Recognition: 2 theorem links
· Lean TheoremDiscovery of Hidden Miscalibration Regimes
Pith reviewed 2026-05-14 20:42 UTC · model grok-4.3
The pith
Calibration errors in LLMs depend on input type and can be found without predefined groups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
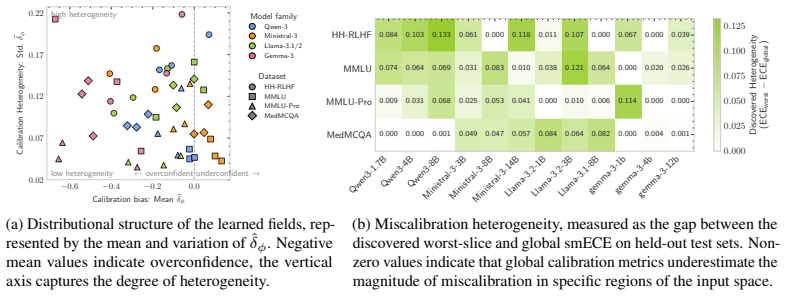
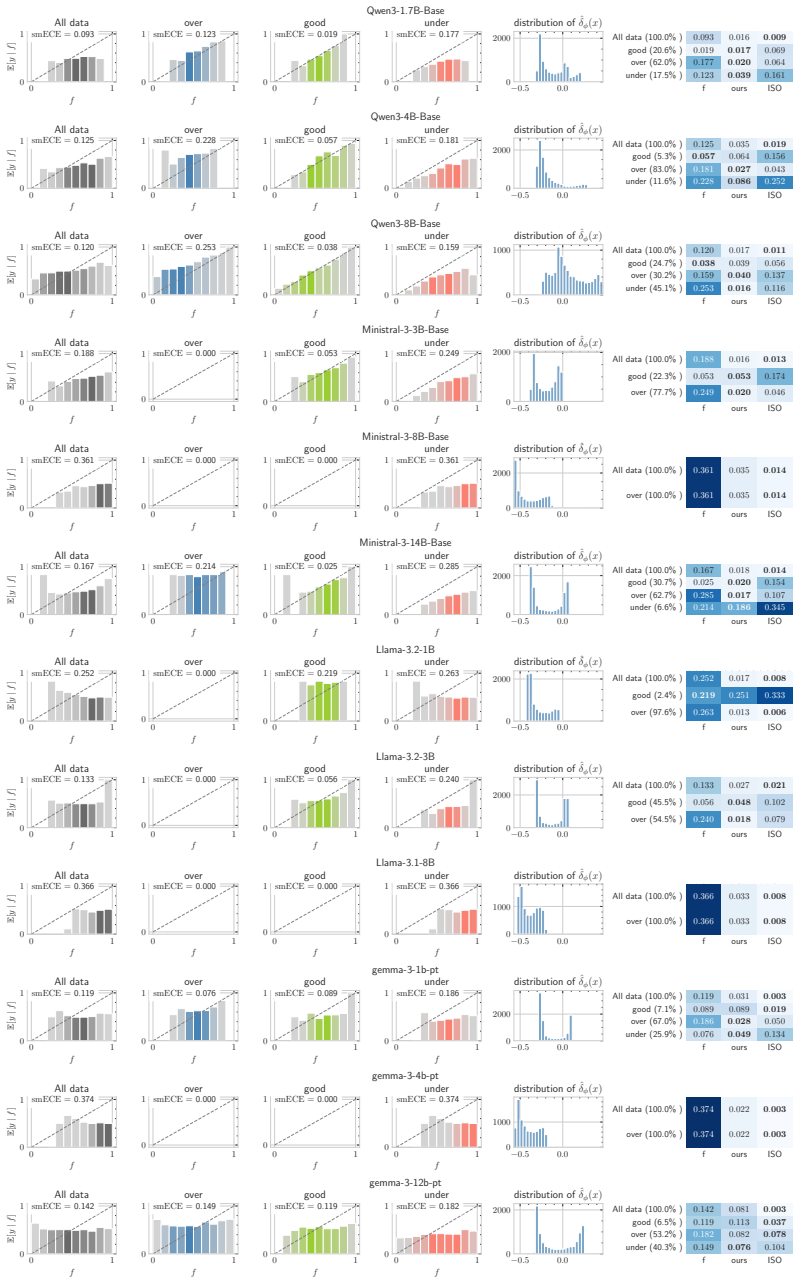
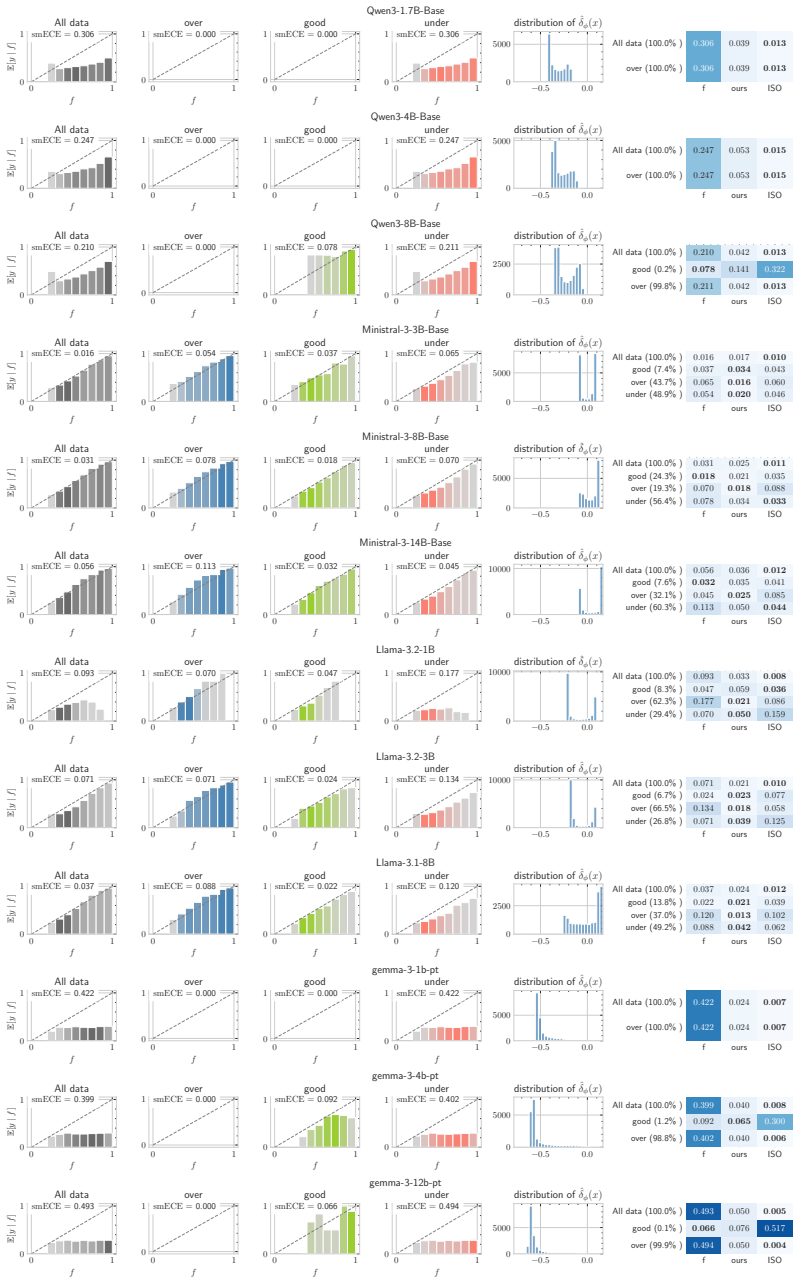
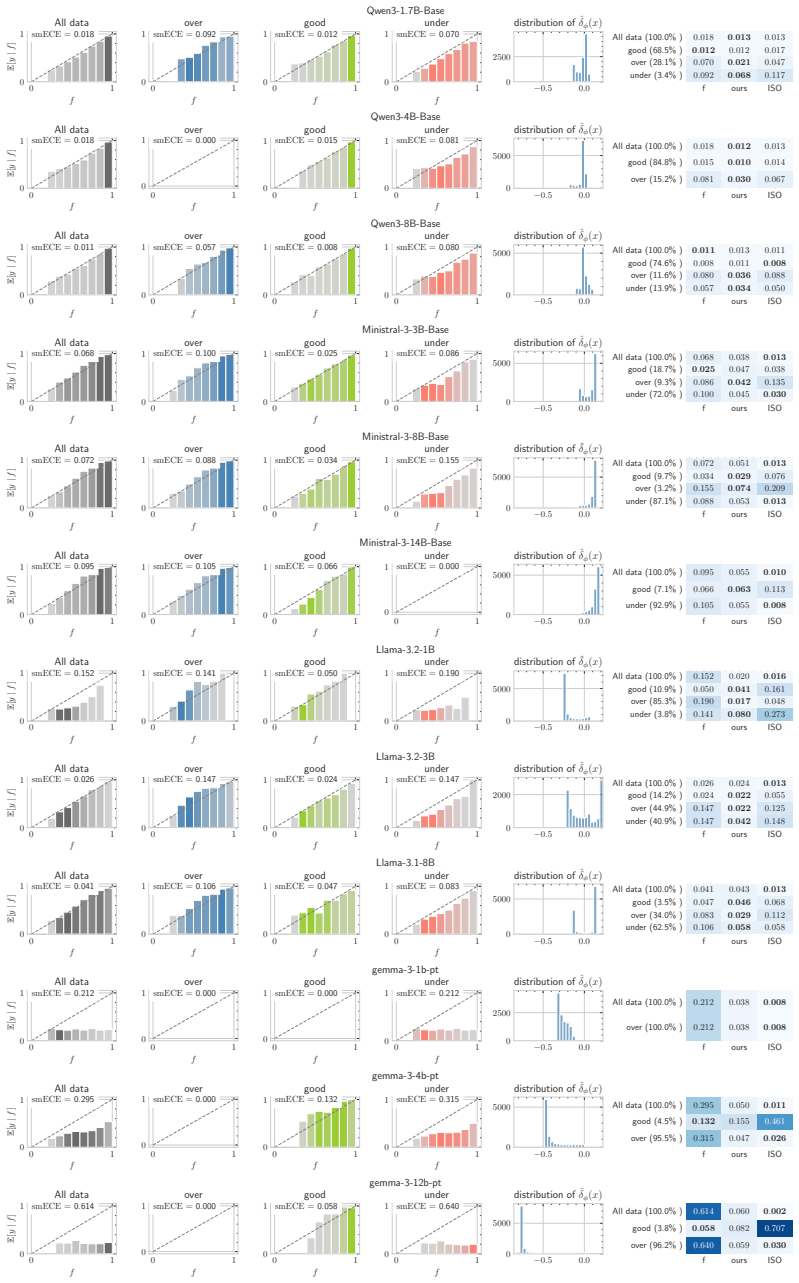
The authors formulate the discovery of hidden miscalibration regimes by defining a miscalibration field estimated through a learned calibration-aware representation and kernel smoothing in that geometry, revealing that input-dependent calibration heterogeneity is prevalent across benchmarks and that local corrections using these fields reduce error more effectively than global confidence-based methods in miscalibrated areas.
What carries the argument
The miscalibration field, a learned representation of the input space combined with kernel smoothing to estimate signed local miscalibration without predefined data slices.
If this is right
- Local corrections using the field reduce calibration error in regions where models are systematically miscalibrated.
- These fields outperform isotonic regression and temperature scaling in those specific regions.
- Input-dependent heterogeneity appears consistently across four benchmarks and twelve LLMs.
- The approach works without access to predefined data slices or additional supervision.
Where Pith is reading between the lines
- Deployed models could use input-based clustering to apply different corrections dynamically.
- The method might extend to identifying reliability issues in non-LLM models like classifiers in other domains.
- New benchmarks could test calibration not just globally but across discovered regimes.
Load-bearing premise
A calibration-aware representation of the inputs exists such that kernel smoothing in it accurately recovers the signed local miscalibration.
What would settle it
If the local confidence corrections based on the discovered fields fail to reduce calibration error more than global methods like temperature scaling in the identified miscalibrated regions, the utility of the approach would be called into question.
Figures













read the original abstract
Calibration is commonly evaluated by comparing model confidence with its empirical correctness, implicitly treating reliability as a function of the confidence score alone. However, this view can hide substantial structure: models may be systematically overconfident on some kinds of inputs and underconfident on others, causing global reliability diagnostics to obscure localised calibration failures. To address this, we formulate the problem of discovering hidden miscalibration regimes without assuming access to predefined data slices. We define the corresponding miscalibration field and propose a diagnostic framework for estimating it. Our approach learns a calibration-aware representation of the input space and estimates signed local miscalibration by kernel smoothing in the learned geometry. Across four real-world LLM benchmarks and twelve LLMs, we find that input-dependent calibration heterogeneity is prevalent. We further show that the discovered fields are actionable: they support local confidence correction and reduce calibration error in systematically miscalibrated regions where confidence-based methods such as isotonic regression and temperature scaling are less effective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that input-dependent calibration heterogeneity is prevalent in LLMs and can be discovered without predefined data slices by learning a calibration-aware representation of the input space, then estimating a signed miscalibration field via kernel smoothing in that geometry. It reports empirical evidence of this heterogeneity across four real-world LLM benchmarks and twelve models, and shows that the discovered fields support local confidence correction that reduces calibration error more effectively than global methods such as isotonic regression and temperature scaling in systematically miscalibrated regions.
Significance. If the learned representation plus kernel smoothing reliably recovers genuine signed local miscalibration rather than method artifacts, the work would meaningfully advance calibration diagnostics beyond confidence-only or global approaches, with direct implications for improving LLM reliability in heterogeneous input regimes. The scale of the empirical evaluation across multiple benchmarks and models strengthens the case for prevalence and actionability, provided the recovery step is validated.
major comments (3)
- [§3] §3 (diagnostic framework): The central claim that kernel smoothing in the learned calibration-aware representation recovers true signed local miscalibration lacks ground-truth validation or predefined slices; the only supporting evidence is superior performance of local correction over global baselines on the same benchmarks, which leaves open the possibility that the representation merely enables better residual fitting rather than identifying genuine input-dependent structure.
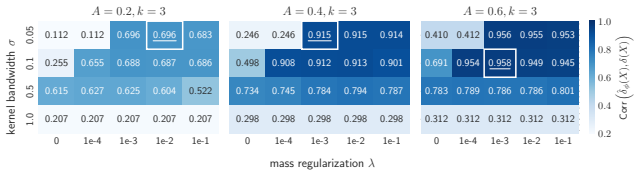
- [Results] Results section (empirical evaluation): The reported reductions in calibration error for local correction are presented without confidence intervals, statistical significance tests, or ablation on the representation learning and kernel bandwidth choices, making it difficult to assess whether the actionability advantage is robust or sensitive to hyperparameter settings.
- [Definition of the miscalibration field] Definition of the miscalibration field: The framework treats the field as recoverable from unlabeled inputs via the learned geometry, but without an explicit consistency check or cross-validation against held-out local correctness estimates, the prevalence conclusion rests on an unverified recovery assumption.
minor comments (2)
- [Method] The abstract and method sections should explicitly list the kernel family, bandwidth selection procedure, and representation learning architecture (including any hyperparameters) to enable reproducibility.
- [Figures] Figure captions for the discovered fields should include the specific benchmark, model, and smoothing parameters used to generate each visualization.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications on our validation approach and indicate revisions that will strengthen the empirical support for the framework.
read point-by-point responses
-
Referee: [§3] §3 (diagnostic framework): The central claim that kernel smoothing in the learned calibration-aware representation recovers true signed local miscalibration lacks ground-truth validation or predefined slices; the only supporting evidence is superior performance of local correction over global baselines on the same benchmarks, which leaves open the possibility that the representation merely enables better residual fitting rather than identifying genuine input-dependent structure.
Authors: We agree that direct ground-truth validation is challenging in a discovery setting without predefined slices, which is precisely the motivation for the framework. The calibration-aware representation is explicitly optimized using observed correctness signals to induce a geometry in which kernel smoothing recovers the signed field; the local correction experiments then demonstrate that applying corrections according to this field yields larger error reductions precisely in the identified regions, an outcome that would not be expected from generic residual fitting. To further address the concern, we will add synthetic experiments with known ground-truth miscalibration fields in the revised manuscript and expand §3 with a discussion of why the observed structure is unlikely to be an artifact of the fitting procedure alone. revision: yes
-
Referee: [Results] Results section (empirical evaluation): The reported reductions in calibration error for local correction are presented without confidence intervals, statistical significance tests, or ablation on the representation learning and kernel bandwidth choices, making it difficult to assess whether the actionability advantage is robust or sensitive to hyperparameter settings.
Authors: We accept this criticism. The revised manuscript will include bootstrap confidence intervals for all reported calibration-error reductions, paired statistical significance tests between local and global correction methods, and systematic ablations on both the representation-learning objective and kernel bandwidth, with results reported across the full set of benchmarks and models. revision: yes
-
Referee: [Definition of the miscalibration field] Definition of the miscalibration field: The framework treats the field as recoverable from unlabeled inputs via the learned geometry, but without an explicit consistency check or cross-validation against held-out local correctness estimates, the prevalence conclusion rests on an unverified recovery assumption.
Authors: The field is estimated from the learned geometry on held-out inputs after the representation is trained on calibration data. To make the recovery assumption explicit and verifiable, we will add a cross-validation procedure that splits the labeled data, estimates the field on one subset, and measures agreement with local correctness estimates on the complementary held-out subset; the corresponding correlation metrics and consistency results will be reported in the revised results section. revision: yes
Circularity Check
No significant circularity; derivation self-contained via external empirical validation
full rationale
The paper defines a miscalibration field and a diagnostic framework that learns a calibration-aware input representation followed by kernel smoothing to estimate signed local miscalibration. These steps are presented as a proposed method rather than a reduction of outputs to fitted inputs or self-citations by construction. Central claims of prevalence and actionability rest on results across four external LLM benchmarks and twelve models, compared against independent baselines such as isotonic regression and temperature scaling. No load-bearing step equates a prediction to its own defining fit or renames a known pattern; the approach is validated outside its own parameters.
Axiom & Free-Parameter Ledger
free parameters (2)
- kernel bandwidth / smoothing parameter
- representation learning hyperparameters
axioms (1)
- domain assumption A calibration-aware representation of the input space exists in which kernel smoothing recovers signed local miscalibration
invented entities (1)
-
miscalibration field
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith.Foundation.RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define the input-dependent miscalibration field δ(x)=E[Y−f(X)|X=x] and estimate it by learning a representation ϕ... kernel smoothing in the learned geometry
-
IndisputableMonolith.Cost.FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Maximizing Eq. (3) encourages representations in which local residual averages are non-cancelling
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Y . Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli, T. Henighan, N. Joseph, S. Kadavath, J. Kernion, T. Conerly, S. El-Showk, N. Elhage, Z. Hatfield- Dodds, D. Hernandez, T. Hume, S. Johnston, S. Kravec, L. Lovitt, N. Nanda, C. Olsson, D. Amodei, T. Brown, J. Clark, S. McCandlish, C. Olah, B. Mann, and J. Kaplan....
work page 2022
-
[2]
J. Blasiok and P. Nakkiran. Smooth ECE: Principled reliability diagrams via kernel smoothing. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[3]
A. Chouldechova. Fair prediction with disparate impact: A study of bias in recidivism prediction instruments.Big Data, 5(2):153–163, June 2017
work page 2017
- [4]
-
[5]
A. P. Dawid. The well-calibrated bayesian.Journal of the American Statistical Association, 77(379):605–610, 1982
work page 1982
-
[6]
M. H. DeGroot and S. E. Fienberg. The comparison and evaluation of forecasters.Journal of the Royal Statistical Society. Series D (The Statistician), 32(1):12–22, 1983
work page 1983
-
[7]
S. Eyuboglu, M. Varma, K. K. Saab, J.-B. Delbrouck, C. Lee-Messer, J. Dunnmon, J. Zou, and C. Re. Domino: Discovering systematic errors with cross-modal embeddings. InInternational Conference on Learning Representations, 2022
work page 2022
-
[8]
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger. On calibration of modern neural networks. In D. Precup and Y . W. Teh, editors,Proceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 1321–1330. PMLR, 06–11 Aug 2017
work page 2017
- [9]
-
[10]
B. He, L. Yin, H. Zhen, S. LIU, H. Wu, X. Zhang, M. Yuan, and C. Ma. Preserving LLM capabilities through calibration data curation: From analysis to optimization. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[11]
U. Hebert-Johnson, M. Kim, O. Reingold, and G. Rothblum. Multicalibration: Calibration for the (Computationally-identifiable) masses. In J. Dy and A. Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 1939–1948. PMLR, 10–15 Jul 2018
work page 1939
-
[12]
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[13]
W. Hua, L. Jin, L. Song, H. Mi, Y . Zhang, and D. Yu. Discover, explain, improve: An automatic slice detection benchmark for natural language processing.Transactions of the Association for Computational Linguistics, 11:1537–1552, 2023
work page 2023
-
[14]
P. Indyk and R. Motwani. Approximate nearest neighbors: towards removing the curse of di- mensionality. InProceedings of the Thirtieth Annual ACM Symposium on Theory of Computing, STOC ’98, page 604–613, New York, NY , USA, 1998. Association for Computing Machinery
work page 1998
-
[15]
S. Kapoor, N. Gruver, M. Roberts, A. Pal, S. Dooley, M. Goldblum, and A. Wilson. Calibration- tuning: Teaching large language models to know what they don’t know. In R. Vázquez, H. Celikkanat, D. Ulmer, J. Tiedemann, S. Swayamdipta, W. Aziz, B. Plank, J. Baan, and M.-C. de Marneffe, editors,Proceedings of the 1st Workshop on Uncertainty-Aware NLP (Uncerta...
work page 2024
-
[16]
J. Kleinberg, S. Mullainathan, and M. Raghavan. Inherent Trade-Offs in the Fair Determination of Risk Scores. In C. H. Papadimitriou, editor,8th Innovations in Theoretical Computer Science Conference (ITCS 2017), volume 67 ofLeibniz International Proceedings in Informatics (LIPIcs), pages 43:1–43:23, Dagstuhl, Germany, 2017. Schloss Dagstuhl – Leibniz-Zen...
work page 2017
-
[17]
E. A. Nadaraya. On estimating regression.Theory of Probability & Its Applications, 9(1):141– 142, 1964
work page 1964
-
[18]
P. Nakkiran, A. Bradley, A. Golinski, E. Ndiaye, M. Kirchhof, and S. Williamson. Trained on tokens, calibrated on concepts: The emergence of semantic calibration in LLMs. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[19]
Z. Obermeyer, B. Powers, C. V ogeli, and S. Mullainathan. Dissecting racial bias in an algorithm used to manage the health of populations.Science, 366(6464):447–453, 2019
work page 2019
-
[20]
J. Otey, L. Biester, and S. R. Wilson. Representing and clustering errors in offensive language detection. In A. Ebrahimi, S. Haider, E. Liu, S. Haider, M. Leonor Pacheco, and S. Wein, editors, Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 4: ...
work page 2025
-
[21]
A. Pal, L. K. Umapathi, and M. Sankarasubbu. Medmcqa: A large-scale multi-subject multi- choice dataset for medical domain question answering. In G. Flores, G. H. Chen, T. Pollard, J. C. Ho, and T. Naumann, editors,Proceedings of the Conference on Health, Inference, and Learning, volume 174 ofProceedings of Machine Learning Research, pages 248–260. PMLR, ...
work page 2022
-
[22]
J. C. Platt. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. In A. J. Smola, P. L. Bartlett, B. Schölkopf, and D. Schuurmans, editors, Advances in Large Margin Classifiers, pages 61–74. MIT Press, 1999
work page 1999
-
[23]
S. Sagadeeva and M. Boehm. Sliceline: Fast, linear-algebra-based slice finding for ml model debugging. InProceedings of the 2021 International Conference on Management of Data, SIGMOD ’21, page 2290–2299, New York, NY , USA, 2021. Association for Computing Machinery
work page 2021
-
[24]
C. J. Stone. Consistent Nonparametric Regression.The Annals of Statistics, 5(4):595 – 620, 1977
work page 1977
-
[25]
Y . Wang, X. Ma, G. Zhang, Y . Ni, A. Chandra, S. Guo, W. Ren, A. Arulraj, X. He, Z. Jiang, T. Li, M. Ku, K. Wang, A. Zhuang, R. Fan, X. Yue, and W. Chen. MMLU-pro: A more robust and challenging multi-task language understanding benchmark. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024
work page 2024
-
[26]
G. S. Watson. Smooth regression analysis.Sankhy ¯a: The Indian Journal of Statistics, Series A (1961-2002), 26(4):359–372, 1964
work page 1961
-
[27]
J. Xiao, B. Hou, Z. Wang, R. Jin, Q. Long, W. J. Su, and L. Shen. Restoring calibration for aligned large language models: A calibration-aware fine-tuning approach. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[28]
B. Zadrozny and C. Elkan. Obtaining calibrated probability estimates from decision trees and naive bayesian classifiers. InProceedings of the Eighteenth International Conference on Machine Learning, ICML ’01, page 609–616, San Francisco, CA, USA, 2001. Morgan Kaufmann Publishers Inc
work page 2001
-
[29]
B. Zadrozny and C. Elkan. Transforming classifier scores into accurate multiclass probability estimates. InProceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’02, page 694–699, New York, NY , USA, 2002. Association for Computing Machinery. 11
work page 2002
- [30]
-
[31]
C. Zhu, B. Xu, Q. Wang, Y . Zhang, and Z. Mao. On the calibration of large language models and alignment. In H. Bouamor, J. Pino, and K. Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 9778–9795, Singapore, Dec. 2023. Association for Computational Linguistics. 12 Appendix Appendix roadmap.The appendix is organise...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.