CrystalReasoner: Reasoning and RL for Property-Conditioned Crystal Structure Generation
Pith reviewed 2026-05-19 16:44 UTC · model grok-4.3
The pith
CrystalReasoner generates more valid and stable crystal structures by inserting physical priors as reasoning steps before atomic coordinates and aligning the output with reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
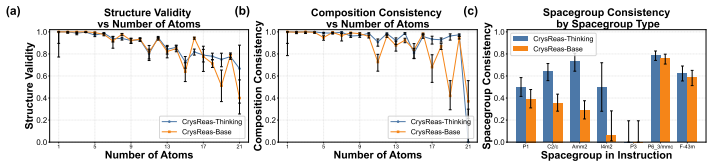
CrystalReasoner generates crystal structures from natural language instructions by first emitting thinking traces that encode crystallographic symmetry, local coordination environments, and predicted physical properties, then applying reinforcement learning with a multi-objective dense reward function to align the final atomic coordinates with physical validity, chemical consistency, and thermodynamic stability; task-specific reward functions further specialize the model for discrete constraints such as space groups and continuous properties such as elasticity or thermal expansion, producing higher performance on validity metrics and tripling the S.U.N. ratio relative to baselines that lack,
What carries the argument
Physical priors encoded as thinking tokens before coordinate generation, paired with multi-objective reinforcement learning that supplies dense rewards for validity, consistency, and stability.
If this is right
- Structures satisfy validity, uniqueness, and novelty criteria at roughly three times the rate of prior methods.
- Property-conditioned generation succeeds for both discrete constraints like space groups and continuous targets like elasticity without separate post-processing.
- Reasoning length automatically scales with the number of atoms, providing longer traces for more complex structures.
- Specialized models can be trained for individual property classes while sharing the same underlying reasoning and alignment pipeline.
Where Pith is reading between the lines
- Natural-language queries could become a practical interface for requesting crystal structures with user-specified functional properties, shortening the design loop in materials engineering.
- The same pattern of domain-specific reasoning tokens followed by RL alignment might transfer to other generative tasks that map language to three-dimensional atomic or molecular arrangements.
- Wider adoption would reduce reliance on large post-generation filtering stages, since more candidates already satisfy stability and property constraints at generation time.
Load-bearing premise
The multi-objective and task-specific reward functions accurately reflect real physical validity, chemical consistency, and thermodynamic stability without introducing evaluation biases that inflate the reported gains.
What would settle it
Recompute stability and property values for the generated structures using independent high-accuracy methods outside the reward model; if the fraction of structures meeting the original S.U.N. criteria drops substantially or property-matching accuracy falls to baseline levels, the performance advantage would not hold.
Figures






read the original abstract
Generative modeling has emerged as a promising approach for crystal structure discovery. However, existing LLM-based generative models struggle with low-level atomic precision, while diffusion-based methods fall short in integrating high-level scientific knowledge. As a result, generated structures are often invalid, unstable, or do not possess desirable properties. To address this gap, we propose CrystalReasoner (CrysReas), an end-to-end LLM framework that generates crystal structures from natural language instructions through reasoning and alignment. CrysReas introduces physical priors as thinking tokens, which include crystallographic symmetry, local coordination environments and predicted physical properties before generating atomic coordinates. This bridges the gap between natural language and 3D structures. CrysReas then employs reinforcement learning (RL) with a multi-objective, dense reward function to align generation with physical validity, chemical consistency, and thermodynamic stability. For property-conditioned tasks, we design task-specific reward functions and train specialized models for discrete constraints (e.g., space group) and continuous properties (e.g., elasticity, thermal expansion). Empirical results demonstrate that compared to prior works and baselines without thinking traces or RL, CrysReas obtains better performance on diverse metrics, triples S.U.N. ratio, and achieves better performance for property conditioned generation. CrysReas also exhibits adaptive reasoning, increasing reasoning lengths as the number of atoms increases. Our work demonstrates the potential of leveraging thinking traces and RL for generating valid, stable, and property-conditioned crystal structures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CrystalReasoner (CrysReas), an end-to-end LLM framework for generating crystal structures from natural language instructions. It incorporates physical priors as thinking tokens (crystallographic symmetry, local coordination environments, and predicted physical properties) before generating atomic coordinates, then applies reinforcement learning with a multi-objective dense reward function to enforce physical validity, chemical consistency, and thermodynamic stability. Task-specific rewards are designed for discrete (e.g., space group) and continuous (e.g., elasticity) property-conditioned generation. The central empirical claim is that CrysReas outperforms prior works and baselines without thinking traces or RL on diverse metrics, triples the S.U.N. ratio, achieves better property-conditioned performance, and exhibits adaptive reasoning lengths that increase with atom count.
Significance. If the empirical results hold under independent validation, the work could meaningfully advance crystal structure generation by combining high-level scientific reasoning traces with RL alignment, addressing limitations of pure diffusion models (low scientific integration) and standard LLMs (low atomic precision). The explicit use of physical priors and multi-objective rewards for validity/stability is a constructive direction; the reported adaptive reasoning behavior is a secondary strength worth highlighting.
major comments (2)
- [§3.2] §3.2 (Reward Function): The multi-objective dense reward and task-specific rewards are load-bearing for the central claim of tripling the S.U.N. ratio and superior property-conditioned results. The manuscript provides no quantitative breakdown of reward weights, no validation of individual terms (e.g., thermodynamic stability predictor) against independent DFT-relaxed energies or stricter symmetry checks, and no ablation removing post-hoc filters. This leaves open the possibility that gains are partly an artifact of reward shaping rather than intrinsic improvement from reasoning traces or RL.
- [§4.1] §4.1 (Baselines and Metrics): The claim of outperforming 'prior works and baselines without thinking traces or RL' is central to the empirical contribution, yet the paper lacks a detailed description of baseline adaptations, whether they use equivalent property predictors, and the precise definitions of S.U.N. ratio and other metrics (including error analysis or statistical tests). Without these, the reported superiority cannot be fully assessed.
minor comments (2)
- [Abstract] Abstract: The abstract asserts empirical superiority and tripling of the S.U.N. ratio without any quantitative values, baseline names, or error information; adding at least one key number and a brief metric definition would improve clarity.
- [§2] Notation: The term 'thinking tokens' is used throughout but its exact format and integration into the LLM prompt is not formalized in an equation or pseudocode; adding a concise definition in §2 or §3 would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments identify areas where additional methodological transparency would strengthen the paper. We address each major comment below and will revise the manuscript to incorporate the suggested clarifications and supporting analyses.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Reward Function): The multi-objective dense reward and task-specific rewards are load-bearing for the central claim of tripling the S.U.N. ratio and superior property-conditioned results. The manuscript provides no quantitative breakdown of reward weights, no validation of individual terms (e.g., thermodynamic stability predictor) against independent DFT-relaxed energies or stricter symmetry checks, and no ablation removing post-hoc filters. This leaves open the possibility that gains are partly an artifact of reward shaping rather than intrinsic improvement from reasoning traces or RL.
Authors: We agree that explicit documentation of the reward design is necessary for reproducibility and to address potential concerns about reward shaping. In the revised manuscript we will add a quantitative table listing all reward weights and their scaling factors. The thermodynamic stability predictor was trained on DFT energies from the Materials Project; we will include a new validation subsection comparing its outputs against an independent set of DFT-relaxed structures and stricter symmetry checks performed with spglib. We also conducted an ablation that disables post-hoc filters after generation; the results show that the S.U.N. ratio improvement and property-conditioned gains remain largely intact when only the reasoning traces and RL stage are active. These ablation results and the corresponding figures will be added to the supplementary material. revision: yes
-
Referee: [§4.1] §4.1 (Baselines and Metrics): The claim of outperforming 'prior works and baselines without thinking traces or RL' is central to the empirical contribution, yet the paper lacks a detailed description of baseline adaptations, whether they use equivalent property predictors, and the precise definitions of S.U.N. ratio and other metrics (including error analysis or statistical tests). Without these, the reported superiority cannot be fully assessed.
Authors: We acknowledge that the current description of the experimental protocol is insufficient for full assessment. In the revision we will expand §4.1 with a dedicated subsection detailing how each baseline was re-implemented or adapted, confirming that equivalent property predictors (when required) were used for fair comparison. We will also provide the exact definition of the S.U.N. ratio (structures that are thermodynamically stable, unique within the generated set, and novel relative to the training distribution) together with the numerical thresholds employed. Finally, we will report standard deviations across five independent runs and include paired t-test p-values to quantify statistical significance of the observed improvements. revision: yes
Circularity Check
No significant circularity; empirical framework relies on external priors without self-referential derivations
full rationale
The paper describes an LLM framework that injects physical priors as thinking tokens and uses RL with a multi-objective dense reward to align generations to validity and stability. No equations, uniqueness theorems, or derivation chains appear in the abstract or described content. The central claims rest on empirical comparisons to baselines and reported gains in S.U.N. ratio and property-conditioned tasks, which are evaluated against external physical and chemical criteria rather than reducing to fitted parameters or self-citations by construction. The method is therefore self-contained against independent benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- multi-objective reward weights
axioms (1)
- domain assumption Physical priors such as crystallographic symmetry and local coordination can be reliably encoded as intermediate thinking tokens that improve downstream coordinate generation.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CrysReas introduces physical priors as thinking tokens... RL with a multi-objective, dense reward function to align generation with physical validity, chemical consistency, and thermodynamic stability.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Rtarget = α_validity R_validity + α_stability 1_validity R_stability
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Junwu Chen, Jeff Guo, Edvin Fako, and Philippe Schwaller. Accelerating inverse materials design using generative diffusion models with reinforcement learning.arXiv preprint arXiv:2511.03112,
-
[2]
Run-Ze Fan, Zengzhi Wang, and Pengfei Liu. Megascience: Pushing the frontiers of post-training datasets for science reasoning.arXiv preprint arXiv:2507.16812,
-
[3]
Jingru Gan, Peichen Zhong, Yuanqi Du, Yanqiao Zhu, Chenru Duan, Haorui Wang, Daniel Schwalbe- Koda, Carla P Gomes, Kristin A Persson, and Wei Wang. Matllmsearch: Crystal structure discovery with evolution-guided large language models.arXiv preprint arXiv:2502.20933,
-
[4]
Fine-tuned language models generate stable inorganic materials as text
Nate Gruver, Anuroop Sriram, Andrea Madotto, Andrew Gordon Wilson, C Lawrence Zitnick, and Zachary Ulissi. Fine-tuned language models generate stable inorganic materials as text.arXiv preprint arXiv:2402.04379,
-
[5]
System of agentic ai for the discovery of metal-organic frameworks.arXiv preprint arXiv:2504.14110,
Theo Jaffrelot Inizan, Sherry Yang, Aaron Kaplan, Yen-hsu Lin, Jian Yin, Saber Mirzaei, Mona Abdelgaid, Ali H Alawadhi, KwangHwan Cho, Zhiling Zheng, et al. System of agentic ai for the discovery of metal-organic frameworks.arXiv preprint arXiv:2504.14110,
-
[6]
Space group constrained crystal generation.arXiv preprint arXiv:2402.03992,
Rui Jiao, Wenbing Huang, Yu Liu, Deli Zhao, and Yang Liu. Space group constrained crystal generation.arXiv preprint arXiv:2402.03992,
-
[7]
Chaitanya K Joshi, Xiang Fu, Yi-Lun Liao, Vahe Gharakhanyan, Benjamin Kurt Miller, Anuroop Sriram, and Zachary W Ulissi. All-atom diffusion transformers: Unified generative modelling of molecules and materials.arXiv preprint arXiv:2503.03965,
-
[8]
Wyckoffdiff–a generative diffusion model for crystal symmetry.arXiv preprint arXiv:2502.06485,
11 Filip Ekström Kelvinius, Oskar B Andersson, Abhijith S Parackal, Dong Qian, Rickard Armiento, and Fredrik Lindsten. Wyckoffdiff–a generative diffusion model for crystal symmetry.arXiv preprint arXiv:2502.06485,
-
[9]
Subhojyoti Khastagir, Kishalay Das, Pawan Goyal, Seung-Cheol Lee, Satadeep Bhattacharjee, and Niloy Ganguly. Llm meets diffusion: A hybrid framework for crystal material generation.arXiv preprint arXiv:2510.23040,
-
[10]
Qwen, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning,
Zayne Sprague, Fangcong Yin, Juan Diego Rodriguez, Dongwei Jiang, Manya Wadhwa, Prasann Singhal, Xinyu Zhao, Xi Ye, Kyle Mahowald, and Greg Durrett. To cot or not to cot? chain- of-thought helps mainly on math and symbolic reasoning.arXiv preprint arXiv:2409.12183,
-
[15]
Crys- tal diffusion variational autoencoder for periodic material generation
Tian Xie, Xiang Fu, Octavian-Eugen Ganea, Regina Barzilay, and Tommi Jaakkola. Crystal diffusion variational autoencoder for periodic material generation.arXiv preprint arXiv:2110.06197,
-
[16]
Andy Xu, Rohan Desai, Larry Wang, Gabriel Hope, and Ethan Ritz. Plaid++: A preference aligned language model for targeted inorganic materials design.arXiv preprint arXiv:2509.07150,
-
[17]
MatterSim: A Deep Learning Atomistic Model Across Elements, Temperatures and Pressures
Guang Yang, Yu Zhou, Xiang Chen, Xiangyu Zhang, Terry Yue Zhuo, and Taolue Chen. Chain-of- thought in neural code generation: From and for lightweight language models.IEEE Transactions on Software Engineering, 50(9):2437–2457, 2024a. Han Yang, Chenxi Hu, Yichi Zhou, Xixian Liu, Yu Shi, Jielan Li, Guanzhi Li, Zekun Chen, Shuizhou Chen, Claudio Zeni, et al....
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Mattergen: a generative model for inorganic materials design.arXiv preprint arXiv:2312.03687, 2023
Sherry Yang, Simon Batzner, Ruiqi Gao, Muratahan Aykol, Alexander Gaunt, Brendan McMorrow, Danilo Rezende, Dale Schuurmans, Igor Mordatch, and Ekin D Cubuk. Generative hierarchical materials search.Advances in Neural Information Processing Systems, 37:38799–38819, 2024c. Claudio Zeni, Robert Pinsler, Daniel Zügner, Andrew Fowler, Matthew Horton, Xiang Fu,...
-
[19]
[2013]) structures stored in our CrysReas database
13 A Experimental Details Data.All experiments are conducted on Materials Project (Jain et al. [2013]) structures stored in our CrysReas database. We use the CDV AE MP-20 split (Xie et al. [2021]) as the upstream data source. For supervised fine-tuning, we use split_cdvae.json, which contains 24,231 training structures and 8,141 test structures. We furthe...
work page 2013
-
[20]
The energy above the convex hull is 0.0. The band gap is 4.9995. Generate a description of the lengths and angles of the lattice vectors and then the element type and coordinates for each atom within the lattice: Assistant Response Let’s generate a material report first, according to the given information. Material Report: Crystal Structure First, conside...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.