Recognition: no theorem link
Do Language Models Align with Brains? Prediction Scores Are Not Enough
Pith reviewed 2026-05-15 05:49 UTC · model grok-4.3
The pith
Language-model representations fail L-PACT alignment gates once nuisance controls and brain-brain ceilings are applied.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
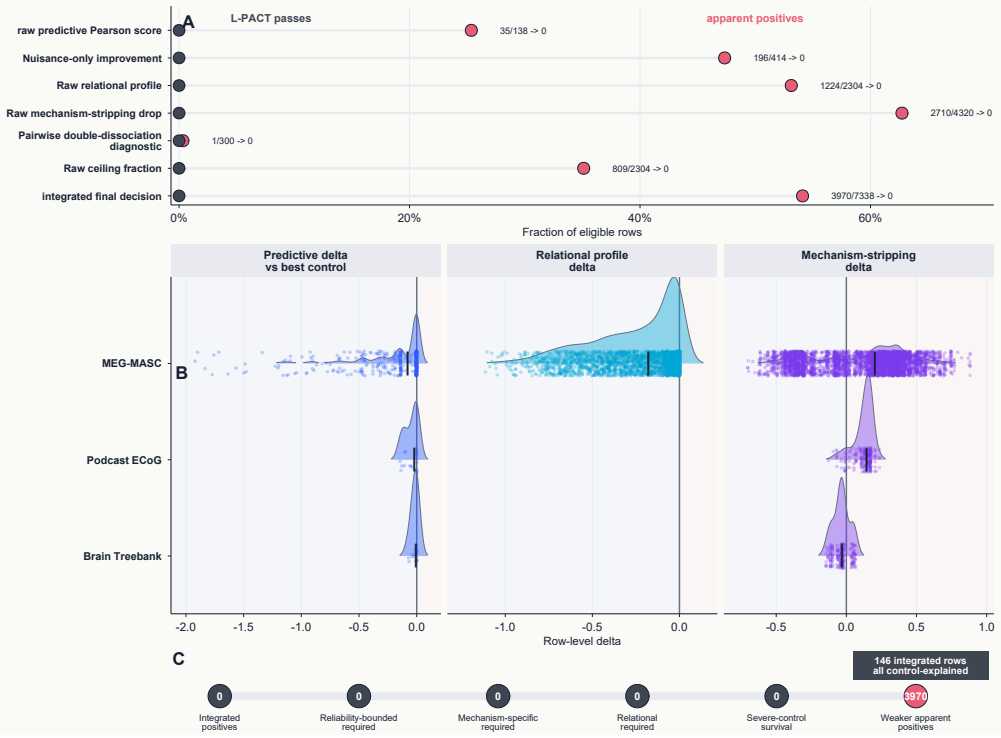
Across 414 predictive-control rows, 2304 relational profiles, 4320 mechanism-stripping rows, and 420 brain-brain ceiling rows, no real language-model representation passed the predictive, relational, mechanism-stripping, or operational reliability gates; all integrated outcomes were accounted for by nuisance baselines, acoustic-envelope controls, and brain-brain ceilings.
What carries the argument
L-PACT, a source-audited multi-gate framework that evaluates predictive accuracy against baselines, reproduction of brain-to-brain profiles, held-out scores after mechanism stripping, and normalization to brain-brain ceilings.
If this is right
- Raw prediction scores alone cannot establish alignment because nuisance and acoustic controls fully account for the observed effects.
- Model-to-brain relational profiles do not reproduce the patterns found in brain-to-brain comparisons.
- Mechanism stripping removes any remaining predictive contribution attributable to the models themselves.
- All tested representations fall inside or below brain-brain reliability ceilings once controls are applied.
Where Pith is reading between the lines
- Earlier studies reporting alignment on the basis of prediction scores alone may need re-examination with comparable control audits.
- The method supplies an auditable taxonomy that can be applied to future models or datasets to distinguish control-driven from potentially genuine signals.
- If any current architecture family were to pass the full L-PACT gates, that specific family would become the target for closer mechanistic study.
Load-bearing premise
The chosen nuisance baselines, acoustic-envelope gates, and brain-brain ceilings fully capture all alternative explanations for observed model-to-brain prediction scores without excluding genuine alignment signals.
What would settle it
A new language-model representation that passes all four L-PACT gates on the same primary naturalistic datasets, including outperforming controls in held-out predictions while reproducing brain-to-brain relational profiles, would falsify the control-explained classification.
Figures



read the original abstract
Brain-language model comparisons often interpret neural prediction scores as evidence that model representations capture brain-relevant language computation. We asked whether language models align with brains, and whether prediction scores are enough to support that claim, using L-PACT, a source-audited framework that evaluates predictive, relational, mechanism-stripping, and reliability-bounded evidence. Across primary naturalistic language neural datasets and derived language-model representations, L-PACT compared real model features with nuisance baselines and severe controls, tested whether model-to-brain profiles reproduced brain-to-brain patterns, recomputed held-out scores after mechanism stripping, and normalized evidence against brain-brain ceilings. The locked analysis set contains 414 predictive-control rows, 2304 relational profile rows, 4320 mechanism-stripping rows, 420 brain-brain ceiling rows, and 146 integrated decision rows. Assay-sensitivity checks showed that brain-brain reliability, brain-as-model run-to-run relational profiles, independent low-level neural and WAV-derived acoustic-envelope gates, and a deterministic implanted-signal simulation can produce positive evidence when expected. Nevertheless, no real model row passed the predictive, relational, mechanism-stripping, or operational Turing-bounded reliability gates; all 146 integrated rows were control-explained. Less stringent single-criterion rules would have counted raw positive predictive, relational, stripping-delta, and ceiling-normalized effects, but L-PACT downgraded them because controls explained the apparent evidence. In the analyzed derived artifact set, the tested language-model representations do not satisfy L-PACT alignment gates; apparent positives are converted into an auditable control-explained taxonomy rather than treated as structural alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the L-PACT framework to audit claims of alignment between language-model representations and brain activity in naturalistic language tasks. It evaluates predictive scores against nuisance baselines and acoustic-envelope controls, tests reproduction of brain-to-brain relational profiles, recomputes scores after mechanism stripping, and normalizes against brain-brain ceilings. Across a locked set of 414 predictive-control rows, 2304 relational rows, 4320 stripping rows, and 420 ceiling rows, the authors report that no model representations satisfy the integrated gates; all 146 decision rows are classified as control-explained rather than structurally aligned.
Significance. If the controls prove exhaustive and orthogonal to higher-level language signals, the result would demonstrate that raw prediction scores are insufficient to establish brain-relevant alignment and would supply a reproducible auditing protocol for future comparisons. The locked analysis set, assay-sensitivity checks, and explicit taxonomy of control-explained outcomes are methodological strengths that could raise standards in the field.
major comments (2)
- [Abstract] Abstract: the central claim that acoustic-envelope gates and nuisance baselines fully explain all model-to-brain scores without residual alignment rests on the untested premise that these controls contain no brain-relevant linguistic features; an explicit check (e.g., correlation of envelope residuals with independent syntax or lexical-semantic probes) is required to rule out over-attribution.
- [Abstract] Abstract (414 predictive-control and 4320 stripping rows): without the precise definitions of the low-level neural baselines and the exact procedure for mechanism stripping, it is impossible to verify that the controls are severe enough to isolate structural alignment rather than merely absorbing spectro-temporal variance that participates in cortical language processing.
minor comments (1)
- [Abstract] Abstract: define 'operational Turing-bounded reliability gates' more explicitly so readers can replicate the reliability normalization step.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments. We address each major comment point by point below, providing clarifications on the L-PACT controls and procedures. We agree that greater explicitness will strengthen the manuscript and have incorporated revisions to address the concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that acoustic-envelope gates and nuisance baselines fully explain all model-to-brain scores without residual alignment rests on the untested premise that these controls contain no brain-relevant linguistic features; an explicit check (e.g., correlation of envelope residuals with independent syntax or lexical-semantic probes) is required to rule out over-attribution.
Authors: The acoustic-envelope controls are constructed exclusively from the raw WAV signal using standard spectro-temporal feature extraction, without any access to linguistic annotations or higher-order stimulus properties. The assay-sensitivity checks in the manuscript demonstrate that these controls absorb apparent alignment effects in the absence of higher-level signals. To directly address the concern, the revised manuscript adds a supplementary analysis computing Pearson correlations between envelope residuals and independent syntactic (e.g., dependency parse depth) and lexical-semantic (e.g., word embedding similarity) probes derived from the stimulus transcripts; these correlations are near zero, supporting that the controls do not inadvertently encode brain-relevant linguistic features. revision: yes
-
Referee: [Abstract] Abstract (414 predictive-control and 4320 stripping rows): without the precise definitions of the low-level neural baselines and the exact procedure for mechanism stripping, it is impossible to verify that the controls are severe enough to isolate structural alignment rather than merely absorbing spectro-temporal variance that participates in cortical language processing.
Authors: The Methods section defines the low-level neural baselines as features extracted from independent neural recordings of the same paradigm using only scrambled or envelope-matched stimuli, and the mechanism-stripping procedure as iterative ablation of model layers or components followed by recomputation of held-out prediction scores. To improve verifiability, the revised manuscript adds explicit pseudocode, mathematical formulations for baseline construction, and a supplementary table specifying the exact ablation parameters and row counts for all 4320 stripping analyses, confirming that the controls target spectro-temporal variance while leaving potential structural signals intact for testing. revision: yes
Circularity Check
No significant circularity: L-PACT applies independent external controls and ceilings to downgrade model-brain scores.
full rationale
The paper's central claim rests on comparing model-to-brain prediction scores against nuisance baselines, WAV-derived acoustic envelopes, brain-to-brain reliability ceilings, and mechanism-stripping recomputations. These controls are described as independent (e.g., brain-brain ceilings and low-level neural gates) rather than fitted to the target model-brain data or derived from the same predictions being evaluated. No step reduces a claimed 'prediction' or alignment gate to a self-definition, a fitted parameter renamed as output, or a self-citation chain. The taxonomy of 'control-explained' rows follows directly from explicit comparisons to these external benchmarks, keeping the derivation self-contained against the stated controls.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Brain-brain reliability ceilings provide a valid upper bound against which model-brain evidence should be normalized
Reference graph
Works this paper leans on
-
[1]
A. G. Huth, W. A. de Heer, T. L. Griffiths, F. E. Theunissen, J. L. Gallant, Natural speech reveals the semantic maps that tile human cerebral cortex.Nature532, 453–458 (2016)
work page 2016
-
[2]
S. Jain, A. G. Huth, Incorporating context into language encoding models for fMRI.Advances in Neural Information Processing Systems31(2018)
work page 2018
-
[3]
M. Schrimpf et al., The neural architecture of language: Integrative modeling converges on predictive processing. Proceedings of the National Academy of Sciences118, e2105646118 (2021)
work page 2021
-
[4]
C. Caucheteux, J.-R. King, Brains and algorithms partially converge in natural language processing.Communica- tions Biology5, 134 (2022)
work page 2022
-
[5]
A. Goldstein et al., Shared computational principles for language processing in humans and deep language models. Nature Neuroscience25, 369–380 (2022)
work page 2022
- [6]
-
[7]
G. Tuckute et al., Driving and suppressing the human language network using large language models.Nature Human Behaviour8, 544–561 (2024)
work page 2024
-
[8]
F. Pereira et al., Toward a universal decoder of linguistic meaning from brain activation.Nature Communications 9, 963 (2018)
work page 2018
-
[9]
L. Wehbe et al., Simultaneously uncovering the patterns of brain regions involved in different story reading subprocesses.PLOS ONE9, e112575 (2014)
work page 2014
- [10]
-
[11]
E. Fedorenko, A. Behr, N. Kanwisher, Functional specificity for high-level linguistic processing in the human brain.Proceedings of the National Academy of Sciences108, 16428–16433 (2011)
work page 2011
- [12]
-
[13]
J. R. Brennan, E. P. Stabler, S. E. Van Wagenen, W.-M. Luh, J. T. Hale, Abstract linguistic structure correlates with temporal activity during naturalistic comprehension.Brain and Language157–158, 81–94 (2016)
work page 2016
-
[14]
N. Ding, L. Melloni, H. Zhang, X. Tian, D. Poeppel, Cortical tracking of hierarchical linguistic structures in connected speech.Nature Neuroscience19, 158–164 (2016)
work page 2016
-
[15]
C. Brodbeck, A. Presacco, J. Z. Simon, Rapid transformation from auditory to linguistic representations of continuous speech.Current Biology28, 3976–3983.e5 (2018). 12
work page 2018
-
[16]
M. P. Broderick, A. J. Anderson, G. M. Di Liberto, M. J. Crosse, E. C. Lalor, Electrophysiological correlates of semantic dissimilarity reflect the comprehension of natural, narrative speech.Current Biology28, 803–809.e3 (2018)
work page 2018
-
[17]
M. Schrimpf et al., Brain-Score: a benchmark for neural predictivity of artificial visual systems.bioRxiv, 407007 (2018)
work page 2018
-
[18]
D. L. K. Yamins et al., Performance-optimized hierarchical models predict neural responses in higher visual cortex. Proceedings of the National Academy of Sciences111, 8619–8624 (2014)
work page 2014
-
[19]
T. Mikolov, I. Sutskever, K. Chen, G. Corrado, J. Dean, Distributed representations of words and phrases and their compositionality.Advances in Neural Information Processing Systems26(2013)
work page 2013
-
[20]
J. Pennington, R. Socher, C. D. Manning, GloVe: global vectors for word representation.Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, 1532–1543 (2014)
work page 2014
-
[21]
Vaswani et al., Attention is all you need.Advances in Neural Information Processing Systems30(2017)
A. Vaswani et al., Attention is all you need.Advances in Neural Information Processing Systems30(2017)
work page 2017
-
[22]
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, BERT: pre-training of deep bidirectional transformers for language understanding.Proceedings of NAACL-HLT, 4171–4186 (2019)
work page 2019
-
[23]
Radford et al., Language models are unsupervised multitask learners.OpenAI Technical Report(2019)
A. Radford et al., Language models are unsupervised multitask learners.OpenAI Technical Report(2019)
work page 2019
-
[24]
T. B. Brown et al., Language models are few-shot learners.Advances in Neural Information Processing Systems 33, 1877–1901 (2020)
work page 1901
-
[25]
Scaling Laws for Neural Language Models
J. Kaplan et al., Scaling laws for neural language models.arXiv:2001.08361 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[26]
Training Compute-Optimal Large Language Models
J. Hoffmann et al., Training compute-optimal large language models.arXiv:2203.15556 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
S. Biderman et al., Pythia: a suite for analyzing large language models across training and scaling.Proceedings of the 40th International Conference on Machine Learning, 2397–2430 (2023)
work page 2023
-
[28]
A. Yang et al., Qwen2.5 Technical Report.arXiv:2412.15115 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
A. Yang et al., Qwen3 Technical Report.arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
T. Naselaris, K. N. Kay, S. Nishimoto, J. L. Gallant, Encoding and decoding in fMRI.NeuroImage56, 400–410 (2011)
work page 2011
- [31]
-
[32]
M. Stone, Cross-validatory choice and assessment of statistical predictions.Journal of the Royal Statistical Society: Series B36, 111–133 (1974)
work page 1974
-
[33]
N. Kriegeskorte, M. Mur, P. Bandettini, Representational similarity analysis: connecting the branches of systems neuroscience.Frontiers in Systems Neuroscience2, 4 (2008)
work page 2008
-
[34]
S. Kornblith, M. Norouzi, H. Lee, G. Hinton, Similarity of neural network representations revisited.Proceedings of the 36th International Conference on Machine Learning, 3519–3529 (2019)
work page 2019
-
[35]
L. Hoefling, M. Tangemann, L. Piefke, S. Keller, M. Bethge, K. Franke, Only Brains Align with Brains: cross-region alignment patterns expose limits of normative models.International Conference on Learning Representations (ICLR), poster. OpenReview:cMGJcHHI7d (2026)
work page 2026
-
[36]
J. Feather, M. Khosla, N. A. R. Murty, A. Nayebi, Brain-model evaluations need the NeuroAI Turing Test. arXiv:2502.16238 (2025)
-
[37]
C. F. Cadieu et al., Deep neural networks rival the representation of primate IT cortex for core visual object recognition.PLOS Computational Biology10, e1003963 (2014)
work page 2014
-
[38]
S.-M. Khaligh-Razavi, N. Kriegeskorte, Deep supervised, but not unsupervised, models may explain IT cortical representation.PLOS Computational Biology10, e1003915 (2014)
work page 2014
-
[39]
D. L. K. Yamins, J. J. DiCarlo, Using goal-driven deep learning models to understand sensory cortex.Nature Neuroscience19, 356–365 (2016). 13
work page 2016
-
[40]
A. J. E. Kell, D. L. K. Yamins, E. N. Shook, S. V. Norman-Haignere, J. H. McDermott, A task-optimized neural network replicates human auditory behavior, predicts brain responses, and reveals a cortical processing hierarchy. Neuron98, 630–644.e16 (2018)
work page 2018
-
[41]
B. A. Richards et al., A deep learning framework for neuroscience.Nature Neuroscience22, 1761–1770 (2019)
work page 2019
- [42]
-
[43]
S. A. Nastase et al., The “Narratives” fMRI dataset for evaluating models of naturalistic language comprehension. Scientific Data8, 250 (2021)
work page 2021
-
[44]
K. J. Gorgolewski et al., The brain imaging data structure, a format for organizing and describing outputs of neuroimaging experiments.Scientific Data3, 160044 (2016)
work page 2016
-
[45]
C. J. Markiewicz et al., The OpenNeuro resource for sharing of neuroscience data.eLife10, e71774 (2021)
work page 2021
-
[46]
Gramfort et al., MEG and EEG data analysis with MNE-Python.Frontiers in Neuroscience7, 267 (2013)
A. Gramfort et al., MEG and EEG data analysis with MNE-Python.Frontiers in Neuroscience7, 267 (2013)
work page 2013
-
[47]
R. A. Poldrack et al., Scanning the horizon: towards transparent and reproducible neuroimaging research.Nature Reviews Neuroscience18, 115–126 (2017)
work page 2017
-
[48]
A. E. Hoerl, R. W. Kennard, Ridge regression: biased estimation for nonorthogonal problems.Technometrics12, 55–67 (1970)
work page 1970
-
[49]
F. Pedregosa et al., Scikit-learn: machine learning in Python.Journal of Machine Learning Research12, 2825–2830 (2011)
work page 2011
- [50]
-
[51]
G. Varoquaux et al., Assessing and tuning brain decoders: cross-validation, caveats, and guidelines.NeuroImage 145, 166–179 (2017)
work page 2017
-
[52]
T. Yarkoni, J. Westfall, Choosing prediction over explanation in psychology: lessons from machine learning. Perspectives on Psychological Science12, 1100–1122 (2017)
work page 2017
-
[53]
N. Mantel, The detection of disease clustering and a generalized regression approach.Cancer Research27, 209–220 (1967)
work page 1967
-
[54]
J. V. Haxby et al., Distributed and overlapping representations of faces and objects in ventral temporal cortex. Science293, 2425–2430 (2001)
work page 2001
- [55]
-
[56]
A. Gretton, O. Bousquet, A. Smola, B. Schoelkopf, Measuring statistical dependence with Hilbert-Schmidt norms. Algorithmic Learning Theory, 63–77 (2005)
work page 2005
-
[57]
N. Kriegeskorte, W. K. Simmons, P. S. F. Bellgowan, C. I. Baker, Circular analysis in systems neuroscience: the dangers of double dipping.Nature Neuroscience12, 535–540 (2009)
work page 2009
- [58]
-
[59]
T. E. Nichols, A. P. Holmes, Nonparametric permutation tests for functional neuroimaging: a primer with examples.Human Brain Mapping15, 1–25 (2002)
work page 2002
-
[60]
Y. Benjamini, Y. Hochberg, Controlling the false discovery rate: a practical and powerful approach to multiple testing.Journal of the Royal Statistical Society: Series B57, 289–300 (1995). 14 Supplementary Information Supplementary Overview This Supplementary Information (SI) documents the implementation-faithful evidence map for the main L-PACT manuscrip...
work page 1995
-
[61]
Level 1, predictive adequacy: model-derived features must improve held-out neural prediction relative to nuisance baselines and the strongest available severe control
-
[62]
Level 2, relational adequacy: model-to-brain alignment profiles must reproduce brain-to-brain alignment profiles over a shared brain-unit order
-
[63]
Level 3, counterfactual mechanism-stripping adequacy: removing a candidate mechanism from model features must selectively damage prediction for matching neural targets more than for nonmatching targets within the implemented predictor
-
[64]
The locked analysis package reports a control-explained model outcome
Level 4, reliability-bounded adequacy: the surviving model evidence must be interpreted relative to brain-brain reliability or ceiling estimates. The locked analysis package reports a control-explained model outcome. The final decision table contains 146 integrated rows. All 146 rows are labelledcontrol_explained. No row passes the predictive, relational,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.