Recognition: unknown
Reward-Weighted On-Policy Distillation with an Open Property-Equivalence Verifier for NL-to-SVA Generation
Pith reviewed 2026-05-14 18:28 UTC · model grok-4.3
The pith
Reward-weighted on-policy distillation using an open property-equivalence checker lets a 7B model set new state-of-the-art results on natural-language to SystemVerilog assertion generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
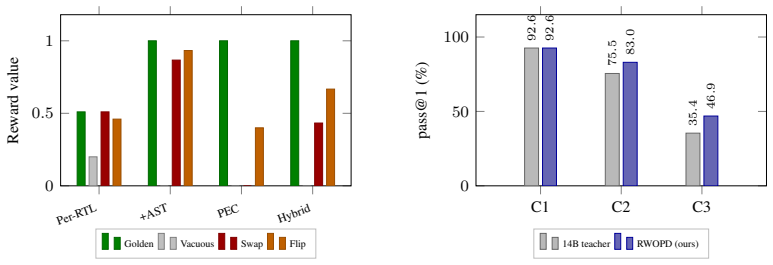
Reward-Weighted On-Policy Distillation (RWOPD) samples student rollouts, scores them with an open SymbiYosys+Z3 Property-Equivalence Checker, and applies a verifier-reward-weighted forward-KL gradient from a frozen 14B teacher on verifier-passable rollouts, distilling CodeV-SVA-14B into a Qwen2.5-Coder-7B-Instruct student that sets a new state of the art on NL2SVA benchmarks.
What carries the argument
Reward-Weighted On-Policy Distillation (RWOPD) with Property-Equivalence Checker (PEC), which scores on-policy rollouts for property equivalence and weights the distillation loss accordingly.
If this is right
- The 7B distilled student achieves higher pass rates than both specialized prior models and much larger general-purpose models on human-written and machine-generated NL-to-SVA tasks.
- Dense token-level supervision is retained while the loss is grounded only in property-equivalent behaviors rather than surface mimicry.
- Open verifiers can serve as reliable reward sources for on-policy distillation in formal specification tasks.
- Smaller models become practical for high-accuracy SVA generation without relying on template collapse for complex timing properties.
Where Pith is reading between the lines
- The same verifier-weighted on-policy loop could be applied to other formal-language generation problems such as protocol or HDL specification.
- Tighter integration of the checker inside the sampling loop might further reduce the number of rollouts needed per training step.
- The approach suggests a path to shrinking the model size required for reliable hardware-verification assistance across multiple description languages.
Load-bearing premise
The open SymbiYosys+Z3 checker reliably labels property-equivalent SVA specifications without systematic false positives or negatives that would distort the reward-weighted loss.
What would settle it
A collection of SVA properties on which the checker reports equivalence but an independent formal tool or exhaustive manual review shows behavioral mismatch would eliminate the claimed performance gains.
Figures

read the original abstract
LLM-based generation of SystemVerilog Assertions (SVA) is often reported as nearing saturation, with the strongest specialized model reaching ${\sim}76\%$ accuracy on NL2SVA-Human. We show that this aggregate hides a temporal gap: models that appear strong overall still collapse to a few implication templates on bounded-delay and liveness specifications. The core issue is that the dominant recipe, supervised fine-tuning on NL/SVA pairs, optimizes token-level mimicry rather than the \emph{property equivalence} that defines SVA correctness. We introduce \emph{Reward-Weighted On-Policy Distillation} (RWOPD), an on-policy distillation method that samples student rollouts, scores them with an open SymbiYosys+Z3 Property-Equivalence Checker (PEC), and applies a verifier-reward-weighted forward-KL gradient from a frozen 14B teacher on verifier-passable rollouts. This keeps the supervision dense at every response token while grounding both selection and loss weight in property-equivalent behavior. RWOPD distills CodeV-SVA-14B into a Qwen2.5-Coder-7B-Instruct student that sets a new state of the art on NL2SVA-Human and NL2SVA-Machine across pass@1, pass@5, and pass@10, surpassing both specialized prior SOTA models and 671B general-purpose baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Reward-Weighted On-Policy Distillation (RWOPD) for NL-to-SVA generation. It samples rollouts from a student model (Qwen2.5-Coder-7B-Instruct), scores them with an open SymbiYosys+Z3 Property-Equivalence Checker (PEC), and applies a verifier-reward-weighted forward-KL loss from a frozen CodeV-SVA-14B teacher only on PEC-passable rollouts. The central claim is that this yields a new SOTA on NL2SVA-Human and NL2SVA-Machine across pass@1/5/10, outperforming prior specialized models and 671B baselines by addressing collapse on bounded-delay and liveness properties.
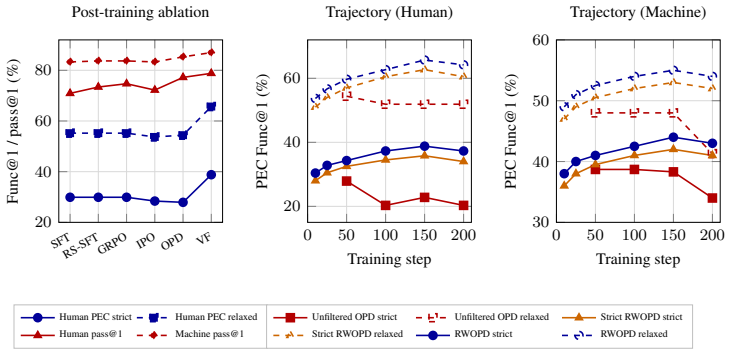
Significance. If the PEC is shown to be reliable, RWOPD provides a concrete mechanism for verifier-grounded distillation that keeps dense token-level supervision while tying selection and weighting to property equivalence rather than surface mimicry. This could generalize to other formal-specification tasks where token-level SFT fails on temporal or liveness constraints.
major comments (2)
- [Abstract and §4] Abstract and §4 (Results): the claim of new SOTA is stated without any numerical accuracy values, ablation tables, or error analysis on the NL2SVA benchmarks. This makes it impossible to quantify the improvement or isolate the contribution of the reward weighting versus the base student model.
- [§3] §3 (RWOPD method): no precision, recall, or human-agreement numbers are supplied for the SymbiYosys+Z3 PEC on the target property classes (bounded-delay, liveness). Because the binary reward directly filters rollouts and scales the forward-KL term, uncharacterized false-positive rates on the very templates where prior models collapse would systematically reinforce non-equivalent SVA and undermine the central claim.
minor comments (2)
- [§3] Notation for the reward-weighted loss (Eq. in §3) could be expanded to show explicitly how the indicator 1{PEC=pass} multiplies the per-token KL term.
- [§4] Figure captions and table headers should state the exact pass@k definitions and the number of samples used for each metric.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that quantitative details and verifier characterization are essential for substantiating the SOTA claims and method reliability. We will revise the manuscript to incorporate the requested numbers, tables, and metrics.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Results): the claim of new SOTA is stated without any numerical accuracy values, ablation tables, or error analysis on the NL2SVA benchmarks. This makes it impossible to quantify the improvement or isolate the contribution of the reward weighting versus the base student model.
Authors: We agree that specific numerical values, ablations, and error analysis were not sufficiently highlighted in the abstract and §4. In the revised manuscript we will add the exact pass@1/5/10 accuracies on NL2SVA-Human and NL2SVA-Machine for the 7B RWOPD model versus all baselines (including the 76% prior SOTA and 671B models), include ablation tables isolating the reward-weighting term from the base student, and provide error analysis focused on bounded-delay and liveness failure modes. revision: yes
-
Referee: [§3] §3 (RWOPD method): no precision, recall, or human-agreement numbers are supplied for the SymbiYosys+Z3 PEC on the target property classes (bounded-delay, liveness). Because the binary reward directly filters rollouts and scales the forward-KL term, uncharacterized false-positive rates on the very templates where prior models collapse would systematically reinforce non-equivalent SVA and undermine the central claim.
Authors: We acknowledge that precision, recall, and human-agreement figures for the PEC are missing from §3. The revised version will include a dedicated evaluation subsection (or appendix) reporting these metrics on held-out bounded-delay and liveness properties, together with measured false-positive rates. While the underlying SymbiYosys+Z3 checker is a formal tool whose soundness limits false positives, we will supply the requested empirical characterization to address the concern directly. revision: yes
Circularity Check
No significant circularity; external verifier grounds reward
full rationale
The RWOPD derivation samples student rollouts and weights the forward-KL term using scores from the independent open SymbiYosys+Z3 Property-Equivalence Checker. This external binary signal (property-equivalent vs. not) is not defined inside the training loop or by any self-citation chain, nor does any equation reduce the loss to a fitted parameter renamed as prediction. Results are reported on held-out NL2SVA-Human and NL2SVA-Machine benchmarks with standard pass@k, keeping the central claim externally falsifiable rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The SymbiYosys+Z3 Property-Equivalence Checker correctly identifies whether a generated SVA is logically equivalent to a reference property.
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal et al. On-policy distillation of language models: Learning from self-generated mistakes. InProceedings of the International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[2]
A general theoretical paradigm to understand learning from human preferences
Mohammad Gheshlaghi Azar, Daniel Guo, Bilal Piot, Remi Munos, Mark Rowland, Michal Valko, and Daniele Calandriello. A general theoretical paradigm to understand learning from human preferences. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), 2024
work page 2024
-
[3]
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. In Proceedings of the International Conference on Machine Learning (ICML), pages 41–48, 2009
work page 2009
-
[4]
Symbolic model checking without BDDs
Armin Biere, Alessandro Cimatti, Edmund Clarke, and Yunshan Zhu. Symbolic model checking without BDDs. InProceedings of the International Conference on Tools and Algorithms for the Construction and Analysis of Systems (TACAS), pages 193–207, 1999
work page 1999
-
[5]
Evaluating Large Language Models Trained on Code
Mark Chen et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Model checking
Edmund M Clarke. Model checking. InInternational conference on foundations of software technology and theoretical computer science, pages 54–56. Springer, 1997
1997
-
[7]
Training Verifiers to Solve Math Word Problems
Karl Cobbe et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Z3: An efficient SMT solver
Leonardo de Moura and Nikolaj Bjørner. Z3: An efficient SMT solver. InProceedings of the International Conference on Tools and Algorithms for the Construction and Analysis of Systems (TACAS), pages 337–340, 2008
2008
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. InNeurIPS Deep Learning Workshop, 2014. arXiv:1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[11]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InProceedings of the International Conference on Learning Representations (ICLR), 2022
work page 2022
-
[12]
Qwen2.5-Coder Technical Report
Binyuan Hui et al. Qwen2.5-Coder technical report.arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Fveval: Understand- ing language model capabilities in formal verification of digital hardware
Minwoo Kang, Mingjie Liu, Ghaith Bany Hamad, Syed M Suhaib, and Haoxing Ren. Fveval: Understand- ing language model capabilities in formal verification of digital hardware. In2025 Design, Automation & Test in Europe Conference (DATE), pages 1–6. IEEE, 2025
2025
-
[14]
StarCoder: may the source be with you!
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. Starcoder: may the source be with you!arXiv preprint arXiv:2305.06161, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InProceedings of the International Conference on Learning Representations (ICLR), 2024. arXiv:2305.20050
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Hongqin Lyu, Yunlin Du, Yonghao Wang, Zhiteng Chao, Tiancheng Wang, and Huawei Li. Assertfix: Empowering automated assertion fix via large language models.arXiv preprint arXiv:2509.23972, 2025
-
[17]
Mehta.SystemVerilog Assertions and Functional Coverage: Guide to Language, Methodology and Applications
Ashok B. Mehta.SystemVerilog Assertions and Functional Coverage: Guide to Language, Methodology and Applications. Springer, 3 edition, 2020
2020
-
[18]
Code Llama: Open Foundation Models for Code
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Yosys-a free verilog synthesis suite
Clifford Wolf, Johann Glaser, and Johannes Kepler. Yosys-a free verilog synthesis suite. InProceedings of the 21st Austrian Workshop on Microelectronics (Austrochip), volume 97, pages 1–6, 2013
2013
-
[21]
Yutong Wu, Chenrui Cao, Pengwei Jin, Di Huang, Rui Zhang, Xishan Zhang, Zidong Du, Qi Guo, and Xing Hu. Qimeng-codev-sva: Training specialized llms for hardware assertion generation via rtl-grounded bidirectional data synthesis.arXiv preprint arXiv:2603.14239, 2026
-
[22]
Assertllm: Generating hardware verification assertions from design specifications via multi-llms
Zhiyuan Yan, Wenji Fang, Mengming Li, Min Li, Shang Liu, Zhiyao Xie, and Hongce Zhang. Assertllm: Generating hardware verification assertions from design specifications via multi-llms. InProceedings of the 30th Asia and South Pacific Design Automation Conference, pages 614–621, 2025
2025
-
[23]
An Yang et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 10 A Terminology and Benchmark Composition Terminology.Table 3 summarizes the main abbreviations used in the paper. We use TCL and its C1/C2/C3 classes only as a diagnostic description of temporal-operator structure; semantic correctness is measured by JasperGold pass@kand, for t...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
/proc/.*\/stat
Yet Pilots 3, 4, 4b, 5, and 6 all evaluate at or below the SFT-50% baseline at every checkpoint. The disconnect is the training-vs-evaluation distribution gap: the multi-reference pool is built by paraphrasing NL2SV A-Machine, which uses synthetic signal names (sig_F, sig_H, . . . ), while NL2SV A-Human uses real-world signal naming. The policy fits the t...
2016
-
[25]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.