Recognition: no theorem link
Real-Time Group Dynamics with LLM Facilitation: Evidence from a Charity Allocation Task
Pith reviewed 2026-05-15 01:47 UTC · model grok-4.3
The pith
LLM facilitators in group charity tasks shift specific donation shares by up to 5.5 points without raising overall consensus or participation equity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
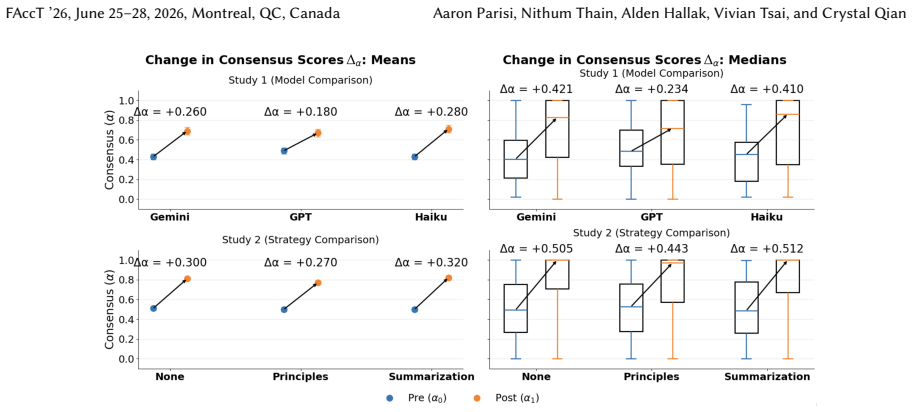
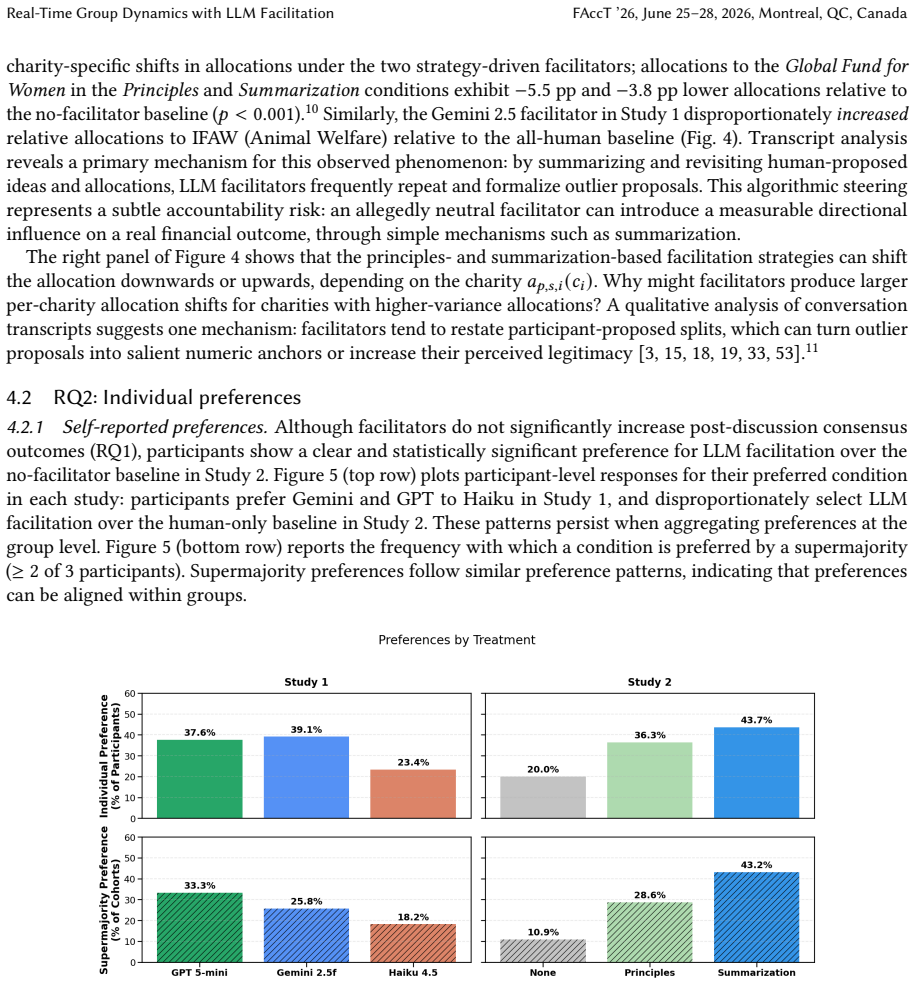
In two studies totaling 879 participants who allocated real donation budgets in groups of three, LLM facilitation across frontier models and strategies produced no significant rise in group consensus compared with no-facilitation baselines. Participants nevertheless preferred facilitated sessions and cited inclusivity as the main reason. Facilitators altered select charity-level shares by as much as 5.5 percentage points, directly affecting payouts, while neither survey responses nor transcript analysis detected improvements in participation equity. Reported trust in the process was higher in the very conditions where steering occurred.
What carries the argument
The incentive-compatible charity allocation task, in which groups divide a fixed budget across charities under text-only chat with or without LLM facilitation, with outcomes tracked through consensus scores, per-charity allocation shifts, survey and transcript equity measures, and post-task preference ratings.
If this is right
- Facilitators can change final charitable payouts even when aggregate agreement metrics remain flat.
- Perceived inclusivity can rise without any corresponding increase in measured participation equity.
- Trust in the deliberation process can increase under conditions where directional influence on outcomes is present.
- Governance evaluation of AI-mediated groups must track collective outcomes, interaction patterns, and subjective perceptions as separate targets.
Where Pith is reading between the lines
- Similar steering could occur in other high-stakes text-based deliberations such as workplace budgeting or community planning.
- Designers might add explicit limits on directional suggestions to reduce unintended allocation shifts while retaining facilitation benefits.
- Testing voice or video interfaces could reveal whether the gap between perceived and actual equity shrinks outside text chat.
Load-bearing premise
The specific charity allocation task with real financial stakes and text-only chat generalizes to other group deliberation settings and the chosen metrics fully capture steering and equity effects.
What would settle it
A replication using a different real-stakes group task, such as ranking policy options, in which LLM facilitation produces neither allocation shifts nor higher preference ratings would falsify the steering and preference findings.
Figures







read the original abstract
As large language models (LLMs) evolve from single-user assistants to active participants in civic and workplace deliberation, evaluating their effects on collective decision making becomes a governance challenge. We present two empirical studies (N=879) of real-time, text-based group deliberation in an incentive-compatible charity allocation task with real financial stakes ($7,200 USD). Groups of three allocate a donation budget under varying LLM facilitation conditions: Study 1 (N=204) compares three frontier models; Study 2 (N=675) compares facilitator strategies against a no-facilitation baseline. Across both studies, LLM facilitation did not significantly improve group consensus in either study, yet participants consistently preferred facilitated discussion. We additionally identify two governance-relevant risks. First, algorithmic steering: facilitators shifted select charity-level allocations by up to 5.5 percentage points -- directly affecting the final charitable payout -- even when aggregate agreement metrics remained unchanged. Second, an illusion of inclusion: participants cited inclusivity as their primary reason for preferring LLM facilitators, yet neither survey nor transcript-based measures of participation equity improved. Notably, participants reported greater trust in the process under the same conditions where facilitators exerted directional influence on outcomes. Together, these findings show that in AI-mediated group deliberation, perceived procedural improvement can coexist with measurable steering and unchanged participation inequality, motivating evaluation practices that treat collective outcomes, interaction dynamics, and participant perceptions as distinct governance targets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents two empirical studies (total N=879) on real-time, text-based group deliberation in an incentive-compatible charity allocation task with real financial stakes ($7,200 USD). Study 1 (N=204) compares three frontier LLMs as facilitators; Study 2 (N=675) compares facilitation strategies to a no-facilitation baseline. Central claims are that LLM facilitation produced no significant improvement in group consensus (per aggregate agreement metrics) yet elicited consistent participant preference for facilitated conditions; two governance risks are identified—algorithmic steering (shifts in select charity allocations up to 5.5 pp without aggregate consensus change) and illusion of inclusion (higher perceived inclusivity without gains in survey or transcript equity measures).
Significance. If the results hold under more detailed scrutiny, the work is significant for HCI and AI governance research. It provides concrete evidence that perceived procedural benefits (preference, trust) can coexist with measurable outcome steering and static participation inequality in LLM-mediated groups. The incentive-compatible design with real stakes strengthens ecological validity for civic and workplace applications, and the distinction between collective outcomes, interaction dynamics, and perceptions offers a useful framework for future evaluation practices.
major comments (3)
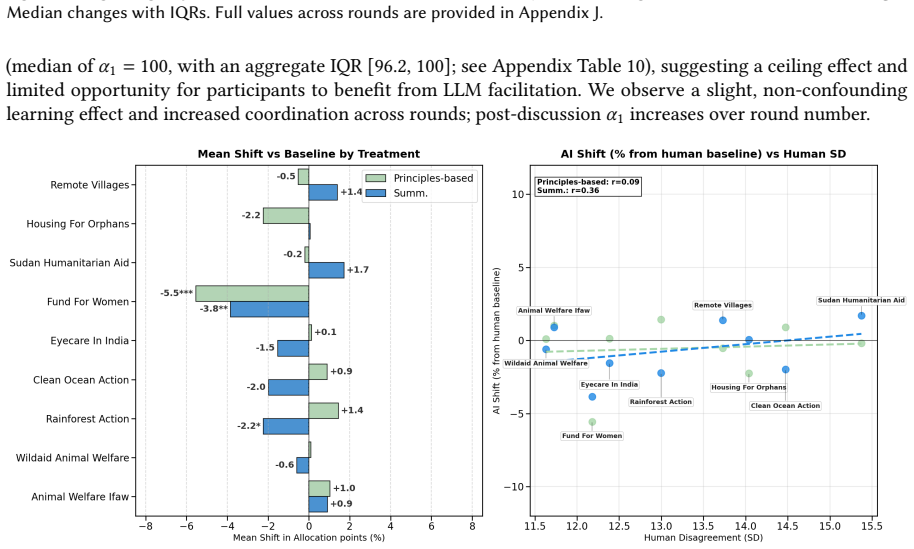
- [Results (Study 2)] Results section (Study 2, algorithmic steering paragraph): The claim of shifts up to 5.5 percentage points in specific charity allocations requires explicit statistical tests (e.g., per-charity t-tests or regression coefficients with p-values and confidence intervals) and a precise definition of how 'select' charities were identified; without these, it is unclear whether the shifts are distinguishable from noise given that aggregate agreement metrics showed no change.
- [Methods] Methods section: The operationalization of consensus (e.g., variance, pairwise similarity, or other aggregate metrics) and participation equity (survey items plus transcript coding rules for message volume/turn-taking) must be specified in detail, including inter-rater reliability for transcripts and power analysis for the null consensus result; these metrics are load-bearing for the steering and illusion-of-inclusion conclusions.
- [Discussion] Discussion section: The interpretation that unchanged aggregate metrics plus directional shifts constitute 'steering' rather than a form of consensus change needs justification against alternative granular measures (e.g., semantic alignment of contributions or preference polarization indices); if coarser metrics miss these, the governance-risk framing may require qualification.
minor comments (2)
- [Abstract] Abstract: The total N=879 is the sum of the two studies with no overlap, but a parenthetical note on this would improve immediate clarity.
- [Results] The paper would benefit from reporting effect sizes (e.g., Cohen's d or partial eta-squared) alongside the preference and trust findings to allow readers to assess practical significance.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major point below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Results (Study 2)] Results section (Study 2, algorithmic steering paragraph): The claim of shifts up to 5.5 percentage points in specific charity allocations requires explicit statistical tests (e.g., per-charity t-tests or regression coefficients with p-values and confidence intervals) and a precise definition of how 'select' charities were identified; without these, it is unclear whether the shifts are distinguishable from noise given that aggregate agreement metrics showed no change.
Authors: We agree that additional statistical detail is required for transparency. In the revised manuscript, we will report per-charity independent-samples t-tests (facilitated vs. baseline) with p-values, Cohen's d, and 95% confidence intervals for all allocation differences. 'Select' charities will be defined explicitly as those exhibiting a mean shift of at least 3 percentage points that reaches statistical significance (p < 0.05) in at least one facilitated condition. We will also include the full allocation table for all charities so readers can evaluate the pattern against noise. revision: yes
-
Referee: [Methods] Methods section: The operationalization of consensus (e.g., variance, pairwise similarity, or other aggregate metrics) and participation equity (survey items plus transcript coding rules for message volume/turn-taking) must be specified in detail, including inter-rater reliability for transcripts and power analysis for the null consensus result; these metrics are load-bearing for the steering and illusion-of-inclusion conclusions.
Authors: We will expand the Methods section with precise operational definitions. Consensus is measured by (1) variance of the final allocation proportions across groups and (2) mean pairwise cosine similarity of pre- and post-discussion preference vectors. Participation equity comprises Likert-scale survey items on perceived inclusion/fairness plus transcript coding for message count, total words, and turn-taking Gini coefficient. Two coders will independently code 20% of transcripts; Cohen's kappa will be reported. A post-hoc power analysis for the null consensus results, based on observed effect sizes, will be added to quantify sensitivity to small effects. revision: yes
-
Referee: [Discussion] Discussion section: The interpretation that unchanged aggregate metrics plus directional shifts constitute 'steering' rather than a form of consensus change needs justification against alternative granular measures (e.g., semantic alignment of contributions or preference polarization indices); if coarser metrics miss these, the governance-risk framing may require qualification.
Authors: We maintain that the observed pattern qualifies as steering because directional changes in specific allocations occurred without corresponding gains in aggregate agreement, indicating targeted influence rather than broad convergence. In revision we will add explicit justification contrasting our metrics with polarization indices (showing no increase in preference extremity) and acknowledge that semantic alignment or contribution-level measures could reveal subtler dynamics. The governance-risk language will be qualified to note that our standard allocation metrics may not capture every form of influence, while still highlighting the dissociation between perceived and measured outcomes. revision: partial
Circularity Check
No circularity: purely empirical study with no derivations or self-referential predictions
full rationale
The paper reports two incentive-compatible experiments (N=879) measuring LLM facilitation effects on group consensus, allocation shifts, and perceived inclusivity via surveys and transcripts. No equations, fitted parameters, or first-principles derivations appear; all results rest on direct statistical comparisons of collected data against baselines. No self-citation chains or ansatzes are invoked to justify core claims, so the reported findings on steering and illusion of inclusion are independent of any internal reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions of randomized controlled trials and null-hypothesis significance testing apply to the group allocation task
Reference graph
Works this paper leans on
- [1]
-
[2]
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. 2022. Constitutional AI: harmlessness from AI feedback. 2022.arXiv preprint arXiv:2212.080738, 3 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Nadia M. Brashier and Elizabeth J. Marsh. 2020. Judging Truth.Annual Review of Psychology71, 1 (2020), 499–515. doi:10.1146/annurev- psych-010419-050807
-
[4]
Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychology.Qualitative Research in Psychology3, 2 (2006), 77–101. doi:10.1191/1478088706qp063oa
-
[5]
Zana Buçinca, Phoebe Lin, Krzysztof Z. Gajos, and Elena L. Glassman. 2020. Proxy tasks and subjective measures can be misleading in evaluating explainable AI systems. InProceedings of the 25th International Conference on Intelligent User Interfaces (IUI ’20). ACM, 454–464. doi:10.1145/3377325.3377498
-
[6]
Charity Navigator. 2024. Charity Navigator Ratings and Evaluations. https://www.charitynavigator.org/. Accessed: October 2025
work page 2024
- [7]
-
[8]
Chun-Wei Chiang, Zhuoran Lu, Zhuoyan Li, and Ming Yin. 2024. Enhancing AI-Assisted Group Decision Making through LLM- Powered Devil’s Advocate. InProceedings of the 29th International Conference on Intelligent User Interfaces(Greenville, SC, USA)(IUI ’24). Association for Computing Machinery, New York, NY, USA, 103–119. doi:10.1145/3640543.3645199
- [9]
-
[10]
Daly, Julie Lee, Geoffrey Soutar, and Sarah Rasmi
Timothy M. Daly, Julie Lee, Geoffrey Soutar, and Sarah Rasmi. 2010. Conflict-handling style measurement: A best-worst scaling application.International Journal of Conflict Management21, 3 (2010), 281–308. doi:10.1108/10444061011063180 Real-Time Group Dynamics with LLM Facilitation FAccT ’26, June 25–28, 2026, Montreal, QC, Canada
-
[11]
Fred D. Davis. 1989. Perceived Usefulness, Perceived Ease of Use, and User Acceptance of Information Technology.MIS Quarterly13, 3 (1989), 319–340. doi:10.2307/249008
-
[12]
Stefano DellaVigna, John A. List, and Ulrike Malmendier. 2012. Testing for Altruism and Social Pressure in Charitable Giving.The Quarterly Journal of Economics127, 1 (2012), 1–56. doi:10.1093/qje/qjr050
-
[13]
Ernst Fehr and Simon Gächter. 2000. Cooperation and Punishment in Public Goods Experiments.American Economic Review90, 4 (2000), 980–994. doi:10.1257/aer.90.4.980
- [14]
-
[15]
Galinsky and Thomas Mussweiler
Adam D. Galinsky and Thomas Mussweiler. 2001. First Offers as Anchors: The Role of Perspective-Taking and Negotiator Focus.Journal of Personality and Social Psychology81, 4 (2001), 657–669. doi:10.1037/0022-3514.81.4.657
- [16]
-
[17]
Jarod Govers, Eduardo Velloso, Vassilis Kostakos, and Jorge Goncalves. 2024. AI-Driven Mediation Strategies for Audience Depolarisation in Online Debates. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 803, 18 pages. doi:10.1145/361...
-
[18]
Lynn Hasher, David Goldstein, and Thomas Toppino. 1977. Frequency and the Conference of Referential Validity.Journal of Verbal Learning and Verbal Behavior16, 1 (1977), 107–112. doi:10.1016/S0022-5371(77)80012-1
-
[19]
Carl I. Hovland and Walter Weiss. 1951. The Influence of Source Credibility on Communication Effectiveness.Public Opinion Quarterly 15, 4 (1951), 635–650. doi:10.1086/266350
-
[20]
Irving L. Janis. 1982.Groupthink: Psychological Studies of Policy Decisions and Fiascoes(2 ed.). Houghton Mifflin, Boston, MA
work page 1982
-
[21]
Margo Janssens, Nicole Meslec, and Roger T. A. J. Leenders. 2022. Collective Intelligence in Teams: Contextualizing Collective Intelligent Behavior Over Time.Frontiers in Psychology13 (2022), 989572. doi:10.3389/fpsyg.2022.989572
-
[22]
Karpowitz, Tali Mendelberg, and Lee Shaker
Christopher F. Karpowitz, Tali Mendelberg, and Lee Shaker. 2012. Gender Inequality in Deliberative Participation.American Political Science Review106, 3 (2012), 533–547. doi:10.1017/S0003055412000329
- [23]
-
[24]
Min Seo Kim, Jung Su Lee, and Bae Hyuna. 2025. Large Language Models for Pre-mediation Counseling in Medical Disputes: A Compar- ative Evaluation against Human Experts.hir31, 2 (2025), 200–208. arXiv:http://www.e-sciencecentral.org/articles/?scid=1516090752 doi:10.4258/hir.2025.31.2.200
-
[25]
Andrew Konya, Luke Thorburn, Wasim Almasri, Oded Adomi Leshem, Ariel Procaccia, Lisa Schirch, and Michiel Bakker. 2025. Using collective dialogues and AI to find common ground between Israeli and Palestinian peacebuilders. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’25). ACM, 312–333. doi:10.1145/3715275.3732022
-
[26]
Özgecan Koçak, Phanish Puranam, and AFSAR YEGIN. 2025. LLMs as Mediators: Can They Diagnose Conflicts Accurately?ACM Journal on Computing and Sustainable Societies(Oct. 2025). doi:10.1145/3771553
-
[27]
Klaus Krippendorff. 2004. Reliability in content analysis: Some common misconceptions and recommendations. InHuman communication research. Vol. 30. Wiley, 411–433
work page 2004
-
[28]
John O. Ledyard. 1995. Public Goods: A Survey of Experimental Research. InThe Handbook of Experimental Economics, John H. Kagel and Alvin E. Roth (Eds.). Princeton University Press, 111–194
work page 1995
-
[29]
Hyunsoo Lee, Auk Kim, Hwajung Hong, and Uichin Lee. 2021. Sticky Goals: Understanding Goal Commitments for Behavioral Changes in the Wild. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems(Yokohama, Japan)(CHI ’21). Association for Computing Machinery, New York, NY, USA, Article 230, 16 pages. doi:10.1145/3411764.3445295
-
[30]
Haiwen Li, Soham De, Manon Revel, Andreas Haupt, Brad Miller, Keith Coleman, Jay Baxter, Martin Saveski, and Michiel Bakker. 2025. Scaling Human Judgment in Community Notes with LLMs.Journal of Online Trust and Safety3, 1 (Sept. 2025). doi:10.54501/jots.v3i1.255
- [31]
-
[32]
Tadayuki Matsumura, Takeshi Kato, Yasuhiro Asa, Kanako Esaki, Ryuji Mine, and Hiroyuki Mizuno. 2025. AI-Facilitation for Consensus- Building by Virtual Discussion Using Large Language Models. InPRICAI 2024: Trends in Artificial Intelligence, Rafik Hadfi, Patricia Anthony, Alok Sharma, Takayuki Ito, and Quan Bai (Eds.). Springer Nature Singapore, Singapore...
work page 2025
-
[33]
Judith Mehta, Chris Starmer, and Robert Sugden. 1994. Focal Points in Pure Coordination Games: An Experimental Investigation. Theory and Decision36, 2 (1994), 163–185. doi:10.1007/BF01079211
-
[34]
Napolitan Institute and Jigsaw. 2025. We the People. https://wethepeople-250.org/. AI-powered national conversation initiative; accessed 2026-01-12
work page 2025
-
[35]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.arXiv preprint arXiv:2203.02155 (2022). FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Aaron Parisi, Nithum Thain, Alden Hallak, V...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
Marios Papachristou, Longqi Yang, and Chin-Chia Hsu. 2025. Leveraging Large Language Models for Collective Decision-Making. Proceedings of the ACM on Human-Computer Interaction9, 7 (Oct. 2025), 1–44. doi:10.1145/3757418
- [37]
-
[38]
Priya Pitre, Naren Ramakrishnan, and Xuan Wang. 2025. CONSENSAGENT: Towards Efficient and Effective Consensus in Multi-Agent LLM Interactions Through Sycophancy Mitigation. InFindings of the Association for Computational Linguistics: ACL 2025, Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Computational...
-
[39]
Prolific. 2025. Prolific Participant Recruitment Platform. https://www.prolific.com. Accessed: 2025-05-09
work page 2025
-
[40]
Crystal Qian, Aaron T Parisi, Clémentine Bouleau, Vivian Tsai, Maël Lebreton, and Lucas Dixon. 2025. To Mask or to Mirror: Human-AI Alignment in Collective Reasoning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association f...
- [41]
-
[42]
Crystal Qian and James Wexler. 2024. Take It, Leave It, or Fix It: Measuring Productivity and Trust in Human-AI Collaboration. In Proceedings of the 29th International Conference on Intelligent User Interfaces(Greenville, SC, USA)(IUI ’24). Association for Computing Machinery, New York, NY, USA, 370–384. doi:10.1145/3640543.3645198
-
[43]
Manning, Vivian Tsai, James Wexler, and Nithum Thain
Crystal Qian, Kehang Zhu, John Horton, Benjamin S. Manning, Vivian Tsai, James Wexler, and Nithum Thain. 2025. Strategic Tradeoffs Between Humans and AI in Multi-Agent Bargaining. arXiv:2509.09071 [cs.AI] https://arxiv.org/abs/2509.09071
-
[44]
Alice Siu. 2017. Deliberation & the Challenge of Inequality.Daedalus146, 3 (2017), 119–128. doi:10.1162/DAED_a_00451
-
[45]
Christopher T. Small, Ivan Vendrov, Esin Durmus, Hadjar Homaei, Elizabeth Barry, Julien Cornebise, Ted Suzman, Deep Ganguli, and Colin Megill. 2023. Opportunities and Risks of LLMs for Scalable Deliberation with Polis. arXiv:2306.11932 [cs.SI] https: //arxiv.org/abs/2306.11932
-
[46]
Garold Stasser and William Titus. 1985. Pooling of Unshared Information in Group Decision Making: Biased Information Sampling During Discussion.Journal of Personality and Social Psychology48, 6 (1985), 1467–1478. doi:10.1037/0022-3514.48.6.1467
-
[47]
SwayBeta. 2025. SwayBeta. https://www.swaybeta.ai/home. Accessed: 2025-12-10
work page 2025
- [48]
-
[49]
Amir Taubenfeld, Yaniv Dover, Roi Reichart, and Ariel Goldstein. 2024. Systematic Biases in LLM Simulations of Debates. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 251–267. doi:10.18653/v1/2024.emnlp-main.16
-
[50]
Bakker, Daniel Jarrett, Hannah Sheahan, Martin J
Michael Henry Tessler, Michiel A. Bakker, Daniel Jarrett, Hannah Sheahan, Martin J. Chadwick, Raphael Koster, Georgina Evans, Lucy Campbell-Gillingham, Tantum Collins, David C. Parkes, Matthew Botvinick, and Christopher Summerfield
-
[51]
arXiv:https://www.science.org/doi/pdf/10.1126/science.adq2852 doi:10.1126/science.adq2852
AI can help humans find common ground in democratic deliberation.Science386, 6719 (2024), eadq2852. arXiv:https://www.science.org/doi/pdf/10.1126/science.adq2852 doi:10.1126/science.adq2852
- [52]
-
[53]
The Verge. 2025. Columbia tries using AI to cool off student tensions. https://www.theverge.com/ai-artificial-intelligence/770510/ columbia-university-sway-ai-to-cool-off-student-tensions-israel-palestine-protests. Accessed: 2025-12-10
work page 2025
-
[54]
Amos Tversky and Daniel Kahneman. 1974. Judgment under Uncertainty: Heuristics and Biases.Science185, 4157 (1974), 1124–1131. doi:10.1126/science.185.4157.1124
-
[55]
Tom R. Tyler. 2003. Procedural Justice, Legitimacy, and the Effective Rule of Law.Crime and Justice30 (2003), 283–357. doi:10.1086/652233
-
[56]
Donna M. Webster and Arie W. Kruglanski. 1994. Individual Differences in Need for Cognitive Closure.Journal of Personality and Social Psychology67, 6 (1994), 1049–1062. doi:10.1037/0022-3514.67.6.1049
-
[57]
Chabris, Alex Pentland, Nada Hashmi, and Thomas W
Anita Williams Woolley, Christopher F. Chabris, Alex Pentland, Nada Hashmi, and Thomas W. Malone. 2010. Evidence for a Collective Intelligence Factor in the Performance of Human Groups.Science330, 6004 (2010), 686–688. doi:10.1126/science.1193147 Real-Time Group Dynamics with LLM Facilitation FAccT ’26, June 25–28, 2026, Montreal, QC, Canada A PARTICIPANT...
-
[58]
Standard Schema (Base) This structured output schema is used by the summarization facilitator and the baseline OOTB models (Claude, Gemini, GPT). It defines how the model should reason about intervention timing, frequency and content. Standard Schema (JSON) { "type": "OBJECT", "properties": [ { "name": "explanation", "description": "Your reasoning for you...
-
[59]
Summarization-Style Facilitator Prompt This system instruction directs the model to act as a neutral summarizer. It utilizes theStandard Facilitator Schema. Summarization-Style Facilitator System Prompt You are a neutral facilitator supporting a group discussion about how to allocate donations: you accomplish this through summarization-style facilitation,...
-
[60]
Principles-Based Facilitator Schema Description:This schema extends theStandard facilitator Schemawith specific fields for diagnosing group failure modes (e.g., “OffTopicDrift”), providing a list of associated strategies for each failure mode. Real-Time Group Dynamics with LLM Facilitation FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Principles-Based...
work page 2026
-
[61]
Principles-Based Facilitator Prompt This facilitator is provided with a lookup table of common conversational failure modes and their associated “solutions” - common strategies associated with each conversational failure mode. It uses the following schema. Principles-Based Facilitator System Prompt You are a neutral facilitator supporting a group discussi...
-
[62]
Baseline / OOTB facilitator Prompt Description:This minimal prompt is used for the “Out-of-the-Box” conditions (Gemini 2.5 Flash, Claude 4.5 Haiku, GPT-5 mini). It relies on the model’s inherent training. Baseline facilitator System Prompt As the conversation facilitator, help the group explore how they want to split the donation across the three charitie...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.