Recognition: no theorem link
Know When To Fold 'Em: Token-Efficient LLM Synthetic Data Generation via Multi-Stage In-Flight Rejection
Pith reviewed 2026-05-15 05:00 UTC · model grok-4.3
The pith
MSIFR cuts token use in LLM synthetic data generation by 11-77% through early rejection of faulty outputs at intermediate stages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
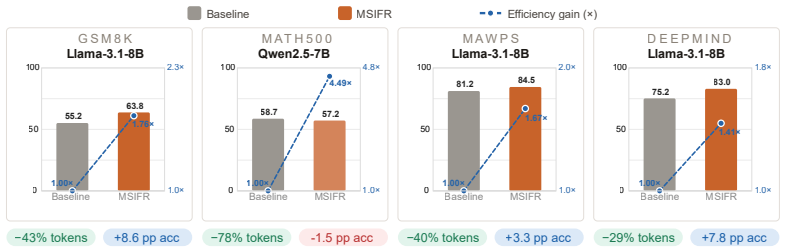
By decomposing the generation into sequential stages and applying fast rule-based validators for issues like arithmetic inconsistencies, hallucination patterns, and formatting violations, low-quality trajectories can be terminated before completion. This in-flight rejection is formalized as a sequential decision process where any non-trivial discard policy reduces expected token consumption, and conditional utility estimates form a martingale that preserves the expected utility of retained samples. Experiments across five models and seven benchmarks confirm token reductions of 11-77% standalone or up to 78.2% combined with early-exit, with accuracy preserved or improved.
What carries the argument
Multi-Stage In-Flight Rejection (MSIFR): a framework that inserts rule-based validators at intermediate generation checkpoints to identify and terminate faulty output trajectories early.
Load-bearing premise
The rule-based validators must correctly identify low-quality trajectories early enough to save tokens without wrongly discarding too many high-quality ones.
What would settle it
Measuring the accuracy of retained samples after applying MSIFR and finding it lower than full-generation filtering would disprove the no-bias claim, or observing no token savings if most rejections occur only at the final stage.
Figures



read the original abstract
While synthetic data generation with large language models (LLMs) is widely used in post-training pipelines, existing approaches typically generate full outputs before applying quality filters, leading to substantial token waste on samples that are ultimately discarded. To address this, we propose Multi-Stage In-Flight Rejection (MSIFR), a lightweight, training-free framework that detects and terminates low-quality generation trajectories at intermediate checkpoints before they reach full completion. MSIFR decomposes the generation process into sequential stages and applies fast rule-based validators to identify arithmetic inconsistencies, hallucination patterns, and formatting violations, enabling early rejection of faulty samples. We formalize in-flight rejection as a sequential decision process and show that any non-trivial discard policy reduces expected token consumption, with stage-wise savings increasing when rejection occurs earlier in the generation pipeline. We further demonstrate that conditional utility estimates form a martingale, ensuring that early, in-flight rejection does not bias the expected utility of retained samples. Across five instruction-tuned models and seven reasoning benchmarks, MSIFR reduces token consumption by 11%-77% as a standalone method, and up to 78.2% when combined with early-exit methods, while preserving or improving evaluation accuracy. These results confirm that MSIFR provides a practical mechanism for improving the efficiency of LLM-based synthetic data generation without additional training or architectural changes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Multi-Stage In-Flight Rejection (MSIFR), a training-free framework that decomposes LLM generation into sequential stages and applies fast rule-based validators (for arithmetic inconsistencies, hallucination patterns, and formatting) to terminate low-quality trajectories early. It formalizes in-flight rejection as a sequential decision process, claims that any non-trivial discard policy reduces expected token consumption with greater savings from earlier rejection, and shows that conditional utility estimates form a martingale ensuring early rejection does not bias the expected utility of retained samples. Empirically, across five instruction-tuned models and seven reasoning benchmarks, MSIFR achieves 11%-77% token reduction as a standalone method and up to 78.2% when combined with early-exit techniques while preserving or improving accuracy.
Significance. If the martingale property and validator reliability hold, MSIFR provides a practical, zero-training mechanism to cut token waste in LLM synthetic data pipelines, which is significant for scaling post-training data generation where full-trajectory filtering is costly. The combination with early-exit methods and the parameter-free nature of the token-saving argument (derived directly from the sequential process) strengthen its potential impact.
major comments (3)
- [Abstract / theoretical formalization] Abstract and theoretical section: the martingale claim for conditional utility is presented as grounding for unbiasedness, but the abstract provides no derivation details or explicit statement of the filtration and stopping time; without these, it is impossible to verify whether the rejection decision preserves the martingale property when validators are heuristic rather than exact.
- [Empirical results] Empirical evaluation: the reported 11%-77% token reductions and accuracy preservation rest on the unverified assumption that rule-based validators (especially for 'hallucination patterns') have low false-negative rates on low-quality trajectories; the paper evaluates only on reasoning benchmarks where such rules are easiest to write, so the results do not demonstrate generalizability to broader synthetic data tasks.
- [Empirical results] Empirical evaluation: no error bars, confidence intervals, or statistical tests are mentioned for the token-consumption or accuracy figures, and data exclusion rules for failed generations are not specified, undermining the claim that accuracy is preserved or improved.
minor comments (1)
- [Abstract] Abstract: the 11%-77% range would be more informative if accompanied by per-model or per-benchmark breakdowns rather than an aggregate interval.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract / theoretical formalization] Abstract and theoretical section: the martingale claim for conditional utility is presented as grounding for unbiasedness, but the abstract provides no derivation details or explicit statement of the filtration and stopping time; without these, it is impossible to verify whether the rejection decision preserves the martingale property when validators are heuristic rather than exact.
Authors: We agree that the abstract is too concise and omits key formal elements. In the revision we will expand the abstract to explicitly name the filtration (generated by partial token sequences up to each stage), the stopping time (first stage at which a validator rejects), and the martingale property of the conditional expected utility process. The full derivation already appears in Section 3; we will add a short clarifying paragraph noting that the martingale holds under the assumption that validators produce unbiased estimates of utility conditional on the observed prefix. For purely heuristic validators we will explicitly state the additional assumption required and discuss its implications. revision: partial
-
Referee: [Empirical results] Empirical evaluation: the reported 11%-77% token reductions and accuracy preservation rest on the unverified assumption that rule-based validators (especially for 'hallucination patterns') have low false-negative rates on low-quality trajectories; the paper evaluates only on reasoning benchmarks where such rules are easiest to write, so the results do not demonstrate generalizability to broader synthetic data tasks.
Authors: The experiments are deliberately restricted to reasoning benchmarks precisely because these domains admit reliable, low-cost rule-based validators; we will add an explicit limitations paragraph stating that extension to open-ended generation tasks requires task-specific validators whose reliability must be validated separately. To address the false-negative concern we will report empirical false-negative rates on a manually annotated subset of trajectories and include a short sensitivity analysis showing how token savings degrade under higher false-negative rates. revision: partial
-
Referee: [Empirical results] Empirical evaluation: no error bars, confidence intervals, or statistical tests are mentioned for the token-consumption or accuracy figures, and data exclusion rules for failed generations are not specified, undermining the claim that accuracy is preserved or improved.
Authors: We will revise all tables and figures to include 95% confidence intervals and error bars computed over the full set of runs. We will add paired statistical tests (t-tests and Wilcoxon signed-rank) for accuracy and token-consumption differences versus baselines. The experimental section will be expanded with a precise description of data-exclusion criteria (e.g., generations that exceed the maximum token limit or produce unparseable output are excluded from both accuracy and token counts). revision: yes
Circularity Check
Minor self-definitional elements in theoretical claims; empirical results independent
specific steps
-
self definitional
[Abstract (formalization paragraph)]
"We formalize in-flight rejection as a sequential decision process and show that any non-trivial discard policy reduces expected token consumption, with stage-wise savings increasing when rejection occurs earlier in the generation pipeline."
The claimed reduction follows immediately from the definition: terminating generation at an intermediate stage by construction avoids generating the remaining tokens, so the 'show that' statement is tautological rather than an independent derivation from the model.
-
self definitional
[Abstract (martingale paragraph)]
"We further demonstrate that conditional utility estimates form a martingale, ensuring that early, in-flight rejection does not bias the expected utility of retained samples."
Conditional utility is defined as the expected final utility given the current partial trajectory; the martingale property then holds by the tower law of conditional expectation, making the demonstration equivalent to the definition rather than a separate result.
full rationale
The paper's formalization shows token reduction for any early rejection by construction of the sequential process, and the martingale property follows directly from defining conditional utility via expectation. These are definitional rather than derived predictions. However, the reported 11-77% token savings and accuracy preservation come from direct experiments across models and benchmarks, with no fitted parameters, self-citation chains, or renamings of known results as new derivations. The central efficiency claim does not reduce to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Conditional utility estimates form a martingale
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2501.12345 , year=
Qwen2.5 Technical Report , author=. arXiv preprint arXiv:2501.12345 , year=
-
[2]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
- [3]
- [4]
-
[5]
Algorithmic Learning in a Random World , author=. 2005 , publisher=
work page 2005
-
[7]
arXiv preprint arXiv:2508.15260 , year=
Deep Think with Confidence , author=. arXiv preprint arXiv:2508.15260 , year=
-
[8]
The Llama 3 Herd of Models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
DeepSeek-LLM: Scaling Open-Source Language Models with Longtermism , author=. arXiv preprint arXiv:2401.02954 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone , author=. arXiv preprint arXiv:2404.14219 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Training Verifiers to Solve Math Word Problems
GSM8K: 8.5K High Quality Linguistically Diverse Grade School Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Measuring Mathematical Problem Solving With the MATH Dataset
MATH: Measuring Mathematical Problem Solving , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Measuring Massive Multitask Language Understanding
Measuring Massive Multitask Language Understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[15]
arXiv preprint arXiv:2112.01599 , year=
SVAMP: Solving Varied Arithmetic Word Problems with Missing Quantities , author=. arXiv preprint arXiv:2112.01599 , year=
-
[16]
arXiv preprint arXiv:1606.07141 , year=
MAWPS: A Math Word Problem Repository , author=. arXiv preprint arXiv:1606.07141 , year=
-
[17]
MathQA: Towards Interpretable Math Word Problem Solving with Operation-Based Formalisms
MathQA: Towards Interpretable Math Word Problem Solving with Operation-Based Formalisms , author=. arXiv preprint arXiv:1905.13319 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[18]
Analysing Mathematical Reasoning Abilities of Neural Models
Analysing Mathematical Reasoning Abilities of Neural Models , author=. arXiv preprint arXiv:1904.01557 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[19]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. arXiv preprint arXiv:2306.05685 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[21]
Falcon-40B: An Open-Source Language Model with State-of-the-Art Performance , author=. arXiv preprint arXiv:2306.01116 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Qwen Technical Report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
GPT-4 Technical Report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Synthesizing Post-Training Data for LLMs through Multi-Agent Simulation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2025 , address=. doi:10.18653/v1/2025.acl-long.1136 , url=
-
[25]
arXiv preprint arXiv:2410.14251 , year=
Synthesizing Post-Training Data for LLMs through Multi-Agent Simulation , author=. arXiv preprint arXiv:2410.14251 , year=
-
[26]
arXiv preprint arXiv:2502.13313 , year=
Revisiting Privacy, Utility, and Efficiency Trade-offs when Fine-tuning Large Language Models , author=. arXiv preprint arXiv:2502.13313 , year=
-
[27]
Journal of Information Systems Engineering and Management , year=
Does Synthetic Data Generalize? A Comparative Study of Synthetic and Real Datasets for Reinforcement Fine-Tuning of Domain-Specific LLMs , author=. Journal of Information Systems Engineering and Management , year=
-
[28]
Synthetic Data Generation Using Large Language Models: Advances in Text and Code , author=. IEEE Access , volume=. 2025 , doi=
work page 2025
-
[29]
arXiv preprint arXiv:2405.10040 , year=
SynthesizRR: Generating Diverse Datasets with Retrieval Augmentation , author=. arXiv preprint arXiv:2405.10040 , year=
-
[30]
A Novel Llama 3-Based Prompt Engineering Platform for Textual Data Generation and Labeling , author=. Electronics , volume=. 2025 , doi=
work page 2025
-
[31]
LYNX: Learning Dynamic Exits for Confidence-Controlled Reasoning , author=. NeurIPS , year=
-
[32]
S-GRPO: Early Exit via Reinforcement Learning in Reasoning Models , author=. NeurIPS , year=
-
[33]
TERMINATOR: Learning Optimal Stopping Points for Chain-of-Thought Reasoning , author=. ICML , year=
-
[34]
HALT-CoT: Model-Agnostic Early Stopping for Chain-of-Thought Reasoning via Answer Entropy , author=. ICML , year=
-
[35]
ThinkLess: A Training-Free Inference-Efficient Method for Reducing Reasoning Redundancy , author=. NeurIPS , year=
-
[36]
The Detection--Extraction Gap: Models Know the Answer Before They Can Say It , author=. ICLR , year=
-
[37]
Prune 'n Predict: Optimizing LLM Decision-making with Conformal Prediction , author=. ICML , year=
-
[38]
Knowing When to Quit: A Principled Framework for Dynamic Abstention in LLM Reasoning , author=. ICML , year=
- [39]
-
[40]
Abstain-R1: Calibrated Abstention and Post-Refusal Clarification via Verifiable RL , author=. ACL , year=
-
[41]
Conformal Prediction Beyond the Seen: A Missing Mass Perspective for Uncertainty Quantification in Generative Models , author=. NeurIPS , year=
-
[42]
arXiv preprint arXiv:2504.15895 , year=
Dynamic Early Exit in Reasoning Models , author=. arXiv preprint arXiv:2504.15895 , year=
-
[43]
arXiv preprint arXiv:2505.18237 , year=
Think or Not? Exploring Thinking Efficiency in Large Reasoning Models via an Information-Theoretic Lens , author=. arXiv preprint arXiv:2505.18237 , year=
-
[44]
arXiv preprint arXiv:2505.13949 , year=
FlashThink: An Early Exit Method for Efficient Reasoning , author=. arXiv preprint arXiv:2505.13949 , year=
-
[45]
Journal of Machine Learning Research , volume=
A tutorial on conformal prediction , author=. Journal of Machine Learning Research , volume=
-
[46]
A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification
A gentle introduction to conformal prediction and distribution-free uncertainty quantification , author=. arXiv preprint arXiv:2107.07511 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
International Conference on Learning Representations , year=
Conformal language modeling , author=. International Conference on Learning Representations , year=
-
[48]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[49]
International Conference on Machine Learning , pages=
Sequence tutor: Conservative fine-tuning of sequence generation models with kl-control , author=. International Conference on Machine Learning , pages=. 2017 , organization=
work page 2017
-
[50]
Fine-Tuning Language Models from Human Preferences
Fine-tuning language models from human preferences , author=. arXiv preprint arXiv:1909.08593 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.