Recognition: unknown
Many-Shot CoT-ICL: Making In-Context Learning Truly Learn
Pith reviewed 2026-05-14 19:12 UTC · model grok-4.3
The pith
Many-shot chain-of-thought in-context learning behaves as test-time learning when demonstrations are ordered for smooth conceptual progression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
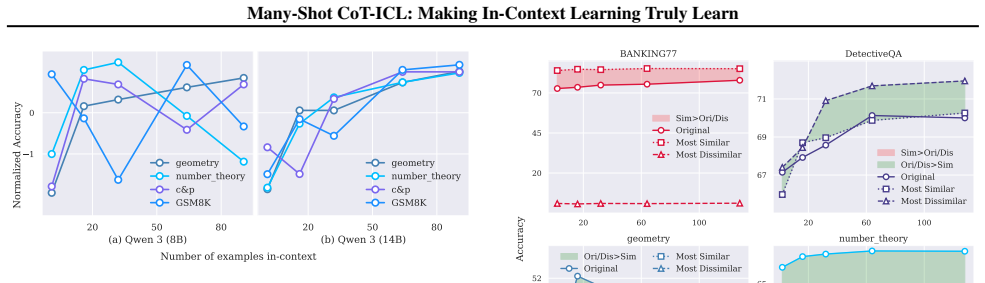
Across both reasoning and non-reasoning LLMs and tasks, many-shot CoT-ICL exhibits a setting-dependent scaling effect, fails under similarity-based retrieval because semantic similarity poorly predicts CoT compatibility, and displays growing performance variance with demonstration order. Viewing the setup as in-context test-time learning rather than scaled pattern matching yields two principles: demonstrations should be easy for the target model to understand and should be ordered to support smooth conceptual progression. Guided by these principles, Curvilinear Demonstration Selection produces consistent gains, reframing the long context window as a structured curriculum.
What carries the argument
Curvilinear Demonstration Selection (CDS), an ordering method that arranges demonstrations to follow a smooth conceptual progression so the model can perform in-context test-time learning.
If this is right
- Reasoning-oriented models benefit from many more CoT demonstrations once ordering respects conceptual progression.
- Similarity-based retrieval must be replaced by procedural-compatibility measures for reasoning tasks.
- Performance variance grows with demonstration count unless order supports smooth progression.
- Long context windows function as curricula rather than simple retrieval buffers.
Where Pith is reading between the lines
- The same ordering principle could be applied to non-reasoning tasks by first identifying what the model finds easy to parse.
- Models might internally assess demonstration difficulty and reorder prompts dynamically at inference time.
- Curriculum design for in-context learning could be tested on tasks beyond geometry by measuring step-by-step mastery.
- If test-time learning is the mechanism, training objectives that reward smooth progression in synthetic data might amplify the effect.
Load-bearing premise
The observed gains arise because ordered demonstrations enable the model to perform test-time learning rather than because of raw prompt length or model-specific artifacts.
What would settle it
Randomly ordering the same 64 demonstrations or replacing the curvilinear order with any non-progressive sequence should produce comparable accuracy gains if the test-time learning account is incorrect.
Figures













read the original abstract
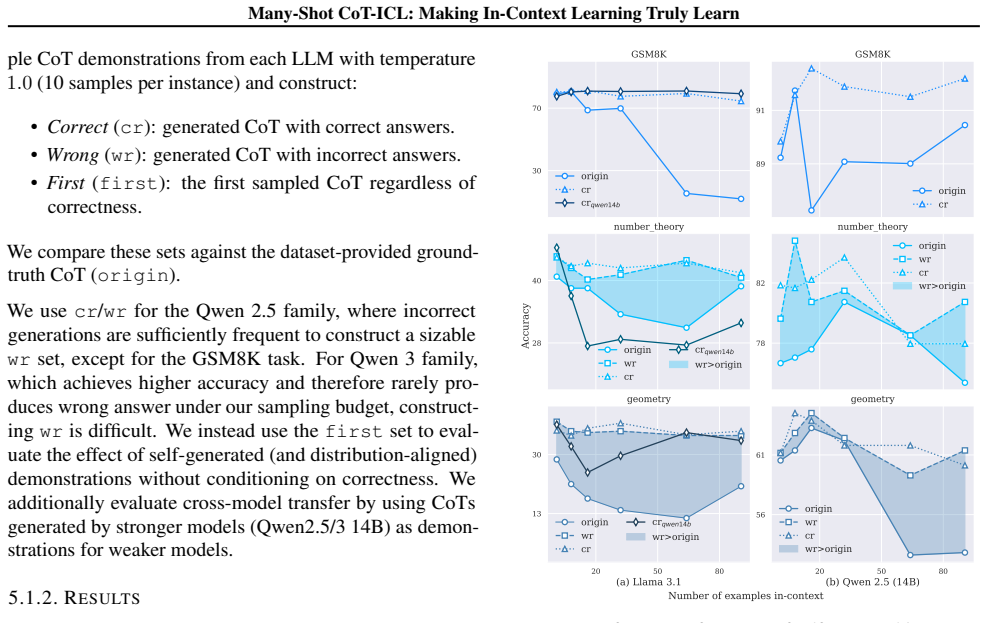
In-context learning (ICL) adapts large language models (LLMs) to new tasks by conditioning on demonstrations in the prompt without parameter updates. With long-context models, many-shot ICL can use dozens to hundreds of examples and achieve performance comparable to fine-tuning, yet current understanding of its scaling behavior is largely derived from non-reasoning tasks. We study many-shot chain-of-thought in-context learning (CoT-ICL) for reasoning and show that standard many-shot rules do not transfer. Across non-reasoning and reasoning-oriented LLMs and across non-reasoning and reasoning tasks, we find: (i) a setting-dependent scaling effect, where increasing the number of CoT demonstrations is unstable for non-reasoning LLMs and benefits mainly reasoning-oriented LLMs; (ii) similarity-based retrieval helps on non-reasoning tasks but fails on reasoning, since semantic similarity poorly predicts procedural (i.e., CoT) compatibility; and (iii) an order-scaling effect, where performance variance grows with more CoT demonstrations. We interpret these behaviors by viewing many-shot CoT-ICL as in-context test-time learning rather than scaled pattern matching, and suggests two principles: (i) demonstrations should be easy for the target model to understand, and (ii) they should be ordered to support a smooth conceptual progression. Guided by the principle, we propose Curvilinear Demonstration Selection (CDS), a simple ordering method that yields up to a 5.42 percentage-point gain on geometry with 64 demonstrations. Overall, our results reframe the long context window from a retrieval buffer into a structured curriculum for in-context test-time learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies many-shot chain-of-thought in-context learning (CoT-ICL) for reasoning tasks. It reports three main empirical patterns: (i) a setting-dependent scaling effect in which adding more CoT demonstrations is unstable for non-reasoning LLMs but beneficial for reasoning-oriented models; (ii) failure of semantic similarity retrieval on reasoning tasks because it does not capture procedural compatibility; and (iii) an order-scaling effect in which performance variance grows with the number of demonstrations. The authors interpret these behaviors as evidence that many-shot CoT-ICL functions as in-context test-time learning rather than scaled pattern matching, propose two guiding principles (demonstrations should be easy for the model to understand and should be ordered for smooth conceptual progression), and introduce Curvilinear Demonstration Selection (CDS) as a concrete ordering heuristic that yields up to a 5.42 percentage-point gain on geometry tasks with 64 demonstrations.
Significance. If the central empirical patterns and the attribution of gains to ordering hold, the work supplies a useful conceptual reframing of long-context ICL as structured curriculum-style learning and a practical, low-overhead method (CDS) that improves reasoning performance. The cross-model and cross-task consistency of the reported scaling behaviors is a positive feature that could inform future prompt-engineering practice.
major comments (3)
- [CDS description and associated experiments] The experiments do not appear to ablate ordering while holding the exact demonstration set fixed. Consequently it remains unclear whether the reported 5.42 pp gain on geometry with 64 shots is produced by the curvilinear sequence itself or by the upstream selection of high-quality or procedurally compatible examples. This distinction is load-bearing for the claim that principle (ii) (smooth conceptual progression) explains the order-scaling effect and for the test-time-learning interpretation.
- [Experimental results and methods] The results sections provide no variance measures (standard deviations or confidence intervals across random seeds or runs), no exact operationalization of the CDS curvilinear ordering procedure, and no explicit controls for prompt-length or token-budget confounds when scaling from few-shot to 64-shot regimes. These omissions weaken the support for both the scaling-effect claims and the performance gains attributed to CDS.
- [Discussion and interpretation] The interpretation of many-shot CoT-ICL as in-context test-time learning is offered as a post-hoc reframing of the observed behaviors. No direct diagnostic experiments (e.g., incremental probing of concept acquisition or comparison against non-ordered but equally informative demonstration sets) are reported that would distinguish this account from alternative explanations such as improved coverage or reduced example interference.
minor comments (2)
- [Methods] Define 'reasoning-oriented LLMs' versus 'non-reasoning LLMs' more explicitly in the methods section, including the criteria used for classification.
- [Figures and tables] Add error bars or confidence intervals to all performance plots and tables that report scaling curves.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which has helped us strengthen the empirical rigor and clarity of the manuscript. We have revised the paper to address the concerns about ablations, variance reporting, method operationalization, and controls. Below we respond point-by-point to each major comment.
read point-by-point responses
-
Referee: [CDS description and associated experiments] The experiments do not appear to ablate ordering while holding the exact demonstration set fixed. Consequently it remains unclear whether the reported 5.42 pp gain on geometry with 64 shots is produced by the curvilinear sequence itself or by the upstream selection of high-quality or procedurally compatible examples. This distinction is load-bearing for the claim that principle (ii) (smooth conceptual progression) explains the order-scaling effect and for the test-time-learning interpretation.
Authors: We agree that isolating the contribution of ordering requires holding the demonstration set fixed. In the revised manuscript we have added a controlled ablation on the geometry task with 64 shots: we fix the exact set of demonstrations selected by CDS and compare performance under (a) the original curvilinear order versus (b) a random permutation of the same set. The curvilinear order yields a statistically significant improvement over random order on the fixed set, supporting that the ordering itself drives part of the gain and bolstering the smooth-progression principle. We have also clarified in Section 4.2 that CDS first selects candidates by procedural compatibility heuristics and then orders them; the new ablation separates these stages. revision: yes
-
Referee: [Experimental results and methods] The results sections provide no variance measures (standard deviations or confidence intervals across random seeds or runs), no exact operationalization of the CDS curvilinear ordering procedure, and no explicit controls for prompt-length or token-budget confounds when scaling from few-shot to 64-shot regimes. These omissions weaken the support for both the scaling-effect claims and the performance gains attributed to CDS.
Authors: We acknowledge these omissions. The revised version now reports standard deviations across five independent runs (different random seeds for ordering and model sampling) for all scaling curves and CDS results. We have added a precise algorithmic description of CDS, including pseudocode for the curvilinear traversal, in the methods section. To address token-budget confounds, we include a controlled experiment that truncates all prompts to the same maximum token length when scaling from 4 to 64 shots; the reported scaling trends and CDS gains remain consistent under this control. revision: yes
-
Referee: [Discussion and interpretation] The interpretation of many-shot CoT-ICL as in-context test-time learning is offered as a post-hoc reframing of the observed behaviors. No direct diagnostic experiments (e.g., incremental probing of concept acquisition or comparison against non-ordered but equally informative demonstration sets) are reported that would distinguish this account from alternative explanations such as improved coverage or reduced example interference.
Authors: The test-time-learning framing is indeed interpretive and derived from the combination of the three observed patterns rather than from dedicated diagnostic probes. We have expanded the discussion to explicitly contrast this account with alternatives (improved coverage, reduced interference) and to acknowledge the absence of incremental probing experiments as a limitation. The new fixed-set ordering ablation helps differentiate ordering effects from pure coverage, but we agree that stronger causal evidence would require additional experiments (e.g., step-wise concept probes) that are beyond the scope of the current revision. revision: partial
- Direct diagnostic experiments (incremental probing of concept acquisition) to causally distinguish the test-time learning interpretation from alternatives such as coverage or interference.
Circularity Check
No significant circularity; claims rest on empirical observations and heuristic proposal
full rationale
The paper reports empirical scaling effects for many-shot CoT-ICL, interprets them as in-context test-time learning, states two principles, and introduces CDS as a simple ordering heuristic guided by those principles. No derivation reduces by construction to its inputs: there are no equations, no fitted parameters renamed as predictions, no self-citations invoked as uniqueness theorems, and no ansatz smuggled via prior work. Performance gains are presented as experimental results on specific tasks and models rather than tautological outcomes of the framing itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs perform in-context test-time learning that improves when demonstrations are ordered for smooth conceptual progression
Reference graph
Works this paper leans on
-
[1]
Selection-p: Self-Supervised Task-Agnostic Prompt Compression for Faithfulness and Transferability
Chung, Tsz Ting and Cui, Leyang and Liu, Lemao and Huang, Xinting and Shi, Shuming and Yeung, Dit-Yan. Selection-p: Self-Supervised Task-Agnostic Prompt Compression for Faithfulness and Transferability. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.646
-
[2]
Induction Heads as an Essential Mechanism for Pattern Matching in In-context Learning
Crosbie, Joy and Shutova, Ekaterina. Induction Heads as an Essential Mechanism for Pattern Matching in In-context Learning. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.283
- [3]
-
[4]
The Stochastic Parrot on LLM ' s Shoulder: A Summative Assessment of Physical Concept Understanding
Yu, Mo and Liu, Lemao and Wu, Junjie and Chung, Tsz Ting and Zhang, Shunchi and Li, Jiangnan and Yeung, Dit-Yan and Zhou, Jie. The Stochastic Parrot on LLM ' s Shoulder: A Summative Assessment of Physical Concept Understanding. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human...
-
[5]
Chung, Tsz Ting and Liu, Lemao and Yu, Mo and Yeung, Dit-Yan. D iv L ogic E val: A Framework for Benchmarking Logical Reasoning Evaluation in Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.47
-
[6]
arXiv preprint arXiv:2009.07896 (2020)
Captum: A unified and generic model interpretability library for PyTorch , year =. arXiv , author =:2009.07896 , primaryclass =
-
[7]
Measuring Mathematical Problem Solving With the MATH Dataset , year =
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , journal =. Measuring Mathematical Problem Solving With the MATH Dataset , year =
-
[8]
Training Verifiers to Solve Math Word Problems , url =
Cobbe, Karl and Kosaraju, Vineet and Bavarian, Mohammad and Chen, Mark and Jun, Heewoo and Kaiser, Lukasz and Plappert, Matthias and Tworek, Jerry and Hilton, Jacob and Nakano, Reiichiro and Hesse, Christopher and Schulman, John , journal =. Training Verifiers to Solve Math Word Problems , url =
-
[9]
Increasing Naturalness and Flexibility in Spoken Dialogue Interaction , doi =
Benchmarking Natural Language Understanding Services for Building Conversational Agents , url =. Increasing Naturalness and Flexibility in Spoken Dialogue Interaction , doi =
-
[10]
Efficient Intent Detection with Dual Sentence Encoders , url =
Casanueva, I. Efficient Intent Detection with Dual Sentence Encoders , url =. Proceedings of the 2nd Workshop on Natural Language Processing for Conversational AI , doi =
-
[11]
Proceedings of the first international conference on Human language technology research , year=
Toward semantics-based answer pinpointing , author=. Proceedings of the first international conference on Human language technology research , year=
-
[12]
Advances in neural information processing systems , volume=
Superglue: A stickier benchmark for general-purpose language understanding systems , author=. Advances in neural information processing systems , volume=
-
[13]
Qwen2.5 Technical Report , url =
Qwen and : and An Yang and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoran Wei and Huan Lin and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and Jingren Zhou and Junyang Lin and Kai Dang and Keming Lu and Keqin Bao and Kexin Yang and Le Yu an...
-
[14]
In-context learning with long-context models: An in-depth exploration , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
work page 2025
-
[15]
Alfred V. Aho and Jeffrey D. Ullman , publisher =. The Theory of Parsing, Translation and Compiling , volume =
-
[16]
Publications Manual , year =
-
[17]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , doi =. Alternation , volume =. Journal of the Association for Computing Machinery , number =
-
[18]
Mohammad Sadegh Rasooli and Joel R. Tetreault , journal =. Yara Parser:
-
[19]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , volume =
Ando, Rie Kubota and Zhang, Tong , issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , volume =. Journal of Machine Learning Research , numpages =
-
[20]
Advances in Neural Information Processing Systems , volume=
Many-shot in-context learning , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Test-Time Preference Optimization: On-the-Fly Alignment via Iterative Textual Feedback , url =
Yafu Li and Xuyang Hu and Xiaoye Qu and Linjie Li and Yu Cheng , journal =. Test-Time Preference Optimization: On-the-Fly Alignment via Iterative Textual Feedback , url =
-
[22]
Dr.ICL: Demonstration-Retrieved In-context Learning , url =
Man Luo and Xin Xu and Zhuyun Dai and Panupong Pasupat and Mehran Kazemi and Chitta Baral and Vaiva Imbrasaite and Vincent Y Zhao , journal =. Dr.ICL: Demonstration-Retrieved In-context Learning , url =
-
[23]
What Makes Good In-Context Examples for
Liu, Jiachang and Shen, Dinghan and Zhang, Yizhe and Dolan, Bill and Carin, Lawrence and Chen, Weizhu , booktitle =. What Makes Good In-Context Examples for. doi:10.18653/v1/2022.deelio-1.10 , editor =
-
[24]
Wu, Zhiyong and Wang, Yaoxiang and Ye, Jiacheng and Kong, Lingpeng , booktitle =. Self-Adaptive In-Context Learning: An Information Compression Perspective for In-Context Example Selection and Ordering , url =. doi:10.18653/v1/2023.acl-long.79 , editor =
-
[25]
Exploring the Role of Diversity in Example Selection for In-Context Learning , url =
Janak Kapuriya and Manit Kaushik and Debasis Ganguly and Sumit Bhatia , journal =. Exploring the Role of Diversity in Example Selection for In-Context Learning , url =
-
[26]
Wenhu Chen and Xueguang Ma and Xinyi Wang and William W. Cohen , issn =. Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks , url =. Transactions on Machine Learning Research , note =
-
[27]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[28]
L., Liu, Y ., Shang, N., Sun, Y ., Zhu, Y ., Yang, F., and Yang, M
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking , year =. arXiv , author =:2501.04519 , primaryclass =
-
[29]
Yiran Ding and Li Lyna Zhang and Chengruidong Zhang and Yuanyuan Xu and Ning Shang and Jiahang Xu and Fan Yang and Mao Yang , bibsource =. LongRoPE: Extending. Forty-first International Conference on Machine Learning,
-
[30]
Han, Chi and Wang, Qifan and Peng, Hao and Xiong, Wenhan and Chen, Yu and Ji, Heng and Wang, Sinong , booktitle =
-
[31]
YaRN: Efficient Context Window Extension of Large Language Models , url =
Bowen Peng and Jeffrey Quesnelle and Honglu Fan and Enrico Shippole , bibsource =. YaRN: Efficient Context Window Extension of Large Language Models , url =. The Twelfth International Conference on Learning Representations,
-
[32]
Long-context LLMs Struggle with Long In-context Learning , url =
Tianle Li and Ge Zhang and Quy Duc Do and Xiang Yue and Wenhu Chen , journal =. Long-context LLMs Struggle with Long In-context Learning , url =
-
[33]
Revisiting In-Context Learning with Long Context Language Models , url =
Jinheon Baek and Sun Jae Lee and Prakhar Gupta and Geunseob Oh and Siddharth Dalmia and Prateek Kolhar , journal =. Revisiting In-Context Learning with Long Context Language Models , url =
-
[34]
Advances in neural information processing systems , volume=
Large language models are zero-shot reasoners , author=. Advances in neural information processing systems , volume=
-
[35]
International Conference on Machine Learning , pages=
Transformers learn in-context by gradient descent , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[36]
In-context learning and gradient descent revisited , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
work page 2024
-
[37]
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
Min, Sewon and Lyu, Xinxi and Holtzman, Ari and Artetxe, Mikel and Lewis, Mike and Hajishirzi, Hannaneh and Zettlemoyer, Luke , booktitle =. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? , url =. doi:10.18653/v1/2022.emnlp-main.759 , editor =
-
[38]
An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels , url =
Sorensen, Taylor and Robinson, Joshua and Rytting, Christopher and Shaw, Alexander and Rogers, Kyle and Delorey, Alexia and Khalil, Mahmoud and Fulda, Nancy and Wingate, David , booktitle =. An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels , url =. doi:10.18653/v1/2022.acl-long.60 , editor =
-
[39]
How Do In-Context Examples Affect Compositional Generalization? , url =
An, Shengnan and Lin, Zeqi and Fu, Qiang and Chen, Bei and Zheng, Nanning and Lou, Jian-Guang and Zhang, Dongmei , booktitle =. How Do In-Context Examples Affect Compositional Generalization? , url =. doi:10.18653/v1/2023.acl-long.618 , editor =
-
[40]
Costas Mavromatis and Balasubramaniam Srinivasan and Zhengyuan Shen and Jiani Zhang and Huzefa Rangwala and Christos Faloutsos and George Karypis , journal =. Which Examples to Annotate for In-Context Learning? Towards Effective and Efficient Selection , url =
-
[41]
Charlie Victor Snell and Jaehoon Lee and Kelvin Xu and Aviral Kumar , booktitle =. Scaling
-
[42]
Let's Verify Step by Step , url =
Hunter Lightman and Vineet Kosaraju and Yuri Burda and Harrison Edwards and Bowen Baker and Teddy Lee and Jan Leike and John Schulman and Ilya Sutskever and Karl Cobbe , bibsource =. Let's Verify Step by Step , url =. The Twelfth International Conference on Learning Representations,
-
[43]
The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning , url =
Bill Yuchen Lin and Abhilasha Ravichander and Ximing Lu and Nouha Dziri and Melanie Sclar and Khyathi Raghavi Chandu and Chandra Bhagavatula and Yejin Choi , bibsource =. The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning , url =. The Twelfth International Conference on Learning Representations,
-
[44]
Automatic Chain of Thought Prompting in Large Language Models , url =
Zhuosheng Zhang and Aston Zhang and Mu Li and Alex Smola , bibsource =. Automatic Chain of Thought Prompting in Large Language Models , url =. The Eleventh International Conference on Learning Representations,
-
[45]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[46]
Mo Yu and Tsz Ting Chung and Chulun Zhou and Tong Li and Rui Lu and Jiangnan Li and Liyan Xu and Haoshu Lu and Ning Zhang and Jing Li and Jie Zhou , journal =. PRELUDE: A Benchmark Designed to Require Global Comprehension and Reasoning over Long Contexts , url =
-
[47]
Deep Research Agents: A Systematic Examination And Roadmap , url =
Yuxuan Huang and Yihang Chen and Haozheng Zhang and Kang Li and Huichi Zhou and Meng Fang and Linyi Yang and Xiaoguang Li and Lifeng Shang and Songcen Xu and Jianye Hao and Kun Shao and Jun Wang , journal =. Deep Research Agents: A Systematic Examination And Roadmap , url =
-
[48]
Computers & Geosciences , volume=
Principal components analysis (PCA) , author=. Computers & Geosciences , volume=. 1993 , publisher=
work page 1993
-
[49]
Umap: Uniform manifold approximation and projection for dimension reduction , url =
McInnes, Leland and Healy, John and Melville, James , journal =. Umap: Uniform manifold approximation and projection for dimension reduction , url =
-
[50]
Scaling llm test-time compute optimally can be more effective than scaling model parameters , url =
Snell, Charlie and Lee, Jaehoon and Xu, Kelvin and Kumar, Aviral , journal =. Scaling llm test-time compute optimally can be more effective than scaling model parameters , url =
-
[51]
Encyclopedia of infant and early childhood development , author=. 2020 , publisher=
work page 2020
-
[52]
A method for solving traveling-salesman problems , volume =
Croes, Georges A , journal =. A method for solving traveling-salesman problems , volume =
-
[53]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , url =
Yanzhao Zhang and Mingxin Li and Dingkun Long and Xin Zhang and Huan Lin and Baosong Yang and Pengjun Xie and An Yang and Dayiheng Liu and Junyang Lin and Fei Huang and Jingren Zhou , journal =. Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , url =
-
[54]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Qwen3 Technical Report , url =
An Yang and Anfeng Li and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Gao and Chengen Huang and Chenxu Lv and Chujie Zheng and Dayiheng Liu and Fan Zhou and Fei Huang and Feng Hu and Hao Ge and Haoran Wei and Huan Lin and Jialong Tang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and...
-
[56]
DetectiveQA: Evaluating Long-Context Reasoning on Detective Novels , url =
Zhe Xu and Jiasheng Ye and Xiaoran Liu and Xiangyang Liu and Tianxiang Sun and Zhigeng Liu and Qipeng Guo and Linlin Li and Qun Liu and Xuanjing Huang and Xipeng Qiu , journal =. DetectiveQA: Evaluating Long-Context Reasoning on Detective Novels , url =
-
[57]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[58]
Gonzalez and Hao Zhang and Ion Stoica , booktitle =
Woosuk Kwon and Zhuohan Li and Siyuan Zhuang and Ying Sheng and Lianmin Zheng and Cody Hao Yu and Joseph E. Gonzalez and Hao Zhang and Ion Stoica , booktitle =. Efficient Memory Management for Large Language Model Serving with PagedAttention , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.