Recognition: no theorem link
LMPath: Language-Mediated Priors and Path Generation for Aerial Exploration
Pith reviewed 2026-05-14 17:45 UTC · model grok-4.3
The pith
LMPath uses language models on satellite imagery to generate semantic priors that guide UAV search paths more efficiently than uniform geometric coverage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
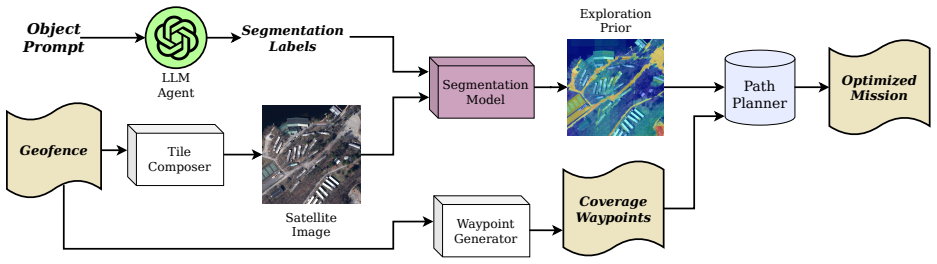
LMPath forms language-mediated exploration priors by first prompting generative language models to reason about likely object locations within a given environment and then running foundation vision models over satellite imagery to produce segmented sub-regions; the resulting prior is used to synthesize UAV trajectories that optimize search metrics such as expected time to detection or probability of success under travel constraints, with validation provided by both physical UAV experiments and comparative simulations.
What carries the argument
The LMPath pipeline, which combines language-model region prediction with vision-model segmentation of satellite imagery to produce semantic priors that constrain and direct UAV path generation.
If this is right
- UAV search missions can allocate flight time preferentially to semantically likely zones rather than uniform coverage.
- Paths can be optimized for a chosen objective such as minimum expected detection time or maximum probability within a distance limit.
- The same prior-generation step narrows the search space to a smaller set of sub-regions before path planning begins.
- Real UAV hardware can execute the resulting trajectories in large outdoor environments.
Where Pith is reading between the lines
- The same language-plus-vision prior could be applied to ground or marine vehicles for semantic-guided coverage tasks.
- Online fusion of UAV camera feeds with the initial satellite prior might allow dynamic re-weighting of regions during flight.
- Performance will likely degrade for rare or visually ambiguous objects whose satellite signatures are poorly represented in the training data of the foundation models.
- The pipeline could be tested for robustness by varying prompt phrasing and satellite image resolution to quantify sensitivity.
Load-bearing premise
Off-the-shelf generative language models and foundation vision models can reliably map an object prompt to the correct sub-regions of satellite imagery without domain-specific fine-tuning or ground-truth checks.
What would settle it
Run a side-by-side field trial in a large outdoor area with known object locations: measure time to first detection and overall success rate for LMPath-generated paths versus standard geometric-coverage paths; absence of consistent improvement falsifies the performance claim.
Figures



read the original abstract
Traditional autonomous UAV search missions rely on geometric coverage patterns that ignore the semantic context of the target, leading to significant time waste in large-scale environments. In this paper we present LMPath, a pipeline for generating language-mediated exploration priors for Unmanned Aerial Vehicle (UAV) search missions that leverages semantics. Given a basic geofence and an object of interest prompt, LMPath uses generative language models to determine what regions of the environment should contain that object and a foundation vision model ran over satellite imagery to segment sub-regions that form the exploration prior. This prior can then be used to generate UAV paths with various objectives, such as minimizing the expected time to locate the object of interest, maximizing the probability that the object is found given a limited travel distance, or narrowing down the search space to sub-regions that are most likely to contain the object. To demonstrate it's capabilities, we used LMPath to generate various UAV paths and ran them using a real UAV over large-scale environments. We also ran simulations to demonstrate how paths generated using LMPath outperform traditional path planning approaches for search missions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LMPath, a pipeline that uses generative language models to infer likely regions for a prompted object of interest within a geofence and applies foundation vision models to satellite imagery to segment sub-regions as semantic exploration priors. These priors then inform UAV path generation optimizing objectives such as minimizing expected time-to-find or maximizing detection probability within limited distance. The central claim is that paths produced by LMPath outperform traditional geometric coverage patterns, as shown in both real UAV flights over large-scale environments and simulations.
Significance. If the empirical claims hold with proper validation, LMPath could improve search efficiency in large environments by replacing uniform geometric patterns with semantically focused priors derived from off-the-shelf models. The approach is modular and leverages existing foundation models without requiring domain-specific training, which is a practical strength for rapid deployment in robotics applications.
major comments (3)
- [Abstract] Abstract: The assertion that 'paths generated using LMPath outperform traditional path planning approaches for search missions' in real UAV flights and simulations is presented without any quantitative metrics (e.g., mean time-to-detection, success probability, or coverage efficiency), baseline definitions (e.g., specific lawnmower or spiral patterns), error bars, or statistical controls. This leaves the headline empirical result unsupported.
- [Methods/Experiments] Methods and Experiments sections: No quantitative validation is provided for the core assumption that the foundation vision model applied to satellite imagery produces priors correlated with actual object presence. Missing are metrics such as IoU against ground-truth locations, precision-recall of segmented regions, or ablation studies that remove the vision step to measure its isolated contribution versus uniform search.
- [Results] Results: The pipeline description gives no error analysis for cases where the language model or vision segmentation misidentifies regions (e.g., false positives leading to wasted flight time or false negatives missing the target), which directly affects whether the claimed time or probability gains survive realistic segmentation noise.
minor comments (2)
- [Abstract] Abstract contains a grammatical error: 'To demonstrate it's capabilities' should read 'its capabilities'.
- [Methods] The description of path objectives (minimizing expected time, maximizing probability) would benefit from explicit mathematical formulations or pseudocode in the Methods section to clarify how the priors are converted into cost functions.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We agree that strengthening the quantitative support for our claims will improve the manuscript and address the concerns raised. Below we respond point-by-point to the major comments and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'paths generated using LMPath outperform traditional path planning approaches for search missions' in real UAV flights and simulations is presented without any quantitative metrics (e.g., mean time-to-detection, success probability, or coverage efficiency), baseline definitions (e.g., specific lawnmower or spiral patterns), error bars, or statistical controls. This leaves the headline empirical result unsupported.
Authors: We agree that the abstract should explicitly report key quantitative results to support the performance claims. In the revised manuscript we will update the abstract to include specific metrics such as mean time-to-detection, success probability, and coverage efficiency from both the simulation and real-flight experiments, along with clear definitions of the baseline geometric patterns (lawnmower and spiral) and mention of error bars and statistical controls. revision: yes
-
Referee: [Methods/Experiments] Methods and Experiments sections: No quantitative validation is provided for the core assumption that the foundation vision model applied to satellite imagery produces priors correlated with actual object presence. Missing are metrics such as IoU against ground-truth locations, precision-recall of segmented regions, or ablation studies that remove the vision step to measure its isolated contribution versus uniform search.
Authors: We acknowledge the absence of direct quantitative validation for the vision segmentation priors. We will add a new subsection in the Experiments section reporting IoU and precision-recall metrics for the segmented regions against ground-truth object locations collected in our test environments. We will also include an ablation study that isolates the contribution of the vision prior by comparing LMPath performance against a uniform-search baseline that omits the vision step. revision: yes
-
Referee: [Results] Results: The pipeline description gives no error analysis for cases where the language model or vision segmentation misidentifies regions (e.g., false positives leading to wasted flight time or false negatives missing the target), which directly affects whether the claimed time or probability gains survive realistic segmentation noise.
Authors: We agree that an explicit error analysis is needed. In the revised Results section we will add a dedicated subsection that examines failure modes of the language model and vision segmentation, provides concrete examples from our datasets, and quantifies the impact of segmentation noise on path efficiency through sensitivity analysis and Monte Carlo simulations of false-positive and false-negative priors. revision: yes
Circularity Check
No circularity detected; pipeline relies on external pre-trained models and separate empirical tests
full rationale
The paper's derivation chain consists of applying off-the-shelf generative language models and foundation vision models to satellite imagery to produce exploration priors, then using those priors for path generation with stated objectives, followed by independent simulation and real-UAV empirical evaluation. No equations, fitted parameters, self-citations, or definitional loops are present in the abstract or pipeline description that would reduce any claimed outperformance to the inputs by construction. The method is self-contained against external benchmarks (pre-trained models and physical tests), making a score of 0 the appropriate finding per the evaluation rules.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 23rd Annual International Conference on Mobile Systems, Applications and Services , pages =
Hatch, Matthew and Fellinge, Cody and Diller, Jonathan and Han, Qi , title =. Proceedings of the 23rd Annual International Conference on Mobile Systems, Applications and Services , pages =. 2025 , isbn =
2025
-
[2]
UAV-VLA: Vision-Language-Action System for Large Scale Aerial Mission Generation , year=
Sautenkov, Oleg and Yaqoot, Yasheerah and Lykov, Artem and Mustafa, Muhammad Ahsan and Tadevosyan, Grik and Akhmetkazy, Aibek and Cabrera, Miguel Altamirano and Martynov, Mikhail and Karaf, Sausar and Tsetserukou, Dzmitry , booktitle=. UAV-VLA: Vision-Language-Action System for Large Scale Aerial Mission Generation , year=
-
[3]
2025 , eprint=
HALO: High-Altitude Language-Conditioned Monocular Aerial Exploration and Navigation , author=. 2025 , eprint=
2025
-
[4]
2025 , eprint=
UAV-CodeAgents: Scalable UAV Mission Planning via Multi-Agent ReAct and Vision-Language Reasoning , author=. 2025 , eprint=
2025
-
[5]
UAV-VLPA*: Vision-Language Guided Global-Local UAV Mission Planning from Satellite Imagery , year=
Sautenkov, Oleg and Akhmetkazy, Aibek and Yaqoot, Yasheerah and Mustafa, Muhammad Ahsan and Tadevosyan, Grik and Lykov, Artem and Serpiva, Valerii and Tsetserukou, Dzmitry , booktitle=. UAV-VLPA*: Vision-Language Guided Global-Local UAV Mission Planning from Satellite Imagery , year=
-
[6]
IB-AMG: Aircraft Mission Generation With Inference-based Vision-Language-Action Model , year=
Li, JinHai and Chen, Peng and Li, MoHan and Ren, LuYi , booktitle=. IB-AMG: Aircraft Mission Generation With Inference-based Vision-Language-Action Model , year=
-
[7]
2026 , eprint=
SAM 3: Segment Anything with Concepts , author=. 2026 , eprint=
2026
-
[8]
Diller, Jonathan and Han, Qi , title =. ACM J. Auton. Transport. Syst. , month = jun, articleno =. 2025 , issue_date =. doi:10.1145/3716894 , abstract =
-
[9]
and Pappas, George J
Cladera, Fernando and Ravichandran, Zachary and Hughes, Jason and Murali, Varun and Nieto-Granda, Carlos and Ani Hsieh, M. and Pappas, George J. and Taylor, Camillo J. and Kumar, Vijay , journal=. Air-Ground Collaboration for Language-Specified Missions in Unknown Environments , year=
-
[10]
Ani and Taylor, Camillo J
Cladera, Fernando and Chaney, Kenneth and Hsieh, M. Ani and Taylor, Camillo J. and Kumar, Vijay , booktitle=. EvMAPPER: High-Altitude Orthomapping with Event Cameras , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.