Recognition: unknown
AttenA+: Rectifying Action Inequality in Robotic Foundation Models
Pith reviewed 2026-05-14 18:39 UTC · model grok-4.3
The pith
Reweighting robotic action losses by inverse velocity improves foundation model performance on manipulation tasks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Robotic foundation models are limited by an implicit assumption of temporal homogeneity that assigns uniform importance to all actions during optimization. AttenA+ introduces velocity-driven action attention that reweights the loss function by the inverse velocity field, thereby aligning model capacity with the physical hierarchy of manipulation where slow segments demand greater precision. This architecture-agnostic enhancement integrates directly into existing backbones and produces measurable gains on long-horizon benchmarks while preserving the original model structure.
What carries the argument
velocity-driven action attention, a reweighting of the training loss by the inverse of the action velocity field that prioritizes low-speed, precision-critical segments
If this is right
- OpenVLA-OFT reaches 98.6 percent success on the Libero benchmark, a 1.5 percent gain over the prior baseline
- FastWAM reaches 92.4 percent on RoboTwin 2.0, a 0.6 percent gain
- The method attaches to any existing backbone without structural modifications or added parameters
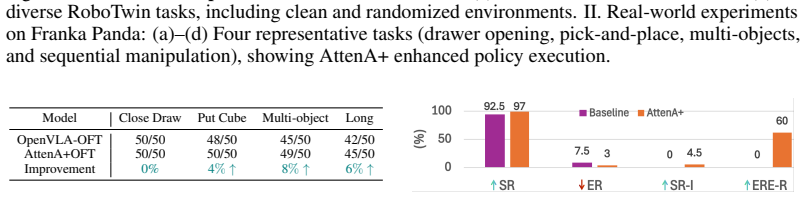
- Real-world deployment on a Franka manipulator demonstrates robustness and cross-task generalization
Where Pith is reading between the lines
- The same inverse-rate reweighting could be tested on other sequential control domains where speed varies, such as autonomous navigation or animation synthesis
- Alternative proxies for criticality, such as contact force or acceleration, could be substituted for velocity to check whether the gains persist
- The result implies that future scaling efforts in robotics may benefit more from embedding physical sequence structure than from data volume alone
Load-bearing premise
That velocity is the right proxy for kinematic criticality and that inverse-velocity reweighting will automatically focus learning on the segments that most affect task success.
What would settle it
Training with the AttenA+ reweighting on a manipulation task where success depends mainly on high-velocity actions would produce equal or lower performance than uniform weighting.
Figures












read the original abstract
Existing robotic foundation models, while powerful, are predicated on an implicit assumption of temporal homogeneity: treating all actions as equally informative during optimization. This "flat" training paradigm, inherited from language modeling, remains indifferent to the underlying physical hierarchy of manipulation. In reality, robot trajectories are fundamentally heterogeneous, where low-velocity segments often dictate task success through precision-demanding interactions, while high-velocity motions serve as error-tolerant transitions. Such a misalignment between uniform loss weighting and physical criticality fundamentally limits the performance of current Vision-Language-Action (VLA) models and World-Action Models (WAM) in complex, long-horizon tasks. To rectify this, we introduce AttenA+, an architecture-agnostic framework that prioritizes kinematically critical segments via velocity-driven action attention. By reweighting the training objective based on the inverse velocity field, AttenA+ naturally aligns the model's learning capacity with the physical demands of manipulation. As a plug-and-play enhancement, AttenA+ can be integrated into existing backbones without structural modifications or additional parameters. Extensive experiments demonstrate that AttenA+ significantly elevates the ceilings of current state-of-the-art models. Specifically, it improves OpenVLA-OFT to 98.6% (+1.5%) on the Libero benchmark and pushes FastWAM to 92.4% (+0.6%) on RoboTwin 2.0. Real-world validation on a Franka manipulator further showcases its robustness and cross-task generalization. Our work suggests that mining the intrinsic structural priors of action sequences offers a highly efficient, physics-aware complement to standard scaling laws, paving a new path for general-purpose robotic control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AttenA+, an architecture-agnostic, parameter-free framework that reweights the training objective of Vision-Language-Action (VLA) and World-Action Models (WAM) using the inverse velocity field. This prioritizes low-velocity segments presumed to be kinematically critical for manipulation success, addressing the assumed temporal homogeneity of standard uniform-loss training. The manuscript reports concrete gains when applied to existing backbones: OpenVLA-OFT reaches 98.6% (+1.5%) on Libero and FastWAM reaches 92.4% (+0.6%) on RoboTwin 2.0, with additional real-world validation on a Franka manipulator.
Significance. If the velocity-specific mechanism can be isolated and the gains replicated with proper controls, the work supplies a lightweight, physics-motivated complement to scaling that exploits intrinsic structure in action sequences. The absence of added parameters and the plug-and-play nature make the approach attractive for existing robotic foundation models, provided the central causal claim holds.
major comments (2)
- [§4 (Experimental Evaluation)] The experimental results (abstract and §4) report specific percentage improvements (+1.5% on Libero, +0.6% on RoboTwin) but supply no information on baseline implementations, number of random seeds, statistical tests, data splits, or variance. This renders the quantitative claims unverifiable and prevents assessment of whether the reported ceilings are robust.
- [§3 (Method) and §4] The central claim that gains arise specifically because inverse-velocity reweighting aligns learning capacity with kinematic criticality is not isolated from generic non-uniform weighting. No ablation compares the proposed scheme against controls such as random weights with matched statistics or reweighting by action norm (or other proxies). Without these, the physics-aware interpretation and the 'rectifying action inequality' framing remain unsupported.
minor comments (2)
- [§3] Notation for the reweighting factor (inverse velocity field) is introduced without an explicit equation number or derivation showing how it is computed from raw trajectories; a short formal definition would improve clarity.
- [Abstract and §4] The abstract states 'extensive experiments' yet provides no table or figure summarizing all evaluated backbones, tasks, and metrics in one place; a consolidated results table would aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of experimental rigor and causal isolation. We address each major point below and will revise the manuscript to strengthen the presentation of results and supporting evidence.
read point-by-point responses
-
Referee: [§4 (Experimental Evaluation)] The experimental results (abstract and §4) report specific percentage improvements (+1.5% on Libero, +0.6% on RoboTwin) but supply no information on baseline implementations, number of random seeds, statistical tests, data splits, or variance. This renders the quantitative claims unverifiable and prevents assessment of whether the reported ceilings are robust.
Authors: We agree that the current version lacks sufficient detail on the experimental protocol. In the revised manuscript we will add a dedicated subsection under §4 that specifies: (i) exact baseline implementations and training hyperparameters, (ii) number of random seeds (we will report results over at least three seeds), (iii) data splits used for Libero and RoboTwin, (iv) statistical tests performed, and (v) mean and standard deviation of success rates. This will allow readers to assess robustness directly. revision: yes
-
Referee: [§3 (Method) and §4] The central claim that gains arise specifically because inverse-velocity reweighting aligns learning capacity with kinematic criticality is not isolated from generic non-uniform weighting. No ablation compares the proposed scheme against controls such as random weights with matched statistics or reweighting by action norm (or other proxies). Without these, the physics-aware interpretation and the 'rectifying action inequality' framing remain unsupported.
Authors: We acknowledge that the present experiments do not yet isolate the velocity-specific mechanism from generic non-uniform weighting. To address this, the revised §4 will include two new ablations: (1) random reweighting drawn from the same distribution as the inverse-velocity weights, and (2) reweighting proportional to action-norm magnitude. These controls will be run on the same backbones and benchmarks, allowing direct comparison of success rates and thereby testing whether the kinematic motivation is necessary for the observed gains. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines AttenA+ explicitly as reweighting the training objective by the inverse velocity field drawn from physical trajectory measurements, independent of the final benchmark numbers. The reported gains on Libero (98.6%) and RoboTwin (92.4%) are presented as empirical outcomes of applying this externally motivated rule rather than as predictions that reduce to a fit or self-definition. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the core mechanism, and the architecture-agnostic plug-and-play framing does not rely on any load-bearing reduction to prior author work or fitted parameters. The derivation therefore remains self-contained against external physical priors.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Robot trajectories are fundamentally heterogeneous, with low-velocity segments dictating task success through precision-demanding interactions.
invented entities (1)
-
AttenA+ framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Daojie Peng, Fulong Ma, and Jun Ma. Structured observation language for efficient and generalizable vision-language navigation.arXiv preprint arXiv:2603.27577, 2026
-
[4]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[6]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Lovon: Legged open-vocabulary object navigator
Daojie Peng, Jiahang Cao, Qiang Zhang, and Jun Ma. Lovon: Legged open-vocabulary object navigator. arXiv preprint arXiv:2507.06747, 2025
-
[10]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. pi05: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Compose your policies! improving diffusion-based or flow-based robot policies via test-time distribution-level composition
Jiahang Cao, Yize Huang, Hanzhong Guo, Qiang Zhang, Rui Zhang, Weijian Mai, Mu Nan, Jiaxu Wang, Hao Cheng, Jingkai SUN, Gang Han, Wen Zhao, Yijie Guo, Qihao Zheng, Xiao Li, Chunfeng Song, Ping Luo, and Andrew Luo. Compose your policies! improving diffusion-based or flow-based robot policies via test-time distribution-level composition. InThe Fourteenth In...
2026
-
[12]
Robot data curation with mutual information estimators.arXiv preprint arXiv:2502.08623, 2025
Joey Hejna, Suvir Mirchandani, Ashwin Balakrishna, Annie Xie, Ayzaan Wahid, Jonathan Tompson, Pannag Sanketi, Dhruv Shah, Coline Devin, and Dorsa Sadigh. Robot data curation with mutual information estimators.arXiv preprint arXiv:2502.08623, 2025
-
[13]
Motus: A Unified Latent Action World Model
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, et al. Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Causal World Modeling for Robot Control
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.arXiv preprint arXiv:2306.03310, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Xiaohuan Pei, Yuxing Chen, Siyu Xu, Yunke Wang, Yuheng Shi, and Chang Xu. Action-aware dynamic pruning for efficient vision-language-action manipulation.arXiv preprint arXiv:2509.22093, 2025
-
[20]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. Smolvla: A vision-language- action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Nora: A small open-sourced generalist vision language action model for embodied tasks, 2025
Chia-Yu Hung, Qi Sun, Pengfei Hong, Amir Zadeh, Chuan Li, U Tan, Navonil Majumder, Soujanya Poria, et al. Nora: A small open-sourced generalist vision language action model for embodied tasks.arXiv preprint arXiv:2504.19854, 2025
-
[23]
Ye Li, Yuan Meng, Zewen Sun, Kangye Ji, Chen Tang, Jiajun Fan, Xinzhu Ma, Shutao Xia, Zhi Wang, and Wenwu Zhu. Sp-vla: A joint model scheduling and token pruning approach for vla model acceleration. arXiv preprint arXiv:2506.12723, 2025
-
[24]
Xudong Tan, Yaoxin Yang, Peng Ye, Jialin Zheng, Bizhe Bai, Xinyi Wang, Jia Hao, and Tao Chen. Think twice, act once: Token-aware compression and action reuse for efficient inference in vision-language-action models.arXiv preprint arXiv:2505.21200, 2025
-
[25]
Siyu Xu, Yunke Wang, Chenghao Xia, Dihao Zhu, Tao Huang, and Chang Xu. Vla-cache: Towards efficient vision-language-action model via adaptive token caching in robotic manipulation.arXiv preprint arXiv:2502.02175, 2025
-
[26]
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InEuropean Conference on Computer Vision, pages 19–35. Springer, 2024
2024
-
[27]
arXiv preprint arXiv:2410.04417 (2024)
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al. Sparsevlm: Visual token sparsification for efficient vision-language model inference.arXiv preprint arXiv:2410.04417, 2024
-
[28]
Xiaohuan Pei, Tao Huang, and Chang Xu. Cross-self kv cache pruning for efficient vision-language inference.arXiv preprint arXiv:2412.04652, 2024
-
[29]
Fast-WAM: Do World Action Models Need Test-time Future Imagination?
Tianyuan Yuan, Zibin Dong, Yicheng Liu, and Hang Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipula- tion with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[32]
Coarse-to-fine imitation learning: Learning faster from heterogeneous demonstrations.Advances in Neural Information Processing Systems, 32, 2019
Daniel S Brown, Scott Niekum, and Marek Petrik. Coarse-to-fine imitation learning: Learning faster from heterogeneous demonstrations.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[33]
Robust imitation learning against heterogeneous demonstrations.Advances in Neural Information Processing Systems, 35:2104–2117, 2022
Tianwei Ren, Yutian Ma, Jiaming Li, Yuandong Tian, and Xiaolong Wang. Robust imitation learning against heterogeneous demonstrations.Advances in Neural Information Processing Systems, 35:2104–2117, 2022
2022
-
[34]
Ajay Mandlekar, Fabio Ramos, Byron Boots, Silvio Savarese, Li Fei-Fei, Animesh Garg, and Dieter Fox. Iris: Implicit reinforcement without interaction at scale for learning control from offline robot manipulation data.arXiv preprint arXiv:1911.05321, 2019. 11
-
[35]
Learning to weight states for imitation learning.Conference on Robot Learning, 2021
Rafael Mendonca, Xinyang Geng, Deepak Pathak, and Pulkit Agrawal. Learning to weight states for imitation learning.Conference on Robot Learning, 2021
2021
-
[36]
Spatial robograsp: Generalized robotic grasping control policy.arXiv preprint arXiv:2505.20814, 2025
Yiqi Huang, Travis Davies, Jiahuan Yan, Jiankai Sun, Xiang Chen, and Luhui Hu. Spatial robograsp: Generalized robotic grasping control policy.arXiv preprint arXiv:2505.20814, 2025
-
[37]
Interactive language: Talking to robots in real time.IEEE Robotics and Automation Letters, 2023
Corey Lynch, Ayzaan Wahid, Jonathan Tompson, Tianli Ding, James Betker, Robert Baruch, Travis Armstrong, and Pete Florence. Interactive language: Talking to robots in real time.IEEE Robotics and Automation Letters, 2023
2023
-
[38]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations.arXiv preprint arXiv:2403.03954, 2024
-
[39]
Mamba policy: Towards efficient 3d diffusion policy with hybrid selective state models
Jiahang Cao, Qiang Zhang, Jingkai Sun, Jiaxu Wang, Hao Cheng, Yulin Li, Jun Ma, Kun Wu, Zhiyuan Xu, Yecheng Shao, et al. Mamba policy: Towards efficient 3d diffusion policy with hybrid selective state models. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11359–11366. IEEE, 2025
2025
-
[40]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model.arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. Eva-clip: Improved training techniques for clip at scale.arXiv preprint arXiv:2303.15389, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
stack the blue block on the red block
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidi- rectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019. A Pr...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.