Recognition: 2 theorem links
· Lean TheoremModeling Bounded Rationality in Drug Shortage Pharmacists Using Attention-Guided Dynamic Decomposition
Pith reviewed 2026-05-15 05:09 UTC · model grok-4.3
The pith
Pharmacists maintain stable drug-shortage decisions by directing attention to urgent cases instead of analyzing the full state.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
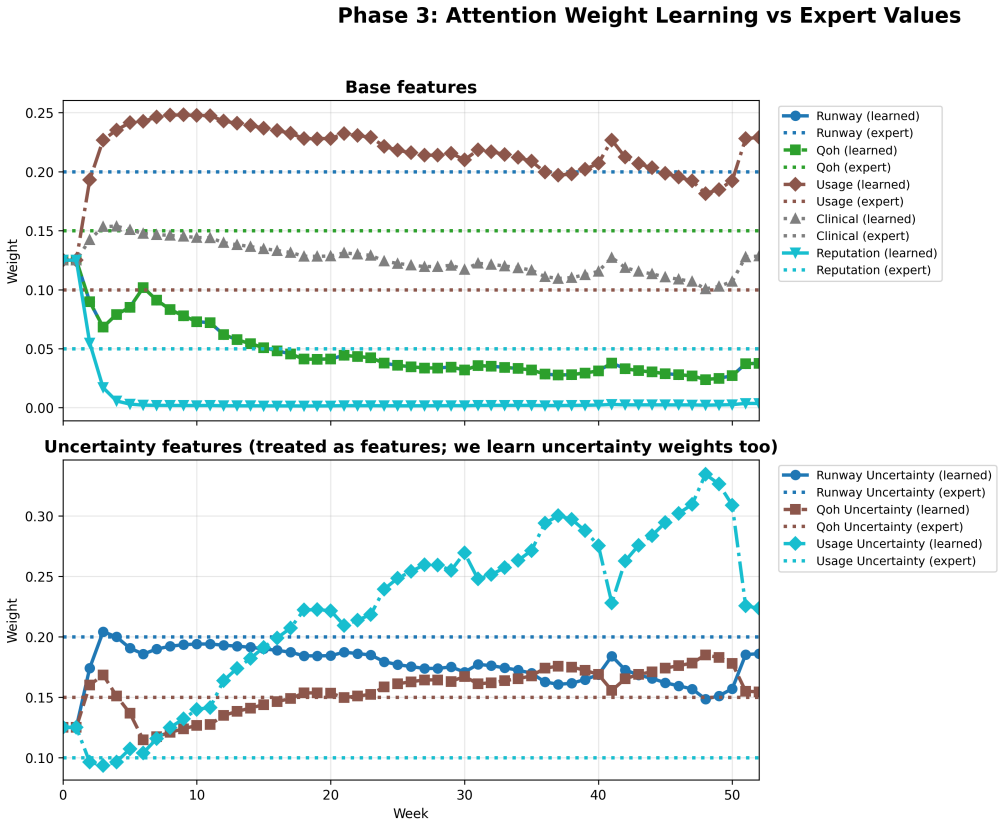
Hospital pharmacists focus attention on a small subset of drugs to limit cognitive effort to urgent cases under time pressure and patient risk. The attention-guided decision framework dynamically decomposes the set of drugs into a subset for high-cost reasoning and a complementary subset for low-cost monitoring. An Expert Agent applies attention weights taken directly from pharmacist interviews, while a Learner Agent adapts the allocation through repeated experience. Across simulated scenarios that span short to long horizons, attention-guided planning produces stable decision-making without requiring complete state reasoning.
What carries the argument
Attention-guided dynamic decomposition that splits drugs into high-cost reasoning and low-cost monitoring subsets using weights derived from pharmacist interviews.
If this is right
- The primary decision shifts from choosing an action to choosing where to allocate cognitive effort.
- Attention-guided satisficing strategies reduce problem complexity while preserving stable performance.
- Both the interview-based Expert Agent and the experience-based Learner Agent maintain stability across short and long planning horizons.
- Bounded-rational attention mechanisms can be applied to other high-stakes decisions under uncertainty and time pressure.
Where Pith is reading between the lines
- Similar attention-limited decomposition could be tested in other time-critical professional settings such as emergency-room triage or supply-chain crisis response.
- Real-time updates to drug-shortage data might accelerate the Learner Agent's adaptation rate beyond what interview weights alone provide.
- If attention weights derived from one group of pharmacists fail to generalize, retraining on new interview data becomes the required next step.
- The framework suggests that training programs could explicitly teach pharmacists to identify and prioritize the urgent subset rather than attempting exhaustive analysis.
Load-bearing premise
Attention weights taken from pharmacist interviews accurately reflect real decision processes and transfer to the simulated shortage scenarios without major distortion.
What would settle it
Direct comparison of the model's attention allocations and resulting shortage-mitigation choices against observed pharmacist behavior in a new controlled shortage scenario.
Figures
read the original abstract
Hospital pharmacists make high-stakes decisions to mitigate drug shortages under uncertainty, time pressure, and patient risk. Interviews revealed that pharmacists focus attention on a small subset of drugs, limiting cognitive effort to the most urgent cases. Motivated by these findings, we formalize a bounded-rational, attention-guided decision framework that dynamically decomposes drugs into a subset for high-cost reasoning and a complementary subset for low-cost monitoring. We develop two agents: an Expert Agent that applies attention weights derived from pharmacist interviews, and a Learner Agent that adapts attention allocation over time through experience. Across simulated scenarios spanning short to long horizons, we show that attention-guided planning supports stable decision-making without complete state reasoning. These results suggest that a primary decision is not what action to take, but where to allocate cognitive effort, and that attention-guided, satisficing strategies can reduce problem complexity while maintaining stable performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that hospital pharmacists exhibit bounded rationality by focusing attention on a small subset of drugs during shortages. It formalizes this via an attention-guided dynamic decomposition framework that partitions drugs into high-cost reasoning and low-cost monitoring subsets. Two agents are introduced: an Expert Agent that uses attention weights derived from pharmacist interviews and a Learner Agent that adapts allocation through experience. Simulations across short-to-long horizons are reported to show stable decision-making without requiring complete state reasoning, implying that the primary decision is cognitive-effort allocation rather than action selection.
Significance. If the central claim holds after validation, the work offers a concrete formalization of attention-based satisficing in a high-stakes domain and demonstrates that stable performance can be achieved without full rationality. The simulation design spanning multiple horizons is a positive feature that tests robustness. However, the absence of reported baselines, error bars, or mapping validation between interview data and simulation inputs limits the strength of the contribution to modeling bounded rationality.
major comments (2)
- [Abstract] Abstract: the claim that attention-guided planning supports stable decision-making rests on interview-derived weights, yet no elicitation protocol, quantification method (e.g., ranking or regression), or inter-rater reliability is described. This is load-bearing for the bounded-rationality interpretation; without it the reported stability may be an artifact of the chosen simulation dynamics rather than a property of the attention mechanism.
- [Simulation results] Simulation results (implied in abstract): no baseline comparisons, error bars, or statistical tests against real pharmacist behavior are mentioned, leaving the central claim only weakly supported. The absence of these elements makes it impossible to determine whether the Expert and Learner agents outperform standard full-reasoning or random-attention controls.
minor comments (1)
- [Abstract] The abstract uses the term 'parameter-free' implicitly for the decomposition but lists attention weights as free parameters; clarify this distinction in the methods section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for strengthening the description of our interview-based attention weights and the simulation evaluation. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that attention-guided planning supports stable decision-making rests on interview-derived weights, yet no elicitation protocol, quantification method (e.g., ranking or regression), or inter-rater reliability is described. This is load-bearing for the bounded-rationality interpretation; without it the reported stability may be an artifact of the chosen simulation dynamics rather than a property of the attention mechanism.
Authors: We agree that the abstract and main text would benefit from greater transparency on the interview process. The full manuscript describes the pharmacist interviews that informed the attention weights, but we will add a dedicated subsection detailing the elicitation protocol (semi-structured questions on prioritization during shortages), the quantification method (normalized average rankings across respondents), and inter-rater reliability (Cohen's kappa computed on a subset of responses). We will also revise the abstract to briefly reference this protocol. These changes will make explicit that the reported stability is attributable to the attention mechanism. revision: yes
-
Referee: [Simulation results] Simulation results (implied in abstract): no baseline comparisons, error bars, or statistical tests against real pharmacist behavior are mentioned, leaving the central claim only weakly supported. The absence of these elements makes it impossible to determine whether the Expert and Learner agents outperform standard full-reasoning or random-attention controls.
Authors: We agree that explicit baselines and statistical reporting are needed. In the revision we will add (i) full-reasoning and random-attention control agents, (ii) error bars computed over 50 independent simulation runs per horizon, and (iii) paired t-tests comparing performance metrics. Direct statistical tests against observed real-world pharmacist decisions are not possible because the study uses simulation informed by interview data rather than paired observational logs; we will instead strengthen the qualitative mapping discussion between interview themes and simulated behavior. revision: partial
- Direct quantitative statistical comparison to real-time observed pharmacist decisions is unavailable because the study design relies on simulation rather than paired field data.
Circularity Check
No significant circularity detected; derivation relies on external interview data and independent simulations
full rationale
The paper extracts attention weights from pharmacist interviews (external data source) to define the Expert Agent and then evaluates the resulting attention-guided agents via separate simulation runs across short-to-long horizons. No equations, self-citations, uniqueness theorems, or prior-work ansatzes are quoted that would make the stability result reduce to the interview inputs by construction. The central claim is presented as an empirical outcome of the simulations rather than a definitional or fitted tautology. This is the standard non-circular case where external inputs feed a model whose performance is tested separately.
Axiom & Free-Parameter Ledger
free parameters (1)
- attention weights
axioms (2)
- domain assumption Pharmacists focus attention on a small subset of drugs under time pressure and uncertainty
- standard math Bounded rationality limits complete state reasoning
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formalize a bounded-rational, attention-guided decision framework that dynamically decomposes drugs into a subset for high-cost reasoning and a complementary subset for low-cost monitoring... urgency is computed as U_i = U_runway(s_i) + ∑ β_f · U_f(s_i,f)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The Expert Agent encodes attention weights that guide which drugs to attend to. These weights are informed by pharmacist interviews.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Decision-Theoretic Planning: Structural Assumptions and Computational Leverage
Boutilier,C.,Dean,T.,&Hanks,S.(2011).Decision-theoretic planning: Structural assumptions and computational lever- age.arXiv preprint arXiv:1105.5460. https://arxiv.org/abs/ 1105.5460
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[2]
Chicoine, N., & Griffin, J. (2025). The unreliability of esti- mated releasedates in hospitaldrug shortage management: A case study of hospital pharmacy operations during the covid-19 pandemic.medRxiv. https://doi.org/10.1101/ 2025.07.10.25331166 Ergun,O.,Zohreh,R.,Atkinson,R.,&Keskinocak,P.(2020). Supplychainresilience:Impactofstakeholderbehaviorand trus...
work page 2025
-
[3]
Gigerenzer, G., & Gaissmaier, W. (2011). Heuristic decision making.Annual Review of Psychology,62, 451–482
work page 2011
-
[4]
Hansen, E. A., & Zilberstein, S. (2001). Monitoring and con- trol of anytime algorithms: A dynamic programming ap- proach.Artificial Intelligence,126(1-2), 139–157
work page 2001
-
[5]
Igl, M., Zintgraf, L., Le, T. A., Wood, F., & Whiteson, S. (2018). Deep variational reinforcement learning for pomdps.International conference on machine learning, 2117–2126
work page 2018
-
[6]
(1998).Sources of power: How people make deci- sions
Klein, G. (1998).Sources of power: How people make deci- sions. MIT Press
work page 1998
-
[7]
(2009).Streetlights and shadows: Searching for the keys to adaptive decision making
Klein, G. (2009).Streetlights and shadows: Searching for the keys to adaptive decision making. MIT Press
work page 2009
-
[8]
Kurniawati, H., Hsu, D., & Lee, W. S. (2008). Sarsop: Effi- cient point-based pomdp planning by approximating opti- mally reachable belief spaces.Robotics: Science and Sys- tems,2008
work page 2008
-
[9]
McGeeney, J., McAden, E., & Sertkaya, A. (2025, January). Analysis of drug shortages, 2018–2023(Prepared by East- ern Research Group, Inc. for the Office of the Assistant Secretary for Planning and Evaluation (ASPE)) (Available from ASPE or ERG upon request). U.S. Department of Health and Human Services (HHS)
work page 2025
-
[10]
Mnih, V., Heess, N., Graves, A., & Kavukcuoglu, K. (2014). Recurrentmodelsofvisualattention.AdvancesinNeuralIn- formationProcessingSystems27(NIPS2014),2204–2212. https://proceedings.neurips.cc/paper_files/paper/2014/file/ 3e456b31302cf8210edd4029292a40ad-Paper.pdf Papadimitriou,C.H.,&Tsitsiklis,J.N.(1987).Thecomplex- ity of markov decision processes.Mathe...
work page 2014
-
[11]
Poupart, P. (2005).Exploiting structure to efficiently solve largescalepartiallyobservablemarkovdecisionprocesses [Doctoral dissertation, University of Toronto]. https://cs. uwaterloo.ca/~ppoupart/publications/ut-thesis/ut-thesis. pdf
work page 2005
-
[12]
Mohaddesi, O., Harteveld, C., Kaeli, D., & Marsella, S. (2022). Supply chain resilience: Impact of stakeholder be- havior and trustworthy information sharing with a case study on pharmaceutical supply chains. InTutorials in op- erations research: Emerging and impactful topics in oper- ations(pp. 133–159). INFORMS. Silver,D.,&Veness,J.(2010).Monte-carlopla...
work page 2022
-
[13]
Simon, H. A. (1972). Theories of bounded rationality. In C. McGuire & R. Radner (Eds.),Decision and organization (pp. 161–176). North-Holland Publishing Company
work page 1972
-
[14]
Williams, R. J. (1992). Simple statistical gradient-following algorithms for connectionist reinforcement learning.Ma- chine Learning,8(3-4), 229–256
work page 1992
-
[15]
G., Shen, B., Zhang, J., & Weng, W
Wu, Y., Wang, Z. G., Shen, B., Zhang, J., & Weng, W. (2023). Reinforcement learning for healthcare operations management: Methodological framework, recent develop- ments, and future research directions.Computers & Oper- ations Research
work page 2023
-
[16]
Yongsatianchot, N., Chicoine, N., Griffin, J., Ergun, O., & Marsella, S. (2023). Agent-based modeling of human decision-makers under uncertain information during sup- ply chain shortages.Proceedings of the 22nd International ConferenceonAutonomousAgentsandMultiagentSystems (AAMAS 2023), 1886–1894. https://www.ifaamas.org/ Proceedings/aamas2023/pdfs/p1886.pdf
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.