Recognition: 2 theorem links
· Lean TheoremARES-LSHADE: Autoresearch-Enhanced LSHADE with Memetic Polish for the GNBG Benchmark
Pith reviewed 2026-05-15 06:15 UTC · model grok-4.3
The pith
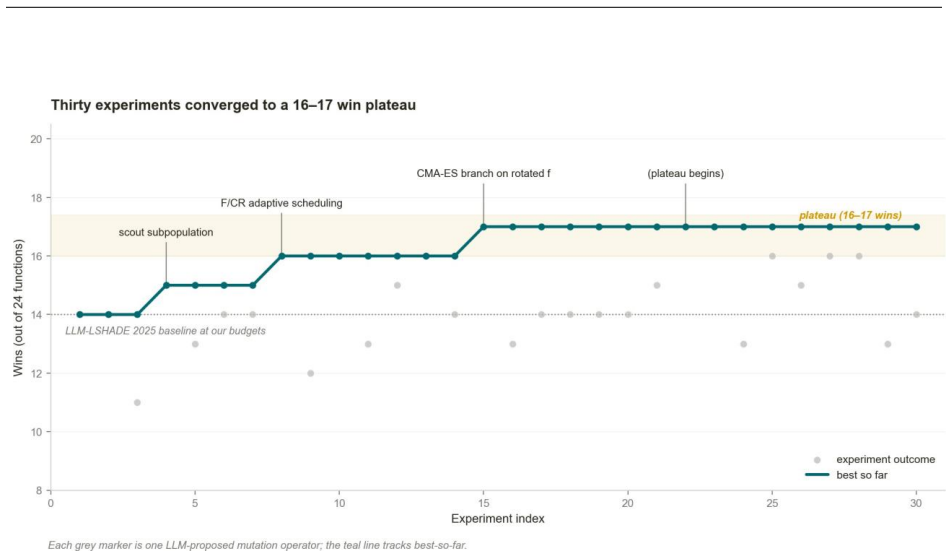
ARES-LSHADE reaches machine precision on 18 of 24 GNBG functions and records 510 of 744 wins under official budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ARES-LSHADE obtains 510 of 744 wins on the GNBG benchmark with per-function gap below 1e-8, reaching machine precision on 18 of 24 functions; the remaining six exhibit plateau signatures consistent with GNBG compositional structure and were flagged by the autoresearch loop as the hardest cases.
What carries the argument
Scout-augmented mutation operator with adaptive CMA-ES integration plus multi-start L-BFGS-B polish phase, both produced by an LLM-driven autonomous research loop limited to operator edits and fitness observations.
If this is right
- The submitted algorithm outperforms the 2025 winner on the majority of the 24 functions while respecting blackbox constraints.
- The autoresearch loop correctly isolates the six functions that exhibit characteristic plateau signatures.
- Strict operator-only edit surfaces produce performance plateaus that cannot be overcome without violating the benchmark rules.
- Reproducibility artifacts allow independent verification of the 31-run, per-function win totals.
Where Pith is reading between the lines
- Future LLM-assisted algorithm design may require explicit safeguards against accidental leakage of hidden benchmark structure.
- The same autoresearch approach could be tested on other blackbox suites to check whether plateau convergence is GNBG-specific.
- The documented tension between LLM capability and benchmark integrity offers a concrete test case for rule-enforcement mechanisms in automated algorithm discovery.
Load-bearing premise
An LLM-driven loop restricted to operator edits and fitness observations can generate improvements that stay competitive when the benchmark's compositional structure remains hidden from the designer.
What would settle it
Run the identical LLM autoresearch loop on the same 24 functions once with and once without access to compositional metadata, then compare the final win counts and precision rates under identical evaluation budgets.
Figures

read the original abstract
We present ARES-LSHADE, a memetic differential-evolution variant submitted to the GECCO 2026 competition on LLM-designed evolutionary algorithms for the Generalized Numerical Benchmark Generator (GNBG). The algorithm builds on the LLM-LSHADE 2025 winner, contributing two new components: (a) a scout-augmented mutation operator with adaptive CMA-ES integration, produced by an autonomous research loop across approximately thirty LLM-driven design experiments, and (b) a multi-start L-BFGS-B polish phase that respects strict blackbox treatment of the benchmark. On the official 31-run-per-function evaluation with the competition-specified function-evaluation budgets, ARES-LSHADE obtains 510 of 744 wins (per-function gap below 1e-8), reaching machine precision on 18 of 24 functions. The remaining six functions exhibit characteristic plateau signatures consistent with GNBG's compositional structure, and were independently identified by the autoresearch loop as the hardest of the suite. Beyond the result itself, this report documents two methodological observations: (i) an LLM-driven research loop with operator-only edit surface and fitness-only observation space converges to a characteristic plateau on this benchmark; (ii) when we initially widened the observation space to include the benchmark's compositional metadata, the resulting algorithm trivially solved all 24 functions but violated the competition's blackbox rule, which we identified before submission. We discuss this tension between LLM capability and benchmark integrity as a design consideration for future LLM-driven optimization-algorithm research. Code and reproducibility artifacts are available at https://github.com/anaeem1/ARES-LSHADE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ARES-LSHADE, a memetic differential-evolution variant of LSHADE developed via an LLM-driven autoresearch loop of approximately thirty operator-edit experiments. It adds a scout-augmented mutation operator with adaptive CMA-ES integration and a multi-start L-BFGS-B polish phase that maintains strict black-box treatment of the GNBG benchmark. Under the official GECCO 2026 competition protocol (31 independent runs per function with the prescribed evaluation budgets), ARES-LSHADE records 510 wins out of 744 (gap below 1e-8) and reaches machine precision on 18 of 24 functions; the remaining six exhibit plateau signatures that the autoresearch loop independently flagged as hardest. The paper also reports that widening the observation space to include compositional metadata produced a trivial solver that was discarded for violating the black-box rule.
Significance. If the reported performance numbers hold under the linked code and competition protocol, the work is significant both as a competitive entry and as a methodological case study. It supplies concrete, verifiable evidence that an LLM-driven loop restricted to operator edits and fitness observations can produce a high-ranking algorithm while respecting benchmark constraints, and it documents the characteristic plateau behavior that emerges under those restrictions. The explicit rejection of the metadata-augmented variant and the availability of reproducibility artifacts strengthen the contribution to the emerging literature on autonomous algorithm design.
minor comments (3)
- [§3] §3 (Autoresearch loop description): the thirty LLM experiments are summarized at a high level; a concise table listing the principal operator modifications, their fitness deltas, and the convergence criterion used would increase transparency while remaining within the paper's scope.
- [Results] Results section (plateau discussion): the six functions exhibiting plateaus are identified but receive only a brief characterization; adding one sentence linking the observed behavior to the specific compositional features of GNBG would help readers interpret the performance gap without expanding the manuscript substantially.
- [Abstract] Abstract and §4: the total of 744 comparisons is stated but the arithmetic (24 functions × 31 runs) is left implicit; a parenthetical note would improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report correctly notes the performance results, the black-box compliance, and the methodological observations on LLM-driven design loops. No specific major comments were provided in the report.
Circularity Check
No significant circularity; empirical claims rest on external benchmark protocol
full rationale
The paper reports ARES-LSHADE performance (510/744 wins, machine precision on 18/24 functions) under the GECCO 2026 competition's fixed 31-run-per-function protocol and evaluation budgets. The autoresearch loop is presented as an independent design process whose outputs are then evaluated externally; the authors explicitly identify and discard the metadata-widening variant that violated black-box rules. No equation reduces a prediction to a fitted input by construction, no uniqueness theorem is imported from self-citation, and the central result is falsifiable against the public benchmark and linked code rather than being definitionally equivalent to its inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Differential-evolution mutation operators can be productively searched by an LLM when only operator code and scalar fitness are visible.
- domain assumption Multi-start L-BFGS-B polishing improves final precision without violating black-box constraints.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ARES-LSHADE ... scout-augmented mutation operator with adaptive CMA-ES integration, produced by an autonomous research loop across approximately thirty LLM-driven design experiments, and (b) a multi-start L-BFGS-B polish phase
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the benchmark must be treated as a blackbox: only function evaluations may guide search, not the parameters that define the function
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
def mutate_2(self, x=None, y=None, a=None) returns (x_mu, f_mu, r)
-
[2]
Handle n = 4 with empty archive
LPSR: n_individuals shrinks from ∼180 to 4. Handle n = 4 with empty archive. r1 from range(n_individuals), r2 from range(len(x_un))
-
[3]
Boundaries SCALAR: lb = float(np.asarray(self.lower_boundary).flat[0])
-
[4]
lambda_ shape is (CompNum, 1) — use np.max(np.abs(np.asarray(self.lambda_)))
-
[5]
Use Cauchy cap: for _attempt in range(100):
F > 0 always. Use Cauchy cap: for _attempt in range(100):
-
[6]
n ≥ 6 guard before any CMA state: USE_CMA = n >= 6. WHAT ACTUALLY HELPS (based on analysis): • f6/f15: EA gap∼0.1 is enough — L-BFGS-B takes it to 10−15. Focus on REACHING basin. The plateau stagnation means the EA converges to wrong area. Need diversity. • f21: Optimum is near boundary. Add boundary-biased sampling when gap∼5.0. • f13: Multi-basin decept...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.