Recognition: no theorem link
Dynamics of the Transformer Residual Stream: Coupling Spectral Geometry to Network Topology
Pith reviewed 2026-05-15 02:34 UTC · model grok-4.3
The pith
Training installs a monotonic spectral gradient in LLMs from non-normal early layers to near-symmetric late layers, creating a low-rank bottleneck for perturbations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
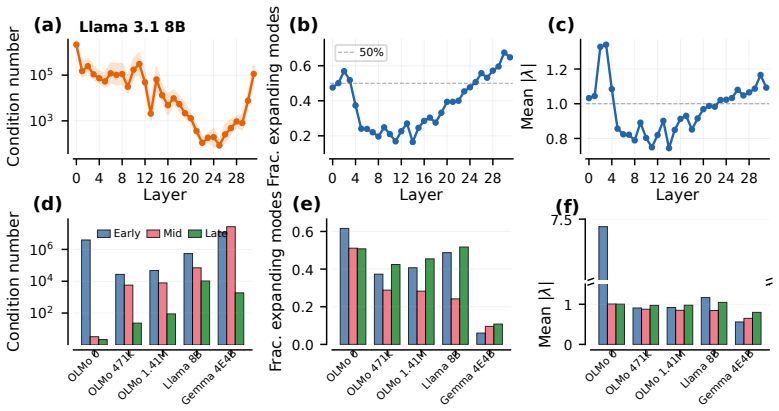
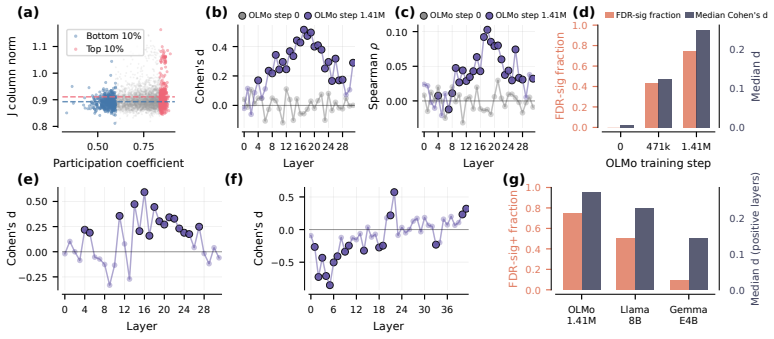
Training in production-scale large language models installs a monotonic spectral gradient through depth, moving from non-normal, rotation-dominated early layers to near-symmetric late layers, together with a cumulative low-rank bottleneck that funnels perturbations into a small fraction of the residual stream's effective dimensions. The topological positioning of graph communities predicts whether the Jacobian amplifies or suppresses them, with the sign of the coupling determined by the local operator type; this relationship is absent at initialization.
What carries the argument
The full Jacobian eigendecomposition at each layer, which maps the spectral geometry of perturbation propagation and couples it to the network's graph community topology.
Load-bearing premise
The Jacobian provides a faithful linear approximation to how actual nonlinear layer updates propagate perturbations, and the graph communities detected have functional significance independent of the spectral analysis.
What would settle it
Running a full nonlinear simulation of small input perturbations through the trained model and finding that their evolution does not match the predictions from the Jacobian eigendecompositions at each layer.
Figures






read the original abstract
Large language models are remarkably capable, yet how computation propagates through their layers remains poorly understood. A growing line of work treats depth as discrete time and the residual stream as a dynamical system, where each layer's nonlinear update has a local linear description. However, previous analyses have relied on scalar summaries or approximate linearizations, leaving the full spectral geometry of trained LLMs unknown. We perform full Jacobian eigendecomposition across three production--scale LLMs and show that training installs a monotonic spectral gradient through depth -- from non-normal, rotation-dominated early layers to near--symmetric late layers -- together with a cumulative low-rank bottleneck that funnels perturbations into a small fraction of the residual stream's effective dimensions. Our experiments reveal that this gradient and the dimensional collapse are learned rather than architectural, and is largely dissolved when structured non-normality is removed. We further show that the topological positioning of graph communities predicts whether the Jacobian amplifies or suppresses them, with the sign of the coupling determined by the local operator type, a relationship absent at initialization. These results map a learned spectral geometry in LLMs that links perturbation propagation and compression to the network's functional topology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that training installs a monotonic spectral gradient through transformer depth—from non-normal, rotation-dominated early layers to near-symmetric late layers—along with a cumulative low-rank bottleneck that funnels perturbations into few effective dimensions of the residual stream. It further claims that graph-community topology predicts whether the per-layer Jacobian amplifies or suppresses perturbations, with sign set by local operator type, and that both the gradient and the topology-coupling are learned (absent at initialization). These conclusions rest on full Jacobian eigendecompositions performed across three production-scale LLMs.
Significance. If the central claims hold, the work supplies a concrete empirical map of learned spectral geometry in LLMs that ties perturbation dynamics and dimensional collapse directly to functional topology. The use of complete eigendecomposition rather than scalar summaries on three large models is a clear technical strength and moves the field beyond prior approximate linearizations. The demonstration that the reported relationships are training-induced rather than architectural also supplies a falsifiable prediction that future work can test.
major comments (3)
- [§4.2] §4.2 (Jacobian linearization): the dynamical interpretation of the monotonic gradient, low-rank bottleneck, and community amplification/suppression requires that the first-order Jacobian product accurately tracks finite perturbation evolution across multiple nonlinear layers, yet the manuscript contains no forward-pass validation or divergence metric comparing linear predictions to actual residual-stream trajectories for perturbations of realistic magnitude.
- [§4.3] §4.3 and Table 3 (community coupling): the claim that topological positioning predicts Jacobian sign is load-bearing for the topology-geometry link, but the manuscript reports no ablation on the community-detection algorithm itself nor any quantitative test that the detected communities remain functionally independent of the Jacobian analysis pipeline.
- [§5.1] §5.1 (learned vs. architectural): the assertion that the spectral gradient and low-rank bottleneck are dissolved when structured non-normality is removed is central to the 'learned' conclusion, yet the manuscript supplies neither the precise intervention used to remove non-normality nor error bars on the resulting dissolution across the three models.
minor comments (2)
- [Figure 4] Figure 4 caption: the color scale for amplification/suppression is not numerically labeled, making it impossible to read the magnitude of the reported coupling without consulting the main text.
- [§3.1] Notation in §3.1: the symbol for the cumulative product of Jacobians is introduced without an explicit equation number, forcing the reader to reconstruct the multi-layer operator from surrounding prose.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify key areas where additional validation and clarification will strengthen the manuscript's claims regarding the learned spectral properties and their coupling to network topology. We address each major comment point by point below.
read point-by-point responses
-
Referee: §4.2 (Jacobian linearization): the dynamical interpretation of the monotonic gradient, low-rank bottleneck, and community amplification/suppression requires that the first-order Jacobian product accurately tracks finite perturbation evolution across multiple nonlinear layers, yet the manuscript contains no forward-pass validation or divergence metric comparing linear predictions to actual residual-stream trajectories for perturbations of realistic magnitude.
Authors: We agree that validating the linear approximation against finite nonlinear perturbations is essential to support the dynamical interpretations. The original analysis centered on the spectral geometry of the Jacobians, but the revised manuscript will include new forward-pass experiments that compare linear predictions to actual residual-stream trajectories over multiple layers. These will use perturbations of realistic magnitudes drawn from activation statistics and report quantitative divergence metrics such as relative L2 error and cosine similarity between predicted and observed states. revision: yes
-
Referee: §4.3 and Table 3 (community coupling): the claim that topological positioning predicts Jacobian sign is load-bearing for the topology-geometry link, but the manuscript reports no ablation on the community-detection algorithm itself nor any quantitative test that the detected communities remain functionally independent of the Jacobian analysis pipeline.
Authors: We acknowledge that robustness to the community detection procedure and independence from the Jacobian pipeline were not demonstrated. In the revision we will add an ablation study varying the resolution parameter of the Louvain algorithm and comparing results against spectral clustering. We will also include a quantitative independence test, such as mutual information between community assignments and Jacobian-derived quantities computed on held-out data, to confirm that the detected communities are not artifacts of the analysis pipeline. revision: yes
-
Referee: §5.1 (learned vs. architectural): the assertion that the spectral gradient and low-rank bottleneck are dissolved when structured non-normality is removed is central to the 'learned' conclusion, yet the manuscript supplies neither the precise intervention used to remove non-normality nor error bars on the resulting dissolution across the three models.
Authors: The referee is correct that the precise intervention and statistical reporting were insufficiently detailed. The revised §5.1 will specify the exact procedure: symmetrizing each weight matrix while preserving its Frobenius norm, with full pseudocode. We will also report the dissolution of the spectral gradient and low-rank bottleneck with error bars computed over multiple random seeds for the symmetrization step, across all three models. revision: yes
Circularity Check
No circularity; central claims are empirical measurements from Jacobian eigendecomposition
full rationale
The paper performs full Jacobian eigendecomposition on trained LLMs to observe a monotonic spectral gradient from non-normal early layers to near-symmetric late layers, plus a cumulative low-rank bottleneck and topology-dependent amplification of graph communities. These are reported as learned empirical patterns absent at initialization, with no equations or derivations that reduce the claimed predictions to quantities defined by the same data or self-citations. The analysis relies on direct computation rather than fitted parameters renamed as predictions or ansatzes smuggled via prior work, making the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The residual stream update at each layer admits a local linear description via its Jacobian matrix whose eigendecomposition captures perturbation propagation.
- domain assumption Graph communities extracted from the network topology correspond to functionally meaningful groupings whose amplification or suppression can be read from the Jacobian spectrum.
Reference graph
Works this paper leans on
-
[1]
Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Yang, Amy and Fan, Angela and others , journal =. The. 2024 , annote =
work page 2024
-
[2]
arXiv preprint arXiv:2512.13961 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
International Conference on Learning Representations (ICLR) , year =
Pointer Sentinel Mixture Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[4]
and Waltman, Ludo and van Eck, Nees Jan , journal =
Traag, Vincent A. and Waltman, Ludo and van Eck, Nees Jan , journal =. From. 2019 , publisher =
work page 2019
-
[5]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Exponential Expressivity in Deep Neural Networks through Transient Chaos , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[6]
International Conference on Learning Representations (ICLR) , year =
Deep Information Propagation , author =. International Conference on Learning Representations (ICLR) , year =
-
[7]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Resurrecting the Sigmoid in Deep Learning through Dynamical Isometry: Theory and Practice , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[8]
Dynamical Isometry is Achieved in Residual Networks in a Universal Way for any Activation Function , author =. Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics (AISTATS) , pages =. 2019 , volume =
work page 2019
- [9]
-
[10]
arXiv preprint arXiv:2505.24293 , year =
Large Language Models are Locally Linear Mappings , author =. arXiv preprint arXiv:2505.24293 , year =
-
[11]
Transformer Block Coupling and its Correlation with Generalization in
Aubry, Murdock and Meng, Haoming and Sugolov, Anton and Papyan, Vardan , booktitle =. Transformer Block Coupling and its Correlation with Generalization in. 2025 , annote =
work page 2025
-
[12]
International Conference on Learning Representations (ICLR) , year =
Block Recurrent Dynamics in Vision Transformers , author =. International Conference on Learning Representations (ICLR) , year =
-
[13]
arXiv preprint arXiv:2203.12967 , year =
Extended Critical Regimes of Deep Neural Networks , author =. arXiv preprint arXiv:2203.12967 , year =
-
[14]
Journal of Mathematical Imaging and Vision , volume =
Deep Neural Networks Motivated by Partial Differential Equations , author =. Journal of Mathematical Imaging and Vision , volume =. 2020 , publisher =. doi:10.1007/s10851-019-00903-1 , annote =
-
[15]
Understanding and Improving Transformer From a Multi-Particle Dynamic System Point of View
Understanding and Improving Transformer From a Multi-Particle Dynamic System Point of View , author =. arXiv preprint arXiv:1906.02762 , year =
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[16]
arXiv preprint arXiv:2311.04930 , year =
Large Language Models Implicitly Learn to Straighten Neural Sentence Trajectories to Construct a Predictive Representation of Natural Language , author =. arXiv preprint arXiv:2311.04930 , year =
-
[17]
Storm, Ludvig and Linander, Hampus and Bec, J. Finite-Time. Physical Review Letters , volume =. 2024 , publisher =. doi:10.1103/PhysRevLett.132.057301 , annote =
-
[18]
Gradient Flossing: Improving Gradient Descent through Dynamic Control of
Engelken, Rainer , booktitle =. Gradient Flossing: Improving Gradient Descent through Dynamic Control of. 2023 , annote =
work page 2023
-
[19]
A mathematical perspective on transformers.CoRR, abs/2312.10794, 2023
A Mathematical Perspective on Transformers , author =. arXiv preprint arXiv:2312.10794 , year =
-
[20]
Residual Stream Analysis with Multi-Layer
Lawson, Tim and Farnik, Lucy and Houghton, Conor and Aitchison, Laurence , journal =. Residual Stream Analysis with Multi-Layer
-
[21]
arXiv preprint arXiv:2603.07162 , year =
Spectral Conditioning of Attention Improves Transformer Performance , author =. arXiv preprint arXiv:2603.07162 , year =
-
[22]
Parcae: Scaling Laws For Stable Looped Language Models
Parcae: Scaling Laws for Stable Looped Language Models , author =. arXiv preprint arXiv:2604.12946 , year =
work page internal anchor Pith review Pith/arXiv arXiv
- [23]
-
[24]
Transformer Circuits Thread , year =
A Mathematical Framework for Transformer Circuits , author =. Transformer Circuits Thread , year =
-
[25]
arXiv preprint arXiv:2604.01978 , year =
Homogenized Transformers , author =. arXiv preprint arXiv:2604.01978 , year =
-
[26]
Zoom In: An Introduction to Circuits , author =. Distill , volume =. 2020 , doi =
work page 2020
-
[27]
Transformer Circuits Thread , year =
On the Biology of a Large Language Model , author =. Transformer Circuits Thread , year =
-
[28]
In-context Learning and Induction Heads
In-context Learning and Induction Heads , author =. arXiv preprint arXiv:2209.11895 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author =. arXiv preprint arXiv:2309.08600 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Transformer Circuits Thread , year =
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author =. Transformer Circuits Thread , year =
-
[31]
Understanding intermediate layers using linear classifier probes
Understanding Intermediate Layers Using Linear Classifier Probes , author =. arXiv preprint arXiv:1610.01644 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Eliciting Latent Predictions from Transformers with the Tuned Lens , author =. arXiv preprint arXiv:2303.08112 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
arXiv preprint arXiv:2502.12131 , year =
Transformer Dynamics: A neuroscientific approach to interpretability of large language models , author =. arXiv preprint arXiv:2502.12131 , year =
-
[34]
arXiv preprint arXiv:2103.03386 , year =
Clusterability in Neural Networks , author =. arXiv preprint arXiv:2103.03386 , year =
-
[35]
Understanding Community Structure in Layered Neural Networks
Understanding Community Structure in Layered Neural Networks , author =. arXiv preprint arXiv:1804.04778 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Traag, V. A. and Van Dooren, P. and Nesterov, Y. , month = jul, year =. Narrow scope for resolution-limit-free community detection , volume =. 1104.3083 , doi =
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.