Recognition: no theorem link
(How) Do Large Language Models Understand High-Level Message Sequence Charts?
Pith reviewed 2026-05-15 05:45 UTC · model grok-4.3
The pith
Large language models achieve only about 52 percent accuracy when tested on the formal semantics of High-Level Message Sequence Charts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
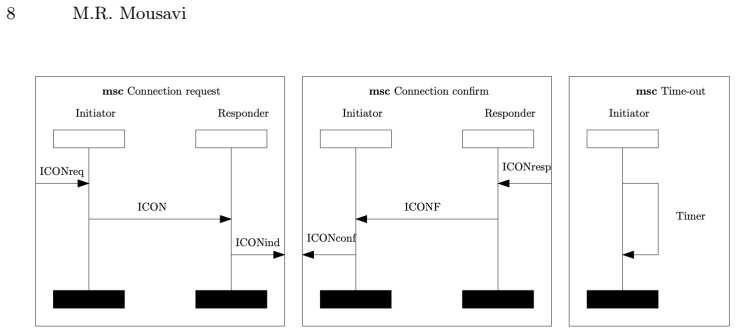
The authors demonstrate through systematic testing that LLMs possess only a modest understanding of the formal semantics of High-Level Message Sequence Charts, attaining approximately 52% accuracy across the 129 tasks. They perform well on basic constructs such as events and their ordering, reaching about 88% accuracy, but falter on semantic-preserving abstractions and compositions at 36% and on traces and equivalent labelled transition systems at 42%. In particular, none of the models made use of co-regions or explicit causal dependencies during transformations.
What carries the argument
A benchmark of 129 semantic tasks applied to three LLMs to measure accuracy on HMSC concepts from basic ordering to abstraction, composition, traces, and LTS equivalence.
If this is right
- LLMs can handle basic event and ordering queries in HMSCs with reasonable reliability but cannot be trusted alone for abstraction, composition, or trace calculations.
- Tools that embed LLMs in architectural design with HMSCs or UML diagrams require separate verification steps for any semantic manipulation.
- The complete absence of co-region and causal-dependency usage points to a specific gap that training data or prompting must address.
- Selective deployment of LLMs is warranted: they suit simple queries yet need safeguards on tasks where accuracy falls below 40 percent.
- Widespread use of LLMs for HMSC-based specifications risks producing designs that deviate from formal semantics unless checked by dedicated verifiers.
Where Pith is reading between the lines
- Applying the same task battery to other formalisms such as state machines could show whether modest semantic understanding is common across visual modeling languages.
- Explicit prompting that forces consideration of co-regions and causal links might narrow the performance gap on abstraction and trace tasks.
- Hybrid pipelines that pair LLM output with automated semantic checkers for HMSCs would mitigate the observed weaknesses in practice.
- Scaling the task set to larger HMSCs would test whether accuracy declines further as diagram complexity increases.
Load-bearing premise
The 129 tasks chosen represent a representative sample of HMSC formal semantics and LLM answers reflect genuine understanding rather than surface pattern matching.
What would settle it
A new or expanded collection of HMSC tasks, balanced across all semantic categories, that produces accuracy markedly higher or lower than 52 percent overall or changes the observed gaps between basic and advanced tasks.
Figures


read the original abstract
Large Language Models (LLMs) are being employed widely to automate tasks across the software development life-cycle. It is, however, unclear whether these tasks are performed consistently with respect to the semantics of the artefacts being handled. This question is particularly under-researched concerning architectural design specification. In this paper, we address this question for High-Level Message Sequence Charts (HMSCs). These are visual models with a rigorous formal semantics that have been used for various purposes, including as a foundation for Sequence Diagrams in the Unified Modelling Language (UML). We examine whether LLMs "understand" the semantics of HMSCs by examining three LLMs (Gemini-3, GPT-5.4, and Qwen-3.6) on how they perform 129 semantic tasks ranging from querying basic semantic constructs in HMSCs (i.e., events and their ordering) to semantic-preserving abstractions and compositions, and calculating the set of traces and trace-equivalent labelled transition systems. The results show that LLMs only have a modest understanding of the formal semantics of HMSCs (ca. 52% overall accuracy), with great variability across different semantic concepts: while LLMs seem to understand the basic semantic concepts of MSCs (ca. 88% accuracy), they struggle with semantic reasoning in tasks involving abstraction and composition (ca. 36% accuracy) and traces and LTSs (ca. 42% accuracy). In particular, all three LLMs struggle with the notions of co-region and explicit causal dependencies and never employed them in semantic-preserving transformations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates whether LLMs understand the formal semantics of High-Level Message Sequence Charts (HMSCs) by evaluating three models (Gemini-3, GPT-5.4, Qwen-3.6) on 129 tasks spanning basic semantic constructs (events, ordering), semantic-preserving abstractions/compositions, and computation of traces and trace-equivalent labelled transition systems. It reports ~52% overall accuracy, with 88% on basics but only 36% on abstraction/composition and 42% on traces/LTS, and notes particular failures on co-regions and explicit causal dependencies.
Significance. If substantiated, the concrete accuracy figures across task categories would provide useful empirical data on LLM limitations for formal semantic reasoning in architectural models, with direct relevance to UML Sequence Diagrams and automated software design tasks. The work is a straightforward benchmarking study with no fitted parameters or derivations, and its value lies in the reported performance gaps rather than any theoretical advance.
major comments (3)
- [Experimental design / task definition] The selection and coverage of the 129 tasks is not justified by any mapping to the formal semantics of HMSCs or by a documented generation protocol. Without this, the central claim that LLMs exhibit only 'modest understanding' (abstract) cannot be evaluated, as the accuracy numbers may reflect sampling bias rather than representative coverage of constructs such as co-regions and causal dependencies.
- [Methodology and results analysis] No controls are described to distinguish semantic understanding from surface-level pattern matching or training-data recall (e.g., adversarial rephrasings, non-semantic baselines, or variants that preserve syntax but alter semantics). This directly undermines the interpretation of the 36% abstraction/composition and 42% traces/LTS accuracies as evidence of limited semantic reasoning.
- [Results section] Accuracy is reported as aggregate percentages per category without per-task error analysis, statistical tests for differences between categories, or details on scoring criteria and inter-rater reliability for LLM outputs. This makes the reported variability (88% vs. 36%) difficult to interpret as a robust finding.
minor comments (2)
- [Experimental setup] Clarify the exact model versions and access dates (Gemini-3, GPT-5.4, Qwen-3.6 appear non-standard) and whether temperature or other generation parameters were fixed across runs.
- [Appendix or supplementary material] Add a table or appendix listing representative task examples from each category to allow readers to assess difficulty and coverage.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and describe the revisions we will make to improve the manuscript's rigor and clarity.
read point-by-point responses
-
Referee: [Experimental design / task definition] The selection and coverage of the 129 tasks is not justified by any mapping to the formal semantics of HMSCs or by a documented generation protocol. Without this, the central claim that LLMs exhibit only 'modest understanding' (abstract) cannot be evaluated, as the accuracy numbers may reflect sampling bias rather than representative coverage of constructs such as co-regions and causal dependencies.
Authors: We appreciate the referee's point on experimental design. The 129 tasks were systematically derived from the standard formal semantics of HMSCs (covering events, ordering, co-regions, causal dependencies, abstractions, compositions, traces, and LTS equivalences), but we acknowledge that the manuscript lacks an explicit mapping table or generation protocol. In the revised version, we will add a new subsection (Section 3.2) with a detailed breakdown mapping each task category to specific semantic constructs, along with the generation protocol and rationale for task distribution to demonstrate representative coverage and mitigate sampling bias concerns. revision: yes
-
Referee: [Methodology and results analysis] No controls are described to distinguish semantic understanding from surface-level pattern matching or training-data recall (e.g., adversarial rephrasings, non-semantic baselines, or variants that preserve syntax but alter semantics). This directly undermines the interpretation of the 36% abstraction/composition and 42% traces/LTS accuracies as evidence of limited semantic reasoning.
Authors: This is a valid methodological concern. While tasks such as full trace enumeration and LTS computation inherently require systematic semantic application unlikely to succeed via surface pattern matching alone, we agree that explicit controls are needed for stronger claims. In revision, we will add a dedicated discussion of potential confounds and include baseline results (e.g., on syntax-preserving but semantically altered variants) in an appendix to show performance drops, thereby supporting the interpretation of the reported accuracies as evidence of limited semantic reasoning. revision: partial
-
Referee: [Results section] Accuracy is reported as aggregate percentages per category without per-task error analysis, statistical tests for differences between categories, or details on scoring criteria and inter-rater reliability for LLM outputs. This makes the reported variability (88% vs. 36%) difficult to interpret as a robust finding.
Authors: We agree that aggregate reporting limits robustness. In the revised Results section, we will include per-task accuracy breakdowns (in an appendix table), statistical tests (e.g., chi-squared) confirming significant differences across categories, and expanded details on scoring criteria (manual verification against formal semantics, with a sample double-checked by a second author and inter-rater agreement reported). These changes will make the observed variability (e.g., 88% vs. 36%) more interpretable as a reliable finding. revision: yes
Circularity Check
No circularity: purely empirical benchmarking with direct result reporting
full rationale
The paper performs an empirical evaluation by running three LLMs on a fixed set of 129 semantic tasks for HMSCs and reports accuracy figures (overall ~52%, with breakdowns by category) directly from model outputs against ground-truth semantics. No derivations, equations, fitted parameters, or predictions are present that could reduce to inputs by construction. No self-citation chains are invoked to justify uniqueness or force results. The study is self-contained against external benchmarks (model responses vs. formal semantics), satisfying the criteria for a non-circular empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Addison Wesley Longman Publishing Co., Inc., USA (1999)
Booch,G.,Rumbaugh,J.,Jacobson,I.:TheUnifiedModelingLanguageuserguide. Addison Wesley Longman Publishing Co., Inc., USA (1999)
work page 1999
-
[2]
llm-assisted code de- velopment
Cheung, K.S., Kaul, M., Jahangirova, G., Mousavi, M.R., Zie, E.: Com- parative analysis of carbon footprint in manual vs. llm-assisted code de- velopment. In: Proceedings of the 1st International Workshop on Responsi- ble Software Engineering, ResponsibleSE 2025, Trondheim, Norway, June 23- 28, 2025. pp. 13–20. ACM (2025). https://doi.org/10.1145/3711919....
-
[3]
In: Dorner, M., Ram- ler, R., Winkler, D., Bergsmann, J
Elberzhager, F., Gerbershagen, M., Ginkel, J.: Using llms to evaluate architecture documents – results from a digital marketplace environment. In: Dorner, M., Ram- ler, R., Winkler, D., Bergsmann, J. (eds.) Software Architecture as the Backbone of Software Quality. pp. 65–81. Springer Nature Switzerland, Cham (2026)
work page 2026
-
[4]
Gröpler, R., Klepke, S., Johns, J., Dreschinski, A., Schmid, K., Dornauer, B., Tüzün, E., Noppen, J., Mousavi, M.R., Tang, Y., Viehmann, J., Aslangül, S.S., Lee, B.S., Ziolkowski, A., Zie, E.: The future of generative AI in soft- ware engineering: A vision from industry and academia in the european ge- nius project. In: 2nd IEEE/ACM International Conferen...
-
[5]
In: 2025 IEEE/ACM International Workshop on Designing Software (Designing)
Guerra, L.P.F., Ernst, N.: Assessing llms for front-end soft- ware architecture knowledge. In: 2025 IEEE/ACM International Workshop on Designing Software (Designing). p. 6–10. IEEE Press (2025). https://doi.org/10.1109/Designing66910.2025.00007, https://doi.org/10.1109/Designing66910.2025.00007
-
[6]
In: Proceedings of the 41st International Conference on Machine Learning
Hooda, A., Christodorescu, M., Allamanis, M., Wilson, A., Fawaz, K., Jha, S.: Do large code models understand programming concepts? counterfactual analysis for code predicates. In: Proceedings of the 41st International Conference on Machine Learning. ICML’24, JMLR.org (2024)
work page 2024
-
[7]
(ITU-T), I.T.S.S.: Recommendation Z.120: Message sequence chart (MSC) (September 1993)
work page 1993
-
[8]
International Journal on Software Tools for Technology Transfer (2026)
Laneve, C., Spanò, A., Ressi, D., Rossi, S., Bugliesi, M.: Understanding code semantics: a benchmark study of llms. International Journal on Software Tools for Technology Transfer (2026). https://doi.org/10.1007/s10009-026-00842- 4, https://doi.org/10.1007/s10009-026-00842-4
- [9]
- [10]
-
[11]
Mousavi Engineering: New Ideas and Emerging Results (ICSE-NIER)
North, M., Atapour-Abarghouei, A., Bencomo, N.: Beyond syntax: How do llms understand code? In: 2025 IEEE/ACM 47th International Conference on Software 20 M.R. Mousavi Engineering: New Ideas and Emerging Results (ICSE-NIER). pp. 86–90 (2025). https://doi.org/10.1109/ICSE-NIER66352.2025.00023
-
[12]
Ouyang, S., Zhang, J.M., Gong, J., Jahangirova, G., Mousavi, M.R., Johns, J., Lee, B.S., Ziolkowski, A., Virginas, B., Noppen, J.: Benchmarking and evaluating vlms for software architecture diagram understanding (2026), https://arxiv.org/abs/2604.04009
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
AJOB Neu- roscience11(2), 88–95 (2020)
Salles, A., Evers, K., Farisco, M.: Anthropomorphism in ai. AJOB Neu- roscience11(2), 88–95 (2020). https://doi.org/10.1080/21507740.2020.1740350, https://doi.org/10.1080/21507740.2020.1740350
- [14]
-
[15]
In: Andrikopoulos, V., Pautasso, C., Ali, N., Soldani, J., Xu, X
Soliman, M., Ashraf, E., Abdelsalam, K.M.K., Keim, J., Venkatesh, A.P.S.: Llms for software architecture knowledge: A comparative analysis among seven llms. In: Andrikopoulos, V., Pautasso, C., Ali, N., Soldani, J., Xu, X. (eds.) Software Architecture. pp. 99–115. Springer Nature Switzerland, Cham (2026)
work page 2026
-
[16]
In: 2025 IEEE 22nd International Conference on Software Architecture (ICSA)
Soliman, M., Keim, J.: Do large language models contain software architec- tural knowledge? : An exploratory case study with gpt. In: 2025 IEEE 22nd International Conference on Software Architecture (ICSA). pp. 13–24 (2025). https://doi.org/10.1109/ICSA65012.2025.00012
-
[17]
Spiess, C., Devanbu, P., Barr, E.T.: How robustly do llms understand execution semantics? (2026), https://arxiv.org/abs/2604.16320
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
In: Christodoulopoulos, C., Chakraborty, T., Rose, C., Peng, V
Wei, A., Cao, J., Li, R., Chen, H., Zhang, Y., Wang, Z., Liu, Y., Teix- eira, T.S.F.X., Yang, D., Wang, K., Aiken, A.: EquiBench: Benchmarking large language models’ reasoning about program semantics via equivalence check- ing. In: Christodoulopoulos, C., Chakraborty, T., Rose, C., Peng, V. (eds.) Proceedings of the 2025 Conference on Empirical Methods in...
-
[19]
Zhou, X., Li, R., Liang, P., Zhang, B., Shahin, M., Li, Z., Yang, C.: Us- ing llms in generating design rationale for software architecture decisions. ACM Trans. Softw. Eng. Methodol. (Dec 2025). https://doi.org/10.1145/3785010, https://doi.org/10.1145/3785010, just Accepted
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.