet and Goldsmith, Morris , title =. Journal of Experimental Psychology: Applied , volume =. 2011 , doi =
work page 2011
- [31]
- [32]
-
[33]
Leonesio, R. Jacob and Nelson, Thomas O. , title =. Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =. 1990 , doi =
work page 1990
-
[34]
Journal of Experimental Psychology: General , volume =
Mazzoni, Giuliana and Cornoldi, Cesare , title =. Journal of Experimental Psychology: General , volume =. 1993 , doi =
work page 1993
- [35]
-
[36]
Thiede, Keith W. and Dunlosky, John , title =. Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =. 1999 , doi =
work page 1999
- [37]
-
[38]
Advances in Neural Information Processing Systems , volume =
Geifman, Yonatan and El-Yaniv, Ran , title =. Advances in Neural Information Processing Systems , volume =. 2017 , eprint =
work page 2017
-
[39]
Kellerer, Hans and Pferschy, Ulrich and Pisinger, David , title =. 2004 , isbn =
work page 2004
-
[40]
Findings of the Association for Computational Linguistics: ACL 2025 , pages =
Han, Tingxu and Wang, Zhenting and Fang, Chunrong and Zhao, Shiyu and Ma, Shiqing and Chen, Zhenyu , title =. Findings of the Association for Computational Linguistics: ACL 2025 , pages =. 2025 , doi =
work page 2025
-
[41]
Xu, Binfeng and Peng, Zhiyuan and Lei, Bowen and Mukherjee, Subhabrata and Liu, Yuchen and Xu, Dongkuan , title =. arXiv preprint , year =. 2305.18323 , archivePrefix =
-
[42]
Lin, Xiaoqiang and Liew, Jun Hao and Savarese, Silvio and Li, Junnan , title =. arXiv preprint , year =. 2602.07359 , archivePrefix =
-
[43]
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik R. , title =. The Twelfth International Conference on Learning Representations (ICLR) , year =
-
[44]
Findings of the Association for Computational Linguistics: ACL 2023 , pages =
Tang, Ruixiang and Kong, Dehan and Huang, Longtao and Xue, Hui , title =. Findings of the Association for Computational Linguistics: ACL 2023 , pages =. 2023 , doi =
work page 2023
-
[45]
Rein, David and Hou, Betty Li and Stickland, Asa Cooper and Petty, Jackson and Pang, Richard Yuanzhe and Dirani, Julien and Michael, Julian and Bowman, Samuel R. , booktitle =. 2024 , eprint =
work page 2024
- [46]
-
[47]
Evidence for Limited Metacognition in
Ackerman, Christopher , booktitle =. Evidence for Limited Metacognition in
-
[48]
Yao, Shunyu and Shinn, Noah and Razavi, Pedram and Narasimhan, Karthik , journal =
-
[49]
International Conference on Learning Representations (ICLR) , year =
Mialon, Gr. International Conference on Learning Representations (ICLR) , year =
-
[50]
Behavioral and Brain Sciences , volume =
Resource-Rational Analysis: Understanding Human Cognition as the Optimal Use of Limited Computational Resources , author =. Behavioral and Brain Sciences , volume =. 2020 , doi =
work page 2020
-
[51]
Journal of Applied Meteorology , volume =
A New Vector Partition of the Probability Score , author =. Journal of Applied Meteorology , volume =
-
[52]
Psychological Review , volume =
Monitoring and Control Processes in the Strategic Regulation of Memory Accuracy , author =. Psychological Review , volume =
-
[53]
Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =
Metacognitive and Control Strategies in Study-Time Allocation , author =. Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =
-
[54]
Journal of Experimental Psychology: Applied , volume =
Metacognitive Regulation of Text Learning: On Screen Versus on Paper , author =. Journal of Experimental Psychology: Applied , volume =
-
[55]
Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =
Toward a General Model of Self-Regulated Study: An Analysis of Selection of Items for Study and Self-Paced Study Time , author =. Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =
-
[56]
Journal of Experimental Psychology: General , volume =
Strategies in Study-Time Allocation: Why Is Study Time Sometimes Not Effective? , author =. Journal of Experimental Psychology: General , volume =
-
[57]
Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =
Spacing One's Study: Evidence for a Metacognitive Control Strategy , author =. Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =
-
[58]
Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =
Do Different Metamemory Judgments Tap the Same Underlying Aspects of Memory? , author =. Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =
-
[59]
Transactions of the Association for Computational Linguistics , volume =
Lost in the Middle: How Language Models Use Long Contexts , author =. Transactions of the Association for Computational Linguistics , volume =
-
[60]
Advances in Neural Information Processing Systems , volume=
Metacognitive capabilities of llms: An exploration in mathematical problem solving , author=. Advances in Neural Information Processing Systems , volume=
-
[61]
Xiong, Miao and Hu, Zhiyuan and Lu, Xinyang and Li, Yifei and Fu, Jie and He, Junxian and Hooi, Bryan , booktitle=. Can. 2024 , url=
work page 2024
-
[62]
Decoupling Metacognition from Cognition: A Framework for Quantifying Metacognitive Ability in
Wang and others , booktitle=. Decoupling Metacognition from Cognition: A Framework for Quantifying Metacognitive Ability in. 2025 , doi=
work page 2025
-
[63]
Nature Communications , volume=
Large Language Models lack essential metacognition for reliable medical reasoning , author=. Nature Communications , volume=. 2025 , doi=
work page 2025
-
[64]
arXiv preprint arXiv:2508.15124 , year=
Side Effects of Erasing Concepts from Diffusion Models , author=. arXiv preprint arXiv:2508.15124 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.