Recognition: no theorem link
AudioMosaic: Contrastive Masked Audio Representation Learning
Pith reviewed 2026-05-15 01:48 UTC · model grok-4.3
The pith
AudioMosaic learns stronger audio representations by contrasting structured masked spectrogram patches rather than reconstructing them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By constructing positive pairs through structured time-frequency masking on spectrogram patches, AudioMosaic enables contrastive learning to produce more discriminative utterance-level representations than generative reconstruction objectives, while using less memory and supporting efficient large-batch training.
What carries the argument
Structured time-frequency masking applied to spectrogram patches to generate positive pairs for contrastive learning.
If this is right
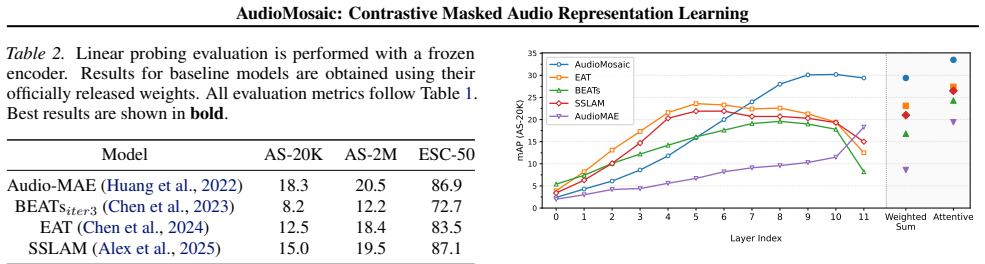
- The encoder achieves state-of-the-art linear-probing accuracy on multiple standard audio benchmarks.
- The encoder achieves state-of-the-art fine-tuning accuracy on the same benchmarks.
- Representations transfer across datasets, acoustic domains, and recording conditions.
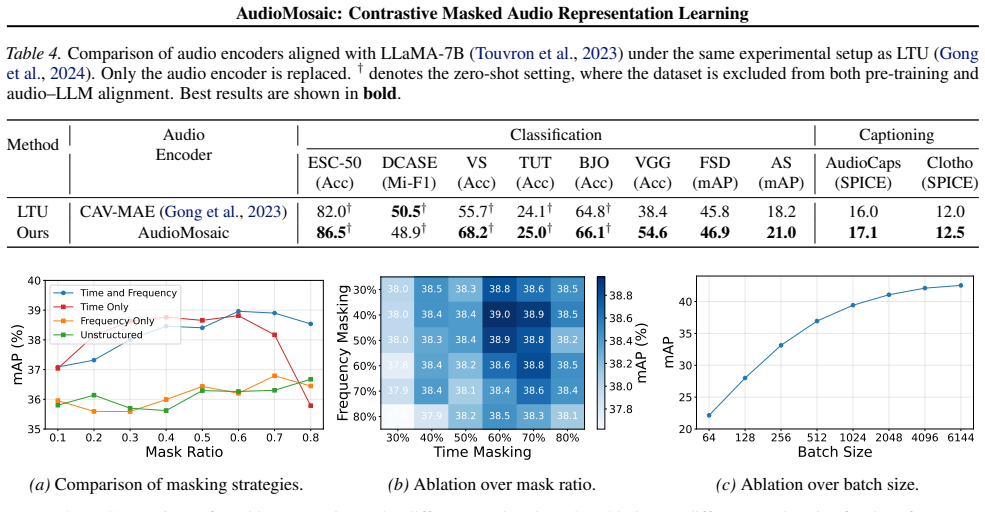
- Integration of the pretrained encoder improves downstream audio-language task performance.
Where Pith is reading between the lines
- The masking recipe may transfer to other sequential signals such as video frames or sensor time series where patch-based contrastive pairs are easy to form.
- Lower memory use could make contrastive pre-training practical for researchers without access to very large GPU clusters.
- Hybrid objectives that combine this contrastive masking with limited reconstruction might further stabilize training on noisy audio corpora.
Load-bearing premise
Structured time-frequency masking on spectrogram patches produces positive pairs effective enough for contrastive learning to outperform generative reconstruction without complex augmentations or impractically large batches.
What would settle it
An experiment that trains AudioMosaic and a generative baseline on identical data and model size and finds the generative model superior on the same linear-probing and fine-tuning benchmarks would falsify the central claim.
Figures


read the original abstract
Audio self-supervised learning (SSL) aims to learn general-purpose representations from large-scale unlabeled audio data. While recent advances have been driven mainly by generative reconstruction objectives, contrastive approaches remain less explored, partly due to the difficulty of designing effective audio augmentations and the large batch sizes required for contrastive pre-training. We introduce \textbf{AudioMosaic}, a contrastive learning-based audio encoder for general audio understanding. During pre-training, AudioMosaic constructs positive pairs by applying structured time-frequency masking to spectrogram patches, which reduces memory usage and enables efficient large-batch training. Compared with generative approaches, the AudioMosaic encoder learns more discriminative utterance-level representations that demonstrate strong transferability across datasets, domains, and acoustic conditions. Extensive experiments show that AudioMosaic achieves state-of-the-art performance on several standard audio benchmarks under both linear probing and fine-tuning. We further show that integrating the pretrained AudioMosaic encoder into audio-language models improves performance on audio-language tasks. The code is publicly available in our \href{https://github.com/HanxunH/AudioMosaic}{GitHub repository}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AudioMosaic, a contrastive SSL framework for audio that constructs positive pairs via structured time-frequency masking applied to spectrogram patches. This design is claimed to enable efficient large-batch training without complex augmentations, yielding more discriminative utterance-level representations than generative baselines. The manuscript reports SOTA results on standard audio benchmarks under linear probing and fine-tuning, plus gains when the encoder is integrated into audio-language models.
Significance. If the empirical results hold under rigorous validation, the work would be significant for audio SSL: it offers a parameter-efficient contrastive alternative to reconstruction-based pre-training, potentially lowering the barrier to large-batch training while improving transfer across domains and acoustic conditions. The public code release further strengthens reproducibility.
major comments (2)
- [§3] §3 (pre-training design): The description of 'structured time-frequency masking' provides no derivation, ablation, or analysis demonstrating that the resulting views preserve semantic content across acoustic conditions while introducing sufficient variation to prevent collapse under InfoNCE. Without this, the central claim that the masking produces effective positive pairs superior to generative objectives rests on unverified assumptions.
- [§4] §4 (experiments): The SOTA assertions on multiple benchmarks under linear probing and fine-tuning lack reported baselines, statistical tests, ablation studies on masking ratio/patch geometry, or error bars. These details are load-bearing for the transferability and discriminativeness claims and must be supplied with concrete numbers and controls.
minor comments (2)
- [Abstract] Abstract: The phrase 'reduces memory usage' is vague; quantify the memory savings relative to standard contrastive baselines.
- [§3] Notation: Define the exact masking procedure (patch size, ratio, time vs. frequency structure) with an equation or pseudocode in the main text rather than deferring entirely to the appendix.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the pre-training design and experimental validation. We have revised the manuscript to incorporate additional theoretical analysis, ablations, baselines, statistical tests, and error bars as requested, which we believe strengthens the central claims.
read point-by-point responses
-
Referee: [§3] §3 (pre-training design): The description of 'structured time-frequency masking' provides no derivation, ablation, or analysis demonstrating that the resulting views preserve semantic content across acoustic conditions while introducing sufficient variation to prevent collapse under InfoNCE. Without this, the central claim that the masking produces effective positive pairs superior to generative objectives rests on unverified assumptions.
Authors: We appreciate this point. While the original manuscript relied primarily on downstream empirical validation to support the effectiveness of the masking strategy, we agree that explicit analysis strengthens the contribution. In the revised version, §3 has been expanded with a derivation grounded in mutual information preservation: structured contiguous time-frequency masking retains local spectro-temporal patterns essential for semantic content (e.g., formants and onsets) while varying global context to avoid collapse. We added ablation tables varying masking ratio (0.3–0.7) and patch geometry, reporting positive-pair cosine similarity and InfoNCE loss to demonstrate non-collapse, plus qualitative spectrogram examples across clean/noisy conditions. revision: yes
-
Referee: [§4] §4 (experiments): The SOTA assertions on multiple benchmarks under linear probing and fine-tuning lack reported baselines, statistical tests, ablation studies on masking ratio/patch geometry, or error bars. These details are load-bearing for the transferability and discriminativeness claims and must be supplied with concrete numbers and controls.
Authors: We agree these elements are necessary for rigorous validation. The revised §4 now includes: complete numerical tables comparing against all cited baselines (AudioMAE, BEATs, etc.) with exact scores; t-test p-values (<0.05) and means ± std over 5 seeds for linear probing and fine-tuning results; dedicated ablation tables for masking ratio and patch geometry with performance deltas; and error bars on all main figures. These additions directly support the transferability and discriminativeness claims with concrete controls. revision: yes
Circularity Check
No circularity: empirical contrastive method with independent experimental validation
full rationale
The paper's central contribution is an empirical pre-training procedure that applies structured time-frequency masking to spectrogram patches to form positive pairs for a standard contrastive (InfoNCE-style) objective. No equations, parameters, or performance claims are shown to reduce by construction to fitted inputs, self-citations, or renamed known results. The SOTA claims rest on benchmark evaluations under linear probing and fine-tuning, which are externally falsifiable and do not rely on any load-bearing self-citation chain or uniqueness theorem imported from the authors' prior work. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Blankemeier, L., Baur, S., Weng, W.-H., Garrison, J., Ma- tias, Y ., Prabhakara, S., Ardila, D., and Nabulsi, Z. Optimizing audio augmentations for contrastive learn- ing of health-related acoustic signals.arXiv preprint arXiv:2309.05843,
-
[2]
A-jepa: Joint-embedding predictive architecture can listen.arXiv preprint arXiv:2311.15830,
Fei, Z., Fan, M., and Huang, J. A-jepa: Joint-embedding predictive architecture can listen.arXiv preprint arXiv:2311.15830,
-
[3]
Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models
Goel, A., Ghosh, S., Kim, J., Kumar, S., Kong, Z., Lee, S.-g., Yang, C.-H. H., Duraiswami, R., Manocha, D., Valle, R., et al. Audio flamingo 3: Advancing audio intelligence with fully open large audio language models. arXiv preprint arXiv:2507.08128,
work page internal anchor Pith review arXiv
-
[4]
Ast: Audio spectro- gram transformer
Gong, Y ., Chung, Y .-A., and Glass, J. Ast: Audio spectro- gram transformer. InProc. Interspeech 2021,
2021
-
[5]
Sheet: A multi- purpose open-source speech human evaluation estimation toolkit
Huang, W.-C., Cooper, E., and Toda, T. Sheet: A multi- purpose open-source speech human evaluation estimation toolkit. InProc. Interspeech 2025,
2025
-
[6]
H., Wang, Z., Yang, S., Mai, Y ., Zhou, Y ., Xie, C., and Liang, P
Lee, T., Tu, H., Wong, C. H., Wang, Z., Yang, S., Mai, Y ., Zhou, Y ., Xie, C., and Liang, P. Ahelm: A holistic evaluation of audio-language models.arXiv preprint arXiv:2508.21376,
-
[7]
K., Schuldt, C., and Chatterjee, S
Liang, X., Cumlin, F., Ungureanu, V ., Reddy, C. K., Schuldt, C., and Chatterjee, S. Selection of layers from self- supervised learning models for predicting mean-opinion- score of speech.arXiv preprint arXiv:2508.08962,
-
[8]
Acoustic scene classification: an overview of dcase 2017 challenge en- tries
Mesaros, A., Heittola, T., and Virtanen, T. Acoustic scene classification: an overview of dcase 2017 challenge en- tries. InInternational Workshop on Acoustic Signal En- hancement,
2017
-
[9]
Niizumi, D., Takeuchi, D., Ohishi, Y ., Harada, N., and Kashino, K. Masked spectrogram modeling using masked autoencoders for learning general-purpose audio repre- sentation.arXiv preprint arXiv:2204.12260,
-
[10]
Oord, A. v. d., Li, Y ., and Vinyals, O. Representation learn- ing with contrastive predictive coding.arXiv preprint arXiv:1807.03748,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
The kaldi speech recognition toolkit
Povey, D., Ghoshal, A., Boulianne, G., Burget, L., Glembek, O., Goel, N., Hannemann, M., Motlicek, P., Qian, Y ., Schwarz, P., et al. The kaldi speech recognition toolkit. InIEEE 2011 workshop on automatic speech recognition and understanding,
2011
-
[12]
Unmute the patch tokens: Rethinking probing in multi-label audio classification
Rauch, L., Heinrich, R., Ghaffari, H., Miklautz, L., Moum- mad, I., Sick, B., and Scholz, C. Unmute the patch tokens: Rethinking probing in multi-label audio classification. arXiv preprint arXiv:2509.24901,
-
[13]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation lan- guage models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition
Warden, P. Speech commands: A dataset for limited-vocabulary speech recognition.arXiv preprint arXiv:1804.03209,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Yang, S.-w., Chi, P.-H., Chuang, Y .-S., Lai, C.-I. J., Lakho- tia, K., Lin, Y . Y ., Liu, A. T., Shi, J., Chang, X., Lin, G.-T., et al. Superb: Speech processing universal performance benchmark.arXiv preprint arXiv:2105.01051,
-
[16]
Yin, H., Xiao, Y ., Das, R. K., Bai, J., and Dang, T. Esdd 2026: Environmental sound deepfake detection challenge evaluation plan.arXiv preprint arXiv:2508.04529, 2025a. Yin, H., Xiao, Y ., Das, R. K., Bai, J., Liu, H., Wang, W., and Plumbley, M. D. Envsdd: Benchmarking environmental sound deepfake detection. InProc. Interspeech 2025, 2025b. Zhai, R., Liu...
-
[17]
Experimental Settings Table 6 summarizes the detailed experimental settings for both pre-training and fine-tuning, while Table 7 reports the settings used for linear probing
14 AudioMosaic: Contrastive Masked Audio Representation Learning A. Experimental Settings Table 6 summarizes the detailed experimental settings for both pre-training and fine-tuning, while Table 7 reports the settings used for linear probing. Table 8 further details the augmentations applied prior to spectrogram masking to generate two distinct views of t...
2018
-
[18]
on fine-grained details. In particular, AudioMosaic enables the model to capture details that are missed when using the original CA V-MAE encoder (Gong et al., 2023), as well as additional details that are not explicitly mentioned in the reference captions but have been verified by the authors. 15 AudioMosaic: Contrastive Masked Audio Representation Learn...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.