Recognition: 2 theorem links
· Lean TheoremRefining Pseudo-Audio Prompts with Speech-Text Alignment for Text-Only Domain Adaptation in LLM-Based ASR
Pith reviewed 2026-05-15 02:18 UTC · model grok-4.3
The pith
A speech-text alignment method generates expressive pseudo-audio prompts for effective text-only domain adaptation in LLM-based ASR, outperforming prior text-only approaches on error rates and OOV coverage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our method efficiently generates highly expressive pseudo-audio prompts that bridges the modality gap, enabling effective target-domain adaptation. Experiments demonstrate that our approach outperforms existing text-only methods, improving both overall error rates and out-of-vocabulary coverage.
Load-bearing premise
That explicitly modeling speech-text alignment during pseudo-audio prompt generation will produce prompts expressive enough to close the modality gap and yield measurable gains in target-domain ASR without any real audio from that domain.
Figures

read the original abstract
LLM-based automatic speech recognition models demonstrate strong performance by connecting audio encoders and LLMs. However, data scarcity of paired speech and transcription often hinders their adaptation to new domains, making text-only domain adaptation crucial. Existing methods typically rely on either fine-tuning the LLM alone or employing pseudo-audio prompts. The former neglects essential acoustic context, while the latter either suffers from limited scalability in data-scarce conditions, or yields inexpressive prompts by leveraging only textual features, ignoring audio modality. To address this, we propose an enhanced framework that explicitly models speech-text alignment. Our method efficiently generates highly expressive pseudo-audio prompts that bridges the modality gap, enabling effective target-domain adaptation. Experiments demonstrate that our approach outperforms existing text-only methods, improving both overall error rates and out-of-vocabulary coverage.
Editorial analysis
A structured set of objections, weighed in public.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
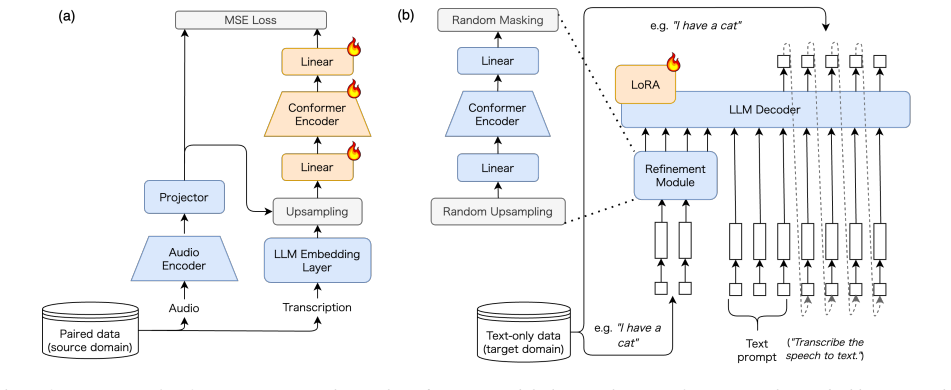
TE2SL ... inserts a learnable refinement module ... transforms upsampled token embeddings ... minimize the discrepancy ... frame-wise Mean Squared Error (MSE) loss ... between the generated prompts and the ground-truth audio prompts.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposed (TE2SL) ... consistently achieved the best recognition accuracy and the highest OOV Recall
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Introduction Large Language Models (LLMs) equipped with speech under- standing abilities have demonstrated significant progress in re- cent years, achieving high performance in speech-related tasks such as Automatic Speech Recognition (ASR) [1–5], speech translation [2–4, 6, 7], and dialogue [8, 9]. As illustrated in Fig- ure 1, these architectures typica...
-
[2]
Related Work 2.1. Text-only Fine-tuning without Audio Prompts The most straightforward approach for domain adaptation in- volves fine-tuning the LLM component using only target- domain text data [18]. Methods such as those designed for low-resource scenarios enable adaptation without the use of audio prompts. While these approaches allow the model to lear...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Methods 3.1. LLM-based ASR We follow an LLM-based ASR framework where the LLM is conditioned on an acoustic representation [1]. LetDbe the embedding dimension of the LLM,Lbe the length of the tran- scription, andL inst be the length of the instruction tokens. Let TandCbe the sequence length and feature dimension of the audio encoder output, andT ′ be the ...
-
[4]
Experiments In this section, we evaluate the effectiveness of the pro- posed TE2SL framework through a series of text-only domain adaptation experiments. To demonstrate the impact of our architecture-aware pseudo-audio prompts, we compared TE2SL against three representative strategies summarized in Table 1: (1) the non-adapted Baseline, (2) Soft Prompt [2...
-
[5]
Conclusion In this paper, we addressed text-only domain adaptation for LLM-based ASR by proposing Text-Embedding-to-Speech- Latent (TE2SL). Unlike methods relying only on heuristic em- bedding manipulation, TE2SL employs a learnable Conformer- based refinement module. This module synthesizes pseudo- audio prompts that are both sample-dependent and aware o...
-
[6]
Generative AI Use Disclosure During the preparation of this work, the authors used generative AI tools for the purpose of editing and polishing the manuscript to improve linguistic clarity and grammatical correctness. The authors reviewed and edited the content as needed and take full responsibility for the final version and content of the paper
-
[7]
Prompting large language models with speech recog- nition abilities,
Y . Fathullah, C. Wu, E. Lakomkin, J. Jia, Y . Shangguan, K. Li, J. Guo, W. Xiong, J. Mahadeokar, O. Kalinli, C. Fuegen, and M. Seltzer, “Prompting large language models with speech recog- nition abilities,” inICASSP, 2024, pp. 13 351–13 355
work page 2024
-
[8]
AudioPaLM: A Large Language Model That Can Speak and Listen
P. K. Rubenstein, C. Asawaroengchai, D. D. Nguyen, A. Bapna, Z. Borsos, F. de Chaumont Quitry, P. Chen, D. E. Badawy, W. Han, E. Kharitonovet al., “AudioPaLM: A large language model that can speak and listen,” 2023. [Online]. Available: https://arxiv.org/abs/2306.12925
work page internal anchor Pith review arXiv 2023
-
[9]
SALMONN: Towards generic hearing abilities for large language models,
C. Tang, W. Yu, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, Z. Ma, and C. Zhang, “SALMONN: Towards generic hearing abilities for large language models,” inICLR, 2024
work page 2024
-
[10]
WavLLM: Towards robust and adap- tive speech large language model,
S. Hu, L. Zhou, S. Liu, S. Chen, L. Meng, H. Hao, J. Pan, X. Liu, J. Li, S. Sivasankaranet al., “WavLLM: Towards robust and adap- tive speech large language model,” inFindings of EMNLP. As- sociation for Computational Linguistics, 2024, pp. 4552–4572
work page 2024
-
[11]
An embarrassingly simple approach for LLM with strong ASR capacity,
Z. Ma, G. Yang, Y . Yang, Z. Gao, J. Wang, Z. Du, F. Yu, Q. Chen, S. Zheng, S. Zhang, and X. Chen, “An embarrassingly simple approach for llm with strong asr capacity,” 2024. [Online]. Available: https://arxiv.org/abs/2402.08846
-
[12]
On decoder-only architecture for speech-to-text and large language model integration,
J. Wu, Y . Gaur, Z. Chen, L. Zhou, Y . Zhu, T. Wang, J. Li, S. Liu, B. Ren, L. Liu, and Y . Wu, “On decoder-only architecture for speech-to-text and large language model integration,” inASRU, 2023, pp. 1–8
work page 2023
-
[13]
SLM: Bridge the thin gap between speech and text foundation models,
M. Wang, W. Han, I. Shafran, Z. Wu, C.-C. Chiu, Y . Cao, N. Chen, Y . Zhang, H. Soltau, P. K. Rubenstein, L. Zilka, D. Yu, G. Pundak, N. Siddhartha, J. Schalkwyk, and Y . Wu, “SLM: Bridge the thin gap between speech and text foundation models,” inASRU, 2023, pp. 1–8
work page 2023
-
[14]
Audio Flamingo: A novel audio language model with few-shot learning and dialogue abilities,
Z. Kong, A. Goel, R. Badlani, W. Ping, R. Valle, and B. Catanzaro, “Audio Flamingo: A novel audio language model with few-shot learning and dialogue abilities,” inICML, 2024
work page 2024
-
[15]
LLaMA-Omni: Seamless speech interaction with large language models,
Q. Fang, S. Guo, Y . Zhou, Z. Ma, S. Zhang, and Y . Feng, “LLaMA-Omni: Seamless speech interaction with large language models,” inICLR, 2025
work page 2025
-
[16]
Integrating text inputs for training and adapting RNN transducer ASR mod- els,
S. Thomas, B. Kingsbury, G. Saon, and H.-K. J. Kuo, “Integrating text inputs for training and adapting RNN transducer ASR mod- els,” inICASSP, 2022, pp. 8127–8131
work page 2022
-
[17]
Internal language model adaptation with text-only data for end- to-end speech recognition,
Z. Meng, Y . Gaur, N. Kanda, J. Li, X. Chen, Y . Wu, and Y . Gong, “Internal language model adaptation with text-only data for end- to-end speech recognition,” inInterspeech, 2022, pp. 2608–2612
work page 2022
-
[18]
Efficient text-only domain adap- tation for CTC-based ASR,
C. Chen, X. Gong, and Y . Qian, “Efficient text-only domain adap- tation for CTC-based ASR,” inASRU, 2023, pp. 1–7
work page 2023
-
[19]
JOIST: A joint speech and text streaming model for asr,
T. N. Sainath, R. Prabhavalkar, A. Bapna, Y . Zhang, Z. Huo, Z. Chen, B. Li, W. Wang, and T. Strohman, “JOIST: A joint speech and text streaming model for asr,” inSLT, 2023, pp. 52–59
work page 2023
-
[20]
MAESTRO: Matched speech text repre- sentations through modality matching,
Z. Chen, Y . Zhang, A. Rosenberg, B. Ramabhadran, P. J. Moreno, A. Bapna, and H. Zen, “MAESTRO: Matched speech text repre- sentations through modality matching,” inInterspeech, 2022, pp. 4093–4097
work page 2022
-
[21]
Efficient domain adaptation for speech foundation models,
B. Li, D. Hwang, Z. Huo, J. Bai, G. Prakash, T. N. Sainath, K. Chai Sim, Y . Zhang, W. Han, T. Strohman, and F. Beaufays, “Efficient domain adaptation for speech foundation models,” in ICASSP, 2023, pp. 1–5
work page 2023
-
[22]
J. Zhu, W. Tong, Y . Xu, C. Song, Z. Wu, Z. You, D. Su, D. Yu, and H. Meng, “Text-only domain adaptation for end-to-end speech recognition through down-sampling acoustic representation,” in Interspeech, 2023, pp. 1334–1338
work page 2023
-
[23]
Text only domain adaptation with phoneme guided data splicing for end- to-end speech recognition,
W. Wang, X. Gong, H. Shao, D. Yang, and Y . Qian, “Text only domain adaptation with phoneme guided data splicing for end- to-end speech recognition,” inInterspeech 2023, 2023, pp. 3347– 3351
work page 2023
-
[24]
Low-resource domain adaptation for speech llms via text-only fine-tuning,
Y . Fang, J. Peng, X. Li, Y . Xi, C. Zhang, G. Zhong, and K. Yu, “Low-resource domain adaptation for speech llms via text-only fine-tuning,” 2025. [Online]. Available: https://arxiv.org/abs/2506.05671
-
[25]
Text-only domain adaptation for end-to-end ASR us- ing integrated text-to-mel-spectrogram generator,
V . Bataev, R. Korostik, E. Shabalin, V . Lavrukhin, and B. Gins- burg, “Text-only domain adaptation for end-to-end ASR us- ing integrated text-to-mel-spectrogram generator,” inInterspeech, 2023, pp. 2928–2932
work page 2023
-
[26]
Effective text adaptation for llm- based asr through soft prompt fine-tuning,
Y . Ma, Z. Liu, and O. Kalinli, “Effective text adaptation for llm- based asr through soft prompt fine-tuning,” inSLT, 2024, pp. 64– 69
work page 2024
-
[27]
Conformer: Convolution-augmented transformer for speech recognition,
A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y . Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y . Wu, and R. Pang, “Conformer: Convolution-augmented transformer for speech recognition,” in Interspeech, 2020, pp. 5036–5040
work page 2020
-
[28]
WavLM: Large- scale self-supervised pre-training for full stack speech process- ing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “WavLM: Large- scale self-supervised pre-training for full stack speech process- ing,”JSTSP, vol. 16, no. 6, pp. 1505–1518, 2022
work page 2022
-
[29]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan et al., “The Llama 3 herd of models,” 2024. [Online]. Available: https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
LoRA: Low-rank adaptation of large lan- guage models,
E. J. Hu, yelong shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large lan- guage models,” inICLR, 2022
work page 2022
-
[31]
Lib- rispeech: An asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: An asr corpus based on public domain audio books,” inICASSP, 2015, pp. 5206–5210
work page 2015
-
[32]
P. K. O’Neill, V . Lavrukhin, S. Majumdar, V . Noroozi, Y . Zhang, O. Kuchaiev, J. Balam, Y . Dovzhenko, K. Freyberg, M. D. Shul- man, B. Ginsburg, S. Watanabe, and G. Kucsko, “SPGISpeech: 5,000 hours of transcribed financial audio for fully formatted end- to-end speech recognition,” inInterspeech, 2021, pp. 1434–1438
work page 2021
-
[33]
SlideSpeech: A large scale slide-enriched audio-visual corpus,
H. Wang, F. Yu, X. Shi, Y . Wang, S. Zhang, and M. Li, “SlideSpeech: A large scale slide-enriched audio-visual corpus,” inICASSP, 2024, pp. 11 076–11 080
work page 2024
-
[34]
Corpus of spontaneous japanese: its design and evaluation,
K. Maekawa, “Corpus of spontaneous japanese: its design and evaluation,” inISCA/IEEE Workshop on Spontaneous Speech Pro- cessing and Recognition, 2003, p. paper MMO2
work page 2003
-
[35]
Decoupled weight decay regulariza- tion,
I. Loshchilov and F. Hutter, “Decoupled weight decay regulariza- tion,” inICLR, 2019
work page 2019
-
[36]
ESPnet: End-to-end speech processing toolkit,
S. Watanabe, T. Hori, S. Karita, T. Hayashi, J. Nishitoba, Y . Unno, N. Enrique Yalta Soplin, J. Heymann, M. Wiesner, N. Chen, A. Renduchintala, and T. Ochiai, “ESPnet: End-to-end speech processing toolkit,” inInterspeech, 2018, pp. 2207–2211
work page 2018
-
[37]
Applying conditional random fields to japanese morphological analysis,
T. Kudo, K. Yamamoto, and Y . Matsumoto, “Applying conditional random fields to japanese morphological analysis,” inEMNLP. Association for Computational Linguistics, 2004, pp. 230–237
work page 2004
-
[38]
S. Ueno, M. Mimura, S. Sakai, and T. Kawahara, “Multi-speaker sequence-to-sequence speech synthesis for data augmentation in acoustic-to-word speech recognition,” inICASSP, 2019, pp. 6161–6165
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.