Recognition: 2 theorem links
· Lean TheoremTo discretize continually: Mean shift interacting particle systems for Bayesian inference
Pith reviewed 2026-05-15 02:01 UTC · model grok-4.3
The pith
Mean shift interacting particle systems approximate expectations from unnormalized densities by minimizing maximum mean discrepancy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
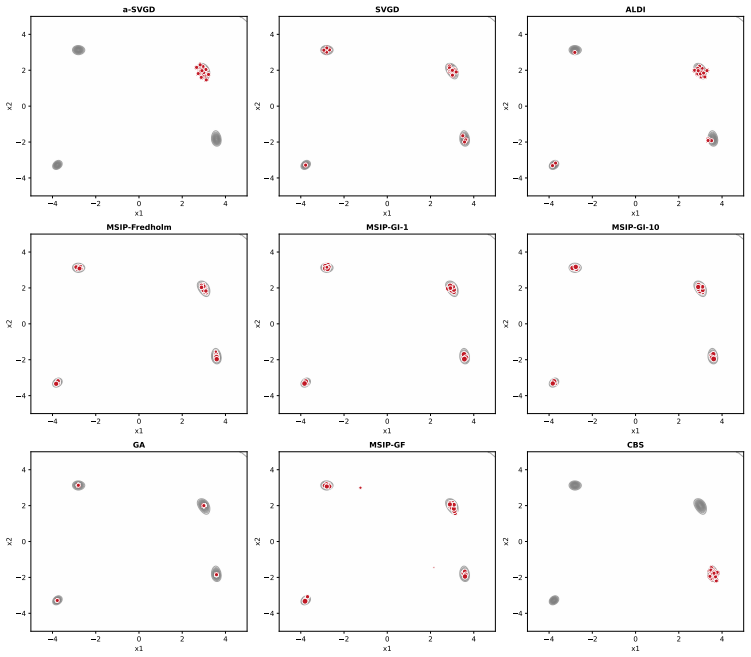
Interacting particle systems that minimize maximum mean discrepancy to a target distribution, extended from mean shift to continuous unnormalized densities, produce weighted samples whose averages accurately approximate the desired expectations, with convergence that captures anisotropy and multi-modality and scales to high dimensions.
What carries the argument
MMD-minimizing interacting particle dynamics that are invariant to the normalizing constant of the target density.
If this is right
- The method handles Bayesian hierarchical models and PDE-constrained inverse problems with the same particle dynamics.
- Both gradient-free and gradient-informed implementations are available from the same underlying MMD flow.
- The particles avoid mode collapse while representing anisotropic and multi-modal structure.
- The approach scales to high-dimensional sampling benchmarks without requiring knowledge of the partition function.
Where Pith is reading between the lines
- The invariance to the normalizing constant may allow direct application to unnormalized models arising in physics or machine learning where the constant is intractable.
- The connection to optimal quantization suggests the particle configurations could also serve as low-discrepancy point sets for integration outside Bayesian settings.
- If the dynamics preserve certain symmetries, they might combine with existing transport or Stein-based methods for variance reduction.
Load-bearing premise
The MMD-minimizing particle dynamics, when run on unnormalized densities, produce configurations whose weighted averages match the true expectations of the target distribution.
What would settle it
Run the particle system on a multi-modal Gaussian mixture with known exact moments and check whether the weighted sample averages deviate from those moments by more than Monte Carlo error.
Figures







read the original abstract
Integration against a probability distribution given its unnormalized density is a central task in Bayesian inference and other fields. We introduce new methods for approximating such expectations with a small set of weighted samples -- i.e., a quadrature rule -- constructed via an interacting particle system that minimizes maximum mean discrepancy (MMD) to the target distribution. These methods extend the classical mean shift algorithm, as well as recent algorithms for optimal quantization of empirical distributions, to the case of continuous distributions. Crucially, our approach creates dynamics for MMD minimization that are invariant to the unknown normalizing constant; they also admit both gradient-free and gradient-informed implementations. The resulting mean shift interacting particle systems converge quickly, capture anisotropy and multi-modality, avoid mode collapse, and scale to high dimensions. We demonstrate their performance on a wide range of benchmark sampling problems, including multi-modal mixtures, Bayesian hierarchical models, PDE-constrained inverse problems, and beyond.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces mean shift interacting particle systems that minimize maximum mean discrepancy (MMD) to an unnormalized target density, yielding weighted particles that serve as quadrature rules for expectations in Bayesian inference. The dynamics are constructed to be invariant to the unknown normalizing constant Z and admit both gradient-free and gradient-informed implementations. The authors claim rapid convergence, effective capture of anisotropy and multi-modality without mode collapse, and scalability to high dimensions, supported by benchmarks on multi-modal mixtures, hierarchical models, and PDE-constrained inverse problems.
Significance. If the invariance property and quadrature accuracy are rigorously established, the method would offer a practical, scalable alternative to MCMC for posterior expectation estimation, especially when only unnormalized densities are available. The extension of mean-shift ideas to continuous MMD minimization and the explicit handling of the normalizer are technically interesting strengths.
major comments (2)
- [§3] §3: The derivation replaces the normalized kernel mean embedding with its unnormalized counterpart to obtain Z-invariant dynamics. Because MMD is defined only between probability measures, the manuscript must clarify the weight-update rule (or its absence) and prove that the stationary particle configuration, when weights are renormalized, exactly recovers the MMD minimizer; without this, the quadrature weights may carry a systematic scaling bias that affects expectation estimates.
- [Theorem 1] Theorem 1 / convergence analysis: The claim of quick convergence to the target is stated without explicit rates, error bounds on the MMD or on the quadrature error, or a proof that the continuous-time limit preserves the correct marginal on the normalized measure. These omissions make it impossible to assess whether the observed benchmark performance is consistent with the theory or merely empirical.
minor comments (2)
- [Notation] The distinction between the normalized and unnormalized kernel mean embeddings is introduced without a compact notation; introducing a consistent symbol (e.g., μ̂ vs. μ̃) would improve readability of the subsequent derivations.
- [Figures] Figure captions for the high-dimensional experiments should report the precise dimension, number of particles, and wall-clock time so that scalability claims can be directly compared with competing methods.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments on our manuscript. We address each major comment point by point below, indicating the revisions we will make to strengthen the presentation.
read point-by-point responses
-
Referee: [§3] §3: The derivation replaces the normalized kernel mean embedding with its unnormalized counterpart to obtain Z-invariant dynamics. Because MMD is defined only between probability measures, the manuscript must clarify the weight-update rule (or its absence) and prove that the stationary particle configuration, when weights are renormalized, exactly recovers the MMD minimizer; without this, the quadrature weights may carry a systematic scaling bias that affects expectation estimates.
Authors: We agree that additional clarification is needed in §3. The dynamics are constructed so that particle positions evolve under a mean-shift flow derived from the unnormalized kernel mean embedding while the weights remain fixed after initialization (determined by the initial empirical measure) and are only renormalized at the end for quadrature. In the revised manuscript we will insert an explicit statement of this weight-update rule (or its absence) together with a short proof that the renormalized stationary configuration is precisely the MMD minimizer between the weighted empirical measure and the target. This will eliminate any ambiguity about scaling bias in the quadrature weights. revision: yes
-
Referee: [Theorem 1] Theorem 1 / convergence analysis: The claim of quick convergence to the target is stated without explicit rates, error bounds on the MMD or on the quadrature error, or a proof that the continuous-time limit preserves the correct marginal on the normalized measure. These omissions make it impossible to assess whether the observed benchmark performance is consistent with the theory or merely empirical.
Authors: We acknowledge that Theorem 1 currently offers only a qualitative convergence guarantee. In the revision we will augment the convergence analysis with explicit rates (under standard Lipschitz and smoothness assumptions on the kernel), derive MMD and quadrature-error bounds, and add a proof (placed in the appendix) that the continuous-time limit of the particle system preserves the correct marginal on the normalized target measure. These additions will make the theoretical claims directly comparable to the reported numerical results. revision: yes
Circularity Check
Derivation is self-contained with no circular reductions
full rationale
The paper constructs new MMD-minimizing particle dynamics that are invariant to the unknown normalizer Z by direct replacement of the normalized kernel mean embedding with its unnormalized counterpart, then extends classical mean shift and quantization algorithms. Central claims of rapid convergence, anisotropy capture, and high-dimensional scaling rest on empirical benchmarks rather than any step that equates a derived prediction to a fitted input or prior self-citation by construction. No load-bearing equation reduces to a self-definition, and the quadrature approximation is presented as a consequence of the dynamics rather than presupposed in their definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existence of dynamics for MMD minimization that are invariant to the unknown normalizing constant
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce finite-particle dynamics for MMD minimization... invariant to the normalization of the target despite the fact that MMD itself depends on this constant.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the regularized dynamics Y(t+1)=(1−η)Y(t)+ηΨ_MSIP,λ(Y(t))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
I. Arasaratnam and S. Haykin. Cubature Kalman Filters.IEEE Transactions on Automatic Control, 54(6):1254–1269, June 2009. ISSN 0018-9286, 1558-2523. doi: 10.1109/TAC.2009. 2019800
- [2]
-
[3]
D. Aristoff and W. Bangerth. A Benchmark for the Bayesian Inversion of Coefficients in Partial Differential Equations.SIAM Review, 65(4):1074–1105, November 2023. ISSN 0036-1445, 1095-7200
work page 2023
-
[4]
F. Bach. On the equivalence between kernel quadrature rules and random feature expansions. The Journal of Machine Learning Research, 18(1):714–751, 2017
work page 2017
-
[5]
F. Bach, S. Lacoste-Julien, and G. Obozinski. On the equivalence between herding and condi- tional gradient algorithms. InProceedings of the 29th International Coference on International Conference on Machine Learning, ICML’12, page 1355–1362, Madison, WI, USA, 2012. Omnipress. ISBN 9781450312851
work page 2012
-
[6]
S. Banerjee, K. Balasubramanian, and P. Ghosal. Improved finite-particle convergence rates for stein variational gradient descent. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
- [7]
-
[8]
A. Belhadji, R. Bardenet, and P. Chainais. Kernel quadrature with DPPs.Advances in Neural Information Processing Systems, 32:12907–12917, 2019
work page 2019
-
[9]
A. Belhadji, R. Bardenet, and P. Chainais. Kernel interpolation with continuous volume sampling.Proceedings of the 37th International Conference on Machine Learning, pages 725–735, 2020
work page 2020
-
[10]
A. Belhadji, Q. J. Zhu, and Y . Marzouk. On the design of scalable, high-precision spherical- radial fourier features.arXiv preprint arXiv:2408.13231, 2024
-
[11]
A. Belhadji, D. Sharp, and Y . M. Marzouk. Weighted quantization using MMD: From mean field to mean shift using gradient flows. InThe 29th International Conference on Artificial Intelligence and Statistics, 2026
work page 2026
-
[12]
Representations of knowledge in complex systems
J. Besag. Comments on “Representations of knowledge in complex systems” by U. Grenander and M. I. Miller.Journal of the Royal Statistical Society: Series B (Methodological), 56(4): 591–592, 1994
work page 1994
-
[13]
L. Bungert, T. Roith, and P. Wacker. Polarized consensus-based dynamics for optimization and sampling.Mathematical Programming, 211(1-2):125–155, May 2025. ISSN 0025-5610, 1436-4646
work page 2025
-
[14]
J. A. Carrillo, M. Fornasier, G. Toscani, and F. Vecil. Particle, kinetic, and hydrodynamic models of swarming. InMathematical modeling of collective behavior in socio-economic and life sciences, pages 297–336. Springer, 2010
work page 2010
-
[15]
J. A. Carrillo, Y-P. Choi, C. Totzeck, and O. Tse. An analytical framework for consensus-based global optimization method.Mathematical Models and Methods in Applied Sciences, 28(06): 1037–1066, 2018
work page 2018
-
[16]
J. A. Carrillo, F. Hoffmann, A. M. Stuart, and U. Vaes. Consensus-based sampling.Studies in Applied Mathematics, 148(3):1069–1140, 2022
work page 2022
-
[17]
J. A. Carrillo, Y . Chen, D. Z. Huang, J. Huang, and D. Wei. Fisher–Rao gradient flow: Geodesic convexity and functional inequalities.SIAM Journal on Mathematical Analysis, 58(2):1062– 1099, 2026. 11
work page 2026
-
[18]
W.Y . Chen, L. Mackey, J. Gorham, F.–X. Briol, and C. Oates. Stein points. InProceedings of the 35th International Conference on Machine Learning, volume 80, pages 844–853. PMLR, 10–15 Jul 2018
work page 2018
- [19]
- [20]
- [21]
-
[22]
K. Chwialkowski, H. Strathmann, and A. Gretton. A kernel test of goodness of fit. In International conference on machine learning, pages 2606–2615. PMLR, 2016
work page 2016
-
[23]
F. Cucker and S. Smale. On the mathematics of emergence.Japanese Journal of Mathematics, 2(1):197–227, 2007
work page 2007
-
[24]
F. D’Angelo and V . Fortuin. Repulsive deep ensembles are Bayesian.Advances in Neural Information Processing Systems, 34:3451–3465, 2021
work page 2021
- [25]
-
[26]
M. Deng, H. Li, T. Li, Y . Du, and K. He. Generative modeling via drifting.arXiv preprint arXiv:2602.04770, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
M. Dorigo and C. Blum. Ant colony optimization theory: A survey.Theoretical computer science, 344(2-3):243–278, 2005
work page 2005
-
[28]
S. Duane, A. D. Kennedy, B. J. Pendleton, and D. Roweth. Hybrid Monte Carlo.Physics Letters B, 195(2):216–222, 1987. doi: 10.1016/0370-2693(87)91197-X
- [29]
-
[30]
G. Evensen. The ensemble kalman filter: Theoretical formulation and practical implementation. Ocean dynamics, 53(4):343–367, 2003
work page 2003
-
[31]
S. Flaxman, S. Mishra, A. Gandy, H. Unwin, H. Coupland, T. Mellan, H. Zhu, T. Berah, J. Eaton, P. Perez-Guzman, et al. Report 13: Estimating the number of infections and the impact of non-pharmaceutical interventions on COVID-19 in 11 European countries. Technical report, Imperial College London, 2020
work page 2020
-
[32]
A. Garbuno-Inigo, F. Hoffmann, W. Li, and A. M. Stuart. Interacting Langevin diffusions: Gradient structure and ensemble Kalman sampler.SIAM Journal on Applied Dynamical Systems, 19(1):412–441, 2020
work page 2020
-
[33]
A. Garbuno-Inigo, N. Nüsken, and S. Reich. Affine invariant interacting Langevin dynamics for Bayesian inference.SIAM Journal on Applied Dynamical Systems, 19(3):1633–1658, 2020
work page 2020
-
[34]
Gautschi.A Survey of Gauss-Christoffel Quadrature Formulae
W. Gautschi.A Survey of Gauss-Christoffel Quadrature Formulae. Birkhauser Verlag, 1981
work page 1981
-
[35]
A. Gelman and J. Hill.Data analysis using regression and multilevel/hierarchical models. Cambridge university press, 2006
work page 2006
-
[36]
N. J. Gerber, F. Hoffmann, and U. Vaes. Mean-field limits for Consensus-Based Optimization and Sampling.ESAIM: Control, Optimisation and Calculus of Variations, 31:74, 2025. ISSN 1292-8119, 1262-3377. 12
work page 2025
-
[37]
C. J. Geyer and E. A. Thompson. Annealing Markov Chain Monte Carlo with Applications to Ancestral Inference.Journal of the American Statistical Association, September 1995
work page 1995
- [38]
-
[39]
G. H. Golub and J. H. Welsch. Calculation of Gauss quadrature rules.Mathematics of computation, 23(106):221–230, 1969
work page 1969
-
[40]
J. Goodman and J. Weare. Ensemble samplers with affine invariance.Communications in Applied Mathematics and Computational Science, 5(1):65–80, 2010. doi: 10.2140/camcos. 2010.5.65
-
[41]
J. Gorham and L. Mackey. Measuring sample quality with kernels. InProceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 1292–1301. PMLR, August 2017
work page 2017
-
[42]
H. Haario, M. Laine, A. Mira, and E. Saksman. DRAM: Efficient adaptive MCMC.Statistics and Computing, 16(4):339–354, 2006. doi: 10.1007/s11222-006-9438-0
-
[43]
S. Hayakawa, H. Oberhauser, and T. Lyons. Positively weighted kernel quadrature via subsam- pling.Advances in Neural Information Processing Systems, 35:6886–6900, 2022
work page 2022
-
[44]
S. Hayakawa, H. Oberhauser, and T. Lyons. Sampling-based Nyström approximation and kernel quadrature. InInternational Conference on Machine Learning, pages 12678–12699. PMLR, 2023
work page 2023
-
[45]
Y . He, K. Balasubramanian, B. K. Sriperumbudur, and J. Lu. Regularized Stein variational gradient flow.Foundations of Computational Mathematics, 25(4):1199–1257, 2025
work page 2025
-
[46]
F. Hickernell. A generalized discrepancy and quadrature error bound.Mathematics of computa- tion, 67(221):299–322, 1998
work page 1998
-
[47]
D. M. Himmelblau.Applied Nonlinear Programming. McGraw-Hill, New York, 1972. ISBN 978-0-07-028921-5
work page 1972
-
[48]
M. D. Hoffman and A. Gelman. The No-U-Turn sampler: Adaptively setting path lengths in Hamiltonian Monte Carlo.Journal of Machine Learning Research, 15(1):1593–1623, 2014
work page 2014
- [49]
-
[50]
F. Igea and A. Cicirello. Cyclical Variational Bayes Monte Carlo for efficient multi-modal posterior distributions evaluation.Mechanical Systems and Signal Processing, 186:109868, March 2023. ISSN 08883270
work page 2023
- [51]
-
[52]
Gaussian Processes and Kernel Methods: A Review on Connections and Equivalences
M. Kanagawa, P. Hennig, D. Sejdinovic, and B. K. Sriperumbudur. Gaussian processes and kernel methods: A review on connections and equivalences.arXiv preprint arXiv:1807.02582, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[53]
T. Karvonen, S. Särkkä, and K. Tanaka. Kernel-based interpolation at approximate Fekete points.Numerical Algorithms, 87:445–468, 2021
work page 2021
-
[54]
J. Kennedy and R. Eberhart. Particle swarm optimization. InProceedings of ICNN’95 - International Conference on Neural Networks, volume 4, pages 1942–1948, 1995
work page 1942
- [55]
-
[56]
A. Korba, P.C. Aubin-Frankowski, S. Majewski, and P. Ablin. Kernel Stein discrepancy descent. InInternational Conference on Machine Learning, pages 5719–5730. PMLR, 2021. 13
work page 2021
-
[57]
M. Koß, S. Weissmann, and J. Zech. On the Mean-Field Limit of Consensus-Based Methods. Mathematical Methods in the Applied Sciences, page mma.70343, November 2025. ISSN 0170-4214, 1099-1476
work page 2025
-
[58]
Q. Liu. Stein variational gradient descent as gradient flow.Advances in neural information processing systems, 30, 2017
work page 2017
- [59]
-
[60]
Q. Liu, J. Lee, and M. Jordan. A kernelized Stein discrepancy for goodness-of-fit tests. In International conference on machine learning, pages 276–284. PMLR, 2016
work page 2016
-
[61]
T. Liu, P. Ghosal, K. Balasubramanian, and N. Pillai. Towards understanding the dynamics of Gaussian-Steinvariational gradient descent.Advances in Neural Information Processing Systems, 36:61234–61291, 2023
work page 2023
-
[62]
M. Magnusson, P. Bürkner, and A. Vehtari. posteriordb: a set of posteriors for Bayesian inference and probabilistic programming, October 2023
work page 2023
-
[63]
A. Maurais and Y . Marzouk. Sampling in unit time with kernel Fisher–Rao flow. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 35138–35162. PMLR, 21–27 Jul 2024
work page 2024
-
[64]
K. Muandet, K. Fukumizu, B. Sriperumbudur, B. Schölkopf, et al. Kernel mean embedding of distributions: A review and beyond.Foundations and Trends® in Machine Learning, 10(1-2): 1–141, 2017
work page 2017
-
[65]
R. M. Neal.Bayesian Learning for Neural Networks. Springer-Verlag, Berlin, Heidelberg,
-
[66]
R. M. Neal. Slice sampling.The Annals of Statistics, 31(3), June 2003. ISSN 0090-5364. doi: 10.1214/aos/1056562461
- [67]
-
[68]
C. P. Robert, G. Casella, and G. Casella.Monte Carlo statistical methods, volume 2. Springer, 1999
work page 1999
-
[69]
G. O. Roberts and R. L. Tweedie. Exponential convergence of Langevin distributions and their discrete approximations.Bernoulli, 2(4):341–363, 1996
work page 1996
- [70]
-
[71]
F. Santambrogio. {Euclidean, metric, and Wasserstein} gradient flows: an overview.Bulletin of Mathematical Sciences, 7:87–154, 2017
work page 2017
- [72]
-
[73]
C. M. Stein. Estimation of the mean of a multivariate normal distribution.The annals of Statistics, pages 1135–1151, 1981
work page 1981
-
[74]
L. Sun, A. Karagulyan, and P. Richtarik. Convergence of Stein variational gradient descent under a weaker smoothness condition. InInternational Conference on Artificial Intelligence and Statistics, pages 3693–3717. PMLR, 2023
work page 2023
-
[75]
G. Toscani. Kinetic models of opinion formation.Communications in Mathematical Sciences, 4(3):481–496, 2006. 14
work page 2006
-
[76]
L. Wang and N. Nüsken. Measure transport with kernel mean embeddings.arXiv preprint arXiv:2401.12967, 2024
- [77]
-
[78]
J. Zhuo, C. Liu, J. Shi, J. Zhu, N. Chen, and B. Zhang. Message passing stein variational gradient descent. InInternational Conference on Machine Learning, pages 6018–6027. PMLR, 2018. 15 A Numerics A.1 The algorithm Algorithm 1:Regularized MSIP Input:Densityπ, step sizeη, number of iterationsT, regularization parameterλ, hybridization rate γ, inner quadr...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.