Recognition: no theorem link
Dual Hierarchical Dialogue Policy Learning for Legal Inquisitive Conversational Agents
Pith reviewed 2026-05-15 05:17 UTC · model grok-4.3
The pith
A dual hierarchical reinforcement learning method lets conversational agents proactively extract information by coordinating high-level strategy and low-level question generation in legal dialogues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that two cooperating reinforcement-learning agents, one managing high-level dialogue strategy and the other handling fine-grained utterance generation, can learn to emulate judicial questioning patterns, systematically uncover crucial information, and thereby achieve the agent's legal objectives in Supreme Court-style oral arguments.
What carries the argument
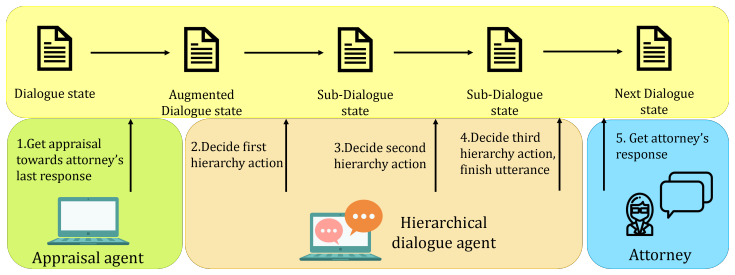
Dual Hierarchical Reinforcement Learning framework consisting of two cooperating RL agents that jointly learn dialogue-level policy and utterance-level generation.
If this is right
- The agents learn both when to initiate probing questions and how to word them to serve legal goals.
- Information extraction becomes more systematic than in standard user-driven dialogue systems.
- The same dual-agent structure can be applied to other high-stakes domains that require proactive questioning.
- Performance gains appear across multiple automatic metrics without additional human reward signals.
Where Pith is reading between the lines
- The framework could be tested in medical intake or investigative interviews where the agent must also drive information gathering.
- Removing the need for extra human feedback during training suggests the method may scale to additional specialized domains with only modest new data.
- Real-time interaction logs could be fed back to refine the learned policies after deployment.
Load-bearing premise
The U.S. Supreme Court dataset captures representative judicial questioning patterns and the dual RL agents can learn effective strategies without further human feedback or validation.
What would settle it
Run the trained agents on a fresh set of Supreme Court transcripts and check whether the generated questions fail to elicit the same categories of information that actual justices obtain or whether performance falls when either the high-level or low-level agent is removed.
Figures







read the original abstract
Most existing dialogue systems are user-driven, primarily designed to fulfill user requests. However, in many critical real-world scenarios, a conversational agent must proactively extract information to achieve its own objectives rather than merely respond. To address this gap, we introduce \emph{Inquisitive Conversational Agents (ICAs)} and develop an ICA specifically tailored to U.S. Supreme Court oral arguments. We propose a Dual Hierarchical Reinforcement Learning framework featuring two cooperating RL agents, each with its own policy, to coordinate strategic dialogue management and fine-grained utterance generation. By learning when and how to ask probing questions, the agent emulates judicial questioning patterns and systematically uncovers crucial information to fulfill its legal objectives. Evaluations on a U.S. Supreme Court dataset show that our method outperforms various baselines across multiple metrics. It represents an important first step toward broader high-stakes, domain-specific applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Inquisitive Conversational Agents (ICAs) tailored to U.S. Supreme Court oral arguments. It proposes a Dual Hierarchical Reinforcement Learning framework with two cooperating agents—one handling strategic dialogue management and the other managing fine-grained utterance generation—to proactively extract information by emulating judicial questioning patterns. The central claim is that this approach outperforms various baselines across multiple metrics on a U.S. Supreme Court dataset.
Significance. If the results hold with proper validation, the work could advance objective-driven dialogue systems for high-stakes legal domains by addressing coordination between high-level strategy and low-level generation. The dual-agent RL setup offers a structured way to pursue agent goals rather than purely respond to users, potentially informing broader applications in specialized conversational AI.
major comments (2)
- Abstract: The assertion that 'Evaluations on a U.S. Supreme Court dataset show that our method outperforms various baselines across multiple metrics' supplies no numerical results, baseline descriptions, error analysis, tables, or statistical tests. This absence is load-bearing for the central empirical claim and prevents verification of the dual hierarchical RL superiority.
- Evaluation section: The assessment relies solely on automatic metrics from the U.S. Supreme Court dataset without human expert validation or independent grounding of the reward function for legal objectives. This leaves unverified whether the learned policies align with actual judicial questioning patterns or merely optimize for fluency on an unrepresentative dataset.
minor comments (1)
- Abstract: The acronym ICA is defined on first use but the motivation for shifting from user-driven to objective-driven agents could be stated more explicitly in the opening sentence to improve accessibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We address each major comment point by point below and have revised the manuscript to strengthen the presentation of our empirical results and evaluation methodology.
read point-by-point responses
-
Referee: Abstract: The assertion that 'Evaluations on a U.S. Supreme Court dataset show that our method outperforms various baselines across multiple metrics' supplies no numerical results, baseline descriptions, error analysis, tables, or statistical tests. This absence is load-bearing for the central empirical claim and prevents verification of the dual hierarchical RL superiority.
Authors: We agree that the abstract would benefit from greater specificity to support the central claim. In the revised manuscript, we have updated the abstract to reference key quantitative improvements (e.g., higher task success rates and probing question quality scores relative to the listed baselines) and direct readers to the corresponding tables and statistical comparisons in the evaluation section. This change preserves the abstract's brevity while enabling verification of the reported superiority. revision: yes
-
Referee: Evaluation section: The assessment relies solely on automatic metrics from the U.S. Supreme Court dataset without human expert validation or independent grounding of the reward function for legal objectives. This leaves unverified whether the learned policies align with actual judicial questioning patterns or merely optimize for fluency on an unrepresentative dataset.
Authors: We acknowledge the value of human validation for high-stakes domains. Our evaluation follows standard practice in reinforcement learning for dialogue by using automatic metrics (task success, information extraction efficiency, and utterance quality) computed directly on the Supreme Court dataset. The reward function is explicitly derived from observed judicial objectives in the data, such as information gain per turn. We have revised the evaluation section to include a detailed derivation of the reward components, an expanded error analysis comparing learned policies to dataset patterns, and a limitations paragraph noting the absence of human expert studies as future work. We maintain that the dataset is representative of U.S. Supreme Court questioning, as it consists of real oral argument transcripts. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper describes a Dual Hierarchical Reinforcement Learning framework consisting of two cooperating agents for dialogue strategy and utterance generation, applied to a U.S. Supreme Court oral arguments dataset. No mathematical derivations, equations, or parameter-fitting steps are presented that reduce predictions or results to the inputs by construction. The central claims rest on standard RL training followed by empirical evaluation against baselines, with no self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations that collapse the argument. The approach is self-contained as an application of existing RL methods to a domain-specific task.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reinforcement learning policies can be learned to emulate judicial questioning strategies from transcript data
Reference graph
Works this paper leans on
-
[1]
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Chen, Weizhu , booktitle =. 2022 , url =
work page 2022
-
[2]
Tiancheng Zhao and Maxine Eskenazi , title =. Proceedings of the 17th Annual Meeting of the Special Interest Group on Discourse and Dialogue , year =
-
[3]
arXiv preprint arXiv:1810.00278 , year =
Paweł Budzianowski and Tsung-Hsien Wen and Bo-Hsiang Tseng and Iñigo Casanueva and Stefan Ultes and Osman Ramadan and Milica Gašić , title =. arXiv preprint arXiv:1810.00278 , year =
-
[4]
Matthew Henderson and Blaise Thomson and Jason Williams and Steve Young , title =. Proceedings of the 15th Annual Meeting of the Special Interest Group on Discourse and Dialogue , year =
-
[5]
Jiwei Li and Will Monroe and Alan Ritter and Michel Galley and Jianfeng Gao and Dan Jurafsky , title =. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
work page 2016
-
[6]
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics , year =
Baolin Peng and Xiujun Li and Jianfeng Gao and Jingjing Liu and Kam-Fai Wong and Shang-Yu Su , title =. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics , year =
-
[7]
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year =
Counterfactual Multi-Agent Policy Gradients , author =. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year =
-
[8]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[9]
and Whiteson, Shimon , booktitle =
Rashid, Tabish and Samvelyan, Mikayel and Schroeder de Witt, Christian and Farquhar, Gregory and Foerster, Jakob N. and Whiteson, Shimon , booktitle =. 2018 , publisher =
work page 2018
-
[10]
Henderson, Matthew and Thomson, Blaise and Williams, Jason D. , editor =. The Second Dialog State Tracking Challenge , url =. Proceedings of the 15th Annual Meeting of the Special Interest Group on Discourse and Dialogue (. doi:10.3115/v1/W14-4337 , eventtitle =
-
[11]
Henderson, Matthew and Thomson, Blaise and Williams, Jason D. , urldate =. The third Dialog State Tracking Challenge , isbn =. 2014. doi:10.1109/SLT.2014.7078595 , eventtitle =
-
[12]
The Dialog State Tracking Challenge , url =
Williams, Jason and Raux, Antoine and Ramachandran, Deepak and Black, Alan , editor =. The Dialog State Tracking Challenge , url =. Proceedings of the
-
[13]
Towards Scalable Multi-domain Conversational Agents: The Schema-Guided Dialogue Dataset , rights =
Rastogi, Abhinav and Zang, Xiaoxue and Sunkara, Srinivas and Gupta, Raghav and Khaitan, Pranav , urldate =. Towards Scalable Multi-domain Conversational Agents: The Schema-Guided Dialogue Dataset , rights =. doi:10.48550/ARXIV.1909.05855 , shorttitle =
-
[14]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Ganguli, Deep and Lovitt, Liane and Kernion, Jackson and Askell, Amanda and Bai, Yuntao and Kadavath, Saurav and Mann, Ben and Perez, Ethan and Schiefer, Nicholas and Ndousse, Kamal and Jones, Andy and Bowman, Sam and Chen, Anna and Conerly, Tom and. Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned , rights =. d...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2209.07858
-
[15]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Yuntao and Jones, Andy and Ndousse, Kamal and Askell, Amanda and Chen, Anna and. Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback , rights =. doi:10.48550/ARXIV.2204.05862 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.05862
-
[16]
Proactive Conversational Agents in the Post-
Liao, Lizi and Yang, Grace Hui and Shah, Chirag , urldate =. Proactive Conversational Agents in the Post-. Proceedings of the 46th International. doi:10.1145/3539618.3594250 , eventtitle =
-
[17]
Andrew and Abbeel, Pieter and Peters, Jan , urldate =
Osa, Takayuki and Pajarinen, Joni and Neumann, Gerhard and Bagnell, J. Andrew and Abbeel, Pieter and Peters, Jan , urldate =. An Algorithmic Perspective on Imitation Learning , volume =. doi:10.1561/2300000053 , pages =
-
[18]
Inquisitive mind: a conversational news companion , isbn =
Dubiel, Mateusz and Cervone, Alessandra and Riccardi, Giuseppe , urldate =. Inquisitive mind: a conversational news companion , isbn =. Proceedings of the 1st International Conference on Conversational User Interfaces , publisher =. doi:10.1145/3342775.3342802 , shorttitle =
-
[19]
Key-Value Retrieval Networks for Task-Oriented Dialogue
Eric, Mihail and Manning, Christopher D. , urldate =. Key-Value Retrieval Networks for Task-Oriented Dialogue , rights =. doi:10.48550/ARXIV.1705.05414 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1705.05414
-
[20]
A Network-based End-to-End Trainable Task-oriented Dialogue System
Wen, Tsung-Hsien and Vandyke, David and Mrksic, Nikola and Gasic, Milica and Rojas-Barahona, Lina M. and Su, Pei-Hao and Ultes, Stefan and Young, Steve , urldate =. A Network-based End-to-End Trainable Task-oriented Dialogue System , rights =. doi:10.48550/ARXIV.1604.04562 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1604.04562
-
[21]
arXiv preprint arXiv:1810.00278 , year =
Budzianowski, Paweł and Wen, Tsung-Hsien and Tseng, Bo-Hsiang and Casanueva, Iñigo and Ultes, Stefan and Ramadan, Osman and Gašić, Milica , urldate =. doi:10.48550/ARXIV.1810.00278 , abstract =
-
[22]
doi:10.48550/ARXIV.2401.01330 , shorttitle =
Aliannejadi, Mohammad and Abbasiantaeb, Zahra and Chatterjee, Shubham and Dalton, Jeffery and Azzopardi, Leif , urldate =. doi:10.48550/ARXIV.2401.01330 , shorttitle =
-
[23]
The. Speech and Natural Language: Proceedings of a Workshop Held at Hidden Valley, Pennsylvania, June 24-27,1990 , author =
work page 1990
-
[24]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: A Family of Highly Capable Multimodal Models , rights =. doi:10.48550/ARXIV.2312.11805 , shorttitle =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.11805
-
[25]
LLaMA: Open and Efficient Foundation Language Models
Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timothée and Rozière, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and Rodriguez, Aurelien and Joulin, Armand and Grave, Edouard and Lample, Guillaume , urldate =. doi:10.48550/ARXIV.2302.13971 , shorttitle =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971
-
[26]
doi:10.48550/ARXIV.2303.08774 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774
-
[27]
doi:10.48550/ARXIV.2304.12026 , shorttitle =
Zhan, Haolan and Li, Zhuang and Wang, Yufei and Luo, Linhao and Feng, Tao and Kang, Xiaoxi and Hua, Yuncheng and Qu, Lizhen and Soon, Lay-Ki and Sharma, Suraj and Zukerman, Ingrid and Semnani-Azad, Zhaleh and Haffari, Gholamreza , urldate =. doi:10.48550/ARXIV.2304.12026 , shorttitle =
-
[28]
ParlAI: A Dialog Research Software Platform
Miller, Alexander H. and Feng, Will and Fisch, Adam and Lu, Jiasen and Batra, Dhruv and Bordes, Antoine and Parikh, Devi and Weston, Jason , urldate =. doi:10.48550/ARXIV.1705.06476 , shorttitle =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1705.06476
-
[29]
Journal of Public Health , author =
Barriers and facilitators of childhood flu vaccination: the views of parents in. Journal of Public Health , author =. 2022 , pages =. doi:10.1007/s10389-022-01695-2 , abstract =
-
[30]
Price, Timothy James , month = mar, year =. Interview. doi:10.25405/data.ncl.14242040.v1 , urldate =
-
[31]
Lachman, Henry , year =. Interview. doi:10.7910/DVN/GDUOVS , urldate =
-
[32]
Taherzadeh, Oliver , year =. Interview. doi:10.7910/DVN/4C9KFK , urldate =
-
[33]
Interviews with 10 change leaders leading organizational change , url =
Sadaric, Antonio , year =. Interviews with 10 change leaders leading organizational change , url =. doi:10.7910/DVN/7JYGTG , urldate =
-
[34]
Tay, Hui Yong , year =. Replication. doi:10.7910/DVN/9X85KL , urldate =
-
[35]
Routledge Open Research , author =. 2024 , pages =. doi:10.12688/routledgeopenres.18443.1 , abstract =
-
[36]
doi:10.7910/DVN/WZ0BU5 , urldate =
Girard, Amy , year =. doi:10.7910/DVN/WZ0BU5 , urldate =
-
[37]
Watkins, David , year =. Healthworker. doi:10.7910/DVN/CYRR9O , urldate =
- [38]
-
[39]
doi:10.48550/ARXIV.2412.10424 , shorttitle =
Kim, Eunsu and Suk, Juyoung and Kim, Seungone and Muennighoff, Niklas and Kim, Dongkwan and Oh, Alice , urldate =. doi:10.48550/ARXIV.2412.10424 , shorttitle =
-
[40]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , urldate =. Judging. doi:10.48550/ARXIV.2306.05685 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.05685
-
[41]
CoQA: A Conversational Question Answering Challenge
Reddy, Siva and Chen, Danqi and Manning, Christopher D. , year =. doi:10.48550/ARXIV.1808.07042 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1808.07042
-
[42]
Better Zero-Shot Reasoning with Role-Play Prompting , rights =
Kong, Aobo and Zhao, Shiwan and Chen, Hao and Li, Qicheng and Qin, Yong and Sun, Ruiqi and Zhou, Xin and Wang, Enzhi and Dong, Xiaohang , urldate =. Better Zero-Shot Reasoning with Role-Play Prompting , rights =. doi:10.48550/ARXIV.2308.07702 , abstract =
-
[43]
Transformers: State-of-the-Art Natural Language Processing
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Tim and Louf, Remi and Funtowicz, Morgan and Davison, Joe and Shleifer, Sam and Von Platen, Patrick and Ma, Clara and Jernite, Yacine and Plu, Julien and Xu, Canwen and Le Scao, Teven and Gugger, Sylvain and Drame, M...
-
[44]
Fitzpatrick, Kathleen Kara and Darcy, Alison and Vierhile, Molly , urldate =. Delivering Cognitive Behavior Therapy to Young Adults With Symptoms of Depression and Anxiety Using a Fully Automated Conversational Agent (Woebot): A Randomized Controlled Trial , volume =. doi:10.2196/mental.7785 , shorttitle =
-
[45]
QuAC : Question Answering in Context
Choi, Eunsol and He, He and Iyyer, Mohit and Yatskar, Mark and Yih, Wen-tau and Choi, Yejin and Liang, Percy and Zettlemoyer, Luke , urldate =. doi:10.48550/arXiv.1808.07036 , shorttitle =. 1808.07036 , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1808.07036
-
[46]
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
Bajaj, Payal and Campos, Daniel and Craswell, Nick and Deng, Li and Gao, Jianfeng and Liu, Xiaodong and Majumder, Rangan and. doi:10.48550/arXiv.1611.09268 , shorttitle =. 1611.09268 , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1611.09268
-
[47]
Mulla, Nikahat and Gharpure, Prachi , urldate =. Automatic question generation: a review of methodologies, datasets, evaluation metrics, and applications , volume =. doi:10.1007/s13748-023-00295-9 , shorttitle =
-
[48]
CHAI: A CHatbot AI for Task-Oriented Dialogue with Offline Reinforcement Learning , author=. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , year=
work page 2022
-
[49]
A ir C oncierge: Generating Task-Oriented Dialogue via Efficient Large-Scale Knowledge Retrieval
Chen, Chieh-Yang and Wang, Pei-Hsin and Chang, Shih-Chieh and Juan, Da-Cheng and Wei, Wei and Pan, Jia-Yu. A ir C oncierge: Generating Task-Oriented Dialogue via Efficient Large-Scale Knowledge Retrieval. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.79
-
[50]
Neural Approaches to Conversational AI
Gao, Jianfeng and Galley, Michel and Li, Lihong. Neural Approaches to Conversational AI. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts. 2018. doi:10.18653/v1/P18-5002
-
[51]
Su, Pei-Hao and Vandyke, David and Gaši´c, Milica and Kim, Dongho and Mrkši´c, Nikola and Wen, Tsung Hsien and Young, Steve , year =. Learning from Real Users: Rating Dialogue Success with Neural Networks for Reinforcement Learning in Spoken Dialogue Systems , doi =
-
[52]
Young, Steve and Gašić, Milica and Thomson, Blaise and Williams, Jason D. , journal=. POMDP-Based Statistical Spoken Dialog Systems: A Review , year=
-
[53]
Book Reviews: Spoken Natural Language Dialogue Systems: A Practical Approach
Traum, David R. Book Reviews: Spoken Natural Language Dialogue Systems: A Practical Approach. Computational Linguistics. 1996
work page 1996
-
[54]
Zero-Shot Transfer Learning with Synthesized Data for Multi-Domain Dialogue State Tracking
Campagna, Giovanni and Foryciarz, Agata and Moradshahi, Mehrad and Lam, Monica. Zero-Shot Transfer Learning with Synthesized Data for Multi-Domain Dialogue State Tracking. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.12
-
[55]
A Simple Language Model for Task-Oriented Dialogue , url =
Hosseini-Asl, Ehsan and McCann, Bryan and Wu, Chien-Sheng and Yavuz, Semih and Socher, Richard , booktitle =. A Simple Language Model for Task-Oriented Dialogue , url =
-
[56]
Vinyals, Oriol and Le, Quoc , keywords =. A Neural Conversational Model , publisher =. 2015 , copyright =. doi:10.48550/ARXIV.1506.05869 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1506.05869 2015
-
[57]
Moon, Seungwhan and Shah, Pararth and Kumar, Anuj and Subba, Rajen. O pen D ial KG : Explainable Conversational Reasoning with Attention-based Walks over Knowledge Graphs. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1081
-
[58]
Augmenting End-to-End Dialog Systems with Commonsense Knowledge
Young, Tom and Cambria, Erik and Chaturvedi, Iti and Huang, Minlie and Zhou, Hao and Biswas, Subham , keywords =. Augmenting End-to-End Dialog Systems with Commonsense Knowledge , publisher =. 2017 , copyright =. doi:10.48550/ARXIV.1709.05453 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1709.05453 2017
-
[59]
M em2 S eq: Effectively Incorporating Knowledge Bases into End-to-End Task-Oriented Dialog Systems
Madotto, Andrea and Wu, Chien-Sheng and Fung, Pascale. M em2 S eq: Effectively Incorporating Knowledge Bases into End-to-End Task-Oriented Dialog Systems. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1136
-
[60]
Learning Knowledge Bases with Parameters for Task-Oriented Dialogue Systems
Madotto, Andrea and Cahyawijaya, Samuel and Winata, Genta Indra and Xu, Yan and Liu, Zihan and Lin, Zhaojiang and Fung, Pascale. Learning Knowledge Bases with Parameters for Task-Oriented Dialogue Systems. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.215
-
[61]
Aliannejadi, Mohammad and Zamani, Hamed and Crestani, Fabio and Croft, W. Bruce , title =. Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2019 , isbn =. doi:10.1145/3331184.3331265 , abstract =
-
[62]
Yu, Shi and Liu, Jiahua and Yang, Jingqin and Xiong, Chenyan and Bennett, Paul and Gao, Jianfeng and Liu, Zhiyuan , title =. Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2020 , isbn =. doi:10.1145/3397271.3401323 , abstract =
-
[63]
Bruce and Iyyer, Mohit , title =
Qu, Chen and Yang, Liu and Chen, Cen and Qiu, Minghui and Croft, W. Bruce and Iyyer, Mohit , title =. Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2020 , isbn =. doi:10.1145/3397271.3401110 , abstract =
-
[64]
Controlling the Risk of Conversational Search via Reinforcement Learning , publisher =
Wang, Zhenduo and Ai, Qingyao , keywords =. Controlling the Risk of Conversational Search via Reinforcement Learning , publisher =. 2021 , copyright =. doi:10.48550/ARXIV.2101.06327 , url =
-
[65]
Zhang, Yichi and Ou, Zhijian and Yu, Zhou , keywords =. Task-Oriented Dialog Systems that Consider Multiple Appropriate Responses under the Same Context , publisher =. 2019 , copyright =. doi:10.48550/ARXIV.1911.10484 , url =
-
[66]
Modelling Hierarchical Structure between Dialogue Policy and Natural Language Generator with Option Framework for Task-oriented Dialogue System , author=. ArXiv , year=
-
[67]
Rethinking action spaces for reinforcement learning in end-to-end dialog agents with latent variable models , author=. arXiv preprint arXiv:1902.08858 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[68]
A Sequence-to-Sequence Model for User Simulation in Spoken Dialogue Systems
Asri, Layla El and He, Jing and Suleman, Kaheer , keywords =. A Sequence-to-Sequence Model for User Simulation in Spoken Dialogue Systems , publisher =. 2016 , copyright =. doi:10.48550/ARXIV.1607.00070 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1607.00070 2016
-
[69]
High-Quality Diversification for Task-Oriented Dialogue Systems , publisher =
Tang, Zhiwen and Kulkarni, Hrishikesh and Yang, Grace Hui , keywords =. High-Quality Diversification for Task-Oriented Dialogue Systems , publisher =. 2021 , copyright =. doi:10.48550/ARXIV.2106.00891 , url =
-
[70]
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
- [71]
-
[72]
Mnih, Volodymyr and Kavukcuoglu, Koray and Silver, David and Graves, Alex and Antonoglou, Ioannis and Wierstra, Daan and Riedmiller, Martin , year =
-
[73]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Deep Reinforcement Learning with Double Q-Learning , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2016 , month=. doi:10.1609/aaai.v30i1.10295 , abstractNote=
-
[74]
GitHub repository , howpublished =
Dhariwal, Prafulla and Hesse, Christopher and Klimov, Oleg and Nichol, Alex and Plappert, Matthias and Radford, Alec and Schulman, John and Sidor, Szymon and Wu, Yuhuai and Zhokhov, Peter , title =. GitHub repository , howpublished =. 2017 , publisher =
work page 2017
-
[75]
Decoupling Strategy and Generation in Negotiation Dialogues
He, He and Chen, Derek and Balakrishnan, Anusha and Liang, Percy. Decoupling Strategy and Generation in Negotiation Dialogues. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1256
-
[76]
Polikar, Robi. Ensemble Learning. Ensemble Machine Learning: Methods and Applications. 2012. doi:10.1007/978-1-4419-9326-7_1
-
[77]
Proceedings of the 38th International Conference on Machine Learning , pages =
SUNRISE: A Simple Unified Framework for Ensemble Learning in Deep Reinforcement Learning , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
work page 2021
-
[78]
and van Hasselt, Hado , journal=
Wiering, Marco A. and van Hasselt, Hado , journal=. Ensemble Algorithms in Reinforcement Learning , year=
-
[79]
Croft, Bruce and Metzler, Donald and Strohman, Trevor , title =. 2009 , isbn =
work page 2009
-
[80]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, Nils and Gurevych, Iryna , keywords =. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks , publisher =. 2019 , copyright =. doi:10.48550/ARXIV.1908.10084 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1908.10084 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.