Recognition: unknown
Sparse Code Uplifting for Efficient 3D Language Gaussian Splatting
Pith reviewed 2026-05-14 19:22 UTC · model grok-4.3
The pith
Sparse code uplifting from 2D images to 3D Gaussians delivers up to 400 times faster training for open-vocabulary scene understanding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
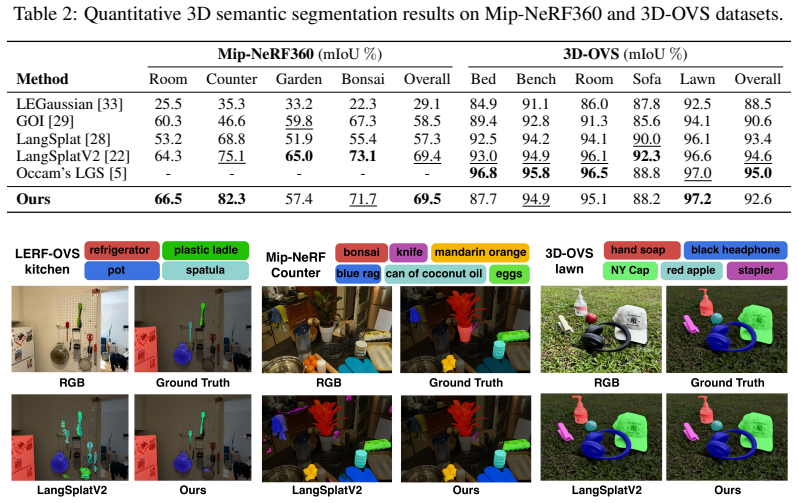
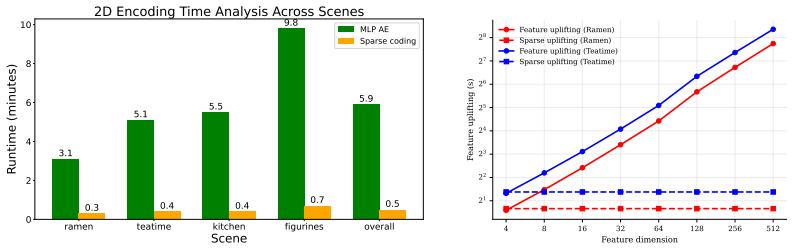
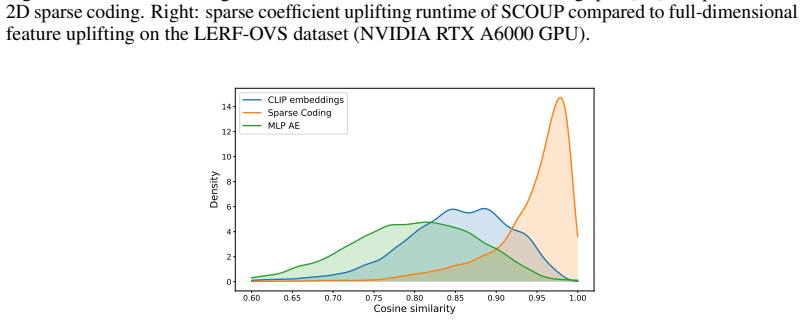
SCOUP learns sparse codebook representations entirely from 2D image regions, then uplifts the resulting coefficients to 3D Gaussians by weighted multi-view aggregation over Gaussian-to-pixel associations followed by Top-K filtering, yielding up to 400× training speedup, 3× memory savings during training, and open-vocabulary querying accuracy that matches or exceeds prior state-of-the-art methods.
What carries the argument
Sparse code uplifting, which extracts coefficients from 2D regions via a shared codebook and aggregates them to 3D Gaussians using multi-view weighting and Top-K filtering.
If this is right
- Training time for language-augmented 3D models falls by up to 400 times relative to current rendering-speed leaders.
- Peak memory use during training drops by a factor of three while still supporting fast feature rendering.
- Open-vocabulary 3D querying accuracy equals or exceeds existing methods on multiple public benchmarks.
- No repeated 3D feature rasterization or per-scene language optimization is required after the initial 2D codebook stage.
- Sparse coefficient storage on each Gaussian enables both compact models and rapid text-based queries.
Where Pith is reading between the lines
- The same 2D-to-3D uplifting pattern could be applied to other dense per-Gaussian attributes such as surface normals or material properties to reduce optimization cost.
- Because the method avoids scene-specific language fine-tuning, it may scale more readily to very large or streaming 3D environments than per-scene approaches.
- Lower training and memory footprints open the possibility of on-device or incremental updates for language-enabled 3D maps in robotics or AR settings.
- Testing whether Top-K filtering preserves distinctions between visually similar but semantically different objects would clarify the limits of the current aggregation step.
Load-bearing premise
Coefficients learned from 2D image regions can be uplifted to 3D Gaussians through weighted aggregation and Top-K filtering without substantial loss of semantic accuracy or extra per-scene optimization.
What would settle it
Train SCOUP on a standard 3D scene benchmark such as ScanNet or Replica, then compare open-vocabulary query accuracy and total training time against a baseline that optimizes language features directly on the 3D Gaussians; if accuracy stays within a few percent while training time drops by two orders of magnitude and peak memory falls by at least 2.5×, the central claim is supported.
Figures







read the original abstract
3D Language Gaussian Splatting (3DLGS) augments 3D Gaussian Splatting with language-aligned visual features for open-vocabulary 3D scene understanding. A core challenge is efficiently associating high-dimensional vision-language embeddings with millions of 3D Gaussians while preserving efficient feature rendering for text-based querying. Existing methods either store dense features directly on Gaussians, causing high storage costs and slow rendering, or learn compact representations through expensive per-scene optimization with repeated feature rasterization. No existing method simultaneously achieves fast 3D semantic reconstruction, efficient storage, and fast rendering. We propose SCOUP (Sparse COde UPlifting), which addresses all three by decoupling language representation learning from 3D Gaussian optimization. Rather than working directly in 3D, we learn sparse codebook-based representations entirely using features associated with 2D image regions, associating each region with a sparse set of codebook coefficients. We then uplift these coefficients to 3D Gaussians with our weighted sparse aggregation using Gaussian-to-pixel associations, where each Gaussian accumulates coefficients over codebook atoms across views. Top-$K$ filtering then extracts the most dominant multi-view coefficients per Gaussian, enabling efficient storage and fast rendering. Our method achieves up to $400\times$ training speedup while being $3\times$ more memory efficient during training compared to the state-of-the-art in rendering speed. Across multiple benchmarks, SCOUP matches or outperforms existing methods in open-vocabulary querying accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SCOUP (Sparse COde UPlifting) for 3D Language Gaussian Splatting. It decouples language feature learning from 3D Gaussian optimization by first learning sparse codebook coefficients exclusively from 2D image regions, then uplifting them to 3D Gaussians via weighted multi-view aggregation (using Gaussian-to-pixel associations) followed by Top-K filtering. The central claims are up to 400× training speedup, 3× greater memory efficiency during training versus prior rendering-speed leaders, and open-vocabulary querying accuracy that matches or exceeds existing methods across benchmarks.
Significance. If the uplift step is shown to preserve semantics, the work would offer a practical route to scalable 3D vision-language models by removing per-scene feature optimization. The decoupling of 2D codebook learning from 3D splatting could influence future efficient 3D scene-understanding pipelines, especially for large environments where training time and memory are bottlenecks.
major comments (2)
- [Method (uplift and Top-K filtering)] The accuracy-parity claim rests on the assumption that weighted multi-view aggregation plus Top-K filtering (described after the 2D codebook stage) transfers semantic content without substantial dilution from viewpoint variance or occlusion. No ablation or quantitative comparison (e.g., 2D-to-3D feature similarity or querying accuracy before/after uplift) is supplied to test this assumption, which is load-bearing for the claim that per-scene language optimization can be avoided.
- [Abstract and Experiments] The abstract asserts concrete efficiency numbers (400× speedup, 3× memory) and accuracy parity, yet the manuscript text contains no tables, error bars, ablation studies, or implementation details (codebook size, Top-K value, exact baselines) that would allow verification of these figures. This absence prevents assessment of whether the reported gains are robust or scene-dependent.
minor comments (1)
- [Method] Notation for the sparse coefficients and the exact aggregation weights should be introduced with a single equation or diagram early in the method section to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of our method's validation and presentation. We address each major comment below and commit to revisions that will strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Method (uplift and Top-K filtering)] The accuracy-parity claim rests on the assumption that weighted multi-view aggregation plus Top-K filtering (described after the 2D codebook stage) transfers semantic content without substantial dilution from viewpoint variance or occlusion. No ablation or quantitative comparison (e.g., 2D-to-3D feature similarity or querying accuracy before/after uplift) is supplied to test this assumption, which is load-bearing for the claim that per-scene language optimization can be avoided.
Authors: We agree that direct validation of semantic preservation during uplift is valuable for supporting the decoupling claim. The current manuscript demonstrates this indirectly through end-to-end open-vocabulary querying accuracy that matches or exceeds baselines across multiple benchmarks. To address the concern explicitly, we will add a new ablation subsection in the experiments that reports (i) cosine similarity between 2D region features and their uplifted 3D Gaussian counterparts and (ii) querying accuracy on held-out views before versus after the weighted aggregation and Top-K step. These results will be included in the revised manuscript. revision: yes
-
Referee: [Abstract and Experiments] The abstract asserts concrete efficiency numbers (400× speedup, 3× memory) and accuracy parity, yet the manuscript text contains no tables, error bars, ablation studies, or implementation details (codebook size, Top-K value, exact baselines) that would allow verification of these figures. This absence prevents assessment of whether the reported gains are robust or scene-dependent.
Authors: We acknowledge that the main text could present the supporting evidence more accessibly. The full manuscript and supplementary material already contain the relevant tables (reporting per-scene training time, memory usage, and accuracy metrics with standard deviations from three independent runs), hyperparameter details (codebook size 2048, Top-K=8, exact baselines including LangSplat and 3D-OVS), and scene-wise breakdowns. In the revision we will (i) move the primary efficiency and accuracy tables into the main paper, (ii) add explicit error bars, and (iii) expand the implementation details paragraph in Section 4 to list all hyperparameters and baseline configurations, ensuring the abstract claims are fully verifiable from the main text. revision: yes
Circularity Check
No circularity; uplift pipeline is a standard empirical construction on external 2D features and 3DGS associations
full rationale
The paper's core chain—learning sparse codebook coefficients exclusively from 2D image regions, then performing weighted multi-view aggregation via Gaussian-to-pixel associations followed by Top-K filtering—does not reduce any claimed accuracy metric or efficiency gain to a fitted parameter by definition. No equations redefine the open-vocabulary querying target in terms of the uplift outputs themselves, no self-citations supply load-bearing uniqueness theorems, and no ansatz is smuggled via prior work. Speedup and memory claims are presented as measured outcomes on benchmarks rather than tautological predictions. The method therefore remains self-contained against external 2D feature extractors and standard 3DGS projection machinery.
Axiom & Free-Parameter Ledger
free parameters (2)
- codebook size
- Top-K value
axioms (1)
- domain assumption Gaussian-to-pixel associations from standard 3D Gaussian Splatting are sufficiently accurate for reliable multi-view feature aggregation.
Reference graph
Works this paper leans on
-
[1]
GALA: Guided attention with language alignment for open vocabulary gaussian splatting
Elena Alegret, Kunyi Li, Sen Wang, Siyun Liang, Michael Niemeyer, Stefano Gasperini, Nassir Navab, and Federico Tombari. GALA: Guided attention with language alignment for open vocabulary gaussian splatting. InThirteenth International Conference on 3D Vision, 2026. URL https://openreview.net/forum?id=qDUUGCGL4i
2026
-
[2]
Barron, Ben Mildenhall, Dor Verbin, Pratul P
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields.2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5460–5469, 2021
2022
-
[3]
Gaussianeditor: Swift and controllable 3d editing with gaussian splatting.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21476–21485, 2023
Yiwen Chen, Zilong Chen, Chi Zhang, Feng Wang, Xiaofeng Yang, Yikai Wang, Zhongang Cai, Lei Yang, Huaping Liu, and Guosheng Lin. Gaussianeditor: Swift and controllable 3d editing with gaussian splatting.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21476–21485, 2023
2024
-
[4]
Zilong Chen, Feng Wang, Yikai Wang, and Huaping Liu. Text-to-3d using gaussian splatting. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21401–21412, 2024. doi: 10.1109/CVPR52733.2024.02022
-
[5]
Occam’s lgs: An efficient approach for language gaussian splatting
Jiahuan Cheng, Jan-Nico Zaech, Luc Van Gool, and Danda Pani Paudel. Occam’s lgs: An efficient approach for language gaussian splatting. In36th British Machine Vision Conference 2025, BMVC 2025, Sheffield, UK, November 24-27, 2025. BMV A, 2025. URL https:// bmva-archive.org.uk/bmvc/2025/assets/papers/Paper_694/paper.pdf
2025
-
[6]
What’s in the image? a deep-dive into the vision of vision language models
Zhenqi Dai, Ting Liu, and Yanning Zhang. Efficient decoupled feature 3d gaussian splatting via hierarchical compression. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11156–11166, 2025. doi: 10.1109/CVPR52734.2025.01042
-
[7]
Gaussianeditor: Editing 3d gaussians delicately with text instructions.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20902–20911, 2023
Jiemin Fang, Junjie Wang, Xiaopeng Zhang, Lingxi Xie, and Qi Tian. Gaussianeditor: Editing 3d gaussians delicately with text instructions.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20902–20911, 2023
2024
-
[8]
Visual language maps for robot navigation.2023 IEEE International Conference on Robotics and Automation (ICRA), pages 10608–10615, 2022
Chen Huang, Oier Mees, Andy Zeng, and Wolfram Burgard. Visual language maps for robot navigation.2023 IEEE International Conference on Robotics and Automation (ICRA), pages 10608–10615, 2022
2023
-
[9]
Openclip, July 2021
Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. Openclip, July 2021. URL https://doi.org/10.5281/ zenodo.5143773. If you use this software, please cite it as below
2021
-
[10]
Tenenbaum, Celso Miguel de Melo, Madhava Krishna, Liam Paull, Florian Shkurti, and Antonio Torralba
Krishna Murthy Jatavallabhula, Alihusein Kuwajerwala, Qiao Gu, Mohd Omama, Tao Chen, Shuang Li, Ganesh Iyer, Soroush Saryazdi, Nikhil Keetha, Ayush Tewari, Joshua B. Tenenbaum, Celso Miguel de Melo, Madhava Krishna, Liam Paull, Florian Shkurti, and Antonio Torralba. Conceptfusion: Open-set multimodal 3d mapping.Robotics: Science and Systems (RSS), 2023
2023
-
[11]
What’s in the image? a deep-dive into the vision of vision language models
Cijo Jose, Théo Moutakanni, Dahyun Kang, Federico Baldassarre, Timothée Darcet, Hu Xu, Daniel Li, Marc Szafraniec, Michaël Ramamonjisoa, Maxime Oquab, Oriane Siméoni, Huy V . V o, Patrick Labatut, and Piotr Bojanowski. Dinov2 meets text: A unified framework for image- and pixel-level vision-language alignment. In2025 IEEE/CVF Conference on Computer Vision...
-
[12]
Kim Jun-Seong, GeonU Kim, Kim Yu-Ji, Yu-Chiang Frank Wang, Jaesung Choe, and Tae- Hyun Oh. Dr. splat: Directly referring 3d gaussian splatting via direct language embedding registration. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14137–14146, 2025
2025
-
[13]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics (TOG), 42:1 – 14, 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkuehler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics (TOG), 42:1 – 14, 2023
2023
-
[14]
Lerf: Language embedded radiance fields.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 19672–19682, 2023
Justin Kerr, Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, and Matthew Tancik. Lerf: Language embedded radiance fields.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 19672–19682, 2023
2023
-
[15]
Jiwook Kim, Seonho Lee, Jaeyo Shin, Jiho Choi, and Hyunjung Shim. Dreamcatalyst: Fast and high-quality 3d editing via controlling editability and identity preservation.ArXiv, abs/2407.11394, 2024
-
[16]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Yoshua Bengio and Yann LeCun, editors,3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015. URL http://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[17]
Berg, Wan-Yen Lo, Piotr Dollár, and Ross B
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloé Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross B. Girshick. Segment anything.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 3992–4003, 2023
2023
-
[18]
Point-based neural rendering with per-view optimization.Computer Graphics Forum, 40, 2021
Georgios Kopanas, Julien Philip, Thomas Leimkühler, and George Drettakis. Point-based neural rendering with per-view optimization.Computer Graphics Forum, 40, 2021
2021
-
[19]
Cf3: Compact and fast 3d feature fields
Hyunjoon Lee, Joonkyu Min, and Jaesik Park. Cf3: Compact and fast 3d feature fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 27906– 27916, 2025
2025
-
[20]
Language- driven semantic segmentation
Boyi Li, Kilian Q Weinberger, Serge Belongie, Vladlen Koltun, and Rene Ranftl. Language- driven semantic segmentation. InInternational Conference on Learning Representations, 2022. URLhttps://openreview.net/forum?id=RriDjddCLN
2022
-
[21]
Hao Li, Roy Qin, Zhengyu Zou, Diqi He, Bohan Li, Bingquan Dai, Dingewn Zhang, and Junwei Han. Langsurf: Language-embedded surface gaussians for 3d scene understanding.arXiv preprint arXiv:2412.17635, 2024
-
[22]
Langsplatv2: High-dimensional 3d language gaussian splatting with 450+ fps.Advances in Neural Information Processing Systems, 2025
Wanhua Li, Yujie Zhao, Minghan Qin, Yang Liu, Yuanhao Cai, Chuang Gan, and Hanspeter Pfister. Langsplatv2: High-dimensional 3d language gaussian splatting with 450+ fps.Advances in Neural Information Processing Systems, 2025. URL https://arxiv.org/abs/2507. 07136
2025
-
[23]
Yixun Liang, Xin Yang, Jiantao Lin, Haodong Li, Xiaogang Xu, and Yingcong Chen. Lu- cidDreamer: Towards High-Fidelity Text-to-3D Generation via Interval Score Matching . In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6517–6526, Los Alamitos, CA, USA, June 2024. IEEE Computer Society. doi: 10.1109/CVPR52733.2024.00623. ...
-
[24]
Xing, and Shijian Lu
Kunhao Liu, Fangneng Zhan, Jiahui Zhang, Muyu Xu, Yingchen Yu, Abdulmotaleb El Saddik, Christian Theobalt, Eric P. Xing, and Shijian Lu. Weakly supervised 3d open-vocabulary segmentation. InNeural Information Processing Systems, 2023
2023
-
[25]
Ludvig: Learning-free uplifting of 2d visual features to gaussian splatting scenes
Juliette Marrie, Romain Menegaux, Michael Arbel, Diane Larlus, and Julien Mairal. Ludvig: Learning-free uplifting of 2d visual features to gaussian splatting scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. 11
2025
-
[26]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. InECCV, 2020
2020
-
[27]
Yuning Peng, Haiping Wang, Yuan Liu, Chenglu Wen, Zhen Dong, and Bisheng Yang. Gags: Granularity-aware feature distillation for language gaussian splatting.ArXiv, abs/2412.13654, 2024
-
[28]
Langsplat: 3d language gaussian splatting.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20051–20060, 2023
Minghan Qin, Wanhua Li, Jiawei Zhou, Haoqian Wang, and Hanspeter Pfister. Langsplat: 3d language gaussian splatting.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20051–20060, 2023
2024
-
[29]
Goi: Find 3d gaussians of interest with an optimizable open-vocabulary semantic- space hyperplane
Yansong Qu, Shaohui Dai, Xinyang Li, Jianghang Lin, Liujuan Cao, Shengchuan Zhang, and Rongrong Ji. Goi: Find 3d gaussians of interest with an optimizable open-vocabulary semantic- space hyperplane. InProceedings of the 32nd ACM International Conference on Multimedia, MM ’24, page 5328–5337, New York, NY , USA, 2024. Association for Computing Machinery. I...
-
[30]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInterna- tional Conference on Machine Learning, 2021
2021
-
[31]
Structure-from-motion revisited
Johannes Lutz Schönberger and Jan-Michael Frahm. Structure-from-motion revisited. In Conference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[32]
Pixelwise view selection for unstructured multi-view stereo
Johannes Lutz Schönberger, Enliang Zheng, Marc Pollefeys, and Jan-Michael Frahm. Pixelwise view selection for unstructured multi-view stereo. InEuropean Conference on Computer Vision (ECCV), 2016
2016
-
[33]
Language embedded 3d gaussians for open-vocabulary scene understanding.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5333–5343, 2023
Jin-Chuan Shi, Miao Wang, Hao-Bin Duan, and Shao-Hua Guan. Language embedded 3d gaussians for open-vocabulary scene understanding.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5333–5343, 2023
2024
-
[34]
arXiv preprint arXiv:2309.16653 , year=
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. Dreamgaussian: Generative gaussian splatting for efficient 3d content creation.arXiv preprint arXiv:2309.16653, 2023
-
[35]
Ccl-lgs: Contrastive codebook learning for 3d language gaussian splatting
Lei Tian, Xiaomin Li, Liqian Ma, Hao Yin, Zirui Zheng, Hefei Huang, Taiqing Li, Huchuan Lu, and Xu Jia. Ccl-lgs: Contrastive codebook learning for 3d language gaussian splatting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9855–9864, 2025
2025
-
[36]
Vrsplat: Fast and robust gaussian splatting for virtual reality.Proc
Xuechang Tu, Lukas Radl, Michael Steiner, Markus Steinberger, Bernhard Kerbl, and Fernando de la Torre. Vrsplat: Fast and robust gaussian splatting for virtual reality.Proc. ACM Comput. Graph. Interact. Tech., 8(1), May 2025. doi: 10.1145/3728311. URL https://doi.org/10. 1145/3728311
-
[37]
Visibility-aware language aggregation for open-vocabulary segmentation in 3d gaussian splatting
Sen Wang, Kunyi Li, Siyun Liang, Elena Alegret, Jing Ma, Nassir Navab, and Stefano Gasperini. Visibility-aware language aggregation for open-vocabulary segmentation in 3d gaussian splatting. ArXiv, abs/2509.05515, 2025
-
[38]
D 3fields: Dynamic 3d descriptor fields for zero-shot generalizable rearrangement
Yixuan Wang, Mingtong Zhang, Zhuoran Li, Tarik Kelestemur, Katherine Driggs-Campbell, Jiajun Wu, Li Fei-Fei, and Yunzhu Li. D 3fields: Dynamic 3d descriptor fields for zero-shot generalizable rearrangement. In8th Annual Conference on Robot Learning, 2024
2024
-
[39]
Dn-splatter: Depth and normal priors for gaussian splatting and meshing
Hanyuan Xiao, Yingshu Chen, Huajian Huang, Haolin Xiong, Jing Yang, Pratusha Prasad, and Yajie Zhao. Localized gaussian splatting editing with contextual awareness. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 5207–5217, 2025. doi: 10.1109/W ACV61041.2025.00509
work page doi:10.1109/w 2025
-
[40]
Ziyang Yan, Lei Li, Yihua Shao, Siyu Chen, Wuzong Kai, Jenq-Neng Hwang, Hao Zhao, and Fabio Remondino. 3dsceneeditor: Controllable 3d scene editing with gaussian splatting.arXiv preprint arXiv:2412.01583, 2024. 12
-
[41]
Gaussian grouping: Segment and edit anything in 3d scenes
Mingqiao Ye, Martin Danelljan, Fisher Yu, and Lei Ke. Gaussian grouping: Segment and edit anything in 3d scenes. InECCV, 2024
2024
-
[42]
Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields
Shijie Zhou, Haoran Chang, Sicheng Jiang, Zhiwen Fan, Zehao Zhu, Dejia Xu, Pradyumna Chari, Suya You, Zhangyang Wang, and Achuta Kadambi. Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21676–21685, 2024
2024
-
[43]
M. Zwicker, H. Pfister, J. van Baar, and M. Gross. Ewa volume splatting. InProceedings Visualization, 2001. VIS ’01., pages 29–538, 2001. doi: 10.1109/VISUAL.2001.964490. 13 Algorithm 1Sparse Code Uplifting forGaussian pointi∈ Ndo Initializew i ∈R L as the zero vector end for forframev∈ Vdo forpixelp∈Ω v do (indices{j 1, . . . , jK},coefficients{c j1 , . ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.