Recognition: unknown
SID: Sliding into Distribution for Robust Few-Demonstration Manipulation
Pith reviewed 2026-05-14 19:12 UTC · model grok-4.3
The pith
A learned object-centric motion field from two demonstrations iteratively guides a robot into the reliable region of an egocentric policy for robust manipulation under large shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SID learns an object-centric motion field from canonicalized demonstrations to iteratively slide the system toward the demonstrated manifold and into the reliable operating region of a lightweight egocentric execution policy trained with conditioned flow matching, supported by kinematically consistent point-cloud reprojection augmentation.
What carries the argument
The object-centric motion field, which generates distance-dependent corrective motions that vanish near the demonstration manifold and thereby performs online distribution recovery.
If this is right
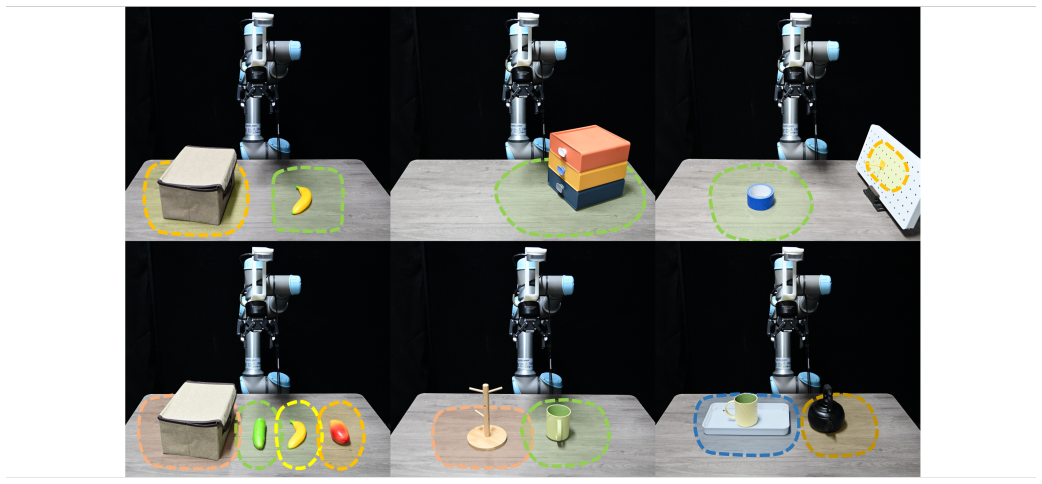
- Only two demonstrations suffice for approximately 90 percent success across six real-world manipulation tasks under out-of-distribution initializations.
- Success drops by less than 10 percent when distractors and external disturbances are added.
- The motion field enables reliable reaching, after which the egocentric policy handles precise task-specific actions.
- Kinematically consistent point-cloud reprojection augmentation preserves action-observation consistency during policy training.
Where Pith is reading between the lines
- The separation of reaching via a motion field and execution via an egocentric policy could be applied to longer-horizon tasks by learning sequential manifolds.
- The framework may lower the data-collection burden in physical robotics by exploiting geometric structure rather than scaling demonstrations.
- Extending the motion field to incorporate additional sensor modalities could further improve robustness without increasing demonstration count.
Load-bearing premise
Demonstrations can be canonicalized into a reliable object-centric motion field that guides the robot into the operating region of the egocentric policy despite substantial pose and viewpoint shifts.
What would settle it
Measure whether the learned motion field consistently reduces distance to the demonstration manifold in real-robot trials with novel object poses and camera viewpoints, or whether success falls substantially below 90 percent under those conditions.
Figures










read the original abstract
Generalizing robotic manipulation across object poses, viewpoints, and dynamic disturbances is difficult, especially with only a few demonstrations. End-to-end visuomotor policies are expressive but data-hungry, while planning and optimization satisfy explicit constraints but do not directly capture the interaction strategies demonstrated by humans. We propose Sliding into Distribution (SID), a structured framework that learns an object-centric motion field from canonicalized demonstrations to iteratively slide the system toward the demonstrated manifold and into the reliable operating region of a lightweight egocentric execution policy, mitigating out-of-distribution (OOD) execution. The motion field provides large corrective motions when far from the demonstration manifold and naturally vanishes near convergence, enabling robust reaching under substantial pose and viewpoint shifts. Within the reached regime, an egocentric policy trained with conditioned flow matching performs task-specific manipulation, supported by kinematically consistent point-cloud reprojection augmentation that preserves action-observation consistency. Across six real-world tasks, SID achieves approximately 90% success under OOD initializations with only two demonstrations, with under a 10% drop under distractors and external disturbances. Overall, SID provides a new paradigm for few-shot manipulation: explicitly managing distribution shift via online distribution recovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Sliding into Distribution (SID), a hybrid framework for few-shot robotic manipulation. It learns an object-centric motion field from two canonicalized demonstrations to iteratively correct pose and viewpoint shifts, sliding the system into the operating region of a lightweight egocentric policy trained via conditioned flow matching with point-cloud reprojection augmentation. The central empirical claim is that this yields ~90% success across six real-world tasks under substantial OOD initializations, with <10% degradation under distractors and external disturbances.
Significance. If the performance claims and the motion-field guidance mechanism hold under rigorous verification, the work would offer a practical new paradigm for robust few-demonstration manipulation that explicitly manages distribution shift rather than relying solely on data scale or end-to-end generalization. The combination of a vanishing corrective field with a lightweight execution policy is conceptually attractive for real-robot deployment.
major comments (3)
- [§4.2] §4.2 and Eq. (3)–(5): The motion field is asserted to 'provide large corrective motions when far' and 'naturally vanish near convergence,' yet no Lyapunov-style stability argument, contraction mapping, or convergence-rate analysis is supplied to show that the field remains well-behaved when canonicalization errors arise from viewpoint shifts or when external disturbances act on the real dynamics.
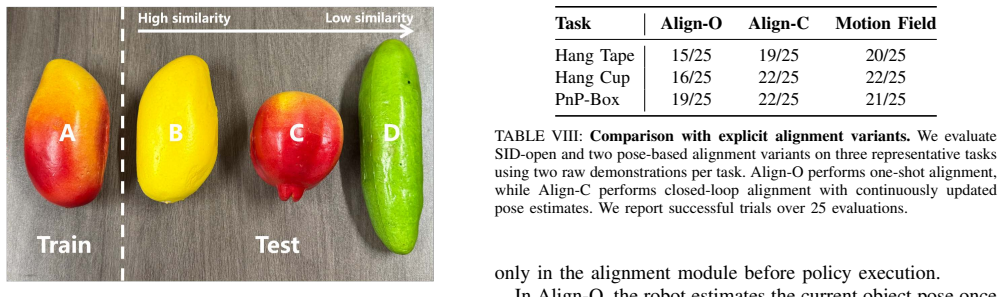
- [Table 1] Table 1 and §5.3: Success rates are reported as point estimates (~90% and <10% drop) without per-task standard deviations, number of trials, or statistical significance tests against the strongest baselines; this makes it impossible to judge whether the headline performance difference is reliable or could be explained by run-to-run variance.
- [§5.4] §5.4 (ablation study): The paper does not report an ablation that isolates the contribution of the learned motion field versus the egocentric policy alone under the same OOD pose/viewpoint conditions; without this, it is unclear whether the iterative guidance is load-bearing for the reported robustness.
minor comments (2)
- [Figure 3] Figure 3: The visualization of the motion field on point clouds would benefit from an explicit color scale or vector-length legend so readers can verify the claimed 'large corrective' to 'vanishing' behavior.
- [§3.1] §3.1: The precise procedure for obtaining the canonical frame from a single demonstration is described at a high level; a short pseudocode block or explicit transformation equations would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment below and describe the corresponding revisions.
read point-by-point responses
-
Referee: [§4.2] §4.2 and Eq. (3)–(5): The motion field is asserted to 'provide large corrective motions when far' and 'naturally vanish near convergence,' yet no Lyapunov-style stability argument, contraction mapping, or convergence-rate analysis is supplied to show that the field remains well-behaved when canonicalization errors arise from viewpoint shifts or when external disturbances act on the real dynamics.
Authors: We acknowledge that a formal stability analysis is absent. The motion field is designed from canonicalized demonstrations to produce large corrections far from the manifold and to vanish near convergence, with this behavior empirically confirmed across six real-world tasks under viewpoint shifts and disturbances. In the revision we will add a dedicated discussion of the empirical convergence behavior, including plots of field magnitude versus distance to the manifold, while noting that a full Lyapunov proof remains future work. revision: partial
-
Referee: [Table 1] Table 1 and §5.3: Success rates are reported as point estimates (~90% and <10% drop) without per-task standard deviations, number of trials, or statistical significance tests against the strongest baselines; this makes it impossible to judge whether the headline performance difference is reliable or could be explained by run-to-run variance.
Authors: We agree that statistical details are required for assessing reliability. The revised manuscript will expand Table 1 to report the number of trials per task, per-task standard deviations, and results of statistical significance tests against the strongest baselines. revision: yes
-
Referee: [§5.4] §5.4 (ablation study): The paper does not report an ablation that isolates the contribution of the learned motion field versus the egocentric policy alone under the same OOD pose/viewpoint conditions; without this, it is unclear whether the iterative guidance is load-bearing for the reported robustness.
Authors: We recognize the importance of isolating the motion field's contribution. The revised manuscript will include a new ablation that evaluates the egocentric policy alone under identical OOD pose and viewpoint conditions, directly comparing it to the full SID framework to quantify the benefit of the iterative guidance. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents SID as a framework that learns an object-centric motion field from canonicalized demonstrations, with its corrective behavior described as emerging from the learned representation rather than predefined by the target success metric. No equations or claims in the provided text reduce by construction to fitted parameters, self-referential definitions, or self-citation chains. The central empirical claims (approximately 90% success on six tasks with two demonstrations) rest on real-world experimental results under OOD conditions, not on tautological derivations. The framework is self-contained against external benchmarks with independent validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Few demonstrations can be canonicalized to learn an effective object-centric motion field for guiding the system into the egocentric policy's operating region
invented entities (1)
-
object-centric motion field
no independent evidence
Reference graph
Works this paper leans on
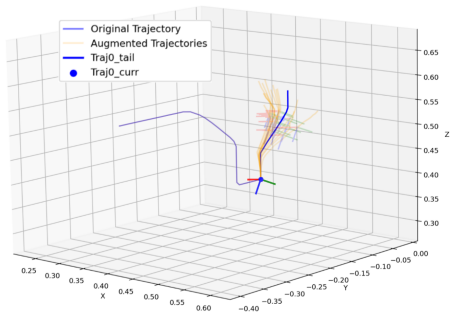
-
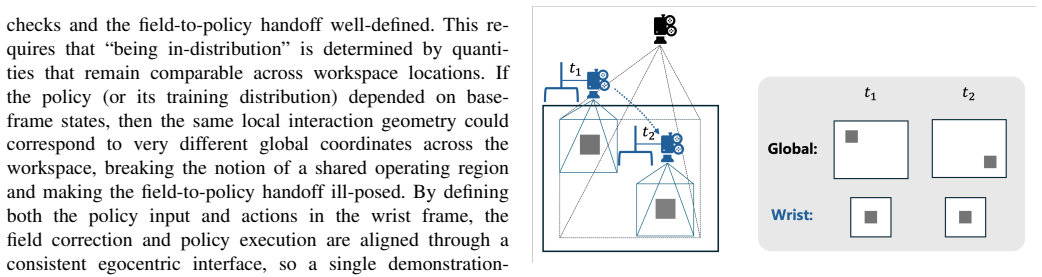
[1]
Collins, Mrinal Jain, and Animesh Garg
Ezra Ameperosa, Jeremy A. Collins, Mrinal Jain, and Animesh Garg. Rocoda: Counterfactual data augmen- tation for data-efficient robot learning from demonstra- tions, 2025. URL https://arxiv.org/abs/2411.16959
-
[2]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoub- hik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, An- drew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman R ¨adle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Li...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Object-centric representations improve policy generalization in robot manipulation
Alexandre Chapin, Bruno Machado, Emmanuel Dellan- drea, and Liming Chen. Object-centric representations improve policy generalization in robot manipulation. arXiv preprint arXiv:2505.11563, 2025
-
[4]
Genaug: Retargeting behaviors to unseen situations via gener- ative augmentation,
Zoey Chen, Sho Kiami, Abhishek Gupta, and Vikash Kumar. Genaug: Retargeting behaviors to unseen situ- ations via generative augmentation, 2023. URL https: //arxiv.org/abs/2302.06671
-
[5]
Semantically con- trollable augmentations for generalizable robot learn- ing,
Zoey Chen, Zhao Mandi, Homanga Bharadhwaj, Mohit Sharma, Shuran Song, Abhishek Gupta, and Vikash Kumar. Semantically controllable augmentations for generalizable robot learning, 2024. URL https://arxiv. org/abs/2409.00951
-
[6]
Diffusion policy: Visuomotor policy learning via action diffusion, 2024
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion, 2024. URL https://arxiv.org/abs/2303. 04137
2024
-
[7]
Learning a thousand tasks in a day.Science Robotics, 10(108), November 2025
Kamil Dreczkowski, Pietro Vitiello, Vitalis V osylius, and Edward Johns. Learning a thousand tasks in a day.Science Robotics, 10(108), November 2025. ISSN 2470-9476. doi: 10.1126/scirobotics.adv7594. URL http://dx.doi.org/10.1126/scirobotics.adv7594
-
[8]
Behavior retrieval: Few-shot imitation learning by querying unlabeled datasets, 2023
Maximilian Du, Suraj Nair, Dorsa Sadigh, and Chelsea Finn. Behavior retrieval: Few-shot imitation learning by querying unlabeled datasets, 2023. URL https://arxiv.org/ abs/2304.08742
-
[9]
Yan Duan, Marcin Andrychowicz, Bradly C. Stadie, Jonathan Ho, Jonas Schneider, Ilya Sutskever, Pieter Abbeel, and Wojciech Zaremba. One-shot imitation learning, 2017. URL https://arxiv.org/abs/1703.07326
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
Kalm: Keypoint abstraction using large models for object-relative imitation learning
Xiaolin Fang, Bo-Ruei Huang, Jiayuan Mao, Jasmine Shone, Joshua B Tenenbaum, Tom ´as Lozano-P ´erez, and Leslie Pack Kaelbling. Kalm: Keypoint abstraction using large models for object-relative imitation learning. In 2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8307–8314. IEEE, 2025
2025
-
[11]
One-shot visual imitation learning via meta-learning, 2017
Chelsea Finn, Tianhe Yu, Tianhao Zhang, Pieter Abbeel, and Sergey Levine. One-shot visual imitation learning via meta-learning, 2017. URL https://arxiv.org/abs/1709. 04905
2017
-
[12]
Jianfeng Gao, Zhi Tao, No ´emie Jaquier, and Tamim Asfour. K-vil: Keypoints-based visual imitation learn- ing.IEEE Transactions on Robotics, 39(5):3888– 3908, October 2023. ISSN 1941-0468. doi: 10.1109/ tro.2023.3286074. URL http://dx.doi.org/10.1109/TRO. 2023.3286074
work page doi:10.1109/tro 2023
-
[13]
Partmanip: Learning cross-category generalizable part manipulation policy from point cloud observations
Haoran Geng, Ziming Li, Yiran Geng, Jiayi Chen, Hao Dong, and He Wang. Partmanip: Learning cross-category generalizable part manipulation policy from point cloud observations. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 2978–2988, 2023
2023
-
[14]
Rvt: Robotic view transformer for 3d object manipulation
Ankit Goyal, Jie Xu, Yijie Guo, Valts Blukis, Yu-Wei Chao, and Dieter Fox. Rvt: Robotic view transformer for 3d object manipulation. InConference on Robot Learning, pages 694–710. PMLR, 2023
2023
-
[15]
Adaflow: Imitation learning with variance-adaptive flow-based policies, 2024
Xixi Hu, Bo Liu, Xingchao Liu, and Qiang Liu. Adaflow: Imitation learning with variance-adaptive flow-based policies, 2024. URL https://arxiv.org/abs/2402.04292
-
[16]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pert...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Coarse-to-fine q-attention: Efficient learning for visual robotic manipulation via discretisa- tion
Stephen James, Kentaro Wada, Tristan Laidlow, and Andrew J Davison. Coarse-to-fine q-attention: Efficient learning for visual robotic manipulation via discretisa- tion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13739– 13748, 2022
2022
-
[18]
Bc-z: Zero-shot task generalization with robotic imitation learning
Eric Jang, Alex Irpan, Mohi Khansari, Daniel Kappler, Frederik Ebert, Corey Lynch, Sergey Levine, and Chelsea Finn. Bc-z: Zero-shot task generalization with robotic imitation learning. InConference on Robot Learning, pages 991–1002. PMLR, 2022
2022
-
[19]
Hanxiao Jiang, Binghao Huang, Ruihai Wu, Zhuoran Li, Shubham Garg, Hooshang Nayyeri, Shenlong Wang, and Yunzhu Li. Roboexp: Action-conditioned scene graph via interactive exploration for robotic manipulation.arXiv preprint arXiv:2402.15487, 2024
-
[20]
Coarse-to-fine imitation learning: Robot manipulation from a single demonstration
Edward Johns. Coarse-to-fine imitation learning: Robot manipulation from a single demonstration. In2021 IEEE international conference on robotics and automation (ICRA), pages 4613–4619. IEEE, 2021
2021
-
[21]
3d diffuser actor: Policy diffusion with 3d scene representations, 2024
Tsung-Wei Ke, Nikolaos Gkanatsios, and Katerina Fragkiadaki. 3d diffuser actor: Policy diffusion with 3d scene representations, 2024. URL https://arxiv.org/abs/ 2402.10885
-
[22]
Weijie Kong, Zhaohui Lin, Wei Yu, Haotian Guo, Zhian Su, and Huixu Dong. Affpose: An integrated rgb- based framework for simultaneous pose estimation and affordance detection in robotic tool manipulation.IEEE Robotics and Automation Letters, 10(10):10170–10177,
-
[23]
doi: 10.1109/LRA.2025.3598984
-
[24]
End-to-end training of deep visuomotor policies,
Sergey Levine, Chelsea Finn, Trevor Darrell, and Pieter Abbeel. End-to-end training of deep visuomotor policies,
-
[25]
URL https://arxiv.org/abs/1504.00702
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Sergey Levine, Peter Pastor, Alex Krizhevsky, and Deirdre Quillen. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection, 2016. URL https://arxiv.org/abs/1603.02199
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[27]
Language-guided object-centric diffusion policy for generalizable and collision-aware manipulation
Hang Li, Qian Feng, Zhi Zheng, Jianxiang Feng, Zhaopeng Chen, and Alois Knoll. Language-guided object-centric diffusion policy for generalizable and collision-aware manipulation. In2025 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 12834–12841. IEEE, 2025
2025
-
[28]
Bridgevla: Input-output alignment for efficient 3d manipulation learning with vision-language models
Peiyan Li, Yixiang Chen, Hongtao Wu, Xiao Ma, Xiang- nan Wu, Yan Huang, Liang Wang, Tao Kong, and Tieniu Tan. Bridgevla: Input-output alignment for efficient 3d manipulation learning with vision-language models. arXiv preprint arXiv:2506.07961, 2025
-
[29]
Yu Li, Xiaojie Zhang, Ruihai Wu, Zilong Zhang, Yiran Geng, Hao Dong, and Zhaofeng He. Unidoormanip: Learning universal door manipulation policy over large- scale and diverse door manipulation environments.arXiv preprint arXiv:2403.02604, 2024
-
[30]
Zhaohui Lin, Haonan Dong, Weijie Kong, Haoran Huang, I-Ming Chen, and Huixu Dong. A coarse- to-fine multimodal detection framework based on deep learning for robotic coating tasks.IEEE/ASME Trans- actions on Mechatronics, 31(1):639–650, 2026. doi: 10.1109/TMECH.2025.3595263
-
[31]
Learning to generalize across long-horizon tasks from human demonstrations
Ajay Mandlekar, Danfei Xu, Roberto Mart ´ın-Mart´ın, Silvio Savarese, and Li Fei-Fei. Learning to generalize across long-horizon tasks from human demonstrations. arXiv preprint arXiv:2003.06085, 2020
-
[32]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Mart ´ın-Mart´ın. What matters in learning from offline human demon- strations for robot manipulation.arXiv preprint arXiv:2108.03298, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
kpam: Keypoint affordances for category-level robotic manipulation, 2019
Lucas Manuelli, Wei Gao, Peter Florence, and Russ Tedrake. kpam: Keypoint affordances for category-level robotic manipulation, 2019. URL https://arxiv.org/abs/ 1903.06684
-
[34]
Calvin: A benchmark for language- conditioned policy learning for long-horizon robot ma- nipulation tasks, 2022
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. Calvin: A benchmark for language- conditioned policy learning for long-horizon robot ma- nipulation tasks, 2022. URL https://arxiv.org/abs/2112. 03227
2022
-
[35]
Two by two: Learning multi- task pairwise objects assembly for generalizable robot manipulation
Yu Qi, Yuanchen Ju, Tianming Wei, Chi Chu, Lawson LS Wong, and Huazhe Xu. Two by two: Learning multi- task pairwise objects assembly for generalizable robot manipulation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17383–17393, 2025
2025
-
[36]
Jianing Qian, Yunshuang Li, Bernadette Bucher, and Dinesh Jayaraman. Task-oriented hierarchical object decomposition for visuomotor control.arXiv preprint arXiv:2411.01284, 2024
-
[37]
Behavior transformers: Cloning k modes with one stone
Nur Muhammad Mahi Shafiullah, Zichen Jeff Cui, Ar- iuntuya Altanzaya, and Lerrel Pinto. Behavior trans- formers: Cloningkmodes with one stone, 2022. URL https://arxiv.org/abs/2206.11251
-
[38]
Cliport: What and where pathways for robotic manipulation,
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Cliport: What and where pathways for robotic manipulation,
- [39]
-
[40]
Perceiver-actor: A multi-task transformer for robotic ma- nipulation
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Perceiver-actor: A multi-task transformer for robotic ma- nipulation. InConference on Robot Learning, pages 785–
-
[41]
Fast flow-based visuomotor policies via conditional optimal transport couplings, 2025
Andreas Sochopoulos, Nikolay Malkin, Nikolaos Tsagkas, Jo ˜ao Moura, Michael Gienger, and Sethu Vijayakumar. Fast flow-based visuomotor policies via conditional optimal transport couplings, 2025. URL https://arxiv.org/abs/2505.01179
-
[42]
Zhian Su, Yicheng Ma, Haotian Guo, and Huixu Dong. Construction of bin-picking system for logistic applica- tion: A hybrid robotic gripper and vision-based grasp planning.IEEE Robotics and Automation Letters, 10(8): 8300–8307, 2025. doi: 10.1109/LRA.2025.3585393
-
[43]
Kite: Keypoint-conditioned policies for semantic manipulation.arXiv preprint arXiv:2306.16605, 2023
Priya Sundaresan, Suneel Belkhale, Dorsa Sadigh, and Jeannette Bohg. Kite: Keypoint-conditioned policies for semantic manipulation.arXiv preprint arXiv:2306.16605, 2023
-
[44]
Chao Tang, Anxing Xiao, Yuhong Deng, Tianrun Hu, Wenlong Dong, Hanbo Zhang, David Hsu, and Hong Zhang. Functo: Function-centric one-shot imi- tation learning for tool manipulation.arXiv preprint arXiv:2502.11744, 2025
-
[45]
Mimicplay: Long- horizon imitation learning by watching human play,
Chen Wang, Linxi Fan, Jiankai Sun, Ruohan Zhang, Li Fei-Fei, Danfei Xu, Yuke Zhu, and Anima Anand- kumar. Mimicplay: Long-horizon imitation learning by watching human play.arXiv preprint arXiv:2302.12422, 2023
-
[46]
Rise: 3d perception makes real-world robot imitation simple and effective, 2024
Chenxi Wang, Hongjie Fang, Hao-Shu Fang, and Cewu Lu. Rise: 3d perception makes real-world robot imitation simple and effective, 2024. URL https://arxiv.org/abs/ 2404.12281
-
[47]
Equiv- ariant diffusion policy, 2024
Dian Wang, Stephen Hart, David Surovik, Tarik Ke- lestemur, Haojie Huang, Haibo Zhao, Mark Yeatman, Jiuguang Wang, Robin Walters, and Robert Platt. Equiv- ariant diffusion policy, 2024. URL https://arxiv.org/abs/ 2407.01812
-
[48]
Skil: Semantic keypoint imitation learn- ing for generalizable data-efficient manipulation, 2025
Shengjie Wang, Jiacheng You, Yihang Hu, Jiongye Li, and Yang Gao. Skil: Semantic keypoint imitation learn- ing for generalizable data-efficient manipulation, 2025. URL https://arxiv.org/abs/2501.14400
-
[49]
Foundationpose: Unified 6d pose estimation and tracking of novel objects, 2024
Bowen Wen, Wei Yang, Jan Kautz, and Stan Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects, 2024. URL https://arxiv.org/abs/2312. 08344
2024
-
[50]
Cage: Causal attention enables data-efficient generalizable robotic manipulation, 2024
Shangning Xia, Hongjie Fang, Cewu Lu, and Hao- Shu Fang. Cage: Causal attention enables data-efficient generalizable robotic manipulation, 2024. URL https: //arxiv.org/abs/2410.14974
-
[51]
Zhengrong Xue, Shuying Deng, Zhenyang Chen, Yixuan Wang, Zhecheng Yuan, and Huazhe Xu. Demogen: Synthetic demonstration generation for data-efficient vi- suomotor policy learning, 2025. URL https://arxiv.org/ abs/2502.16932
-
[52]
Equibot: Sim(3)-equivariant diffusion policy for generalizable and data efficient learning, 2024
Jingyun Yang, Zi ang Cao, Congyue Deng, Rika Antonova, Shuran Song, and Jeannette Bohg. Equibot: Sim(3)-equivariant diffusion policy for generalizable and data efficient learning, 2024. URL https://arxiv.org/abs/ 2407.01479
-
[53]
Equiv- act: Sim(3)-equivariant visuomotor policies beyond rigid object manipulation, 2024
Jingyun Yang, Congyue Deng, Jimmy Wu, Rika Antonova, Leonidas Guibas, and Jeannette Bohg. Equiv- act: Sim(3)-equivariant visuomotor policies beyond rigid object manipulation, 2024. URL https://arxiv.org/abs/ 2310.16050
-
[54]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations, 2024
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations, 2024. URL https://arxiv.org/abs/2403. 03954
2024
-
[55]
Transporter networks: Rearranging the visual world for robotic manipulation,
Andy Zeng, Pete Florence, Jonathan Tompson, Stefan Welker, Jonathan Chien, Maria Attarian, Travis Arm- strong, Ivan Krasin, Dan Duong, Ayzaan Wahid, Vikas Sindhwani, and Johnny Lee. Transporter networks: Rearranging the visual world for robotic manipulation,
- [56]
-
[57]
Qinglun Zhang, Zhen Liu, Haoqiang Fan, Guanghui Liu, Bing Zeng, and Shuaicheng Liu. Flowpolicy: Enabling fast and robust 3d flow-based policy via consistency flow matching for robot manipulation, 2024. URL https://arxiv.org/abs/2412.04987
-
[58]
One-shot imita- tion learning with invariance matching for robotic ma- nipulation, 2024
Xinyu Zhang and Abdeslam Boularias. One-shot imita- tion learning with invariance matching for robotic ma- nipulation, 2024. URL https://arxiv.org/abs/2405.13178
-
[59]
General- izable hierarchical skill learning via object-centric repre- sentation, 2025
Haibo Zhao, Yu Qi, Boce Hu, Yizhe Zhu, Ziyan Chen, Heng Tian, Xupeng Zhu, Owen Howell, Haojie Huang, Robin Walters, Dian Wang, and Robert Platt. General- izable hierarchical skill learning via object-centric repre- sentation, 2025. URL https://arxiv.org/abs/2510.21121
-
[60]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manip- ulation with low-cost hardware, 2023. URL https://arxiv. org/abs/2304.13705
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[61]
You only teach once: Learn one-shot bimanual robotic manipulation from video demonstrations, 2025
Huayi Zhou, Ruixiang Wang, Yunxin Tai, Yueci Deng, Guiliang Liu, and Kui Jia. You only teach once: Learn one-shot bimanual robotic manipulation from video demonstrations, 2025. URL https://arxiv.org/abs/ 2501.14208
-
[62]
Yifeng Zhu, Zhenyu Jiang, Peter Stone, and Yuke Zhu. Learning generalizable manipulation policies with object-centric 3d representations.arXiv preprint arXiv:2310.14386, 2023. APPENDIXA A. Hardware Setup Fig. 7: Hardware setup used in our experiments. The platform consists of a UR5e arm with a Robotiq 2F-85 gripper and an Intel RealSense L515 RGB-D camera...
-
[63]
capture range
Ablation 1: Effect of Egocentric Data Augmentation: a) Setting.:We compare two training settings: (i)w/ ego- aug, where we apply egocentric data augmentation to expand the dataset from 2 demonstrations to 50 demonstrations, and (ii)w/o ego-aug, where we train using only the original 2 demonstrations without augmentation. All other training and inference c...
-
[64]
Ablation 2: Egocentric vs. Fixed Camera Viewpoint: a) Setting.:To isolate the effect of observation view- point, we collect demonstrations with the egocentric camera and an external fixed camera mounted simultaneously. This yields paired observations for each timestep from identical trajectories, ensuring that the training data are matched and the only di...
-
[65]
in-distribution
Summary:Overall, the ablations highlight the impor- tance of egocentric design for robust multi-stage manipulation. Egocentric data augmentation substantially improves perfor- mance, particularly on long-horizon tasks, by broadening the training support and increasing tolerance to motion-field pose estimation errors and observation drift. Moreover, egocen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.