Recognition: 2 theorem links
· Lean TheoremMAPLE: Latent Multi-Agent Play for End-to-End Autonomous Driving
Pith reviewed 2026-05-15 04:38 UTC · model grok-4.3
The pith
MAPLE trains end-to-end driving models in closed loop using latent multi-agent rollouts without external simulators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MAPLE performs independent control of the ego vehicle and nearby traffic agents in the latent space of a vision-language-action model, allowing them to react to each other over multiple time steps. This latent rollout supports closed-loop supervision through an initial supervised fine-tuning stage on ground-truth data followed by reinforcement learning that incorporates global and agent-specific rewards. The resulting model achieves state-of-the-art performance on the Bench2Drive benchmark by learning more realistic and diverse driving behaviors.
What carries the argument
latent multi-agent rollout which enables independent yet reactive control of multiple agents in the VLA model's latent space to simulate closed-loop dynamics for training
If this is right
- The model can handle reactive environments better than standard imitation learning approaches.
- Training scales without the need for external simulators or high visual fidelity requirements.
- Diversity rewards allow the generation of planning behaviors absent from logged data.
- Global and agent-specific rewards promote safety, progress, and realistic interactions in multi-agent scenes.
Where Pith is reading between the lines
- This latent-space approach might reduce the domain gap when transferring to real-world driving compared to simulator-based methods.
- Extending the framework to longer horizons or more agents could further enhance its applicability to complex urban scenarios.
- Combining MAPLE with online adaptation during deployment might address remaining distribution shifts.
Load-bearing premise
Latent space rollouts of the VLA model can accurately capture the reactive dynamics between the ego vehicle and other agents without external simulators or extra visual fidelity losses.
What would settle it
If evaluations on Bench2Drive or similar closed-loop tests show no improvement over baseline imitation learning methods, or if the generated rollouts fail to produce appropriate reactions to changes in other agents' behaviors.
Figures




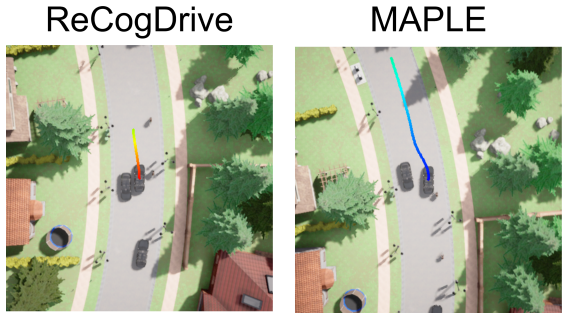




read the original abstract
Vision-language-action (VLA) models are effective as end-to-end motion planners, but can be brittle when evaluated in closed-loop settings due to being trained under traditional imitation learning framework. Existing closed-loop supervision approaches lack scalability and fail to completely model a reactive environment. We propose MAPLE, a novel framework for reactive, multi-agent rollout of a dynamic driving scenario in the latent space of the VLA model. The ego vehicle and nearby traffic agents are independently controlled over multi-step horizons, while being reactive to other agents in the scene, enabling closed-loop training. MAPLE consists of two training stages: (1) supervised fine-tuning on the latent rollouts based on ground-truth trajectories, followed by (2) reinforcement learning with global and agent -specific rewards that encourage safety, progress, and interaction realism. We further propose diversity rewards that encourage the model to generate planning behaviors that may not be present in logged driving data. Notably, our closed-loop training framework is scalable and does not require external simulators, which can be computationally expensive to run and have limited visual fidelity to the real-world. MAPLE achieves state-of-the-art driving performance on Bench2Drive and demonstrates scalable, closed-loop multi-agent play for robust E2E autonomous driving systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MAPLE, a two-stage framework for training vision-language-action (VLA) models for end-to-end autonomous driving. Stage 1 performs supervised fine-tuning on latent-space multi-agent rollouts generated from ground-truth trajectories, with the ego vehicle and nearby agents controlled independently over multi-step horizons while remaining reactive to each other. Stage 2 applies reinforcement learning using global and agent-specific rewards for safety, progress, interaction realism, and diversity. The method claims to enable scalable closed-loop training without external simulators and achieves state-of-the-art performance on the Bench2Drive benchmark.
Significance. If the latent rollouts are shown to faithfully reproduce reactive multi-agent dynamics, the approach would offer a scalable alternative to simulator-based closed-loop training for VLA models, potentially improving robustness over pure imitation learning while avoiding high computational costs and visual fidelity limitations of external simulators. The inclusion of diversity rewards to encourage behaviors beyond logged data is a positive element for exploration.
major comments (2)
- [Section 3] Section 3: The central claim that latent-space rollouts enable reactive multi-agent play for closed-loop RL rests on the unverified assumption that these rollouts accurately capture real-world dynamics. No quantitative validation is provided, such as prediction error metrics against ground-truth trajectories, distribution matching statistics, or ablation studies on rollout horizon length.
- [Section 3] Section 3: Without external grounding or visual fidelity losses, any reported SOTA on Bench2Drive could arise from reduced train-test mismatch within the model's latent biases rather than genuine reactivity gains; this requires explicit checks (e.g., closed-loop vs. open-loop performance deltas or cross-validation on held-out real trajectories) to support the scalability and robustness claims.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our work. We agree that stronger empirical validation of the latent rollouts' fidelity would better support the central claims. We address each major comment below and will incorporate the suggested analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Section 3] Section 3: The central claim that latent-space rollouts enable reactive multi-agent play for closed-loop RL rests on the unverified assumption that these rollouts accurately capture real-world dynamics. No quantitative validation is provided, such as prediction error metrics against ground-truth trajectories, distribution matching statistics, or ablation studies on rollout horizon length.
Authors: We acknowledge the value of direct quantitative validation. In the revision we will add (i) per-step and multi-step prediction error metrics (L2 displacement and heading error) between latent rollouts and ground-truth trajectories on held-out Bench2Drive sequences, (ii) distribution-matching statistics (e.g., Wasserstein distance on velocity and acceleration histograms), and (iii) an ablation table varying rollout horizon length (1, 3, 5, 8 steps) that reports both training stability and final closed-loop driving metrics. These additions will quantify how faithfully the latent dynamics reproduce reactive multi-agent behavior. revision: yes
-
Referee: [Section 3] Section 3: Without external grounding or visual fidelity losses, any reported SOTA on Bench2Drive could arise from reduced train-test mismatch within the model's latent biases rather than genuine reactivity gains; this requires explicit checks (e.g., closed-loop vs. open-loop performance deltas or cross-validation on held-out real trajectories) to support the scalability and robustness claims.
Authors: We will include two new experiments in the revision: (1) a direct closed-loop versus open-loop comparison on the full Bench2Drive test set, reporting the performance delta attributable to our multi-agent RL stage, and (2) cross-validation results on a held-out set of real-world trajectories (distinct from the training distribution) that measure both open-loop imitation accuracy and closed-loop success rate. These checks will demonstrate that the observed SOTA gains stem from improved reactivity rather than latent-space overfitting. revision: yes
Circularity Check
No significant circularity in MAPLE derivation chain
full rationale
The paper presents a two-stage pipeline of supervised fine-tuning on ground-truth latent trajectories followed by RL with hand-designed rewards for safety, progress, interaction realism, and diversity. No equations appear in the manuscript that would reduce any claimed prediction or performance gain to a fitted parameter or input by construction. The latent multi-agent rollout is introduced as a novel mechanism without invoking self-citation load-bearing uniqueness theorems or ansatzes smuggled from prior author work. The central claims rest on empirical Bench2Drive results rather than any self-referential redefinition of inputs as outputs, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction (8-tick period) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
rollout horizon of T=8 ... NR=8 for reactive-agent planners
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MAPLE consists of two training stages: (1) supervised fine-tuning on the latent rollouts ... (2) reinforcement learning with global and agent-specific rewards
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Learning dexterous in-hand manipulation
Marcin Andrychowicz, Bowen Baker, Maciek Chociej, Rafal Józefowicz, Bob McGrew, Jakub Pachocki, Arthur Petron, Matthias Plappert, Glenn Powell, Alex Ray, et al. Learning dexterous in-hand manipulation. The International Journal of Robotics Research, 39(1):3–20, 2020
work page 2020
-
[2]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report.ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
SimNet: Learning reactive self-driving simulations from real-world observations
Luca Bergamini, Yawei Ye, Oliver Scheel, Long Chen, Chih-Yuan Hu, Luca Delévaux, Niels Muller, and Peter Ondruska. SimNet: Learning reactive self-driving simulations from real-world observations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021
work page 2021
-
[5]
Killian, Stuart Bowers, Ozan Sener, Philipp Kraehenbuehl, and Vladlen Koltun
Marco Cusumano-Towner, David Hafner, Alexander Hertzberg, Brody Huval, Aleksei Petrenko, Eugene Vinitsky, Erik Wijmans, Taylor W. Killian, Stuart Bowers, Ozan Sener, Philipp Kraehenbuehl, and Vladlen Koltun. Robust autonomy emerges from self-play. InProceedings of the 42nd International Conference on Machine Learning (ICML), 2025
work page 2025
-
[6]
Parting with misconceptions about learning-based vehicle motion planning
Daniel Dauner, Marcel Hallgarten, Andreas Geiger, and Kashyap Chitta. Parting with misconceptions about learning-based vehicle motion planning. InConference on Robot Learning, pages 1268–1281. PMLR, 2023
work page 2023
-
[7]
Carla: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. Carla: An open urban driving simulator. InConference on robot learning, pages 1–16. PMLR, 2017
work page 2017
-
[8]
Eva: Exploring the limits of masked visual representation learning at scale
Yuxin Fang, Wen Wang, Binhui Xie, Quan Sun, Ledell Wu, Xinggang Wang, Tiejun Huang, Xinlong Wang, and Yue Cao. Eva: Exploring the limits of masked visual representation learning at scale. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19358–19369, 2023
work page 2023
-
[9]
Haoyu Fu, Diankun Zhang, Zongchuang Zhao, Jianfeng Cui, Dingkang Liang, Chong Zhang, Dingyuan Zhang, Hongwei Xie, Bing Wang, and Xiang Bai. Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation.arXiv preprint arXiv:2503.19755, 2025
-
[10]
Cole Gulino, Justin Fu, Wenjie Luo, George Tucker, Eli Bronstein, Yiren Lu, Jean Harb, Xinlei Pan, Yan Wang, Xiangyu Chen, John D. Co-Reyes, Rishabh Agarwal, Rebecca Roelofs, Yao Lu, Nico Montali, Paul Mougin, Zoey Yang, Brandyn White, Aleksandra Faust, Rowan McAllister, Dragomir Anguelov, and Benjamin Sapp. Waymax: An accelerated, data-driven simulator f...
work page 2023
- [11]
-
[12]
Social force model for pedestrian dynamics.Physical Review E, 51(5): 4282–4286, 1995
Dirk Helbing and Péter Molnár. Social force model for pedestrian dynamics.Physical Review E, 51(5): 4282–4286, 1995
work page 1995
-
[13]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17853–17862, 2023
work page 2023
-
[14]
Zhiyu Huang, Xinshuo Weng, Maximilian Igl, Yuxiao Chen, Yulong Cao, Boris Ivanovic, Marco Pavone, and Chen Lv. Gen-drive: Enhancing diffusion generative driving policies with reward modeling and reinforcement learning fine-tuning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 3445–3451. IEEE, 2025
work page 2025
-
[15]
EMMA: End-to-End Multimodal Model for Autonomous Driving
Jyh-Jing Hwang, Runsheng Xu, Hubert Lin, Wei-Chih Hung, Jingwei Ji, Kristy Choi, Di Huang, Tong He, Paul Covington, Benjamin Sapp, Yin Zhou, James Guo, Dragomir Anguelov, and Mingxing Tan. Emma: End-to-end multimodal model for autonomous driving.arXiv preprint arXiv:2410.23262, 2024
work page internal anchor Pith review arXiv 2024
-
[16]
Carl: Learning scalable planning policies with simple rewards.arXiv preprint arXiv:2504.17838, 2025
Bernhard Jaeger, Daniel Dauner, Jens Beißwenger, Simon Gerstenecker, Kashyap Chitta, and Andreas Geiger. Carl: Learning scalable planning policies with simple rewards.arXiv preprint arXiv:2504.17838, 2025. 10
-
[17]
Xiaosong Jia, Yulu Gao, Li Chen, Junchi Yan, Patrick Langechuan Liu, and Hongyang Li. Driveadapter: Breaking the coupling barrier of perception and planning in end-to-end autonomous driving. InICCV, 2023
work page 2023
-
[18]
Think twice before driving: Towards scalable decoders for end-to-end autonomous driving
Xiaosong Jia, Penghao Wu, Li Chen, Jiangwei Xie, Conghui He, Junchi Yan, and Hongyang Li. Think twice before driving: Towards scalable decoders for end-to-end autonomous driving. InCVPR, 2023
work page 2023
-
[19]
Bench2drive: Towards multi- ability benchmarking of closed-loop end-to-end autonomous driving
Xiaosong Jia, Zhenjie Yang, Qifeng Li, Zhiyuan Zhang, and Junchi Yan. Bench2drive: Towards multi- ability benchmarking of closed-loop end-to-end autonomous driving. InNeurIPS 2024 Datasets and Benchmarks Track, 2024
work page 2024
-
[20]
Drivetransformer: Unified transformer for scalable end-to-end autonomous driving
Xiaosong Jia, Junqi You, Zhiyuan Zhang, and Junchi Yan. Drivetransformer: Unified transformer for scalable end-to-end autonomous driving. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[21]
Vad: Vectorized scene representation for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8340–8350, 2023
work page 2023
-
[22]
Bo Jiang, Shaoyu Chen, Bencheng Liao, Xingyu Zhang, Wei Yin, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. Senna: Bridging large vision-language models and end-to-end autonomous driving. arXiv preprint arXiv:2410.22313, 2024
-
[23]
Bo Jiang, Shaoyu Chen, Qian Zhang, Wenyu Liu, and Xinggang Wang. Alphadrive: Unleashing the power of vlms in autonomous driving via reinforcement learning and reasoning.arXiv preprint arXiv:2503.07608, 2025
-
[24]
Beyond behavior cloning in autonomous driving: a survey of closed-loop training techniques
Peter Karkus, Maximilian Igl, Yuxiao Chen, Kashyap Chitta, Boris Ivanovic, and Marco Pavone. Beyond behavior cloning in autonomous driving: a survey of closed-loop training techniques. Technical report, NVIDIA Research, 2025
work page 2025
-
[25]
A survey of generalisation in deep reinforcement learning.arXiv preprint arXiv:2111.09794, 2023
Roberta Kirk, Amy Zhang, Edward Grefenstette, and Tim Rocktäschel. A survey of generalisation in deep reinforcement learning.arXiv preprint arXiv:2111.09794, 2023
-
[26]
Derun Li, Jianwei Ren, Yue Wang, Xin Wen, Pengxiang Li, Leimeng Xu, Kun Zhan, Zhongpu Xia, Peng Jia, Xianpeng Lang, et al. Finetuning generative trajectory model with reinforcement learning from human feedback.arXiv preprint arXiv:2503.10434, 2025
-
[27]
Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving
Yongkang Li, Kaixin Xiong, Xiangyu Guo, Fang Li, Sixu Yan, Gangwei Xu, Lijun Zhou, Long Chen, Haiyang Sun, Bing Wang, et al. Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving. InInternational Conference on Learning Representations (ICLR), 2026
work page 2026
-
[28]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving
Bencheng Liao, Shaoyu Chen, Haoran Yin, Bo Jiang, Cheng Wang, Sixu Yan, Xinbang Zhang, Xiangyu Li, Ying Zhang, Qian Zhang, et al. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12037–12047, 2025
work page 2025
-
[29]
Haochen Liu, Tianyu Li, Haohan Yang, Li Chen, Caojun Wang, Ke Guo, Haochen Tian, Hongchen Li, Hongyang Li, and Chen Lv. Reinforced refinement with self-aware expansion for end-to-end autonomous driving.arXiv preprint arXiv:2506.09800, 2025
-
[30]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
work page 2019
-
[31]
Gpt-driver: Learning to drive with gpt.arXiv preprint arXiv:2310.01415, 2023a
Jiageng Mao, Yuxi Qian, Junjie Ye, Hang Zhao, and Yue Wang. Gpt-driver: Learning to drive with gpt. arXiv preprint arXiv:2310.01415, 2023
-
[32]
Generating useful accident- prone driving scenarios via a learned traffic prior
Davis Rempe, Jonah Philion, Leonidas J Guibas, Sanja Fidler, and Or Litany. Generating useful accident- prone driving scenarios via a learned traffic prior. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
work page 2022
-
[33]
Simlingo: Vision-only closed-loop autonomous driving with language-action alignment
Katrin Renz, Long Chen, Elahe Arani, and Oleg Sinavski. Simlingo: Vision-only closed-loop autonomous driving with language-action alignment. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 11993–12003, 2025
work page 2025
-
[34]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Shaoshuai Shi, Li Jiang, Dengxin Dai, and Bernt Schiele. Motion transformer with global intention localization and local movement refinement.arXiv preprint arXiv:2209.13508, 2022
-
[36]
Mastering the game of Go without human knowledge.Nature, 550:354–359, 2017
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. Mastering the game of Go without human knowledge.Nature, 550:354–359, 2017
work page 2017
-
[37]
Don’t shake the wheel: Momentum-aware planning in end-to-end autonomous driving
Ziying Song, Caiyan Jia, Lin Liu, Hongyu Pan, Yongchang Zhang, Junming Wang, Xingyu Zhang, Shaoqing Xu, Lei Yang, and Yadan Luo. Don’t shake the wheel: Momentum-aware planning in end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22432–22441, 2025
work page 2025
-
[38]
TrafficSim: Learning to simulate realistic multi-agent behaviors
Simon Suo, Sebastian Regalado, Sergio Casas, and Raquel Urtasun. TrafficSim: Learning to simulate realistic multi-agent behaviors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10400–10409, 2021
work page 2021
-
[39]
Yingqi Tang, Zhuoran Xu, Zhaotie Meng, and Erkang Cheng. Hip-ad: Hierarchical and multi-granularity planning with deformable attention for autonomous driving in a single decoder. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 25605–25615, 2025
work page 2025
-
[40]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Chenxu Hu, Yang Wang, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models.arXiv preprint arXiv:2402.12289, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Grandmaster level in StarCraft II using multi-agent reinforcement learning.Nature, 575:350–354, 2019
Oriol Vinyals, Igor Babuschkin, Wojciech M Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David H Choi, Richard Powell, Timo Ewalds, et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning.Nature, 575:350–354, 2019
work page 2019
-
[42]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[43]
Penghao Wu, Xiaosong Jia, Li Chen, Junchi Yan, Hongyang Li, and Yu Qiao. Trajectory-guided con- trol prediction for end-to-end autonomous driving: A simple yet strong baseline.Advances in Neural Information Processing Systems, 35:6119–6132, 2022
work page 2022
-
[44]
Zebin Xing, Xingyu Zhang, Yang Hu, Bo Jiang, Tong He, Qian Zhang, Xiaoxiao Long, and Wei Yin. Goalflow: Goal-driven flow matching for multimodal trajectories generation in end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1602–1611, 2025
work page 2025
-
[45]
Generative scenario rollouts for end-to-end autonomous driving.arXiv preprint arXiv:2601.11475, 2026
Rajeev Yasarla, Deepti Hegde, Shizhong Han, Hsin-Pai Cheng, Yunxiao Shi, Meysam Sadeghigooghari, Shweta Mahajan, Apratim Bhattacharyya, Litian Liu, Risheek Garrepalli, et al. Generative scenario rollouts for end-to-end autonomous driving.arXiv preprint arXiv:2601.11475, 2026
-
[46]
Liuhan Yin, Runkun Ju, Guodong Guo, and Erkang Cheng. Diffrefiner: Coarse to fine trajectory planning via diffusion refinement with semantic interaction for end to end autonomous driving. InProceedings of the AAAI Conference on Artificial Intelligence, pages 12009–12017, 2026
work page 2026
-
[47]
CAT: Closed-loop adversarial training for safe end-to-end driving
Linrui Zhang, Zhenghao Peng, Quanyi Li, and Bolei Zhou. CAT: Closed-loop adversarial training for safe end-to-end driving. InConference on Robot Learning, 2023
work page 2023
-
[48]
Yinan Zheng, Ruiming Liang, Kexin Zheng, Jinliang Zheng, Liyuan Mao, Jianxiong Li, Weihao Gu, Rui Ai, Shengbo Eben Li, Xianyuan Zhan, et al. Diffusion-based planning for autonomous driving with flexible guidance.arXiv preprint arXiv:2501.15564, 2025
-
[49]
Query-centric trajectory prediction
Zikang Zhou, Jianping Wang, Yung-Hui Li, and Yu-Kai Huang. Query-centric trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17863– 17873, 2023
work page 2023
-
[50]
Zewei Zhou, Tianhui Cai, Seth Z Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma. Au- tovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning.arXiv preprint arXiv:2506.13757, 2025. 12 A Ablation Study A.1 Number of Reactive Agents Agent Distribution in Bench2Drive.To contextualize...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.