Recognition: no theorem link
Effective Context in Transformers: An Analysis of Fragmentation and Tokenization
Pith reviewed 2026-05-14 20:36 UTC · model grok-4.3
The pith
Fragmentation into smaller units can strictly raise the minimal log-loss achievable by any finite-context transformer on Markov sources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
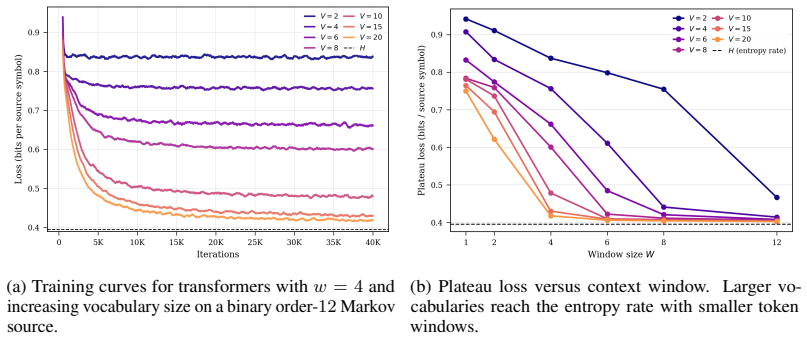
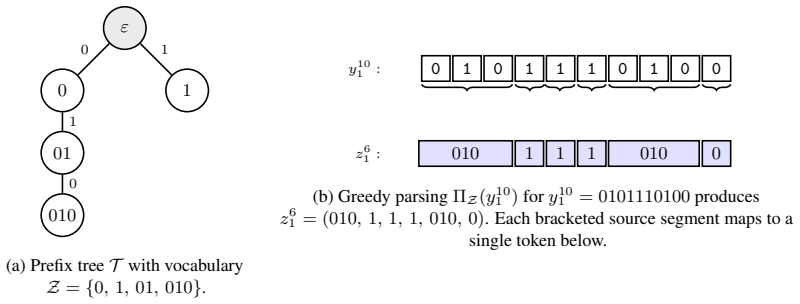
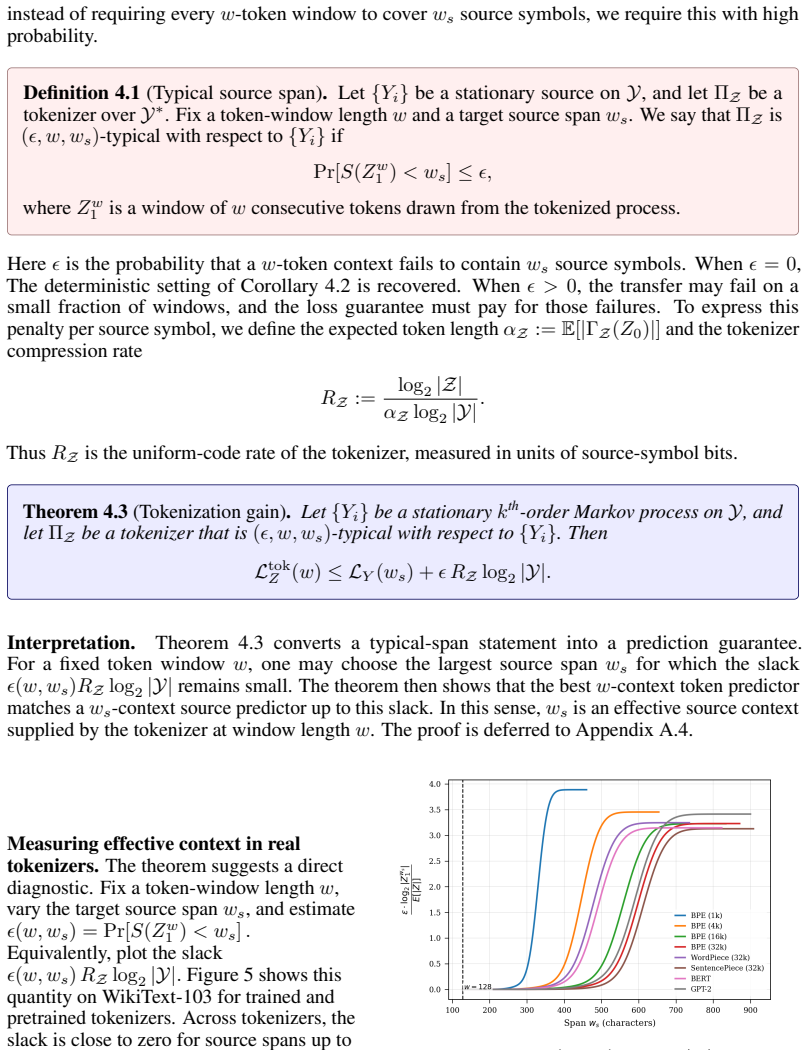
Fragmentation is a lossless recoding that replaces each source symbol by several smaller units; it can strictly increase the optimal finite-context log-loss on Markov sources. Greedy tokenization groups symbols into larger units and can make a token window behave like a longer source-context window, yielding a loss guarantee controlled by spanning reliability and compression rate. Together these establish a finite-context information-theoretic account of representation choices.
What carries the argument
Fragmentation: a lossless recoding that replaces each source symbol by several smaller units, thereby increasing the number of steps needed to cover the same source history.
If this is right
- Byte- and character-level models incur an intrinsic penalty relative to subword models that cannot be removed merely by enlarging the context window.
- A tokenizer can be diagnosed by measuring the fraction of source history reliably covered by its fixed token windows.
- The loss guarantee for tokenization improves when the tokenizer both compresses and ensures that token boundaries align with source transitions.
- Representation choice and context length become coupled design decisions rather than independent ones.
Where Pith is reading between the lines
- The strict increase may weaken or disappear once long-range dependencies or non-stationarity dominate, suggesting a direct test on natural language corpora.
- Hybrid schemes that fragment only where necessary while tokenizing elsewhere could be evaluated by measuring the resulting effective source-context length.
- The diagnostic for tokenizers could be used to compare BPE, WordPiece, and learned tokenizers on the same source without retraining models.
Load-bearing premise
The data are generated by Markov sources of finite order.
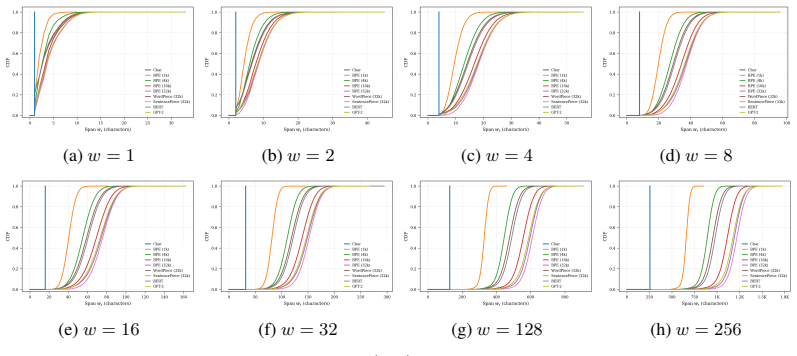
What would settle it
A concrete Markov source on which some fragmentation strictly decreases the optimal finite-context log-loss, or an experiment on real text where enlarging a character-level context window closes the entire gap to a subword model.
Figures




read the original abstract
Transformers predict over a representation of a sequence. The same data can be written as bytes, characters, or subword tokens, and these representations may be lossless. Yet, under a fixed context window, they need not expose the same information to the model. This raises a basic question: how does the choice of representation change what a finite-context predictor can achieve? We study this question on Markov sources and uncover two complementary phenomena. First, we observe that moving to smaller representation units can hurt prediction even when the context window is enlarged to cover the relevant source history. To explain this, we introduce fragmentation: a lossless recoding that replaces each source symbol by several smaller units. We prove that fragmentation can strictly increase the optimal finite-context log-loss, showing that the gap is not merely an optimization or capacity issue, but can be intrinsic to the representation. This gives a theoretical account of the finite-context gap observed in byte- and character-level models such as ByT5 and CANINE relative to subword-tokenized models. Second, we study the opposite direction: greedy tokenization -- BPE, WordPiece, and related methods -- which groups source symbols into larger units. We show that tokenization can make a short token window behave like a longer source-context window, and we give a loss guarantee describing when this is achievable. The guarantee depends on how reliably token windows span the needed source history, together with the compression rate of the tokenizer. This also yields a simple diagnostic for real tokenizers: measuring how much source context a fixed token window reliably contains. Together, the two directions establish a finite-context information-theoretic framework for reasoning about representation choices in Transformers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for data generated by stationary Markov sources, a lossless fragmentation recoding to smaller units can strictly increase the infimum log-loss achievable by any finite-context predictor, providing an intrinsic representational explanation for observed gaps between byte/character-level models (e.g., ByT5) and subword-tokenized models. In the opposite direction, it derives a loss guarantee showing when greedy tokenization (BPE, WordPiece) allows a short token window to behave like a longer source-context window, depending on reliable spanning of source history and compression rate, together with a diagnostic for real tokenizers.
Significance. If the results hold, the work supplies a clean information-theoretic framework that separates representational effects from optimization or capacity limitations in finite-context models. The explicit construction for the strict-increase result under fragmentation and the parameter-light loss guarantee for tokenization are concrete strengths; the diagnostic for measuring source-context coverage in token windows is immediately usable.
major comments (1)
- [Abstract and §2–3] Abstract and the Markov-source setup (likely §2–3): the strict-increase proof and the tokenization loss guarantee are derived only for stationary finite-order Markov sources. The manuscript invokes these results to give 'a theoretical account' of finite-context gaps in real Transformers trained on natural language, yet the skeptic note correctly flags that long-range dependencies and non-stationarities are excluded by construction; a concrete discussion of whether the separation survives (or a counter-example) is load-bearing for the claimed explanatory power.
minor comments (1)
- [Early sections / notation] The definitions of fragmentation and of the optimal finite-context log-loss would be clearer if introduced with explicit notation or a short equation block before the main theorems.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and for highlighting the scope of our theoretical results. We will revise the manuscript to include a dedicated discussion addressing the applicability of the Markov-source analysis to natural language, while preserving the rigor of the existing proofs.
read point-by-point responses
-
Referee: [Abstract and §2–3] Abstract and the Markov-source setup (likely §2–3): the strict-increase proof and the tokenization loss guarantee are derived only for stationary finite-order Markov sources. The manuscript invokes these results to give 'a theoretical account' of finite-context gaps in real Transformers trained on natural language, yet the skeptic note correctly flags that long-range dependencies and non-stationarities are excluded by construction; a concrete discussion of whether the separation survives (or a counter-example) is load-bearing for the claimed explanatory power.
Authors: We agree that an explicit discussion of scope is required for the claimed explanatory power. The strict-increase result for fragmentation is proved for stationary finite-order Markov sources because this setting permits a clean information-theoretic construction showing that the penalty is intrinsic to the representation rather than to optimization or capacity. This already supplies a lower bound: if fragmentation hurts even when all relevant history fits inside the window, the effect cannot be weaker for sources with additional long-range dependencies. Non-stationarities would only increase the amount of history that must be reliably spanned, making the fragmentation penalty at least as large. We will add a new subsection (likely §4.3) that (i) states the Markov assumption explicitly as a modeling choice, (ii) sketches why the separation is expected to survive for non-stationary sources, and (iii) notes that highly structured counter-examples (e.g., deterministic periodic sources) lie outside the stationary Markov regime but do not invalidate the positive result for the broad class of sources that exhibit local dependencies. The tokenization guarantee will be similarly qualified. This revision will be made without altering the theorems themselves. revision: yes
Circularity Check
No circularity: self-contained proofs on Markov sources
full rationale
The paper's central claims are established by explicit constructions and counting arguments for stationary Markov sources of finite order. Fragmentation is defined as a lossless recoding, and the strict increase in optimal finite-context log-loss is shown by exhibiting a source where relevant history is lost under any fixed window in the new alphabet; this follows directly from the Markov property equating the optimal predictor to a function of finite past symbols. The tokenization loss guarantee is derived from measurable properties of how token windows span source history plus compression rate, without any fitted parameters or redefinitions. No load-bearing step reduces to a self-citation, ansatz smuggled via prior work, or renaming of a known result. The derivations remain independent of the target claims and are falsifiable under the stated assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Data is generated by a stationary Markov source of finite order
invented entities (1)
-
Fragmentation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bellard, Fabrice , year = 2021, month = feb, langid =
work page 2021
-
[2]
International Conference on Learning Representations , year =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations , year =
-
[3]
International Conference on Learning Representations , year =
Pointer Sentinel Mixture Models , author =. International Conference on Learning Representations , year =
-
[4]
Bondaschi, Marco and Rajaraman, Nived and Wei, Xiuying and Pascanu, Razvan and Gulcehre, Caglar and Gastpar, Michael and Makkuva, Ashok Vardhan , year = 2025, month = oct, urldate =. From. The
work page 2025
-
[5]
Language Models are Unsupervised Multitask Learners , author =. 2019 , url =
work page 2019
- [6]
-
[7]
Chai, Yekun and Fang, Yewei and Peng, Qiwei and Li, Xuhong , editor =. Tokenization. Findings of the
-
[8]
and Garrette, Dan and Turc, Iulia and Wieting, John , editor =
Clark, Jonathan H. and Garrette, Dan and Turc, Iulia and Wieting, John , editor =. Canine:. Transactions of the Association for Computational Linguistics , volume =
-
[9]
Cover, Thomas M. and Thomas, Joy A. , year = 2005, month = sep, edition =. Elements of
work page 2005
-
[10]
Language Modeling Is Compression , year =
Del. Language. arXiv , langid =:2309.10668 , primaryclass =
-
[11]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , editor =. Proceedings of the 2019
work page 2019
-
[12]
Edelman, Ezra and Tsilivis, Nikolaos and Edelman, Benjamin L and Malach, Eran and Goel, Surbhi , langid =. The
-
[13]
and Malach, Eran and Goel, Surbhi , year = 2024, month = nov, urldate =
Edelman, Ezra and Tsilivis, Nikolaos and Edelman, Benjamin L. and Malach, Eran and Goel, Surbhi , year = 2024, month = nov, urldate =. The. The
work page 2024
- [14]
- [15]
-
[16]
Goyal, Mohit and Tatwawadi, Kedar and Chandak, Shubham and Ochoa, Idoia , year = 2021, month = mar, pages =. 2021
work page 2021
-
[17]
, year = 2025, month = sep, journal =
Haslett, David A. , year = 2025, month = sep, journal =. Tokenization
work page 2025
-
[18]
HUFFMANt, DAVID A , year = 1952, journal =. A
work page 1952
-
[19]
Kudo, Taku and Richardson, John , editor =. Proceedings of the 2018
work page 2018
-
[20]
Kudo, Taku , editor =. Subword. Proceedings of the 56th
-
[21]
Lu, Zeyi and Ma, Xiaoxiao and Huang, Yujun and Chen, Minxiao and Chen, Bin and An, Baoyi and Xia, Shu-Tao , year = 2025, month = oct, series =. Proceedings of the 33rd
work page 2025
-
[22]
Makkuva, Ashok Vardhan and Bondaschi, Marco and Girish, Adway and Nagle, Alliot and Jaggi, Martin and Kim, Hyeji and Gastpar, Michael , year = 2024, month = oct, urldate =. Attention with. The
work page 2024
-
[23]
Mao, Yu and Cui, Yufei and Kuo, Tei-Wei and Xue, Chun Jason , year = 2022, month = oct, series =. Accelerating. Proceedings of the 30th
work page 2022
-
[24]
Mao, Yu and Li, Jingzong and Cui, Yufei and Xue, Jason Chun , year = 2023, month = jul, pages =. Faster and. 2023 60th
work page 2023
-
[25]
Mao, Yu and Cui, Yufei and Kuo, Tei-Wei and Xue, Chun Jason , year = 2022, month = apr, pages =. Proceedings of the
work page 2022
-
[26]
, year = 2015, month = oct, series =
Piczak, Karol J. , year = 2015, month = oct, series =. Proceedings of the 23rd
work page 2015
-
[27]
Rajaraman, Nived and Jiao, Jiantao and Ramchandran, Kannan , year = 2024, month = nov, urldate =. An. The
work page 2024
-
[28]
Rajaraman, Nived and Bondaschi, Marco and Makkuva, Ashok Vardhan and Ramchandran, Kannan and Gastpar, Michael , year = 2024, month = nov, urldate =. Transformers on. The
work page 2024
-
[29]
Schmidt, Craig W and Reddy, Varshini and Zhang, Haoran and Alameddine, Alec and Uzan, Omri and Pinter, Yuval and Tanner, Chris , editor =. Tokenization. Proceedings of the 2024
work page 2024
-
[30]
Schuster, Mike and Nakajima, Kaisuke , year = 2012, month = mar, pages =. Japanese and. 2012
work page 2012
-
[31]
Sennrich, Rico and Haddow, Barry and Birch, Alexandra , year = 2016, month = jun, number =. Neural. 1508.07909 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[32]
Shannon, C. E. , year = 1948, journal =. A
work page 1948
-
[33]
Tao, Chaofan and Liu, Qian and Dou, Longxu and Muennighoff, Niklas and Wan, Zhongwei and Luo, Ping and Lin, Min and Wong, Ngai , year = 2024, langid =. Scaling. Advances in
work page 2024
-
[34]
Tay, Yi and Tran, Vinh Q. and Ruder, Sebastian and Gupta, Jai and Chung, Hyung Won and Bahri, Dara and Qin, Zhen and Baumgartner, Simon and Yu, Cong and Metzler, Donald , year = 2021, month = oct, urldate =. Charformer:. International
work page 2021
-
[35]
LLaMA: Open and Efficient Foundation Language Models
Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth. 2302.13971 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser,. Attention Is. Advances in
-
[37]
, year = 1992, month = feb, journal =
Wallace, G.K. , year = 1992, month = feb, journal =. The
work page 1992
- [38]
-
[39]
Transactions of the Association for Computational Linguistics , volume =
Xue, Linting and Barua, Aditya and Constant, Noah and. Transactions of the Association for Computational Linguistics , volume =
-
[40]
Yu, Lili and Simig, Daniel and Flaherty, Colin and Aghajanyan, Armen and Zettlemoyer, Luke and Lewis, Mike , year = 2023, month = nov, urldate =. Thirty-Seventh
work page 2023
-
[41]
Zhang, Xiang and Cao, Juntai and Wei, Jiaqi and Xu, Yiwei and You, Chenyu , year = 2025, publisher =. Tokenization
work page 2025
-
[42]
IEEE Transactions on Information Theory , volume =
Compression of Individual Sequences via Variable-Rate Coding , author =. IEEE Transactions on Information Theory , volume =
-
[43]
IEEE Transactions on Information Theory , volume =
A Universal Algorithm for Sequential Data Compression , author =. IEEE Transactions on Information Theory , volume =
- [44]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.