Recognition: unknown
LongBEL: Long-Context and Document-Consistent Biomedical Entity Linking
Pith reviewed 2026-05-14 19:21 UTC · model grok-4.3
The pith
LongBEL links biomedical mentions consistently across full documents by maintaining a memory of prior predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
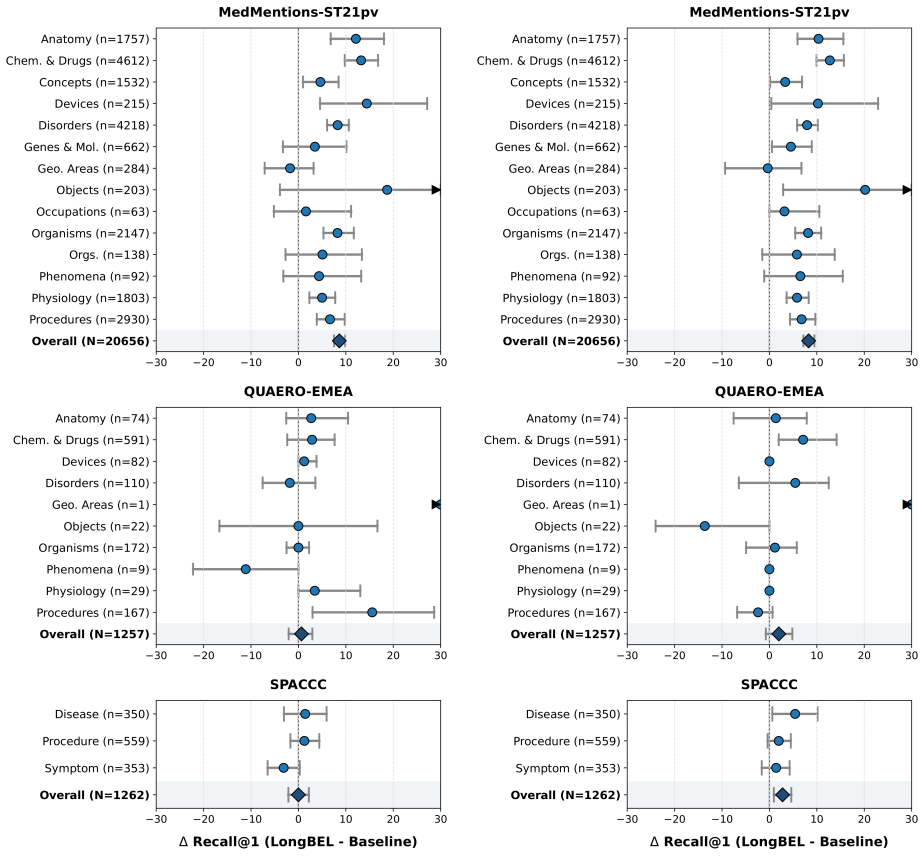
LongBEL is a document-level generative framework for biomedical entity linking that integrates full-document context with a memory module of previous predictions. The memory is trained using cross-validated predictions to minimize the train-inference discrepancy and reduce cascading errors. This leads to improved performance over sentence-level baselines, particularly on datasets with recurring concepts, and the best results come from ensembling variants.
What carries the argument
Memory module trained on cross-validated prior predictions, which carries document-level consistency by conditioning later linking decisions on earlier ones.
If this is right
- Largest gains occur on datasets where concepts frequently recur within documents.
- An ensemble of local, global, and memory-based variants achieves the best results across all benchmarks.
- Improvements primarily enhance document-level consistency rather than isolated mention disambiguation.
- The approach works across English, French, and Spanish biomedical benchmarks.
Where Pith is reading between the lines
- The memory training strategy may generalize to other sequential NLP tasks that require cross-mention consistency.
- Applying the same cross-validation trick could help memory-augmented models in domains like legal document analysis.
- Scalability tests on much longer clinical notes would reveal whether the memory mechanism saturates.
- Wider adoption might reduce terminology drift in electronic health record systems.
Load-bearing premise
Training the memory component exclusively with cross-validated predictions sufficiently reduces train-inference mismatch and prevents cascading errors without introducing new inconsistencies.
What would settle it
If LongBEL showed no improvement or degraded performance on a benchmark of documents containing only unique non-recurring concepts.
Figures





read the original abstract
Biomedical entity linking maps textual mentions to concepts in structured knowledge bases such as UMLS or SNOMED CT. Most existing systems link each mention independently, using only the mention or its surrounding sentence. This ignores dependencies between mentions in the same document and can lead to inconsistent predictions, especially when the same concept appears under different surface forms. We introduce LongBEL, a document-level generative framework that combines full-document context with a memory of previous predictions. To make this memory robust, LongBEL is trained with cross-validated predictions rather than gold labels, reducing the mismatch between training and inference and limiting cascading errors. Experiments on five biomedical benchmarks across English, French, and Spanish show that LongBEL improves over sentence-level generative baselines, with the largest gains on datasets where concepts frequently recur within documents. An ensemble of local, global, and memory-based variants achieves the best results across all benchmarks. Further analysis shows that the largest gains occur on recurring concepts, suggesting that LongBEL mainly improves document-level consistency rather than isolated mention disambiguation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LongBEL, a document-level generative framework for biomedical entity linking that combines full-document context with a memory of prior predictions. The memory component is trained on cross-validated predictions rather than gold labels to reduce train-inference mismatch and limit cascading errors. Experiments on five multilingual biomedical benchmarks (English, French, Spanish) report improvements over sentence-level generative baselines, with the largest gains on datasets featuring frequent concept recurrence; an ensemble of local, global, and memory-based variants yields the best results overall, and further analysis attributes gains primarily to improved document-level consistency on recurring concepts.
Significance. If the reported gains prove robust, LongBEL would advance document-consistent entity linking in biomedicine, where inconsistent predictions across surface forms of the same concept can degrade downstream applications such as knowledge-base population and clinical decision support. The multilingual scope and explicit focus on recurrence patterns provide a concrete empirical basis for the contribution.
major comments (3)
- [Abstract] Abstract and experimental results: the claim of 'consistent improvements' and 'largest gains on recurring concepts' is presented without statistical significance tests, confidence intervals, or run-to-run variance, leaving the strength of evidence for the central claim moderate.
- [Method] Method description of memory training: the use of cross-validated predictions to reduce train-inference mismatch is plausible but lacks detail on the number of folds, how held-out predictions are generated and filtered, and any safeguards against introducing new label noise; an ablation comparing cross-validated vs. gold-label memory training would directly test the weakest assumption.
- [Experiments] Experimental setup: exact baseline implementations, hyper-parameter matching, and error analysis (e.g., breakdown of consistency errors vs. isolated disambiguation errors) are not reported, making it difficult to isolate the contribution of the memory component.
minor comments (1)
- [Analysis] Clarify the precise definition of 'recurring concepts' used in the analysis (e.g., exact frequency threshold or document-level co-occurrence metric).
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each of the major comments below and will revise the paper accordingly to strengthen the presentation and evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental results: the claim of 'consistent improvements' and 'largest gains on recurring concepts' is presented without statistical significance tests, confidence intervals, or run-to-run variance, leaving the strength of evidence for the central claim moderate.
Authors: We agree that including statistical tests would strengthen the claims. In the revised version, we will report results with statistical significance tests (e.g., McNemar's test for paired comparisons) and confidence intervals. We will also include run-to-run variance from multiple random seeds to provide a more robust assessment of the improvements. revision: yes
-
Referee: [Method] Method description of memory training: the use of cross-validated predictions to reduce train-inference mismatch is plausible but lacks detail on the number of folds, how held-out predictions are generated and filtered, and any safeguards against introducing new label noise; an ablation comparing cross-validated vs. gold-label memory training would directly test the weakest assumption.
Authors: We will expand the method section to include the specific details: we use 5-fold cross-validation, generating predictions on held-out folds using models trained on the remaining data, and apply confidence thresholding to filter noisy predictions. We will also add the suggested ablation study comparing cross-validated memory training to gold-label training to empirically validate the approach and address potential concerns about label noise. revision: yes
-
Referee: [Experiments] Experimental setup: exact baseline implementations, hyper-parameter matching, and error analysis (e.g., breakdown of consistency errors vs. isolated disambiguation errors) are not reported, making it difficult to isolate the contribution of the memory component.
Authors: We will provide additional details on the exact implementations of the baselines, including code references or descriptions, and confirm hyperparameter matching. Furthermore, we will incorporate a detailed error analysis that categorizes errors into those related to document-level consistency (e.g., inconsistent predictions for recurring concepts) versus isolated disambiguation errors, allowing better isolation of the memory component's impact. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical method for biomedical entity linking that augments sentence-level generation with document context and a memory of prior predictions. Training the memory exclusively on cross-validated outputs is explicitly introduced to break train-inference dependence on gold labels, so the reported consistency gains do not reduce to a fitted input or self-definition. No mathematical derivations, uniqueness theorems, or load-bearing self-citations appear in the provided text; the central claims rest on benchmark experiments rather than any step that is equivalent to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journal of biomedical informatics , author =
An overview of. Journal of biomedical informatics , author =. 2023 , pages =. doi:10.1016/j.jbi.2022.104252 , abstract =
-
[2]
JMIR Medical Informatics , author =
Improving. JMIR Medical Informatics , author =. 2025 , note =. doi:10.2196/68704 , abstract =
-
[3]
Tang, Yuqing and Tran, Chau and Li, Xian and Chen, Peng-Jen and Goyal, Naman and Chaudhary, Vishrav and Gu, Jiatao and Fan, Angela , month = aug, year =. Multilingual. doi:10.48550/arXiv.2008.00401 , abstract =
-
[4]
Névéol, Aurélie and Grouin, Cyril and Leixa, Jeremy and Rosset, Sophie and Zweigenbaum, Pierre , year =. The. Proc of
-
[5]
Overview of
Miranda-Escalada, Antonio and Gasco, Luis and Lima-López, Salvador and Farré-Maduell, Eulàlia and Estrada, Darryl and Nentidis, Anastasios and Krithara, Anastasia and Katsimpras, Georgios and Paliouras, Georgios and Krallinger, Martin , year =. Overview of. Working
-
[6]
Overview of. Proceedings of the BioCreative VIII Challenge and Workshop: Curation and Evaluation in the Era of Generative Models , month = nov, year =. doi:10.5281/zenodo.10104547 , author =
-
[7]
Cormack, Gordon V. and Clarke, Charles L A and Buettcher, Stefan , month = jul, year =. Reciprocal rank fusion outperforms condorcet and individual rank learning methods , isbn =. Proceedings of the 32nd international. doi:10.1145/1571941.1572114 , abstract =
-
[8]
Liu, Fangyu and Vulić, Ivan and Korhonen, Anna and Collier, Nigel , editor =. Learning. Proceedings of the 59th. 2021 , pages =. doi:10.18653/v1/2021.acl-short.72 , abstract =
-
[9]
Working Notes of CLEF , author =
Overview of. Working Notes of CLEF , author =
-
[10]
Nucleic Acids Research , author =
The. Nucleic Acids Research , author =. 2004 , pmid =. doi:10.1093/nar/gkh061 , abstract =
-
[11]
Medical and
Donnelly, Kevin , year =. Medical and
-
[12]
Journal of Biomedical Informatics , author =
Term identification in the biomedical literature , volume =. Journal of Biomedical Informatics , author =. 2004 , keywords =. doi:10.1016/j.jbi.2004.08.004 , abstract =
-
[13]
Wu, Ledell and Petroni, Fabio and Josifoski, Martin and Riedel, Sebastian and Zettlemoyer, Luke , editor =. Scalable. Proceedings of the 2020. 2020 , pages =. doi:10.18653/v1/2020.emnlp-main.519 , abstract =
-
[14]
Sakhovskiy, Andrey and Semenova, Natalia and Kadurin, Artur and Tutubalina, Elena , editor =. Biomedical. Findings of the. 2024 , pages =. doi:10.18653/v1/2024.findings-naacl.288 , abstract =
-
[15]
Journal of Biomedical Informatics , author =
A comprehensive survey on medical concept normalization:. Journal of Biomedical Informatics , author =. 2026 , keywords =. doi:10.1016/j.jbi.2026.105005 , abstract =
-
[16]
Schwartz, Ariel S. and Hearst, Marti A. , month = dec, year =. A simple algorithm for identifying abbreviation definitions in biomedical text , isbn =. Biocomputing 2003 , publisher =. doi:10.1142/9789812776303_0042 , urldate =
-
[17]
Liu, Fangyu and Shareghi, Ehsan and Meng, Zaiqiao and Basaldella, Marco and Collier, Nigel , year =. Self-. Proceedings of the 2021. doi:10.18653/v1/2021.naacl-main.334 , abstract =
-
[18]
Agarwal, Dhruv and Angell, Rico and Monath, Nicholas and McCallum, Andrew , editor =. Entity. Proceedings of the 2022. doi:10.18653/v1/2022.naacl-main.343 , abstract =
-
[19]
Yuan, Hongyi and Yuan, Zheng and Yu, Sheng , editor =. Generative. Proceedings of the 2022. 2022 , pages =. doi:10.18653/v1/2022.naacl-main.296 , abstract =
-
[20]
Learning from
Kim, Chanhwi and Kim, Hyunjae and Park, Sihyeon and Lee, Jiwoo and Sung, Mujeen and Kang, Jaewoo , editor =. Learning from. Findings of the. 2025 , pages =
2025
-
[21]
Shlyk, Darya and Groza, Tudor and Mesiti, Marco and Montanelli, Stefano and Cavalleri, Emanuele , editor =. Proceedings of the 23rd. 2024 , pages =. doi:10.18653/v1/2024.bionlp-1.29 , abstract =
-
[22]
Local and
Ratinov, Lev and Roth, Dan and Downey, Doug and Anderson, Mike , editor =. Local and. Proceedings of the 49th. 2011 , pages =
2011
-
[23]
SynCABEL: Synthetic Contextualized Augmentation for Biomedical Entity Linking
Remaki, Adam and Gérardin, Christel and Farré-Maduell, Eulàlia and Krallinger, Martin and Tannier, Xavier , month = jan, year =. doi:10.48550/arXiv.2601.19667 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.19667
-
[24]
Ganea, Octavian-Eugen and Hofmann, Thomas , editor =. Deep. Proceedings of the 2017. 2017 , pages =. doi:10.18653/v1/D17-1277 , abstract =
-
[25]
Contextual
Vollmers, Daniel and Zahera, Hamada and Moussallem, Diego and Ngonga Ngomo, Axel-Cyrille , editor =. Contextual. Proceedings of the 31st. 2025 , pages =
2025
-
[26]
doi:10.48550/arXiv.2402.06738 , abstract =
Ding, Yifan and Poudel, Amrit and Zeng, Qingkai and Weninger, Tim and Veeramani, Balaji and Bhattacharya, Sanmitra , month = may, year =. doi:10.48550/arXiv.2402.06738 , abstract =
-
[27]
Ai, Yihao and Ning, Zhiyuan and Dai, Weiwei and Wang, Pengfei and Du, Yi and Cui, Wenjuan and Liu, Kunpeng and Zhou, Yuanchun , editor =. Distilling. Advanced. 2025 , keywords =. doi:10.1007/978-981-95-0027-7_9 , abstract =
-
[28]
Ye, Christophe and Mitchell, Cassie S. , editor =. Proceedings of the 63rd. 2025 , pages =. doi:10.18653/v1/2025.acl-short.25 , abstract =
-
[29]
Improving biomedical entity linking for complex entity mentions with. Database , author =. 2024 , pages =. doi:10.1093/database/baae067 , abstract =
-
[30]
Proceedings of the 31st
Zhu, Lixing and Wang, Jun and He, Yulan , editor =. Proceedings of the 31st. 2025 , pages =
2025
-
[31]
Neumann, Mark and King, Daniel and Beltagy, Iz and Ammar, Waleed , editor =. Proceedings of the 18th. 2019 , pages =. doi:10.18653/v1/W19-5034 , abstract =
-
[32]
Journal of the American Medical Informatics Association , author =
An overview of. Journal of the American Medical Informatics Association , author =. 2010 , pages =. doi:10.1136/jamia.2009.002733 , abstract =
-
[33]
Journal of the American Medical Informatics Association , author =
Mayo clinical. Journal of the American Medical Informatics Association , author =. 2010 , pages =. doi:10.1136/jamia.2009.001560 , abstract =
-
[34]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and others , month = nov, year =. The. doi:10.48550/arXiv.2407.21783 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783
-
[35]
MedMentions: A Large Biomedical Corpus Annotated with UMLS Concepts
Mohan, Sunil and Li, Donghui , month = feb, year =. doi:10.48550/arXiv.1902.09476 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1902.09476 1902
-
[36]
Wang, Fang and Tao, Zhengwei and Wang, Ming and Hu, Minghao and Bai, Xiaoying , editor =. Findings of the. 2025 , pages =. doi:10.18653/v1/2025.findings-emnlp.231 , abstract =
-
[37]
Hou, Jiajun and Zhang, Chenyu and Meng, Rui , editor =. Harnessing. Advanced. 2026 , pages =. doi:10.1007/978-981-95-3453-1_30 , abstract =
-
[38]
Proceedings of the 2024
Ding, Yifan and Zeng, Qingkai and Weninger, Tim , editor =. Proceedings of the 2024. 2024 , annote =
2024
-
[39]
Xin, Amy and Qi, Yunjia and Yao, Zijun and Zhu, Fangwei and Zeng, Kaisheng and Xu, Bin and Hou, Lei and Li, Juanzi , year =. Proceedings of the 34th. doi:10.1145/3746252.3761156 , abstract =
-
[40]
Lin, Zhenxi and Zhang, Ziheng and Wu, Jian and Zheng, Yefeng and Wu, Xian , editor =. Guiding. Findings of the. 2025 , pages =. doi:10.18653/v1/2025.findings-emnlp.1292 , abstract =
-
[41]
Autoregressive
Cao, Nicola De and Izacard, Gautier and Riedel, Sebastian and Petroni, Fabio , month = oct, year =. Autoregressive
-
[42]
Journal of Biomedical Informatics , author =. 2022 , keywords =. doi:10.1016/j.jbi.2021.103983 , abstract =
-
[43]
Xie, Yuzhang and Lu, Jiaying and Ho, Joyce and Nahab, Fadi and Hu, Xiao and Yang, Carl , month = jul, year =. Proceedings of the 47th. doi:10.1145/3626772.3657904 , abstract =
-
[44]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[45]
Publications Manual , year = "1983", publisher =
1983
-
[46]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[47]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[48]
Dan Gusfield , title =. 1997
1997
-
[49]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[50]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.