Recognition: 2 theorem links
· Lean TheoremCUBic: Coordinated Unified Bimanual Perception and Control Framework
Pith reviewed 2026-05-14 19:02 UTC · model grok-4.3
The pith
CUBic unifies bimanual robot perception and control in a shared tokenized representation where independence and coordination arise from structure alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
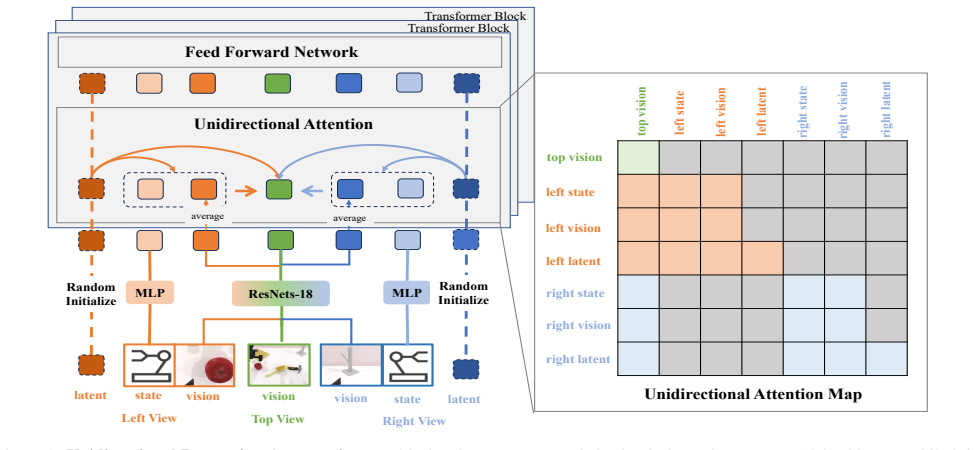
CUBic reformulates bimanual coordination as a unified perceptual modeling problem. It learns a shared tokenized representation that bridges perception and control, so that independence and coordination emerge intrinsically from the structure rather than from hand-crafted coupling mechanisms. The approach combines unidirectional perception aggregation, bidirectional perception coordination through two codebooks that share a mapping, and a single perception-to-control diffusion policy.
What carries the argument
Shared tokenized representation formed by unidirectional perception aggregation and bidirectional coordination via two codebooks with shared mapping.
If this is right
- Bimanual tasks can be solved with higher coordination accuracy without explicit inter-arm coupling mechanisms.
- Task success rates rise on the RoboTwin benchmark relative to decoupled or strongly coupled visuomotor baselines.
- Perception and control are handled inside one diffusion policy that operates on the shared tokenized representation.
- The same structural design supports both independent arm motion and coordinated interaction without separate modules.
Where Pith is reading between the lines
- The tokenized approach could be tested on multi-robot teams to see whether similar emergence of coordination occurs at larger scale.
- Removing the need for hand-crafted coupling rules may shorten the engineering effort required to adapt the method to new bimanual tasks.
- Applying the framework to real physical robots would show whether the benchmark gains persist outside simulation.
Load-bearing premise
The shared tokenized representation produced by unidirectional aggregation and bidirectional codebook coordination will let both arm independence and coordination appear on their own without any added coupling rules.
What would settle it
Running the same benchmark tasks after removing the bidirectional codebook coordination and finding no drop in coordination accuracy or task success rates compared with the full model.
Figures



read the original abstract
Recent advances in visuomotor policy learning have enabled robots to perform control directly from visual inputs. Yet, extending such end-to-end learning from single-arm to bimanual manipulation remains challenging due to the need for both independent perception and coordinated interaction between arms. Existing methods typically favor one side -- either decoupling the two arms to avoid interference or enforcing strong cross-arm coupling for coordination -- thus lacking a unified treatment. We propose CUBic, a Coordinated and Unified framework for Bimanual perception and control that reformulates bimanual coordination as a unified perceptual modeling problem. CUBic learns a shared tokenized representation bridging perception and control, where independence and coordination emerge intrinsically from structure rather than from hand-crafted coupling. Our approach integrates three components: unidirectional perception aggregation, bidirectional perception coordination through two codebooks with shared mapping, and a unified perception-to-control diffusion policy. Extensive experiments on the RoboTwin benchmark show that CUBic consistently surpasses standard baselines, achieving marked improvements in coordination accuracy and task success rates over state-of-the-art visuomotor baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CUBic, a Coordinated Unified Bimanual Perception and Control Framework that reformulates bimanual coordination as a unified perceptual modeling problem. It introduces a shared tokenized representation learned via unidirectional perception aggregation, bidirectional perception coordination through two codebooks with shared mapping, and a unified perception-to-control diffusion policy. The central claim is that independence and coordination emerge intrinsically from this structure without hand-crafted coupling mechanisms, with extensive experiments on the RoboTwin benchmark showing consistent outperformance over state-of-the-art visuomotor baselines in coordination accuracy and task success rates.
Significance. If the empirical results hold with proper validation, the work offers a potentially simplifying architectural alternative for bimanual visuomotor policies by avoiding explicit inter-arm coupling, which could advance end-to-end learning for dual-arm systems. The integration of tokenized representations and diffusion policies follows current trends but applies them in a unified bimanual setting.
major comments (2)
- [Abstract] Abstract: the claim that CUBic 'consistently surpasses standard baselines' and achieves 'marked improvements in coordination accuracy and task success rates' on RoboTwin supplies no quantitative results, error bars, ablation tables, baseline implementation details, or statistical tests. This absence renders the central empirical claim unverifiable and load-bearing for the paper's contribution.
- [Methods] The description of bidirectional codebook coordination and shared mapping (implicit in the methods) lacks explicit equations defining the codebook training objective, the shared mapping function, or how unidirectional aggregation interacts with the diffusion policy. Without these, it is impossible to verify the claim that independence and coordination emerge intrinsically from structure rather than from fitted parameters or hand-crafted elements.
minor comments (1)
- [Abstract] Clarify the precise meaning of 'unidirectional perception aggregation' and 'bidirectional perception coordination' with a short definition or pointer to the relevant algorithmic description.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive feedback on our manuscript. We address the major comments below and have revised the paper accordingly to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that CUBic 'consistently surpasses standard baselines' and achieves 'marked improvements in coordination accuracy and task success rates' on RoboTwin supplies no quantitative results, error bars, ablation tables, baseline implementation details, or statistical tests. This absence renders the central empirical claim unverifiable and load-bearing for the paper's contribution.
Authors: We agree with the referee that the abstract would benefit from including quantitative highlights to support the claims. In the revised version, we have incorporated key performance metrics from the RoboTwin experiments, such as the coordination accuracy and task success rates with comparisons to baselines, along with pointers to the full tables, error bars, and statistical details in the main body of the paper. This addresses the verifiability concern while keeping the abstract concise. revision: yes
-
Referee: [Methods] The description of bidirectional codebook coordination and shared mapping (implicit in the methods) lacks explicit equations defining the codebook training objective, the shared mapping function, or how unidirectional aggregation interacts with the diffusion policy. Without these, it is impossible to verify the claim that independence and coordination emerge intrinsically from structure rather than from fitted parameters or hand-crafted elements.
Authors: We appreciate this observation and have added explicit equations in the revised methods section for the codebook training objective (including commitment and reconstruction losses), the shared mapping function between codebooks, and the interaction with unidirectional aggregation and the diffusion policy. These additions clarify how independence and coordination emerge intrinsically from the structure, as supported by the ablations. revision: yes
Circularity Check
No circularity in architectural proposal
full rationale
The paper introduces CUBic as a new framework with three components: unidirectional perception aggregation, bidirectional coordination via two codebooks with shared mapping, and a unified perception-to-control diffusion policy. No equations, derivations, or fitted parameters are presented in the abstract or description that would reduce the claimed coordination emergence or performance gains to quantities defined by construction within the paper. The method is framed as an architectural choice rather than a self-referential fit or prediction derived from its own inputs. Experimental claims on RoboTwin are external validation, not internal reductions. No self-citation chains or uniqueness theorems are invoked in the provided text to bear the central load.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CUBic learns a shared tokenized representation bridging perception and control, where independence and coordination emerge intrinsically from structure rather than from hand-crafted coupling... bidirectional perception coordination through two codebooks with shared mapping
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
unidirectional perception aggregation... bidirectional perception coordination... unified perception-to-control diffusion policy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Hongzhe Bi, Lingxuan Wu, Tianwei Lin, Hengkai Tan, Zhizhong Su, Hang Su, and Jun Zhu. H-rdt: Human ma- nipulation enhanced bimanual robotic manipulation.arXiv preprint arXiv:2507.23523, 2025. 6
-
[2]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky.π 0: A visi...
2024
-
[3]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent ac- tions.arXiv preprint arXiv:2505.06111, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Xiaoyu Chen, Hangxing Wei, Pushi Zhang, Chuheng Zhang, Kaixin Wang, Yanjiang Guo, Rushuai Yang, Yucen Wang, Xinquan Xiao, Li Zhao, et al. Villa-x: enhancing latent action modeling in vision-language-action models.arXiv preprint arXiv:2507.23682, 2025
-
[5]
Moto: Latent mo- tion token as the bridging language for learning robot ma- nipulation from videos
Yi Chen, Yuying Ge, Weiliang Tang, Yizhuo Li, Yixiao Ge, Mingyu Ding, Ying Shan, and Xihui Liu. Moto: Latent mo- tion token as the bridging language for learning robot ma- nipulation from videos. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 19752–19763, 2025. 3
2025
-
[6]
Diffusion policy: Visuomotor policy learning via action dif- fusion.The International Journal of Robotics Research,
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action dif- fusion.The International Journal of Robotics Research,
-
[7]
Efficient bimanual manipulation using learned task schemas
Rohan Chitnis, Shubham Tulsiani, Saurabh Gupta, and Ab- hinav Gupta. Efficient bimanual manipulation using learned task schemas. In2020 IEEE International Conference on Robotics and Automation (ICRA), pages 1149–1155. IEEE,
-
[8]
Dynamo: In-domain dynamics pretraining for visuo-motor control.Advances in Neural Information Processing Systems, 37:33933–33961, 2024
Zichen Cui, Hengkai Pan, Aadhithya Iyer, Siddhant Haldar, and Lerrel Pinto. Dynamo: In-domain dynamics pretraining for visuo-motor control.Advances in Neural Information Processing Systems, 37:33933–33961, 2024. 3
2024
-
[9]
Safebimanual: Diffusion-based trajectory optimization for safe bimanual manipulation, 2025
Haoyuan Deng, Wenkai Guo, Qianzhun Wang, Zhenyu Wu, and Ziwei Wang. Safebimanual: Diffusion-based trajectory optimization for safe bimanual manipulation, 2025. 1
2025
-
[10]
Interactive imitation learn- ing of bimanual movement primitives.IEEE/ASME Trans- actions on Mechatronics, 2023
Giovanni Franzese, Leandro de Souza Rosa, Tim Verburg, Luka Peternel, and Jens Kober. Interactive imitation learn- ing of bimanual movement primitives.IEEE/ASME Trans- actions on Mechatronics, 2023. 2
2023
-
[11]
Cord- vip: Correspondence-based visuomotor policy for dexterous manipulation in real-world, 2025
Yankai Fu, Qiuxuan Feng, Ning Chen, Zichen Zhou, Mengzhen Liu, Mingdong Wu, Tianxing Chen, Shanyu Rong, Jiaming Liu, Hao Dong, and Shanghang Zhang. Cord- vip: Correspondence-based visuomotor policy for dexterous manipulation in real-world, 2025. 1
2025
-
[12]
Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation
Zipeng Fu, Tony Z Zhao, and Chelsea Finn. Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation.arXiv preprint arXiv:2401.02117,
work page internal anchor Pith review arXiv
-
[13]
Vita: Vision-to-action flow matching policy, 2026
Dechen Gao, Boqi Zhao, Andrew Lee, Ian Chuang, Hanchu Zhou, Hang Wang, Zhe Zhao, Junshan Zhang, and Iman Soltani. Vita: Vision-to-action flow matching policy, 2026. 1
2026
-
[14]
Bi-kvil: Keypoints-based visual imitation learning of bimanual manipulation tasks
Jianfeng Gao, Xiaoshu Jin, Franziska Krebs, No ´emie Jaquier, and Tamim Asfour. Bi-kvil: Keypoints-based visual imitation learning of bimanual manipulation tasks. In2024 IEEE international conference on robotics and automation (ICRA), pages 16850–16857. IEEE, 2024. 2
2024
-
[15]
Dag-plan: Generating directed acyclic de- pendency graphs for dual-arm cooperative planning, 2025
Zeyu Gao, Yao Mu, Jinye Qu, Mengkang Hu, Shijia Peng, Chengkai Hou, Lingyue Guo, Ping Luo, Shanghang Zhang, and Yanfeng Lu. Dag-plan: Generating directed acyclic de- pendency graphs for dual-arm cooperative planning, 2025. 1
2025
-
[16]
3d flowmatch actor: Unified 3d policy for single- and dual-arm manipulation, 2025
Nikolaos Gkanatsios, Jiahe Xu, Matthew Bronars, Arsalan Mousavian, Tsung-Wei Ke, and Katerina Fragkiadaki. 3d flowmatch actor: Unified 3d policy for single- and dual-arm manipulation, 2025. 1
2025
-
[17]
Carp: Visuomotor policy learning via coarse-to-fine autore- gressive prediction, 2025
Zhefei Gong, Pengxiang Ding, Shangke Lyu, Siteng Huang, Mingyang Sun, Wei Zhao, Zhaoxin Fan, and Donglin Wang. Carp: Visuomotor policy learning via coarse-to-fine autore- gressive prediction, 2025. 3
2025
-
[18]
Stabilize to act: Learning to coordinate for bimanual manip- ulation
Jennifer Grannen, Yilin Wu, Brandon Vu, and Dorsa Sadigh. Stabilize to act: Learning to coordinate for bimanual manip- ulation. InConference on Robot Learning, pages 563–576. PMLR, 2023. 1, 2, 3
2023
-
[19]
Peract2: Benchmarking and learn- ing for robotic bimanual manipulation tasks
Markus Grotz, Mohit Shridhar, Yu-Wei Chao, Tamim As- four, and Dieter Fox. Peract2: Benchmarking and learn- ing for robotic bimanual manipulation tasks. InCoRL 2024 Workshop on Whole-body Control and Bimanual Manipula- tion: Applications in Humanoids and Beyond, 2024. 1, 2
2024
-
[20]
Maniskill2: A unified benchmark for generalizable manipulation skills
Jiayuan Gu, Fanbo Xiang, Xuanlin Li, Zhan Ling, Xiqiang Liu, Tongzhou Mu, Yihe Tang, Stone Tao, Xinyue Wei, Yun- chao Yao, Xiaodi Yuan, Pengwei Xie, Zhiao Huang, Rui Chen, and Hao Su. Maniskill2: A unified benchmark for generalizable manipulation skills. InInternational Confer- ence on Learning Representations, 2023. 2, 6
2023
-
[21]
Denoising Diffusion Probabilistic Models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models.arXiv preprint arxiv:2006.11239,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[22]
Sampling-based optimization with parallelized physics simulator for bimanual manipulation, 2025
Iryna Hurova, Alinjar Dan, Karl Kruusam ¨ae, and Arun Ku- mar Singh. Sampling-based optimization with parallelized physics simulator for bimanual manipulation, 2025. 1
2025
-
[23]
Twinvla: Data-efficient bimanual manip- ulation with twin single-arm vision-language-action models,
Hokyun Im, Euijin Jeong, Andrey Kolobov, Jianlong Fu, and Youngwoon Lee. Twinvla: Data-efficient bimanual manip- ulation with twin single-arm vision-language-action models,
-
[24]
Lift3d policy: Lifting 2d foundation models for robust 3d robotic manipu- lation
Yueru Jia, Jiaming Liu, Sixiang Chen, Chenyang Gu, Zhilve Wang, Longzan Luo, Xiaoqi Li, Pengwei Wang, Zhongyuan Wang, Renrui Zhang, and Shanghang Zhang. Lift3d policy: Lifting 2d foundation models for robust 3d robotic manipu- lation. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 17347– 17358, 2025. 1
2025
-
[25]
3d diffuser actor: Policy diffusion with 3d scene rep- resentations.Arxiv, 2024
Tsung-Wei Ke, Nikolaos Gkanatsios, and Katerina Fragki- adaki. 3d diffuser actor: Policy diffusion with 3d scene rep- resentations.Arxiv, 2024. 1
2024
-
[26]
Interact: Inter-dependency aware action chunking with hierarchical attention transformers for bimanual manip- ulation, 2024
Andrew Lee, Ian Chuang, Ling-Yuan Chen, and Iman Soltani. Interact: Inter-dependency aware action chunking with hierarchical attention transformers for bimanual manip- ulation, 2024. 1, 2
2024
-
[27]
Autoregressive image generation using residual quantization
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. Autoregressive image generation using residual quantization. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 11523–11532, 2022. 5
2022
-
[28]
Momagen: Generating demonstrations under soft and hard constraints for multi-step bimanual mobile manipulation, 2026
Chengshu Li, Mengdi Xu, Arpit Bahety, Hang Yin, Yunfan Jiang, Huang Huang, Josiah Wong, Sujay Garlanka, Cem Gokmen, Ruohan Zhang, Weiyu Liu, Jiajun Wu, Roberto Mart´ın-Mart´ın, and Li Fei-Fei. Momagen: Generating demonstrations under soft and hard constraints for multi-step bimanual mobile manipulation, 2026. 1
2026
-
[29]
Gr-mg: Leveraging partially annotated data via multi-modal goal-conditioned policy, 2024
Peiyan Li, Hongtao Wu, Yan Huang, Chilam Cheang, Liang Wang, and Tao Kong. Gr-mg: Leveraging partially annotated data via multi-modal goal-conditioned policy, 2024. 6, 7
2024
-
[30]
I Liu, Chun Arthur, Sicheng He, Daniel Seita, and Gau- rav Sukhatme. V oxact-b: V oxel-based acting and stabi- lizing policy for bimanual manipulation.arXiv preprint arXiv:2407.04152, 2024. 1, 2
-
[31]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipu- lation.arXiv preprint arXiv:2410.07864, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Guanxing Lu, Tengbo Yu, Haoyuan Deng, Season Si Chen, Yansong Tang, and Ziwei Wang. Anybimanual: Transferring unimanual policy for general bimanual manipulation.arXiv preprint arXiv:2412.06779, 2024. 1, 2, 3
-
[33]
H 3dp: Triply- hierarchical diffusion policy for visuomotor learning, 2025
Yiyang Lu, Yufeng Tian, Zhecheng Yuan, Xianbang Wang, Pu Hua, Zhengrong Xue, and Huazhe Xu. H 3dp: Triply- hierarchical diffusion policy for visuomotor learning, 2025. 3, 6
2025
-
[34]
Spatial-temporal graph diffusion policy with kinematic mod- eling for bimanual robotic manipulation
Qi Lv, Hao Li, Xiang Deng, Rui Shao, Yinchuan Li, Jianye Hao, Longxiang Gao, Michael Yu Wang, and Liqiang Nie. Spatial-temporal graph diffusion policy with kinematic mod- eling for bimanual robotic manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17394–17404, 2025. 1
2025
-
[35]
Hierarchical diffusion policy for kinematics-aware multi- task robotic manipulation
Xiao Ma, Sumit Patidar, Iain Haughton, and Stephen James. Hierarchical diffusion policy for kinematics-aware multi- task robotic manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18081–18090, 2024. 1
2024
-
[36]
Learning bi- manual manipulation via action chunking and inter-arm co- ordination with transformers, 2025
Tomohiro Motoda, Ryo Hanai, Ryoichi Nakajo, Masaki Murooka, Floris Erich, and Yukiyasu Domae. Learning bi- manual manipulation via action chunking and inter-arm co- ordination with transformers, 2025. 1
2025
-
[37]
Robotwin: Dual-arm robot benchmark with gen- erative digital twins
Yao Mu, Tianxing Chen, Zanxin Chen, Shijia Peng, Zhiqian Lan, Zeyu Gao, Zhixuan Liang, Qiaojun Yu, Yude Zou, Mingkun Xu, Lunkai Lin, Zhiqiang Xie, Mingyu Ding, and Ping Luo. Robotwin: Dual-arm robot benchmark with gen- erative digital twins. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 27649– 27660, 2025. 2, 6, 8
2025
-
[38]
3d flow diffusion policy: Visuomotor policy learning via gener- ating flow in 3d space, 2025
Sangjun Noh, Dongwoo Nam, Kangmin Kim, Geonhyup Lee, Yeonguk Yu, Raeyoung Kang, and Kyoobin Lee. 3d flow diffusion policy: Visuomotor policy learning via gener- ating flow in 3d space, 2025. 1
2025
-
[39]
Omnimanip: Towards general robotic manipulation via object-centric interaction primitives as spatial constraints
Mingjie Pan, Jiyao Zhang, Tianshu Wu, Yinghao Zhao, Wen- long Gao, and Hao Dong. Omnimanip: Towards general robotic manipulation via object-centric interaction primitives as spatial constraints. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17359–17369, 2025. 1
2025
-
[40]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers.arXiv preprint arXiv:2212.09748, 2022. 6
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
Tokenflow: Unified image tokenizer for multi- modal understanding and generation
Liao Qu, Huichao Zhang, Yiheng Liu, Xu Wang, Yi Jiang, Yiming Gao, Hu Ye, Daniel K Du, Zehuan Yuan, and Xin- glong Wu. Tokenflow: Unified image tokenizer for multi- modal understanding and generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2545–2555, 2025. 3
2025
-
[42]
Learning to act without actions.arXiv preprint arXiv:2312.10812, 2023
Dominik Schmidt and Minqi Jiang. Learning to act without actions.arXiv preprint arXiv:2312.10812, 2023. 3
-
[43]
Biassem- ble: Learning collaborative affordance for bimanual geomet- ric assembly, 2025
Yan Shen, Ruihai Wu, Yubin Ke, Xinyuan Song, Zeyi Li, Xi- aoqi Li, Hongwei Fan, Haoran Lu, and Hao dong. Biassem- ble: Learning collaborative affordance for bimanual geomet- ric assembly, 2025. 1
2025
-
[44]
Denois- ing diffusion implicit models, 2022
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models, 2022. 6
2022
-
[45]
Dense policy: Bidirectional autoregressive learning of actions
Yue Su, Xinyu Zhan, Hongjie Fang, Han Xue, Hao-Shu Fang, Yong-Lu Li, Cewu Lu, and Lixin Yang. Dense policy: Bidirectional autoregressive learning of actions. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 14486–14495, 2025. 2
2025
-
[46]
Dspv2: Improved dense policy for effective and generalizable whole-body mobile manipulation, 2025
Yue Su, Chubin Zhang, Sijin Chen, Liufan Tan, Yansong Tang, Jianan Wang, and Xihui Liu. Dspv2: Improved dense policy for effective and generalizable whole-body mobile manipulation, 2025. 2
2025
-
[47]
Anypos: Au- tomated task-agnostic actions for bimanual manipulation,
Hengkai Tan, Yao Feng, Xinyi Mao, Shuhe Huang, Guodong Liu, Zhongkai Hao, Hang Su, and Jun Zhu. Anypos: Au- tomated task-agnostic actions for bimanual manipulation,
-
[48]
Vitas: Visual tactile soft fusion contrastive learning for visuomotor learning, 2026
Yufeng Tian, Shuiqi Cheng, Tianming Wei, Tianxing Zhou, Yuanhang Zhang, Zixian Liu, Qianwei Han, Zhecheng Yuan, and Huazhe Xu. Vitas: Visual tactile soft fusion contrastive learning for visuomotor learning, 2026. 2
2026
-
[49]
Vq-vla: Improving vision- language-action models via scaling vector-quantized action tokenizers
Yating Wang, Haoyi Zhu, Mingyu Liu, Jiange Yang, Hao- Shu Fang, and Tong He. Vq-vla: Improving vision- language-action models via scaling vector-quantized action tokenizers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11089– 11099, 2025. 3
2025
-
[50]
Unleashing large-scale video generative pre-training for visual robot manipulation, 2023
Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, and Tao Kong. Unleashing large-scale video generative pre-training for visual robot manipulation, 2023. 6
2023
-
[51]
Robocoin: An open-sourced bimanual robotic data collection for integrated manipulation, 2025
Shihan Wu, Xuecheng Liu, Shaoxuan Xie, Pengwei Wang, Xinghang Li, Bowen Yang, Zhe Li, Kai Zhu, Hongyu Wu, Yiheng Liu, Zhaoye Long, Yue Wang, Chong Liu, Dihan Wang, Ziqiang Ni, Xiang Yang, You Liu, Ruoxuan Feng, Runtian Xu, Lei Zhang, Denghang Huang, Chenghao Jin, Anlan Yin, Xinlong Wang, Zhenguo Sun, Junkai Zhao, Mengfei Du, Mingyu Cao, Xiansheng Chen, Ho...
2025
-
[52]
Deep imita- tion learning for bimanual robotic manipulation.Advances in neural information processing systems, 33:2327–2337,
Fan Xie, Alexander Chowdhury, M De Paolis Kaluza, Lin- feng Zhao, Lawson Wong, and Rose Yu. Deep imita- tion learning for bimanual robotic manipulation.Advances in neural information processing systems, 33:2327–2337,
-
[53]
Diffusion-based imaginative coordination for bimanual manipulation, 2025
Huilin Xu, Jian Ding, Jiakun Xu, Ruixiang Wang, Jun Chen, Jinjie Mai, Yanwei Fu, Bernard Ghanem, Feng Xu, and Mo- hamed Elhoseiny. Diffusion-based imaginative coordination for bimanual manipulation, 2025. 1, 6
2025
-
[54]
Hang Xu, Yizhou Chen, Dongjie Yu, Yi Ren, and Jia Pan. Bikc+: Bimanual hierarchical imitation with keypose- conditioned coordination-aware consistency policies.IEEE Transactions on Automation Science and Engineering, 23: 1064–1079, 2026. 1
2026
-
[55]
Speci: Skill prompts based hi- erarchical continual imitation learning for robot manipula- tion.IEEE Transactions on Cognitive and Developmental Systems, 2025
Jingkai Xu and Xiangli Nie. Speci: Skill prompts based hi- erarchical continual imitation learning for robot manipula- tion.IEEE Transactions on Cognitive and Developmental Systems, 2025. 2
2025
-
[56]
Gripper keypose and object pointflow as interfaces for bimanual robotic manipulation, 2025
Yuyin Yang, Zetao Cai, Yang Tian, Jia Zeng, and Jiangmiao Pang. Gripper keypose and object pointflow as interfaces for bimanual robotic manipulation, 2025. 1
2025
-
[57]
Latent Action Pretraining from Videos
Seonghyeon Ye, Joel Jang, Byeongguk Jeon, Sejune Joo, Jianwei Yang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Yu-Wei Chao, Bill Yuchen Lin, et al. Latent action pretrain- ing from videos.arXiv preprint arXiv:2410.11758, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
3d diffusion policy: Gen- eralizable visuomotor policy learning via simple 3d repre- sentations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Gen- eralizable visuomotor policy learning via simple 3d repre- sentations. InProceedings of Robotics: Science and Systems (RSS), 2024. 1, 2, 3, 6, 7
2024
-
[59]
Gener- alizable humanoid manipulation with 3d diffusion policies
Yanjie Ze, Zixuan Chen, Wenhao Wang, Tianyi Chen, Xi- alin He, Ying Yuan, Xue Bin Peng, and Jiajun Wu. Gener- alizable humanoid manipulation with 3d diffusion policies. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2873–2880, 2025
2025
-
[60]
Flowpolicy: Enabling fast and robust 3d flow-based policy via consistency flow match- ing for robot manipulation, 2024
Qinglun Zhang, Zhen Liu, Haoqiang Fan, Guanghui Liu, Bing Zeng, and Shuaicheng Liu. Flowpolicy: Enabling fast and robust 3d flow-based policy via consistency flow match- ing for robot manipulation, 2024. 1
2024
-
[61]
You only teach once: Learn one-shot bimanual robotic manipulation from video demonstrations, 2025
Huayi Zhou, Ruixiang Wang, Yunxin Tai, Yueci Deng, Guil- iang Liu, and Kui Jia. You only teach once: Learn one-shot bimanual robotic manipulation from video demonstrations. arXiv preprint arXiv:2501.14208, 2025. 2
-
[62]
Learning generalizable manipulation policies with object- centric 3d representations, 2023
Yifeng Zhu, Zhenyu Jiang, Peter Stone, and Yuke Zhu. Learning generalizable manipulation policies with object- centric 3d representations, 2023. 1
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.