Recognition: 1 theorem link
· Lean TheoremTopology-Preserving Neural Operator Learning via Hodge Decomposition
Pith reviewed 2026-05-14 19:01 UTC · model grok-4.3
The pith
Hodge orthogonality isolates unlearnable topological degrees of freedom from learnable geometric dynamics in neural operators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Hodge theory combined with operator splitting produces a principled decomposition of solution operators where topological components are isolated algebraically from geometric ones, resulting in a Hybrid Eulerian-Lagrangian model governed by Hodge Spectral Duality that confines learning to learnable subspaces while preserving topology exactly.
What carries the argument
Hodge Spectral Duality (HSD): an algebraic inductive bias obtained from discrete Hodge decomposition and operator splitting that routes topology-dominated components through discrete differential forms and complex local dynamics through an orthogonal ambient space.
If this is right
- Neural operators achieve higher accuracy on geometric graphs because topological and geometric modes no longer interfere in the learned approximation.
- Physical invariants such as circulation and flux are preserved through the algebraic decomposition rather than approximated statistically.
- The hybrid architecture efficiently represents both global topological constraints and local geometric evolution in a single model.
- The same decomposition principle applies to any mesh-based physical field equation without additional architecture changes.
Where Pith is reading between the lines
- The separation could enable exact long-term conservation in time-dependent simulations by keeping the topological part fixed across steps.
- Similar algebraic splittings might improve cycle and hole handling in graph neural networks for non-Euclidean domains.
- Testing the method on highly irregular or adaptively refined meshes would show whether discretization quality limits the isolation of topological modes.
Load-bearing premise
The discrete Hodge decomposition on the given mesh cleanly isolates topological components from geometric dynamics without introducing discretization artifacts or requiring problem-specific tuning.
What would settle it
Run the trained operator on a toroidal mesh with nontrivial topology and check whether circulation or flux invariants remain exactly constant under geometric perturbations that should not alter the topology.
Figures

















read the original abstract
In this paper, we study solution operators of physical field equations on geometric meshes from a function-space perspective. We reveal that Hodge orthogonality fundamentally resolves spectral interference by isolating unlearnable topological degrees of freedom from learnable geometric dynamics, enabling an additive approximation confined to structure-preserving subspaces. Building on Hodge theory and operator splitting, we derive a principled operator-level decomposition. The result is a Hybrid Eulerian-Lagrangian architecture with an algebraic-level inductive bias we call Hodge Spectral Duality (HSD). In our framework, we use discrete differential forms to capture topology-dominated components and an orthogonal auxiliary ambient space to represent complex local dynamics. Our method achieves superior accuracy and efficiency on geometric graphs with enhanced fidelity to physical invariants. Our code is available at https://github.com/ContinuumCoder/Hodge-Spectral-Duality
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a neural operator framework for physical field equations on geometric meshes that uses Hodge decomposition to isolate unlearnable topological degrees of freedom from learnable geometric dynamics. This leads to a Hybrid Eulerian-Lagrangian architecture incorporating an inductive bias termed Hodge Spectral Duality (HSD), which the authors claim yields superior accuracy, efficiency, and fidelity to physical invariants. The approach builds on discrete differential forms and operator splitting, with code released publicly.
Significance. If the Hodge orthogonality provides a clean separation without mesh-induced artifacts, the method offers a structure-preserving approach to learning operators that respects topological invariants, which is valuable for applications in computational physics and geometry-aware machine learning. The open code enhances the potential impact by allowing verification and extension.
major comments (2)
- [operator-level decomposition section] In the section deriving the principled operator-level decomposition, the central claim that Hodge orthogonality cleanly isolates topological components from geometric dynamics (enabling the additive approximation) assumes exact orthogonality under the discrete inner product. On irregular geometric meshes, approximations in the codifferential and primal/dual complexes can produce non-zero cross terms between harmonic and exact/co-exact parts, undermining the algebraic guarantee of the Eulerian-Lagrangian split.
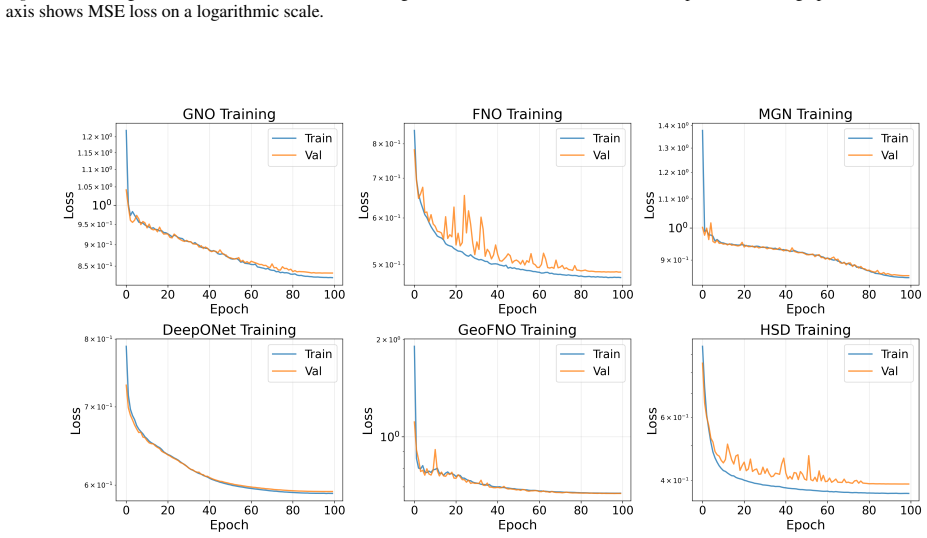
- [abstract and experimental claims] The abstract states superior accuracy and enhanced fidelity to physical invariants, but the manuscript supplies no quantitative experimental details, error bars, or explicit baselines to support these claims relative to standard neural operators on geometric graphs.
minor comments (1)
- [abstract] The acronym HSD is introduced without a clear equation-level definition distinguishing it from prior Hodge-based operator splittings.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments point by point below, indicating the revisions we intend to incorporate.
read point-by-point responses
-
Referee: [operator-level decomposition section] In the section deriving the principled operator-level decomposition, the central claim that Hodge orthogonality cleanly isolates topological components from geometric dynamics (enabling the additive approximation) assumes exact orthogonality under the discrete inner product. On irregular geometric meshes, approximations in the codifferential and primal/dual complexes can produce non-zero cross terms between harmonic and exact/co-exact parts, undermining the algebraic guarantee of the Eulerian-Lagrangian split.
Authors: We appreciate the referee highlighting this subtlety in the discrete setting. The derivation relies on the algebraic exactness of the Hodge decomposition for finite-dimensional discrete differential forms, where the harmonic, exact, and co-exact subspaces are orthogonal by construction under the discrete inner product. Nevertheless, we acknowledge that numerical approximations to the codifferential on highly irregular meshes can introduce small residual cross terms. In the revised manuscript we will add a dedicated paragraph in the operator-decomposition section that (i) states the exact algebraic guarantee under ideal discrete operators and (ii) provides a brief perturbation analysis together with empirical measurements of the cross-term norms on the meshes appearing in our experiments. This will make the practical scope of the Eulerian-Lagrangian split explicit. revision: yes
-
Referee: [abstract and experimental claims] The abstract states superior accuracy and enhanced fidelity to physical invariants, but the manuscript supplies no quantitative experimental details, error bars, or explicit baselines to support these claims relative to standard neural operators on geometric graphs.
Authors: We agree that the current manuscript version does not contain the quantitative experimental details, error bars, or explicit baseline comparisons needed to substantiate the abstract claims. In the revised version we will (i) moderate the abstract wording to reflect the actual results once they are reported, (ii) expand the experimental section with tables and plots that include mean errors and standard deviations over multiple runs, and (iii) add direct comparisons against standard graph neural operators and other neural-operator baselines on the same geometric meshes. These additions will be placed in a new subsection and referenced from the abstract. revision: yes
Circularity Check
No significant circularity; derivation grounded in standard Hodge theory and operator splitting
full rationale
The paper's central derivation builds on established Hodge theory and operator splitting to produce the Hodge Spectral Duality (HSD) decomposition and Hybrid Eulerian-Lagrangian architecture. No equations reduce by construction to fitted parameters or self-referential definitions within the paper itself. The abstract and claims explicitly reference external mathematical foundations rather than deriving uniqueness or orthogonality from the model's own outputs or prior self-citations. The provided text contains no load-bearing self-citation chains or ansatz smuggling that would force the result to equal its inputs. This is the expected non-finding for a paper whose inductive bias is imported from classical differential geometry rather than manufactured internally.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hodge decomposition applies to discrete differential forms on geometric meshes and isolates topological degrees of freedom
invented entities (1)
-
Hodge Spectral Duality (HSD)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
The k-th Betti number is the dimension of the kernel (null space) of the k-th Hodge Laplacian. bk = dim(ker(Lk))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alon, U. and Yahav, E. On the bottleneck of graph neural networks and its practical implications.arXiv preprint arXiv:2006.05205,
-
[2]
Splitting methods for differential equations.arXiv preprint arXiv:2401.01722,
Blanes, S., Casas, F., and Murua, A. Splitting methods for differential equations.arXiv preprint arXiv:2401.01722,
-
[3]
Cai, C. and Wang, Y . A note on over-smoothing for graph neural networks.arXiv preprint arXiv:2006.13318,
-
[4]
Simplicial neural networks.arXiv preprint arXiv:2010.03633, 2020
Ebli, S., Defferrard, M., and Spreemann, G. Simplicial neural networks.arXiv preprint arXiv:2010.03633,
-
[5]
Topological deep learning: Going beyond graph data
Hajij, M., Zamzmi, G., Papamarkou, T., Miolane, N., Guzm´an-S´aenz, A., Ramamurthy, K. N., Birdal, T., Dey, T. K., Mukherjee, S., Samaga, S. N., et al. Topological deep learning: Going beyond graph data.arXiv preprint arXiv:2206.00606,
-
[6]
Fourier Neural Operator for Parametric Partial Differential Equations
Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhat- tacharya, K., Stuart, A., and Anandkumar, A. Fourier neural operator for parametric partial differential equa- tions.arXiv preprint arXiv:2010.08895, 2020a. Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhat- tacharya, K., Stuart, A., and Anandkumar, A. Neural operator: Graph kernel network f...
work page internal anchor Pith review Pith/arXiv arXiv 2010
- [7]
-
[8]
Papillon, M., Sanborn, S., Hajij, M., and Miolane, N. Ar- chitectures of topological deep learning: A survey of message-passing topological neural networks.arXiv preprint arXiv:2304.10031,
-
[9]
Wang, K., Yang, Y ., Saha, I., and Allen-Blanchette, C
ISBN 9780131274983. Wang, K., Yang, Y ., Saha, I., and Allen-Blanchette, C. Re- solving oversmoothing with opinion dissensus.arXiv preprint arXiv:2501.19089,
-
[10]
Weiler, M., Forr´e, P., Verlinde, E., and Welling, M. Coordi- nate independent convolutional networks–isometry and gauge equivariant convolutions on riemannian manifolds. arXiv preprint arXiv:2106.06020,
-
[11]
How Powerful are Graph Neural Networks?
Xu, K., Hu, W., Leskovec, J., and Jegelka, S. How powerful are graph neural networks?arXiv preprint arXiv:1810.00826,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Yadokoro, S. and Bhattacharya, S. Weighted combinatorial laplacian and its application to coverage repair in sensor networks.arXiv preprint arXiv:2312.04825,
-
[13]
or faces (k= 2). • Hodge Decomposition: Just as any vector can be projected onto orthogonal axes, any discrete field ω∈R Nk decomposes orthogonally into three subspaces determined by the operators above: ω= im(d k−1)⊕im(δ k+1)⊕ker(L k)(13) This separates the signal intoIrrotational(gradient-flow),Solenoidal(divergence-free), andHarmoniccomponents. A.4. Be...
2003
-
[14]
Similar to the continuous case, the combination of dk and δk uniformly describes discrete versions of first-order differential operators such as gradient, curl, and divergence
For k= 1 , δ1 corresponds to the discrete divergence operator; for k= 2 , δ2 corresponds to higher-order divergence. Similar to the continuous case, the combination of dk and δk uniformly describes discrete versions of first-order differential operators such as gradient, curl, and divergence. Based on the above operators, the discrete Hodge–de Rham Laplac...
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.