Recognition: 2 theorem links
· Lean TheoremQwen-Image-VAE-2.0 Technical Report
Pith reviewed 2026-05-14 19:48 UTC · model grok-4.3
The pith
Qwen-Image-VAE-2.0 delivers state-of-the-art image reconstruction at high compression ratios while accelerating diffusion model convergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
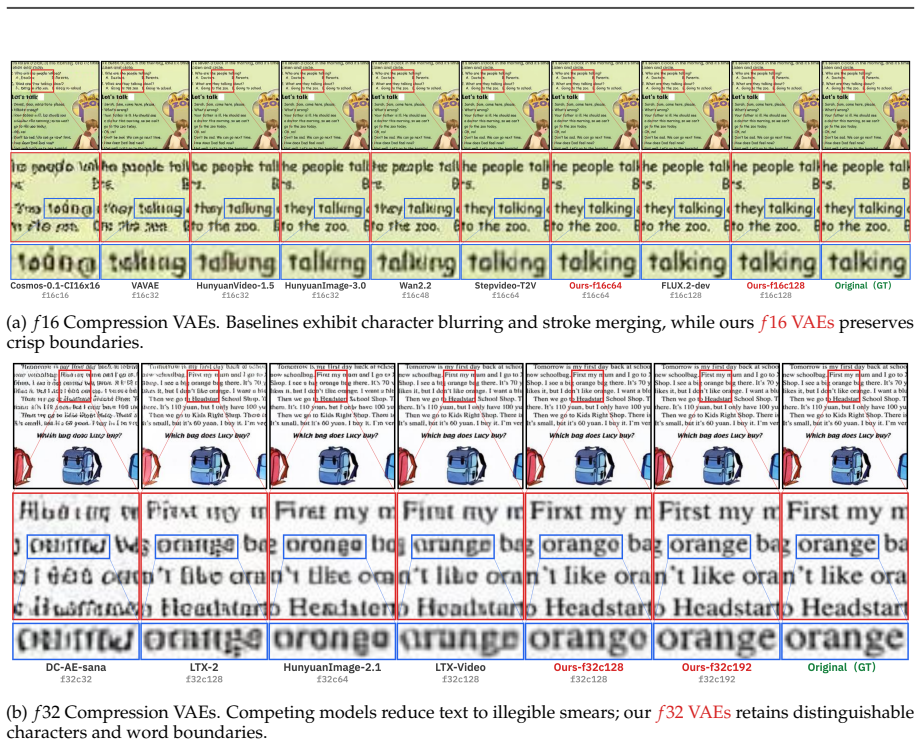
Qwen-Image-VAE-2.0 achieves state-of-the-art reconstruction performance in both general domains and text-rich scenarios at high compression ratios through an improved architecture featuring Global Skip Connections and expanded latent channels, scaled training to billions of images incorporating a synthetic rendering engine, and an enhanced semantic alignment strategy. Downstream DiT experiments demonstrate superior diffusability, with the models significantly accelerating convergence compared to existing high-compression baselines.
What carries the argument
Global Skip Connections and expanded latent channels inside an asymmetric attention-free encoder-decoder backbone, paired with semantic alignment of the high-dimensional latent space.
Load-bearing premise
That scaling training to billions of images together with synthetic rendering and semantic alignment will produce a high-dimensional latent space that is highly amenable to diffusion modeling without introducing new artifacts or domain biases.
What would settle it
DiT models trained on latents from Qwen-Image-VAE-2.0 fail to converge faster than those using prior high-compression VAEs, or reconstruction metrics on OmniDoc-TokenBench fall below current leading baselines.
Figures



read the original abstract
We present Qwen-Image-VAE-2.0, a suite of high-compression Variational Autoencoders (VAEs) that achieve significant advances in both reconstruction fidelity and diffusability. To address the reconstruction bottlenecks of high compression, we adopt an improved architecture featuring Global Skip Connections (GSC) and expanded latent channels. Moreover, we scale training to billions of images and incorporate a synthetic rendering engine to improve performance in text-rich scenarios. To tackle the convergence challenges of high-dimensional latent space, we implement an enhanced semantic alignment strategy to make the latent space highly amenable to diffusion modeling. To optimize computational efficiency, we leverage an asymmetric and attention-free encoder-decoder backbone to minimize encoding overhead. We present a comprehensive evaluation of Qwen-Image-VAE-2.0 on public reconstruction benchmarks. To evaluate performance in text-rich scenarios, we propose OmniDoc-TokenBench, a new benchmark comprising a diverse collection of real-world documents coupled with specialized OCR-based evaluation metrics. Qwen-Image-VAE-2.0 achieves state-of-the-art reconstruction performance, demonstrating exceptional capabilities in both general domains and text-rich scenarios at high compression ratio. Furthermore, downstream DiT experiments reveal our models possess superior diffusability, significantly accelerating convergence compared to existing high-compression baselines. These establish Qwen-Image-VAE-2.0 as a leading model with high compression, superior reconstruction, and exceptional diffusability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Qwen-Image-VAE-2.0, a suite of high-compression VAEs featuring Global Skip Connections, expanded latent channels, training scaled to billions of images with a synthetic rendering engine for text-rich data, and semantic alignment for diffusability. It claims SOTA reconstruction on public benchmarks and the new OmniDoc-TokenBench (real-world documents with OCR metrics), plus superior convergence acceleration in downstream DiT experiments versus high-compression baselines.
Significance. If the empirical results hold with quantitative support, the work would advance high-compression VAEs by showing that architectural tweaks plus large-scale synthetic data and alignment can yield latents that are both high-fidelity for text-rich content and more amenable to diffusion, potentially improving efficiency in latent diffusion pipelines.
major comments (2)
- [Abstract / Evaluation] Abstract and evaluation section: the SOTA reconstruction claim on OmniDoc-TokenBench for text-rich scenarios is load-bearing for the central contribution, yet the manuscript provides no ablation isolating the synthetic rendering engine nor distribution-matching diagnostics (e.g., font/layout statistics) between synthetic training data and the real-world benchmark documents; this leaves open the possibility that reported OCR gains reflect domain mismatch rather than genuine fidelity at high compression.
- [Downstream experiments] Downstream DiT experiments: the claim of significantly accelerated convergence requires explicit quantitative evidence (training curves, epoch counts to target FID, or final metrics) against clearly named high-compression baselines; without these, the diffusability advantage cannot be assessed as load-bearing.
minor comments (2)
- [Method] Define the precise latent channel count, compression ratio, and GSC implementation details with equations or pseudocode in the architecture section.
- [Evaluation] List all public reconstruction benchmarks by name and report standard metrics (PSNR, SSIM, LPIPS) alongside any custom ones for consistency.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will revise the manuscript to incorporate additional evidence and clarifications where appropriate.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation section: the SOTA reconstruction claim on OmniDoc-TokenBench for text-rich scenarios is load-bearing for the central contribution, yet the manuscript provides no ablation isolating the synthetic rendering engine nor distribution-matching diagnostics (e.g., font/layout statistics) between synthetic training data and the real-world benchmark documents; this leaves open the possibility that reported OCR gains reflect domain mismatch rather than genuine fidelity at high compression.
Authors: We agree that isolating the contribution of the synthetic rendering engine via ablation and providing distribution-matching diagnostics would further strengthen the SOTA claim. The current manuscript emphasizes end-to-end results on OmniDoc-TokenBench but does not include these specific analyses. In the revised version we will add an ablation comparing models trained with and without the synthetic rendering engine, together with quantitative comparisons of font distributions, layout complexity, and other relevant statistics between the synthetic training corpus and the real-world documents in OmniDoc-TokenBench. These additions will directly address the possibility of domain mismatch. revision: yes
-
Referee: [Downstream experiments] Downstream DiT experiments: the claim of significantly accelerated convergence requires explicit quantitative evidence (training curves, epoch counts to target FID, or final metrics) against clearly named high-compression baselines; without these, the diffusability advantage cannot be assessed as load-bearing.
Authors: We concur that explicit quantitative support is required to substantiate the diffusability advantage. While the manuscript reports superior convergence relative to high-compression baselines, it does not present the underlying training curves or precise metrics. In the revision we will include FID-versus-epoch training curves, epoch counts required to reach target FID thresholds, and final metrics for Qwen-Image-VAE-2.0 against clearly identified high-compression baselines (including the prior Qwen-Image-VAE and other standard high-compression VAEs). This will enable direct evaluation of the claimed acceleration. revision: yes
Circularity Check
No circularity: empirical architecture, training, and benchmark evaluation chain is self-contained
full rationale
The paper describes an architecture (GSC, expanded channels, asymmetric encoder-decoder), training procedure (scaling to billions of images plus synthetic rendering and semantic alignment), and reports direct empirical results on public reconstruction benchmarks plus the newly proposed OmniDoc-TokenBench with OCR metrics. All central claims (SOTA reconstruction fidelity and superior DiT diffusability) rest on these measurements rather than any equation, parameter fit, or self-citation that reduces the output to the input by construction. No uniqueness theorems, ansatzes smuggled via prior work, or renamed known results appear in the provided text. The derivation chain is the standard end-to-end training-plus-evaluation pipeline, which is externally falsifiable against the cited benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- latent channel count
- training data volume
axioms (1)
- domain assumption Standard VAE evidence lower bound remains valid under high compression and expanded latents
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We adopt an improved VAE architecture with Global Skip Connection (GSC)... semantic alignment loss Lalign which aligns latents to semantic counterparts extracted from pretrained encoders... Lmcos (z′,f) = 1/N ∑ ReLU(1−cos(z′p,fp)−mcos)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Qwen-Image-VAE-2.0-f16c128... NED 0.9617... superior diffusability... staged semantic alignment paradigm
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Perception Encoder: The best visual embeddings are not at the output of the network
Daniel Bolya, Po-Yao Huang, Peize Sun, Jang Hyun Cho, Andrea Madotto, Chen Wei, Tengyu Ma, Jiale Zhi, Jathushan Rajasegaran, Hanoona Rasheed, et al. Perception encoder: The best visual embeddings are not at the output of the network.arXiv preprint arXiv:2504.13181,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Hunyuanimage 3.0 technical report.arXiv preprint arXiv:2509.23951, 2025
Siyu Cao, Hangting Chen, Peng Chen, Yiji Cheng, Yutao Cui, Xinchi Deng, Ying Dong, Kipper Gong, Tianpeng Gu, Xiusen Gu, et al. Hunyuanimage 3.0 technical report.arXiv preprint arXiv:2509.23951,
-
[4]
PaddleOCR 3.0 Technical Report
URL https: //arxiv.org/abs/2507.05595. Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pp. 248–255. IEEE,
work page internal anchor Pith review arXiv
-
[5]
Yu Gao, Lixue Gong, Qiushan Guo, Xiaoxia Hou, Zhichao Lai, Fanshi Li, Liang Li, Xiaochen Lian, Chao Liao, Liyang Liu, et al. Seedream 3.0 technical report.arXiv preprint arXiv:2504.11346,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. Ltx-2: Efficient joint audio-visual foundation model.arXiv preprint arXiv:2601.03233,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks.2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4396–4405,
work page 2019
-
[10]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
URLhttps://api.semanticscholar.org/CorpusID:54482423. 13 Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Xi Liu, Rui Zhang, Yongsheng Zhou, Qianyi Jiang, Qi Song, Nan Li, Kai Zhou, Lei Wang, Dong Wang, Minghui Liao, Mingkun Yang, Xiang Bai, Baoguang Shi, Dimosthenis Karatzas, Shijian Lu, and C. V . Jawahar. Icdar 2019 robust reading challenge on reading chinese text on signboard.2019 International Conference on Document Analysis and Recognition (ICDAR), pp. ...
work page 2019
-
[12]
URL https://api.semanticscholar.org/CorpusID:209439793. Guoqing Ma, Haoyang Huang, Kun Yan, Liangyu Chen, Nan Duan, Shengming Yin, Changyi Wan, Ranchen Ming, Xiaoniu Song, Xing Chen, et al. Step-video-t2v technical report: The practice, challenges, and future of video foundation model.arXiv preprint arXiv:2502.10248,
-
[13]
DINOv2: Learning Robust Visual Features without Supervision
URL https://api.semanticscholar.org/CorpusID: 14851115. Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Linke Ouyang, Yuan Qu, Hongbin Zhou, Jiawei Zhu, Rui Zhang, Qunshu Lin, Bin Wang, Zhiyuan Zhao, Man Jiang, Xiaomeng Zhao, Jin Shi, Fan Wu, Pei Chu, Ming-Hao Liu, Zhenxiang Li, Chaoming Xu, Bo Zhang, Botian Shi, Zhongying Tu, and Conghui He. Omnidocbench: Benchmarking diverse pdf document parsing with comprehensive annotations.2025 IEEE/CVF Conference on C...
work page 2025
-
[15]
Image tokenizer needs post-training.arXiv preprint arXiv:2509.12474,
Kai Qiu, Xiang Li, Hao Chen, Jason Kuen, Xiaohao Xu, Jiuxiang Gu, Yinyi Luo, Bhiksha Raj, Zhe Lin, and Marios Savvides. Image tokenizer needs post-training.arXiv preprint arXiv:2509.12474,
-
[16]
Oriane Siméoni, Huy V Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Wan: Open and Advanced Large-Scale Video Generative Models
14 Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
HunyuanVideo 1.5 Technical Report
Bing Wu, Chang Zou, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Jack Peng, Jianbing Wu, Jiangfeng Xiong, Jie Jiang, et al. Hunyuanvideo 1.5 technical report.arXiv preprint arXiv:2511.18870, 2025a. Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.ar...
work page internal anchor Pith review arXiv
-
[19]
Qwen-Image-2.0 Technical Report
URL https://arxiv.org/abs/2605.10730. Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with representation autoencoders.arXiv preprint arXiv:2510.11690,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.