Recognition: unknown
Fine-tuning with Hierarchical Prompting for Robust Propaganda Classification Across Annotation Schemas
Pith reviewed 2026-05-14 19:38 UTC · model grok-4.3
The pith
Fine-tuning with hierarchical prompting turns weak zero-shot propaganda classifiers into competitive systems that handle ambiguous intent-based taxonomies better.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
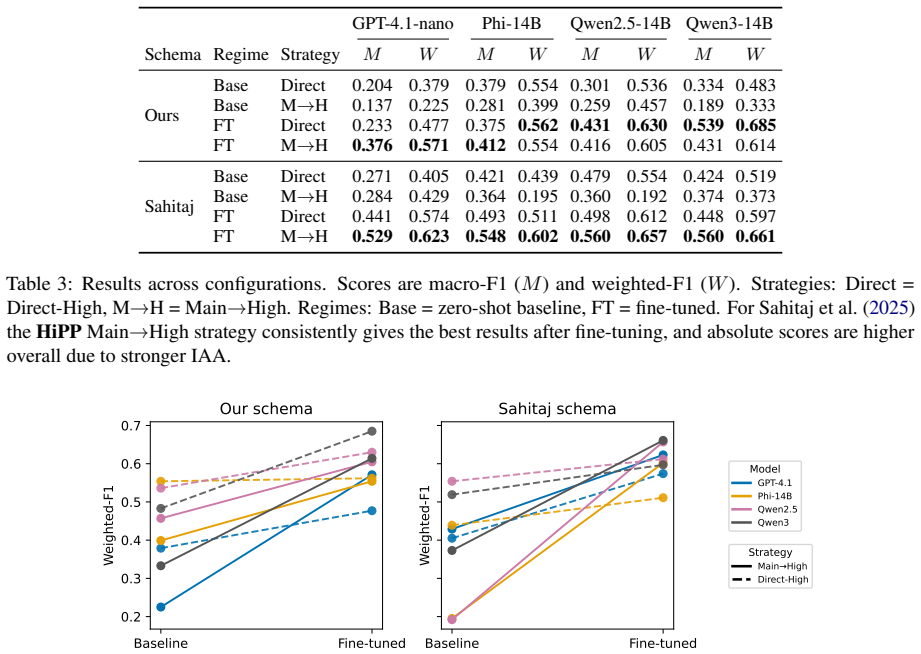
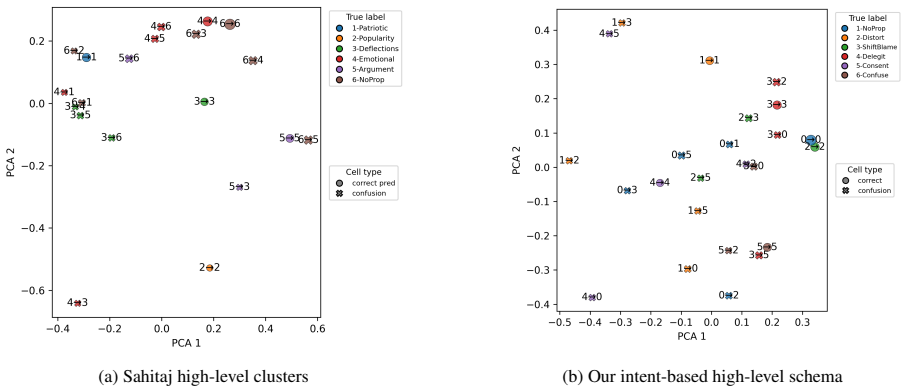
Fine-tuning transforms weak zero-shot baselines into competitive systems and reveals methodological differences hidden in base models. The hierarchical prompting method (HiPP) predicts fine-grained techniques before aggregating them and is especially beneficial after fine-tuning and on the more ambiguous, low-agreement taxonomy. Across schemas the Qwen models achieve the strongest performance while Phi-4 14B consistently outperforms GPT-4.1-nano, and the new intent-based labels in the HQP dataset offer a richer lens on propaganda's strategic goals.
What carries the argument
Hierarchical prompting (HiPP), which first predicts fine-grained propaganda techniques before aggregating them into higher-level labels.
If this is right
- Fine-tuning exposes model and method differences that zero-shot evaluations hide.
- HiPP improves results most on low-agreement, ambiguous taxonomies after fine-tuning.
- Qwen models deliver the strongest performance across both taxonomies.
- Phi-4 14B outperforms GPT-4.1-nano consistently in this setting.
- The HQP dataset serves as a harder benchmark for future robust detection work.
Where Pith is reading between the lines
- Similar hierarchical breakdown could help other noisy text classification tasks with low inter-annotator agreement.
- Intent-focused labels might support downstream applications such as targeted content moderation or campaign analysis.
- Testing the same fine-tuning plus HiPP pipeline on multilingual datasets would check if the gains hold beyond English.
- The performance gap between fine-tuned and base models suggests zero-shot evaluations may systematically underestimate practical utility.
Load-bearing premise
The new intent-focused taxonomy captures propaganda's strategic goals in a way that actually improves real-world robustness beyond the specific datasets tested.
What would settle it
An experiment showing that models trained on the new intent taxonomy perform worse than those using the established schema when evaluated on held-out real-world social media posts with human-verified ground truth.
Figures
read the original abstract
Propaganda detection in social media is challenging due to noisy, short texts and low annotation agreements. We introduce a new intent-focused taxonomy of propaganda techniques and compare it against an established, higher-agreement schema. Along three dimensions (model portfolio, schema effects, and prompting strategy) we evaluate the taxonomies as a classification task with the help of four language models (GPT-4.1-nano, Phi-4 14B, Qwen2.5-14B, Qwen3-14B). Our results show that fine-tuning is essential, since it transforms weak zero-shot baselines into competitive systems and reveals methodological differences that are hidden using base models. Across schemas, the Qwen models achieve the strongest overall performance, and Phi-4 14B consistently outperforms GPT-4.1-nano. Our hierarchical prompting method (HiPP), which predicts fine-grained techniques before aggregating them, is especially beneficial after fine-tuning and on the more ambiguous, low-agreement taxonomy, while remaining competitive on the simpler schema. The HQP dataset, annotated with the new intent-based labels, provides a richer lens on propaganda's strategic goals and a challenging benchmark for future work on robust, real-world detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a new intent-focused taxonomy for propaganda techniques in social media and compares it to an established higher-agreement schema. Using four LLMs (GPT-4.1-nano, Phi-4 14B, Qwen2.5-14B, Qwen3-14B), it evaluates performance across zero-shot and fine-tuned regimes with standard prompting versus the proposed hierarchical prompting method (HiPP), which first predicts fine-grained techniques before aggregation. The central claims are that fine-tuning is essential to convert weak zero-shot baselines into competitive systems and to surface model and schema differences, that HiPP is especially beneficial after fine-tuning on the low-agreement taxonomy, that Qwen models perform strongest overall, and that the released HQP dataset offers a richer benchmark for real-world robustness.
Significance. If the empirical comparisons hold, the work provides concrete evidence that fine-tuning combined with hierarchical prompting improves robustness in propaganda classification across annotation schemas with differing agreement levels. The new intent-focused taxonomy and the HQP dataset constitute a useful contribution for future benchmarking, while the finding that base-model differences are masked until fine-tuning occurs has practical implications for model selection in noisy social-media settings.
Simulated Author's Rebuttal
We thank the referee for their careful summary of the manuscript and for recommending minor revision. We are pleased that the empirical findings on fine-tuning, hierarchical prompting, and the new HQP dataset are viewed as providing concrete evidence for improved robustness across schemas.
Circularity Check
No significant circularity in empirical evaluation
full rationale
The paper is an empirical study comparing four language models, two annotation schemas, and prompting strategies (including the introduced HiPP method) on propaganda detection tasks. All central claims—such as the necessity of fine-tuning to reveal differences and the benefits of hierarchical prompting on low-agreement taxonomies—are presented as direct outcomes of experimental results across datasets. There are no equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations that reduce any result to its inputs by construction. The work remains self-contained as a benchmark comparison without circular reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard i.i.d. assumptions for train/test splits in supervised classification
Reference graph
Works this paper leans on
-
[1]
Fine-grained analysis of propaganda in news articles. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natu- ral Language Processing (EMNLP-IJCNLP), pages 5636–5646, Hong Kong, China. Association for Com- putational Linguistics. A. P. Dawid and A. M. Skene. 1979. Maximum...
-
[2]
Semeval-2020 task 11: Detection of propa- ganda techniques in news articles.arXiv preprint arXiv:2009.02696. OpenAI. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774. E Perez. 2022. Strategic disinformation: Russia, ukraine and crisis communication in digital era. Jakub Piskorski, Nicolas Stefanovitch, Giovanni Da San Martino, and Preslav Nako...
-
[3]
Subtypes: 2, 11, 15, 17 (False Origin Attribution, Circular Reasoning, Appeal to Ignorance)
Distort Reality and Rewrite the Past Goal: Undermine truth and legitimize the present through distortion. Subtypes: 2, 11, 15, 17 (False Origin Attribution, Circular Reasoning, Appeal to Ignorance). Rationale: Denial, fabrication, and invented evidence challenge fact-based narratives
-
[4]
Subtypes: 4, 5, 13, 17 (False Causality, False Balance)
Shift Blame and Justify Aggression Goal: Reframe aggressor as victim or rational actor. Subtypes: 4, 5, 13, 17 (False Causality, False Balance). Rationale: Inverts moral frameworks to rationalize wrongdoing or redirect guilt
-
[5]
Subtypes: 1, 3, 8, 9, 12, 6
Delegitimize the Opponent Goal: Undermine credibility and morality of adversaries. Subtypes: 1, 3, 8, 9, 12, 6. Rationale: Frames enemies as liars, extremists, or inhuman entities
-
[6]
Subtypes: 12, 14, 16, 10, 7
Manufacture Consent and Identity Goal: Rally support and polarize identities. Subtypes: 12, 14, 16, 10, 7. Rationale: Builds loyalty through fear, pride, and tribal solidarity
-
[7]
Subtypes: 7, 15, 6, 17 (Red Herrings, Appeal to Probability, False Di- chotomy)
Confuse and Distract Goal: Overwhelm critical thinking through noise and uncertainty. Subtypes: 7, 15, 6, 17 (Red Herrings, Appeal to Probability, False Di- chotomy). Rationale: Undermines clarity, trust, and consensus. Table 8: Overview of the five high-level propaganda categories and their purposes. Low-Level Fine-Grained Labels
-
[8]
Includes WWII analogies, Hitler/SS references, burning people like Nazis
Guilt-by-association fallacy Most frequently as nazi analogies. Includes WWII analogies, Hitler/SS references, burning people like Nazis. Could also include other reductio ad Hitlerum instances
-
[9]
Historical Distortion / Revisionism Cherry-picking historical events, WWII nostalgia, Soviet glorification, fake quotes
-
[10]
Dehumanization / Demonization Calling opponents subhuman, monsters, or animals; atrocity narratives
-
[11]
Deflect and Justify I: Victimhood / Gaslighting Aggressor framed as victim, blame-shifting, moral inversion, denial of wrongdoing
-
[12]
but the West invaded Iraq
Deflect and Justify II: Whataboutism False moral equivalence, hypocrisy framing (“but the West invaded Iraq”)
-
[13]
the other side lies,
Accusation of Propaganda / Media Distrust Asserting “the other side lies,” mocking mainstream narratives, distrust in institutions
-
[14]
Conspiracy Narratives CIA/Nuland plots, puppet governments, Western coups, assertion-as-proof
-
[15]
Guilt by Association Azov = entire military is Nazi; guilt through affiliation or past ties
-
[16]
Sarcasm / Ridicule / Strawman Mocking tone, exaggeration, caricatures, eye-roll emojis
-
[17]
Emotional Manipulation / Shock Appeal Rape/torture narratives, fearmongering, nuclear threats, mass graves
-
[18]
False Authority / Fabrication Fake quotes, fabricated stats, unverified claims framed as facts
-
[19]
with us or against us
Us vs. Them Framing / Identity Dichotomy Nationalist binaries, tribal solidarity, “with us or against us” rhetoric
-
[20]
Realpolitik Framing / Moral Detachment Cool, analytical justification of aggression; geopolitical realism
-
[21]
Russia is winning,
Triumphalism / Victory Framing “Russia is winning,” inevitability rhetoric, “truth will prevail.”
-
[22]
Unconfirmed reports,
Information Laundering / Rumor Seeding “Unconfirmed reports,” plausible deniability, sowing doubt
-
[23]
Anti-Establishment / Anti-Globalist Framing Criticism of NATO, EU, UN, WEF; anti-West framing
-
[24]
Table 9: Overview of the 17 fine-grained propaganda techniques
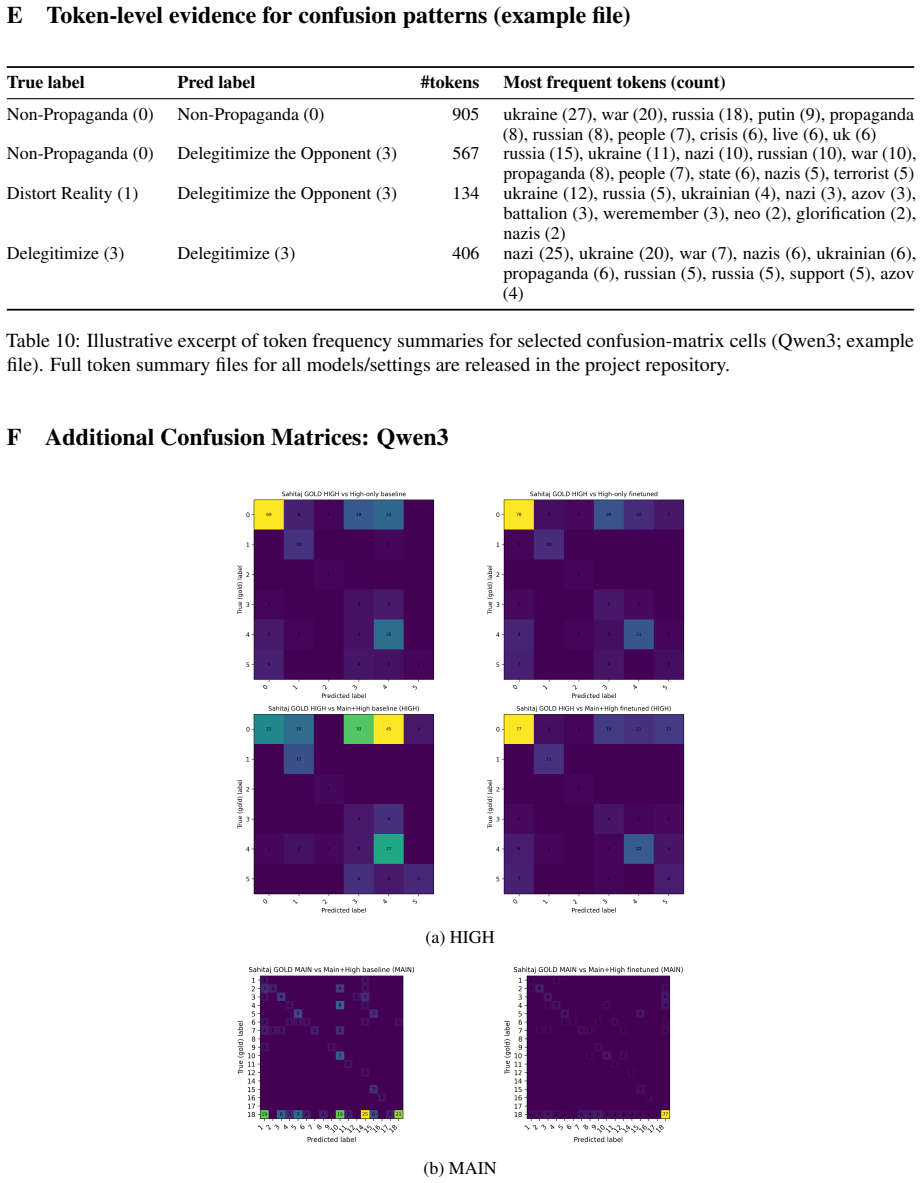
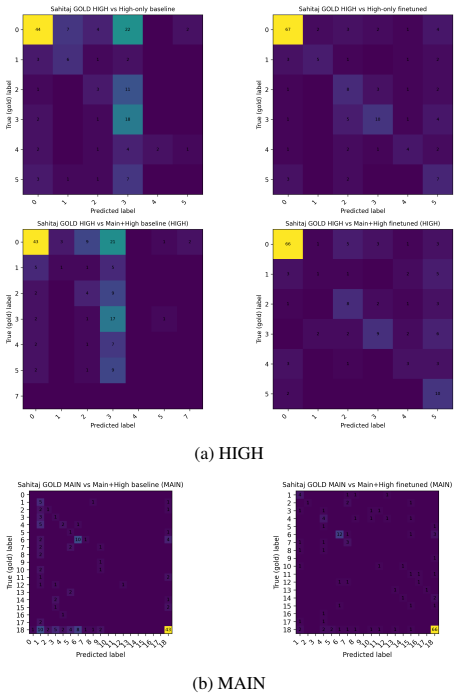
Logical Fallacies False dichotomy, causal oversimplification, circular reasoning, false balance, appeal to ignorance. Table 9: Overview of the 17 fine-grained propaganda techniques. E Token-level evidence for confusion patterns (example file) True label Pred label #tokens Most frequent tokens (count) Non-Propaganda (0) Non-Propaganda (0) 905 ukraine (27),...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.