Recognition: 2 theorem links
· Lean TheoremTemper and Tilt Lead to SLOP: Reward Hacking Mitigation with Inference-Time Alignment
Pith reviewed 2026-05-14 20:23 UTC · model grok-4.3
The pith
Adjusting reference-model temperature generalizes inference-time alignment to ensembles of reward models as a sharpened logarithmic opinion pool whose weights can be calibrated to reduce reward hacking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By introducing reference-model temperature adjustment, inference-time alignment generalizes to ensembles of generative reward models combined as a sharpened logarithmic opinion pool (SLOP). A calibration algorithm for SLOP weight parameters mitigates reward hacking and experimentally improves robustness while preserving alignment performance.
What carries the argument
sharpened logarithmic opinion pool (SLOP) formed from temperature-adjusted reference models
If this is right
- Calibrating SLOP weights reduces reward hacking while alignment performance remains comparable to standard inference-time methods.
- Temperature adjustment extends the theoretical justification of tilted sampling to combined reward-model ensembles.
- Inference-time alignment becomes usable with evolving or multi-objective reward targets without retraining.
- The method offers a practical complement to reinforcement learning for continual adaptation of alignment objectives.
Where Pith is reading between the lines
- The same temperature-plus-calibration pattern could be tested on open-ended generation tasks beyond the paper's reported setups to check scaling behavior.
- SLOP calibration might interact with other ensemble techniques already used for safety in language models, offering a route to hybrid defenses.
- Dynamic re-calibration of weights during a single inference session could be explored as an extension to handle shifting user preferences in real time.
Load-bearing premise
The calibration algorithm for SLOP weights generalizes beyond the specific experimental setups and does not introduce new instabilities when applied to ensembles.
What would settle it
Running the calibrated SLOP on a fresh collection of reward models or tasks and observing an increase in reward hacking compared with uncalibrated baselines would falsify the robustness claim.
Figures

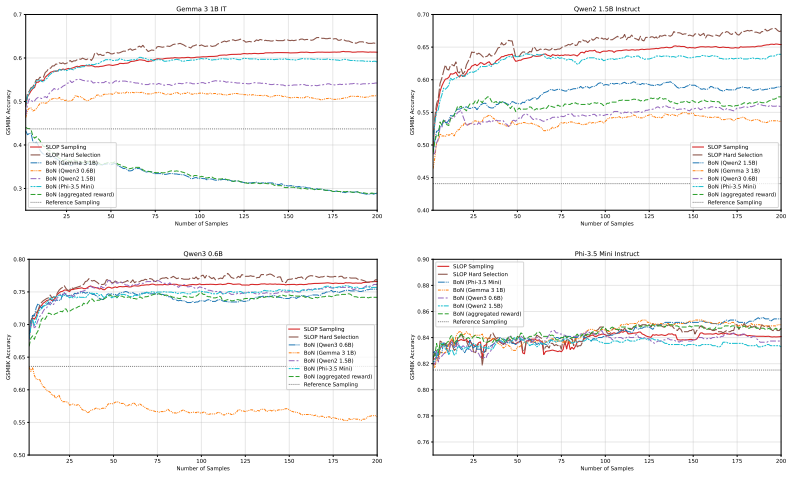











read the original abstract
Inference-time alignment techniques offer a lightweight alternative or complement to costly reinforcement learning, while enabling continual adaptation as alignment objectives and reward targets evolve. Existing theoretical analyses justify these methods as approximations to sampling from distributions optimally tilted toward a given reward model. We extend these techniques by introducing reference-model temperature adjustment, which leads to further generalization of inference-time alignment to ensembles of generative reward models combined as a sharpened logarithmic opinion pool (SLOP). To mitigate reward hacking, we propose an algorithm for calibrating SLOP weight parameters and experimentally demonstrate that it improves robustness while preserving alignment performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends existing theoretical analyses of inference-time alignment as tilted sampling approximations by introducing reference-model temperature adjustment. This leads to a generalization to ensembles of generative reward models combined as a sharpened logarithmic opinion pool (SLOP). The authors propose an algorithm for calibrating SLOP weight parameters to mitigate reward hacking and provide experimental demonstrations that the approach improves robustness while preserving alignment performance.
Significance. If the calibration procedure generalizes and the experimental robustness gains hold beyond the tested setups, the work would offer a practical, low-cost inference-time complement to RL-based alignment that supports continual adaptation to evolving reward targets.
major comments (2)
- [Abstract and §4] Abstract and §4 (experimental results): the central claim that the calibration algorithm improves robustness rests on experimental demonstration, yet the provided details omit explicit baselines, metrics, statistical significance tests, and ablations on ensemble diversity; this leaves open whether gains are general or artifacts of specific reward models and tasks.
- [§3] §3 (method): the extension of temperature-adjusted tilting to SLOP ensembles assumes that rescaling preserves the original approximation guarantees without new instabilities or over-sharpening modes, but no explicit bounds, convergence analysis, or formal justification for the weight calibration procedure is supplied to support this step.
minor comments (2)
- [§2] Notation for SLOP should be introduced with a clear contrast to standard logarithmic opinion pools to prevent reader confusion.
- [Figures and Tables] Figure captions and table legends would benefit from explicit statements of the number of runs and error bars used.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our work extending inference-time alignment to SLOP ensembles. Below, we respond to each major comment and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (experimental results): the central claim that the calibration algorithm improves robustness rests on experimental demonstration, yet the provided details omit explicit baselines, metrics, statistical significance tests, and ablations on ensemble diversity; this leaves open whether gains are general or artifacts of specific reward models and tasks.
Authors: We agree that additional experimental details are necessary to strengthen the claims. In the revised manuscript, we will include comparisons against standard baselines such as single reward model tilting and uncalibrated SLOP. We will report metrics including reward scores, diversity measures, and human preference evaluations where applicable. Statistical significance will be assessed using paired t-tests or bootstrap methods across multiple runs. Furthermore, we will add ablations varying the number of ensemble members and their diversity (e.g., using different reward model architectures or training data). These additions should clarify that the robustness gains are not artifacts of specific setups. revision: yes
-
Referee: [§3] §3 (method): the extension of temperature-adjusted tilting to SLOP ensembles assumes that rescaling preserves the original approximation guarantees without new instabilities or over-sharpening modes, but no explicit bounds, convergence analysis, or formal justification for the weight calibration procedure is supplied to support this step.
Authors: The referee correctly notes the absence of formal analysis. Our approach builds directly on the tilted sampling approximations from prior work, with the temperature adjustment and SLOP combination preserving the core structure. We will expand §3 to include a heuristic justification based on the properties of logarithmic opinion pools, which are known to sharpen distributions while maintaining mode-seeking behavior. We will also discuss potential instabilities such as over-sharpening and how the calibration algorithm mitigates them through empirical validation. However, deriving explicit bounds or a full convergence analysis for the calibrated SLOP would require new theoretical tools and is beyond the scope of this paper; we acknowledge this as a limitation and suggest it as future work. revision: partial
- Deriving explicit theoretical bounds and convergence guarantees for the SLOP weight calibration procedure
Circularity Check
No significant circularity; derivation extends prior analyses with independent proposals
full rationale
The paper builds on existing theoretical analyses of inference-time methods as tilted sampling approximations, then introduces reference-model temperature adjustment to generalize to SLOP ensembles and proposes a calibration algorithm for SLOP weights, which is experimentally demonstrated. No load-bearing step reduces by construction to fitted inputs, self-definitions, or self-citation chains; the new claims rest on the proposed extensions and empirical results rather than renaming or re-deriving the inputs. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- SLOP weight parameters
axioms (1)
- domain assumption Existing theoretical analyses justify inference-time alignment methods as approximations to sampling from distributions optimally tilted toward a given reward model
invented entities (1)
-
SLOP (sharpened logarithmic opinion pool)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearπ∗α,β(y|x) = p(y|x)^α q(y|x)^β / Z ; SLOP as softmax(∑ ω_i s_i) with calibration via Algorithm 1 maximizing empirical gold reward
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclearreference-model temperature adjustment leading to sharpened logarithmic opinion pool
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, Alon Benhaim, Misha Bilenko, Johan Bjorck, Sébastien Bubeck, Martin Cai, Qin Cai, Vishrav Chaudhary, Dong Chen, Dongdong Chen, Weizhu Chen, Yen-Chun Chen, Yi-Ling Chen, Hao Cheng, Parul Chopra, Xiyang Dai, Matt...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Gholamali Aminian, Idan Shenfeld, Amir R Asadi, Ahmad Beirami, and Youssef Mroueh. Best-of-n through the smoothing lens: KL divergence and regret analysis.arXiv preprint arXiv:2507.05913,
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Reward-augmented decoding: Efficient controlled text generation with a unidirectional reward model
Haikang Deng and Colin Raffel. Reward-augmented decoding: Efficient controlled text generation with a unidirectional reward model. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 11781–11791,
2023
-
[7]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Regularized best-of-n sampling with minimum bayes risk objective for language model alignment
Yuu Jinnai, Tetsuro Morimura, Kaito Ariu, and Kenshi Abe. Regularized best-of-n sampling with minimum bayes risk objective for language model alignment. InProceedings of the 2025 Con- ference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), pages 9321–9347,
2025
-
[9]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
On reinforcement learning and distribution matching for fine-tuning language models with no catastrophic forgetting
Tomasz Korbak, Hady Elsahar, Germán Kruszewski, and Marc Dymetman. On reinforcement learning and distribution matching for fine-tuning language models with no catastrophic forgetting. Advances in Neural Information Processing Systems, 35:16203–16220, 2022a. Tomasz Korbak, Ethan Perez, and Christopher Buckley. RL with KL penalties is better viewed as bayes...
2022
-
[11]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. WebGPT: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, et al. Deepseekmath: Pushing the limits of mathematical reason- ing in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jianxin Yang, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Fine-Tuning Language Models from Human Preferences
Joy Qiping Yang, Salman Salamatian, Ziteng Sun, Ananda Theertha Suresh, and Ahmad Beirami. Asymptotics of language model alignment. In2024 IEEE International Symposium on Information Theory (ISIT), pages 2027–2032. IEEE, 2024b. Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine...
work page internal anchor Pith review Pith/arXiv arXiv 2027
-
[15]
For this example, the expected reward is given by Ex∼D,y∼π ∗ω(y|x)[g(x, y)] =ρ ω1 log p1(1|0) p1(0|0) +ρ ω1 log p1(0|1) p1(1|1) ,(22) as a function of two log-likelihood ratios
SLOP, π∗ ω(y|x) = softmax(ω 1 logp 1(y|x)) =ρ ω1 log p1(y|x) p1(1−y|x) ,(21) where ρ(z) := 1/(1 + exp(−z)) is the sigmoid function, and we assume that p1(y|x)∈(0,1) for allx, y∈ {0,1}. For this example, the expected reward is given by Ex∼D,y∼π ∗ω(y|x)[g(x, y)] =ρ ω1 log p1(1|0) p1(0|0) +ρ ω1 log p1(0|1) p1(1|1) ,(22) as a function of two log-likelihood ra...
2025
-
[16]
Final answer:
Proxy ( = 0, = ) Figure 3: SLOP with Gemma-3-4B paired with synthetic proxy reward with varying accuracy, evaluated on SQA. The VLM is prompted with image and question text pairs from the SQA dataset, preceded by the following system prompt: A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful answers to the ...
2014
-
[17]
Figure 5: Optimized (two-expert) SLOP weights for SQA. Figures 10, 11, 12, and 13 depict further SLOP experiment ablation results with weights chosen via the calibration score mean and covariance, or with fixed uniform weights, as described in Section 3.3. For these ablations, we generally applied hard selection. F Datasets and models For the visual quest...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.