Robust and Explainable Bicuspid Aortic Valve Diagnosis Using Stacked Ensembles on Echocardiography
Pith reviewed 2026-05-14 20:04 UTC · model grok-4.3
Add this Pith Number to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{KUVCXGSQ}
Prints a linked pith:KUVCXGSQ badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
A stacked ensemble of video models distinguishes bicuspid from tricuspid aortic valves on routine echocardiography cine loops with an F1-score of 0.907.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
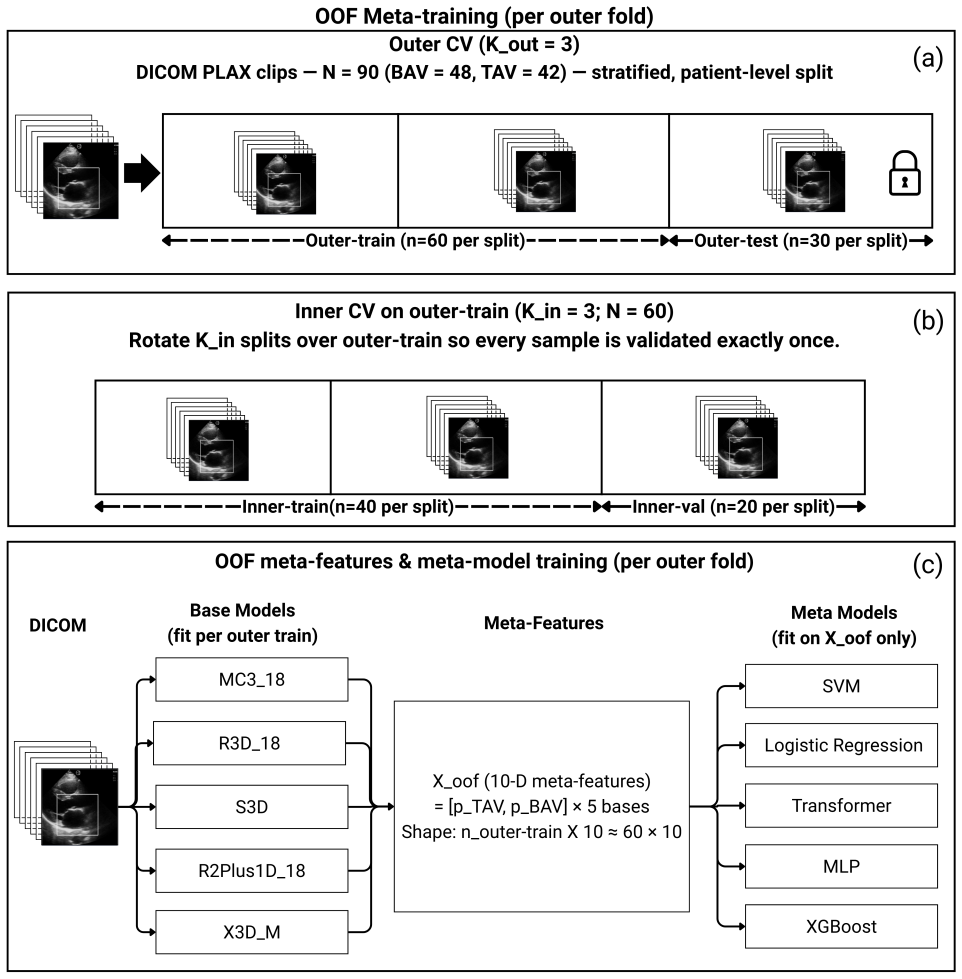
A multi-backbone video ensemble trained and evaluated with leakage-aware stratified outer cross-validation on 90 patient studies (48 BAV, 42 TAV) distinguishes bicuspid from tricuspid aortic valves on parasternal long-axis cine loops, reaching an outer-CV F1-score of 0.907 and recall of 0.877 while supplying case-level auditability via frame-wise Grad-CAM localization to the aortic root and leaflet plane plus aggregated SHAP values that quantify each backbone's contribution to the stacked output.
What carries the argument
A calibrated stacked ensemble of multi-backbone video classifiers evaluated under leakage-aware stratified outer cross-validation.
Load-bearing premise
The leakage-aware stratified outer cross-validation performed on this single internal cohort of 90 patients is sufficient to guarantee robustness and generalizability to new patients and different imaging conditions.
What would settle it
Running the trained model on an independent external set of echocardiography videos from a different center or scanner and observing whether the F1-score remains near 0.907 or drops substantially.
Figures







read the original abstract
Transthoracic echocardiography (TTE) is the first-line imaging modality for diagnosing bicuspid aortic valve (BAV), yet diagnostic performance varies with operator expertise and image quality. We developed an explainable AI model that distinguishes BAV from tricuspid aortic valves (TAV) using routinely acquired parasternal long-axis (PLAX) cine loops. A multi-backbone video ensemble was trained and evaluated using a leakage-aware, stratified outer cross-validation protocol on $N{=}90$ patient studies (48 BAV, 42 TAV). Across fixed outer splits and 10 random seeds, the calibrated stacked ensemble achieved an outer-CV F1-score of $0.907$ and recall of $0.877$. Frame-level Grad-CAM localized salient evidence to the aortic root and leaflet plane, while globally aggregated SHAP values quantified each video backbone's contribution to the stacked prediction, enabling transparent, case-level auditability. These findings indicate that PLAX-based video ensembles can support reliable BAV/TAV classification from routine echocardiographic cine loops and may facilitate earlier detection in non-specialist or resource-limited clinical settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a multi-backbone video ensemble with stacking and calibration for binary classification of bicuspid aortic valve (BAV) versus tricuspid aortic valve (TAV) from routine parasternal long-axis (PLAX) echocardiography cine loops. On a single-center cohort of N=90 studies (48 BAV, 42 TAV), a leakage-aware stratified outer cross-validation protocol yields an outer-CV F1-score of 0.907 and recall of 0.877 for the calibrated stacked ensemble across fixed splits and 10 random seeds. Frame-level Grad-CAM and globally aggregated SHAP values are used to provide case-level explainability.
Significance. If the reported performance holds under broader conditions, the work offers a technically sound approach to assisting BAV/TAV differentiation on standard PLAX views, with built-in interpretability that could aid auditability in clinical workflows. The leakage-aware outer CV and dual explainability methods (Grad-CAM + SHAP) are positive technical features.
major comments (2)
- [Methods / Results] Methods and Results sections: The headline performance (outer-CV F1 0.907, recall 0.877) is obtained solely from internal stratified outer CV on a single-center N=90 cohort. No independent external test set (multi-center or multi-vendor) is described, so the claim that the ensemble 'can support reliable BAV/TAV classification' and 'may facilitate earlier detection in non-specialist settings' rests on the untested assumption that site-specific imaging characteristics do not dominate the learned features.
- [Discussion] Discussion: With only 48 positive cases and no power analysis or confidence intervals on the outer-CV metrics, the statistical support for the robustness claim is limited; the reported point estimates alone do not yet substantiate generalizability beyond the training distribution.
minor comments (2)
- [Methods] The manuscript should explicitly state the video backbones used in the ensemble and the exact stacking architecture (e.g., meta-learner type and input features) to allow reproducibility.
- [Figures] Figure captions for Grad-CAM visualizations should include the number of cases shown and whether they are representative or cherry-picked.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on generalizability and statistical robustness. We address each major comment below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Methods / Results] Methods and Results sections: The headline performance (outer-CV F1 0.907, recall 0.877) is obtained solely from internal stratified outer CV on a single-center N=90 cohort. No independent external test set (multi-center or multi-vendor) is described, so the claim that the ensemble 'can support reliable BAV/TAV classification' and 'may facilitate earlier detection in non-specialist settings' rests on the untested assumption that site-specific imaging characteristics do not dominate the learned features.
Authors: We agree that the reported metrics come from internal cross-validation on a single-center cohort and that external validation is required to support broader claims of reliability. In the revised manuscript we have removed or qualified the phrases suggesting immediate clinical support for non-specialist settings, added explicit language that performance must be confirmed on multi-center data, and inserted a new limitations subsection discussing potential site- and vendor-specific biases in the learned features. revision: yes
-
Referee: [Discussion] Discussion: With only 48 positive cases and no power analysis or confidence intervals on the outer-CV metrics, the statistical support for the robustness claim is limited; the reported point estimates alone do not yet substantiate generalizability beyond the training distribution.
Authors: We acknowledge the modest sample size (48 BAV cases) constrains statistical power. We have added 95 % bootstrap confidence intervals for the outer-CV F1 and recall (computed across the 10 random seeds) to the Results and Discussion sections. A prospective power analysis was not performed because the study is retrospective; we have therefore tempered the robustness language and explicitly stated that larger multi-center cohorts are needed to substantiate generalizability. revision: partial
- We do not have access to an independent multi-center or multi-vendor external test set at this time.
Circularity Check
No circularity: outer-CV metrics computed on independent held-out splits
full rationale
The paper's central performance claims (outer-CV F1 0.907, recall 0.877) are obtained via leakage-aware stratified outer cross-validation on N=90 studies, with metrics evaluated exclusively on held-out test folds independent of training. No equations, parameters, or self-citations reduce these results to fitted inputs by construction. The evaluation protocol follows standard ML practice without self-definitional loops, fitted-input renaming, or load-bearing self-citations. The derivation chain for the stacked ensemble and explainability components remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- stacking ensemble weights
- calibration parameters
axioms (2)
- domain assumption The 90 patient studies represent the distribution of BAV and TAV cases in clinical practice
- domain assumption No data leakage occurs despite the video nature and patient-level splitting
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A multi-backbone video ensemble was trained and evaluated using a leakage-aware, stratified outer cross-validation protocol on N=90 patient studies... calibrated stacked ensemble achieved an outer-CV F1-score of 0.907
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Frame-level Grad-CAM localized salient evidence to the aortic root and leaflet plane, while globally aggregated SHAP values quantified each video backbone's contribution
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alan C. Braverman and Andrew Cheng. The bicuspid aortic valve and associated aortic disease. In Cather- ine M. Otto and Robert O. Bonow, editors,Valvular Heart Disease: A Companion to Braunwald’s Heart Disease, chapter 11, pages 197–223. Saunders/Elsevier, 5 edition, 2021. ISBN 9780323546331
work page 2021
-
[2]
M. Hillebrand, W. Li, S. Gross, et al. Accuracy of transthoracic echocardiography to diagnose bicuspid aortic valve: comparison with surgical findings and cardiac magnetic resonance imaging.International Journal of Cardiology, 243:260–265, 2017
work page 2017
- [3]
-
[4]
J. Chen, S. Li, and Y . Xiao. Automatic classification of BA V using CNNs on echocardiography.IEEE Journal of Biomedical and Health Informatics, 24(11):3120– 3130, 2020
work page 2020
- [5]
-
[6]
Y . Hong, X. Li, and Y . Tang. Transformer-based deep learning for hypertrophic cardiomyopathy diagnosis from echocardiographic videos.Computer Methods and Programs in Biomedicine, 221:106895, 2022
work page 2022
-
[7]
James P. Howard, Jeremy Tan, Matthew J. Shun-Shin, Dina Mahdi, Alexandra N. Nowbar, Ahran D. Arnold, Yousif Ahmad, Peter McCartney, Massoud Zolgharni, Nick W. F. Linton, Nilesh Sutaria, Bushra Rana, Jamil Mayet, Daniel Rueckert, Graham D. Cole, and Darrel P. Francis. Improving ultrasound video classification: an evaluation of novel CNN architectures.Journ...
-
[8]
Ramprasaath R. Selvaraju, Michael Cogswell, Ab- hishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-CAM: Visual explanations from deep networks via gradient-based localization. InPro- ceedings of the IEEE International Conference on Computer Vision (ICCV), pages 618–626, 2017. doi: 10.1109/ICCV .2017.74
-
[9]
Scott M. Lundberg and Su-In Lee. A unified approach to interpreting model predictions.Advances in Neural Information Processing Systems (NeurIPS), 30, 2017
work page 2017
-
[10]
B.H.M. van der Velden, S.C. van de Leemput, W.B. Veldhuis, and K.G.A. Gilhuijs. Explainable artificial intelligence in medical imaging: A systematic review. Medical Image Analysis, 79:102470, 2022. doi: 10. 1016/j.media.2022.102470
-
[11]
Gregory Holste, Evangelos K. Oikonomou, Bobak J. Mortazavi, Andreas Coppi, Kamil F. Faridi, Edward J. Miller, John K. Forrest, Robert L. McNamara, Lu- cila Ohno-Machado, Neal Yuan, Aakriti Gupta, David Ouyang, Harlan M. Krumholz, Zhangyang Wang, and Rohan Khera. Severe aortic stenosis detection by deep learning applied to echocardiography.Euro- pean Heart...
-
[12]
Dominik M¨uller, I˜naki Soto-Rey, and Frank Kramer. An analysis on ensemble learning optimized medical image classification with deep convolutional neural networks.IEEE Access, 10:66467–66480, 2022. doi: 10.1109/ACCESS.2022.3182399
-
[13]
M. A. Ganaie, Minghui Hu, A. K. Malik, M. Tan- veer, and P. N. Suganthan. Ensemble deep learning: A review.Engineering Applications of Artificial Intel- ligence, 115:105151, 2022. doi: 10.1016/j.engappai. 2022.105151. 14
-
[14]
Shahid Mohammad Ganie, Pijush Kanti Dutta Pra- manik, and Zhongming Zhao. Ensemble learning with explainable AI for improved heart disease pre- diction.Scientific Reports, 15:13912, 2025. doi: 10.1038/s41598-025-97547-6
-
[15]
J. Zhou, T. Liang, and C. Wang. Self-supervised echocardiographic representation learning for small datasets.IEEE Transactions on Medical Imaging, 43 (5):1223–1235, 2024
work page 2024
-
[16]
S. Lee, D. Park, and H. Kim. Hybrid CNN-transformer ensembles for medical video classification.Medical Image Analysis, 88:102819, 2023
work page 2023
-
[17]
Michelena, Alessandro Della Corte, Arturo Evangelista, et al
Hector I. Michelena, Alessandro Della Corte, Arturo Evangelista, et al. International consensus statement on nomenclature and classification of the congenital bicus- pid aortic valve and its aortopathy, for clinical, surgical, interventional and research purposes.European Jour- nal of Cardio-Thoracic Surgery, 60(3):448–476, 2021. doi: 10.1093/ejcts/ezab038
-
[18]
Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods
John Platt. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. InAdvances in Large Margin Classifiers. MIT Press, 1999
work page 1999
-
[19]
Glenn W. Brier. Verification of forecasts expressed in terms of probability.Monthly Weather Review, 78(1): 1–3, 1950. doi: 10.1175/1520-0493(1950)078 ⟨0001: VOFEIT⟩2.0.CO;2
-
[20]
Andrew J. Vickers and Elena B. Elkin. Decision curve analysis: a novel method for evaluating prediction mod- els.Medical Decision Making, 26(6):565–574, 2006. doi: 10.1177/0272989X06295361
-
[21]
Christos Chrysanthos Nikolaidis, Vasileios Perifanis, Nikolaos Pavlidis, and Pavlos S. Efraimidis. Federated learning for early dropout prediction on healthy ageing applications. In2023 8th International Conference on Fog and Mobile Edge Computing (FMEC). IEEE,
-
[22]
doi: 10.1109/FMEC59214.2023.10306129
-
[23]
Christos Chrysanthos Nikolaidis and Pavlos S. Efraimidis. Advancing elderly social care dropout prediction with federated learning: Client selection and imbalanced data management.Cluster Computing, 28(2):114, 2025. doi: 10.1007/s10586-024-04850-4
-
[24]
Eleni Briola, Christos Chrysanthos Nikolaidis, Vasileios Perifanis, Nikolaos Pavlidis, and Pavlos S. Efraimidis. A federated explainable AI model for breast cancer classification. InProceedings of the 2024 European Interdisciplinary Cybersecurity Confer- ence (EICC ’24). ACM, 2024. doi: 10.1145/3655693. 3660255
-
[25]
Christos Chrysanthos Nikolaidis and Pavlos S. Efraimidis. A study of membership inference attacks on a federated health care application.Computing, 107: 149, 2025. doi: 10.1007/s00607-025-01507-x
-
[26]
Efraimidis, and Despina Elisabeth Filippidou
Nikolaos Pavlidis, Vasileios Perifanis, Eleni Briola, Christos-Chrysanthos Nikolaidis, Eleftheria Katsiri, Pavlos S. Efraimidis, and Despina Elisabeth Filippidou. Federated anomaly detection for early-stage diagnosis of autism spectrum disorders using serious game data. arXiv preprint arXiv:2410.20003, 2024. URL https: //arxiv.org/abs/2410.20003. 15
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.