Recognition: no theorem link
Conformal Anomaly Detection in Python: Moving Beyond Heuristic Thresholds with 'nonconform'
Pith reviewed 2026-05-14 17:43 UTC · model grok-4.3
The pith
The nonconform package converts anomaly scores into calibrated p-values valid under data exchangeability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that the nonconform package implements conformal anomaly detection methods that convert existing anomaly scores into p-values with valid coverage under the exchangeability assumption, supports multiple calibration strategies, integrates directly with scikit-learn and pyod, and enables false-discovery-rate control, thereby allowing statistically principled anomaly detection without heuristic thresholds.
What carries the argument
The nonconform package, which supplies a unified interface that takes any anomaly detector, applies conformal calibration to produce p-values, and supports false-discovery-rate control.
If this is right
- Users can replace arbitrary score thresholds with explicit p-value cutoffs that control error rates.
- The same detector code works for both point-anomaly and group-anomaly tasks once wrapped by nonconform.
- Shift-aware conformal strategies inside the package reduce the data needed for reliable calibration.
- False-discovery-rate procedures become directly applicable to anomaly lists produced by the package.
Where Pith is reading between the lines
- The same wrapper pattern could be reused for other conformal guarantees such as prediction intervals.
- Empirical checks on mildly non-exchangeable data would quantify how quickly coverage degrades.
- Production pipelines could log the p-value distribution as a continuous monitor of exchangeability.
Load-bearing premise
The p-values remain valid only under the assumption of data exchangeability.
What would settle it
Generate p-values on a large set of exchangeable inliers with no anomalies present; the resulting p-values must be distributed uniformly on [0,1] or the calibration guarantee is violated.
Figures



read the original abstract
Most anomaly detection systems output scores rather than calibrated decisions, leaving practitioners to choose thresholds heuristically and without clear statistical interpretation. Conformal anomaly detection addresses this limitation by converting anomaly scores into calibrated p-values that are valid under the statistical assumption of data exchangeability, with a growing literature extending this idea beyond that setting. We present 'nonconform', a Python package for applying conformal anomaly detection within existing machine-learning workflows, and use it as the basis for an implementation-grounded introduction to the field. The package integrates with 'scikit-learn', 'pyod', and custom anomaly detectors, and provides a unified interface for calibration, p-value generation, and false discovery rate control. It supports several conformalization strategies, ranging from simple split-conformal calibration to more data-efficient and shift-aware extensions. Through a progression from foundational concepts to advanced conformalization strategies, complemented by code examples, the paper connects the statistical ideas behind conformal anomaly detection to their practical use in 'nonconform'. Empirical results demonstrate that the implemented methods enable statistically principled anomaly detection. Together, the package and exposition aim to make core conformal anomaly detection workflows more accessible and reproducible in experimental and production-oriented settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the 'nonconform' Python package for conformal anomaly detection. It integrates with scikit-learn and pyod to convert anomaly scores into exchangeability-calibrated p-values, supports split-conformal and shift-aware conformalization strategies, provides FDR control, and includes code examples plus empirical results that claim to demonstrate statistically principled anomaly detection.
Significance. If the empirical claims hold under realistic conditions, the package would make calibrated anomaly detection more accessible and reproducible for practitioners, reducing reliance on heuristic thresholds. The unified interface and support for extensions beyond basic exchangeability represent a practical contribution that could encourage wider adoption of conformal methods in anomaly detection workflows.
major comments (2)
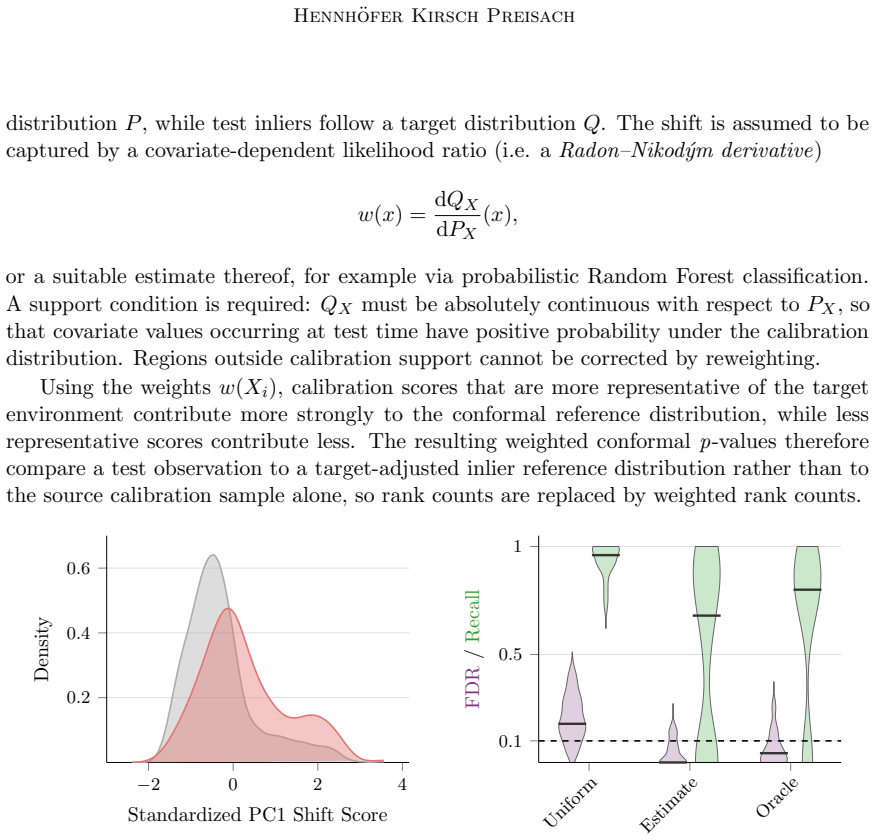
- [Empirical evaluation] Empirical evaluation section: The reported results demonstrate p-value calibration and FDR control only on synthetic data under full exchangeability. Because anomaly detection by definition involves non-exchangeable anomalies and real deployments frequently exhibit mild distribution shift or dependence, the experiments must include tests under such violations to substantiate the central claim that the methods enable 'statistically principled anomaly detection' in practice; otherwise the empirical support is weaker than stated.
- [§4] §4 (conformalization strategies): The description of shift-aware extensions is too brief to allow readers to assess whether they preserve marginal validity or FDR control when exchangeability is mildly violated; explicit statements of the assumptions retained by each strategy and a small simulation under controlled shift would strengthen the exposition.
minor comments (2)
- [Abstract] The abstract states that the package 'supports several conformalization strategies' but does not name them; listing the supported methods (e.g., split-conformal, inductive, etc.) would improve clarity.
- [Tutorial sections] Code examples in the tutorial sections would benefit from explicit handling of the case when the calibration set is empty or too small, as this is a common practical failure mode.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and have made revisions to strengthen the empirical support and exposition as suggested.
read point-by-point responses
-
Referee: [Empirical evaluation] Empirical evaluation section: The reported results demonstrate p-value calibration and FDR control only on synthetic data under full exchangeability. Because anomaly detection by definition involves non-exchangeable anomalies and real deployments frequently exhibit mild distribution shift or dependence, the experiments must include tests under such violations to substantiate the central claim that the methods enable 'statistically principled anomaly detection' in practice; otherwise the empirical support is weaker than stated.
Authors: We agree that the original experiments focused on the exchangeable setting to isolate and validate the core calibration guarantees. To better support the claim of practical utility, the revised manuscript now includes additional simulation studies under controlled distribution shifts and mild temporal dependence. These new results show that the p-values remain approximately valid and FDR control is largely preserved for the shift-aware strategies, consistent with the theoretical literature on conformal methods under mild violations. revision: yes
-
Referee: [§4] §4 (conformalization strategies): The description of shift-aware extensions is too brief to allow readers to assess whether they preserve marginal validity or FDR control when exchangeability is mildly violated; explicit statements of the assumptions retained by each strategy and a small simulation under controlled shift would strengthen the exposition.
Authors: We accept this criticism. Section 4 has been expanded with explicit statements of the assumptions retained by each conformalization strategy (e.g., the shift-aware methods require an estimable shift model but preserve marginal validity for the calibration set under exchangeability). A small controlled-shift simulation has also been added to illustrate the empirical behavior of p-value calibration and FDR control under mild violations. revision: yes
Circularity Check
No circularity: package applies established conformal procedures without deriving new quantities from fits
full rationale
The paper presents an implementation of existing conformal anomaly detection methods (split-conformal calibration, p-value generation, FDR control) that integrate with scikit-learn and pyod. No equations derive new predictions from fitted parameters by construction, no uniqueness theorems are imported via self-citation, and no ansatz is smuggled in. The empirical demonstrations are presented as applications of the standard exchangeability assumption rather than forced outputs. The derivation chain is therefore self-contained against external benchmarks in the conformal prediction literature.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Data exchangeability is required for the conformal p-values to be valid
Reference graph
Works this paper leans on
-
[1]
Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing , author =. Journal of the Royal Statistical Society: Series B (Methodological) , volume = 57, number = 1, pages =. doi:https://doi.org/10.1111/j.2517-6161.1995.tb02031.x , url =
-
[2]
Simultaneous statistical inference , author =
-
[3]
Algorithmic learning in a random world , author =
-
[4]
2024 IEEE International Conference on Knowledge Graph (ICKG) , publisher =
Leave-One-Out-, Bootstrap- and Cross-Conformal Anomaly Detectors , author =. 2024 IEEE International Conference on Knowledge Graph (ICKG) , publisher =. doi:10.1109/ickg63256.2024.00022 , url =
-
[5]
Proceedings of the 34th International Conference on Neural Information Processing Systems , location =
Predictive inference is free with the jackknife+-after-bootstrap , author =. Proceedings of the 34th International Conference on Neural Information Processing Systems , location =
-
[6]
Cross-conformal predictors , author =. Ann. Math. Artif. Intell. , publisher =
-
[7]
Conformal Prediction: A Gentle Introduction , author =. Found. Trends Mach. Learn. , publisher =. doi:10.1561/2200000101 , issn =
-
[8]
Biometrika , volume = 113, number = 1, pages =
Model-free selective inference under covariate shift via weighted conformal p-values , author =. Biometrika , volume = 113, number = 1, pages =. doi:10.1093/biomet/asaf066 , issn =
-
[9]
2008 Eighth IEEE International Conference on Data Mining , volume =
Isolation Forest , author =. 2008 Eighth IEEE International Conference on Data Mining , volume =. doi:10.1109/ICDM.2008.17 , keywords =
-
[10]
Neural Computation , volume = 13, number = 7, pages =
Estimating the Support of a High-Dimensional Distribution , author =. Neural Computation , volume = 13, number = 7, pages =. doi:10.1162/089976601750264965 , keywords =
-
[11]
Testing for outliers with conformal p-values , author =. Ann. Stat. , publisher =
-
[12]
Annals of Mathematics and Artificial Intelligence , publisher =
Inductive conformal anomaly detection for sequential detection of anomalous sub-trajectories , author =. Annals of Mathematics and Artificial Intelligence , publisher =
-
[13]
Foster, Dean P and Stine, Robert A , year = 2008, month = apr, journal =
2008
-
[14]
Online rules for control of false discovery rate and false discovery exceedance , author =. Ann. Stat. , publisher =
-
[15]
Game-theoretic statistics and safe anytime-valid inference , author =. Stat. Sci. , publisher =
-
[16]
Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics , publisher =
The Power of Batching in Multiple Hypothesis Testing , author =. Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics , publisher =
-
[17]
E-values: Calibration, combination and applications , author =. Ann. Stat. , publisher =
-
[18]
Proceedings of the Twentieth International Conference on International Conference on Machine Learning , location =
Testing exchangeability on-line , author =. Proceedings of the Twentieth International Conference on International Conference on Machine Learning , location =
-
[19]
Journal of Statistical Planning and Inference , volume = 90, number = 2, pages =
Improving predictive inference under covariate shift by weighting the log-likelihood function , author =. Journal of Statistical Planning and Inference , volume = 90, number = 2, pages =. doi:https://doi.org/10.1016/S0378-3758(00)00115-4 , issn =
-
[20]
Direct importance estimation for covariate shift adaptation , author =. Ann. Inst. Stat. Math. , publisher =
-
[21]
Machine learning in non-stationary environments , author =
-
[22]
Multiple comparisons , author =
-
[23]
Multiple Comparison Procedures , author =
-
[24]
The problem of multiple comparisons , author =
-
[25]
Cordier, Thibault and Blot, Vincent and Lacombe, Louis and Morzadec, Thomas and Capitaine, Arnaud and Brunel, Nicolas , year = 2023, booktitle =
2023
-
[26]
MAPIE: an open-source library for distribution-free uncertainty quantification , author =
-
[27]
crepes: a Python Package for Generating Conformal Regressors and Predictive Systems , author =. Proc. of the 11th Symposium on Conformal and Probabilistic Prediction with Applications , pages =
-
[28]
Conformal Prediction in Python with crepes , author =. Proc. of the 13th Symposium on Conformal and Probabilistic Prediction with Applications , pages =
-
[29]
Conformal and Probabilistic Prediction with Applications , pages =
PUNCC: a Python Library for Predictive Uncertainty Calibration and Conformalization , author =. Conformal and Probabilistic Prediction with Applications , pages =
-
[30]
ECML PKDD Workshop: Languages for Data Mining and Machine Learning , pages =
Lars Buitinck and Gilles Louppe and Mathieu Blondel and Fabian Pedregosa and Andreas Mueller and Olivier Grisel and Vlad Niculae and Peter Prettenhofer and Alexandre Gramfort and Jaques Grobler and Robert Layton and Jake VanderPlas and Arnaud Joly and Brian Holt and Ga. ECML PKDD Workshop: Languages for Data Mining and Machine Learning , pages =
-
[31]
and Varoquaux, G
Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V. and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P. and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E. , year = 2011, journal =. Scikit-learn: Machine Learning in
2011
-
[32]
Journal of Machine Learning Research , volume = 20, number = 96, pages =
PyOD: A Python Toolbox for Scalable Outlier Detection , author =. Journal of Machine Learning Research , volume = 20, number = 96, pages =
-
[33]
Companion Proceedings of the ACM on Web Conference 2025 , pages =
Pyod 2: A python library for outlier detection with llm-powered model selection , author =. Companion Proceedings of the ACM on Web Conference 2025 , pages =
2025
-
[34]
Between resolution collapse and variance inflation: Weighted conformal anomaly detection in low-data regimes , author =
-
[35]
Shebuti Rayana , year = 2016, note =
2016
-
[36]
Multiple hypothesis testing , author =. Annu. Rev. Psychol. , publisher =
-
[37]
Proceedings of the 29th International Coference on International Conference on Machine Learning , location =
Plug-in martingales for testing exchangeability on-line , author =. Proceedings of the 29th International Coference on International Conference on Machine Learning , location =
-
[38]
Proceedings of the Tenth Symposium on Conformal and Probabilistic Prediction and Applications , publisher =
Retrain or not retrain: conformal test martingales for change-point detection , author =. Proceedings of the Tenth Symposium on Conformal and Probabilistic Prediction and Applications , publisher =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.