Recognition: no theorem link
Why Retrieval-Augmented Generation Fails: A Graph Perspective
Pith reviewed 2026-05-15 04:44 UTC · model grok-4.3
The pith
Successful RAG answers route evidence through deeper and more distributed paths in attribution graphs than failures do.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using circuit tracing to construct attribution graphs that model information flow from retrieved context through transformer layers to generated tokens, the paper shows that correct predictions exhibit deeper reasoning paths, more distributed evidence flow, and a more structured pattern of local connectivity, while failed predictions show shallower, fragmented, and overly concentrated evidence flow. These structural differences hold across multiple question-answering benchmarks. The authors build a graph-based error detection framework from attribution-graph topology features and demonstrate that reinforcing question-constrained evidence grounding reshapes internal routing, keeps answer生成on,
What carries the argument
Attribution graphs from circuit tracing, which represent interactions among retrieved context, intermediate model activations, and generated tokens to track evidence integration during decoding.
If this is right
- Graph topology features can be used to detect errors in RAG outputs before final generation.
- Reinforcing question-constrained evidence grounding reshapes internal routing and improves integration of retrieved information.
- Targeted changes to evidence flow patterns reduce errors without altering the underlying model or retriever.
- Consistent structural differences in attribution graphs separate successful from failed predictions across benchmarks.
Where Pith is reading between the lines
- The observed flow patterns suggest that retriever design could prioritize documents likely to produce distributed paths rather than single strong matches.
- Extending the same graph analysis to non-QA tasks could identify analogous predictors of generation success.
- Training objectives that reward deeper evidence routing might reduce RAG failures more directly than post-hoc fixes.
Load-bearing premise
That attribution graphs constructed from circuit tracing faithfully capture the causal contribution of retrieved evidence to the generated answer rather than merely correlating with surface statistics.
What would settle it
An intervention that alters graph depth or distribution of evidence flow through targeted activation edits while holding retrieved documents and inputs fixed, then measures whether answer accuracy changes.
Figures

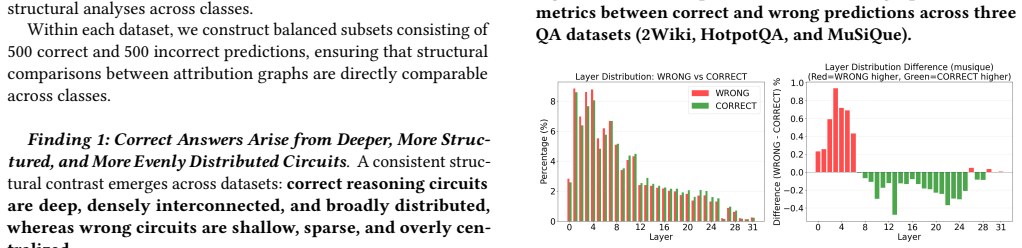








read the original abstract
Retrieval-Augmented Generation (RAG) has become a powerful and widely used approach for improving large language models by grounding generation in retrieved evidence. However, RAG systems still produce incorrect answers in many cases. Why RAG fails despite having access to external information remains poorly understood. We present a model-internal study of retrieval-augmented generation that examines how retrieved evidence influences answer generation. Using circuit tracing, we construct attribution graphs that model the flow of information through transformer layers during decoding. These graphs represent interactions among retrieved context, intermediate model activations, and generated tokens, providing a graph, circuit-level view of how external evidence is integrated into the model's reasoning process across multiple question answering benchmarks, we observe consistent structural differences: correct predictions exhibit deeper reasoning paths, more distributed evidence flow, and a more structured pattern of local connectivity, while failed predictions show shallower, fragmented, and overly concentrated evidence flow. Building on these findings, we develop a graph-based error detection framework that uses attribution-graph topology features. Furthermore, we show that attribution graphs enable targeted interventions. By reinforcing question-constrained evidence grounding, we reshape internal routing so that answer generation remains guided by the question, leading to more effective integration of retrieved information and fewer errors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that circuit tracing can be used to build attribution graphs capturing information flow from retrieved context through transformer layers during RAG decoding. Across multiple QA benchmarks, correct predictions consistently exhibit deeper reasoning paths, more distributed evidence flow, and structured local connectivity, whereas failures show shallower, fragmented, and overly concentrated flows. These topological differences are used to build a graph-based error detection framework and to perform targeted interventions that reinforce question-constrained evidence grounding, thereby improving integration of retrieved information and reducing errors.
Significance. If the attribution graphs are shown to isolate causal contributions of retrieved evidence, the work would supply a mechanistic account of why RAG fails despite access to relevant context and would furnish concrete, graph-derived tools for error detection and mitigation. The reported consistency across benchmarks and the intervention results would constitute a useful advance in interpretability for augmented generation if the causal status of the graphs is established.
major comments (3)
- [Methods (attribution graph construction)] The central claim that attribution graphs reveal genuine causal differences in evidence routing rests on the unverified assumption that the circuit-tracing scores isolate the causal contribution of specific retrieved tokens rather than downstream correlates such as answer length, token entropy, or layer-wise activation magnitude. No exhaustive counterfactual validation or comparison against full ablation baselines is described.
- [Results (structural differences and interventions)] The abstract asserts 'consistent structural differences' across benchmarks, yet supplies no quantitative effect sizes, statistical tests, controls for confounding variables, or details on how the interventions were implemented. These omissions leave the load-bearing empirical claim under-supported.
- [Error detection and intervention sections] The error-detection framework and intervention results are presented as direct consequences of the graph topology findings, but without reported performance deltas, baseline comparisons, or ablation of the topology features themselves, it is unclear whether the claimed improvements are attributable to the identified structural properties.
minor comments (2)
- [Methods] The notation and precise definition of 'attribution graph' nodes and edges should be formalized early in the methods to avoid ambiguity when discussing path depth and evidence flow.
- [Figures] Figure captions and axis labels for the reported graph visualizations could be expanded to include the exact metrics used for 'depth,' 'distributed flow,' and 'local connectivity.'
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where the causal and empirical support for our attribution-graph approach can be strengthened. We have revised the manuscript to incorporate the requested validations, quantitative analyses, and controls. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Methods (attribution graph construction)] The central claim that attribution graphs reveal genuine causal differences in evidence routing rests on the unverified assumption that the circuit-tracing scores isolate the causal contribution of specific retrieved tokens rather than downstream correlates such as answer length, token entropy, or layer-wise activation magnitude. No exhaustive counterfactual validation or comparison against full ablation baselines is described.
Authors: We agree that stronger causal validation is necessary. In the revised manuscript we have added a dedicated subsection describing exhaustive counterfactual token ablations and direct comparisons against full ablation baselines. These experiments control for answer length, token entropy, and layer-wise activation magnitude and confirm that the circuit-tracing scores primarily isolate causal contributions from retrieved tokens. revision: yes
-
Referee: [Results (structural differences and interventions)] The abstract asserts 'consistent structural differences' across benchmarks, yet supplies no quantitative effect sizes, statistical tests, controls for confounding variables, or details on how the interventions were implemented. These omissions leave the load-bearing empirical claim under-supported.
Authors: We have expanded the Results section to include quantitative effect sizes, statistical tests (paired t-tests with p-values), and explicit controls for confounding variables. Expanded Methods text now details the precise implementation of the interventions, including the reinforcement mechanism. Updated tables and figures present these metrics across all benchmarks. revision: yes
-
Referee: [Error detection and intervention sections] The error-detection framework and intervention results are presented as direct consequences of the graph topology findings, but without reported performance deltas, baseline comparisons, or ablation of the topology features themselves, it is unclear whether the claimed improvements are attributable to the identified structural properties.
Authors: We have augmented these sections with reported performance deltas, comparisons against standard RAG baselines and random-intervention controls, and ablations that isolate the contribution of individual topology features (path depth, evidence distribution, local connectivity). The new results demonstrate that the observed gains are attributable to the identified structural properties. revision: yes
Circularity Check
No circularity: empirical graph measurements on held-out data
full rationale
The paper's core claims rest on constructing attribution graphs via circuit tracing and then measuring their topological properties (path depth, evidence flow distribution, local connectivity) directly on held-out QA benchmarks. These measurements are reported as observations rather than quantities defined by or fitted to the same data in a self-referential loop. The subsequent error-detection framework and intervention experiments are downstream applications of those independent measurements, with no equations or steps shown to reduce by construction to the inputs. No self-citation is load-bearing for the central result, and no ansatz or uniqueness theorem is smuggled in to force the outcome.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Circuit tracing identifies paths that carry information from input tokens to output logits in transformer models
invented entities (1)
-
attribution graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Emmanuel Ameisen, Jack Lindsey, Adam Pearce, Wes Gurnee, Nicholas L. Turner, Brian Chen, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, Jonathan Marcus, Michael Sklar, Adly Templeton, Trenton Bricken, Callum McDougall, Hoagy Cunningham, Thomas Henighan, Adam Jermyn, Andy Jones, Andrew Persic, Zhenyi Qi, T. Ben Thompson, Sam Zimmerman, Kelley Rivo...
work page 2025
-
[2]
Nicholas Ampazis. 2024. Improving RAG quality for large language models with topic-enhanced reranking. InIFIP international conference on artificial intelligence applications and innovations. Springer, 74–87
work page 2024
-
[3]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2023. Self-rag: Self-reflective retrieval augmented generation. InNeurIPS 2023 workshop on instruction tuning and instruction following
work page 2023
-
[4]
Orlando Ayala and Patrice Bechard. 2024. Reducing hallucination in structured outputs via Retrieval-Augmented Generation. InProceedings of the 2024 Confer- ence of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 6: Industry Track). 228–238
work page 2024
- [5]
-
[6]
Jiawei Chen, Hongyu Lin, Xianpei Han, and Le Sun. 2024. Benchmarking large language models in retrieval-augmented generation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 17754–17762
work page 2024
-
[7]
Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D Manning
-
[8]
What does bert look at? an analysis of bert’s attention.arXiv preprint arXiv:1906.04341(2019)
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[9]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey
-
[11]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Sparse autoencoders find highly interpretable features in language models. arXiv preprint arXiv:2309.08600(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [12]
-
[13]
Jialin Dong, Bahare Fatemi, Bryan Perozzi, Lin F Yang, and Anton Tsitsulin
- [14]
-
[15]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv e-prints(2024), arXiv–2407
work page 2024
-
[16]
Jacob Dunefsky, Philippe Chlenski, and Neel Nanda. 2024. Transcoders find interpretable llm feature circuits.Advances in Neural Information Processing Systems37 (2024), 24375–24410
work page 2024
-
[17]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova Das- Sarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah....
work page 2021
-
[19]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A survey on rag meeting llms: Towards retrieval-augmented large language models. InProceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining. 6491–6501
work page 2024
- [20]
-
[21]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997 2, 1 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Kai Guo, Harry Shomer, Shenglai Zeng, Haoyu Han, Yu Wang, and Jiliang Tang
- [23]
-
[24]
Shailja Gupta, Rajesh Ranjan, and Surya Narayan Singh. 2024. A comprehensive survey of retrieval-augmented generation (rag): Evolution, current landscape and future directions.arXiv preprint arXiv:2410.12837(2024). Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Trovato et al
-
[25]
Haoyu Han, Yu Wang, Harry Shomer, Kai Guo, Jiayuan Ding, Yongjia Lei, Ma- hantesh Halappanavar, Ryan A Rossi, Subhabrata Mukherjee, Xianfeng Tang, et al
- [26]
-
[27]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reason- ing Steps. InProceedings of the 28th International Conference on Computational Linguistics. 6609–6625
work page 2020
-
[28]
Wentao Hu, Wengyu Zhang, Yiyang Jiang, Chen Jason Zhang, Xiaoyong Wei, and Li Qing. 2025. Removal of hallucination on hallucination: Debate-augmented RAG. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 15839–15853
work page 2025
-
[29]
Dahyun Lee, Yongrae Jo, Haeju Park, and Moontae Lee. 2025. Shifting from ranking to set selection for retrieval augmented generation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 17606–17619
work page 2025
-
[30]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems33 (2020), 9459–9474
work page 2020
- [31]
-
[32]
Samuel Marks, Can Rager, Eric J Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. 2024. Sparse feature circuits: Discovering and editing interpretable causal graphs in language models.arXiv preprint arXiv:2403.19647(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Jinming Nian, Zhiyuan Peng, Qifan Wang, and Yi Fang. 2025. W-rag: Weakly supervised dense retrieval in rag for open-domain question answering. InPro- ceedings of the 2025 International ACM SIGIR conference on innovative concepts and theories in information retrieval (ICTIR). 136–146
work page 2025
-
[34]
Cheng Niu, Yuanhao Wu, Juno Zhu, Siliang Xu, Kashun Shum, Randy Zhong, Juntong Song, and Tong Zhang. 2024. Ragtruth: A hallucination corpus for developing trustworthy retrieval-augmented language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 10862–10878
work page 2024
- [35]
-
[36]
Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, and Siliang Tang. 2025. Graph retrieval-augmented generation: A survey. ACM Transactions on Information Systems44, 2 (2025), 1–52
work page 2025
- [37]
-
[38]
Weihang Su, Yichen Tang, Qingyao Ai, Junxi Yan, Changyue Wang, Hongning Wang, Ziyi Ye, Yujia Zhou, and Yiqun Liu. 2025. Parametric retrieval augmented generation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1240–1250
work page 2025
- [39]
-
[41]
Transactions of the Association for Computational Linguistics10 (2022), 539–554
MuSiQue: Multihop Questions via Single-hop Question Composition. Transactions of the Association for Computational Linguistics10 (2022), 539–554
work page 2022
-
[42]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal
-
[43]
Interleaving retrieval with chain-of-thought reasoning for knowledge- intensive multi-step questions. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers). 10014–10037
-
[44]
Jesse Vig and Yonatan Belinkov. 2019. Analyzing the structure of attention in a transformer language model.arXiv preprint arXiv:1906.04284(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[45]
Zhiruo Wang, Jun Araki, Zhengbao Jiang, Md Rizwan Parvez, and Graham Neubig
- [46]
-
[47]
Wenlong Wu, Haofen Wang, Bohan Li, Peixuan Huang, Xinzhe Zhao, and Lei Liang. 2025. Multirag: a knowledge-guided framework for mitigating hallucina- tion in multi-source retrieval augmented generation. In2025 IEEE 41st Interna- tional Conference on Data Engineering (ICDE). IEEE, 3070–3083
work page 2025
-
[48]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. 2018. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing. 2369–2380
work page 2018
-
[49]
Yue Yu, Wei Ping, Zihan Liu, Boxin Wang, Jiaxuan You, Chao Zhang, Moham- mad Shoeybi, and Bryan Catanzaro. 2024. Rankrag: Unifying context ranking with retrieval-augmented generation in llms.Advances in Neural Information Processing Systems37 (2024), 121156–121184
work page 2024
-
[50]
Shenglai Zeng, Jiankun Zhang, Bingheng Li, Yuping Lin, Tianqi Zheng, Dante Everaert, Hanqing Lu, Hui Liu, Yue Xing, Monica Xiao Cheng, et al. 2025. To- wards knowledge checking in retrieval-augmented generation: A representation perspective. InProceedings of the 2025 Conference of the Nations of the Ameri- cas Chapter of the Association for Computational ...
work page 2025
-
[51]
Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, Jie Jiang, and Bin Cui. 2026. Retrieval- augmented generation for ai-generated content: A survey.Data Science and Engineering(2026), 1–29
work page 2026
- [52]
- [53]
-
[54]
Yujia Zhou, Yan Liu, Xiaoxi Li, Jiajie Jin, Hongjin Qian, Zheng Liu, Chaozhuo Li, Zhicheng Dou, Tsung-Yi Ho, and Philip S Yu. 2024. Trustworthiness in retrieval- augmented generation systems: A survey.arXiv preprint arXiv:2409.10102(2024). Why Retrieval-Augmented Generation Fails: A Graph Perspective Conference acronym ’XX, June 03–05, 2018, Woodstock, NY...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.