Recognition: 2 theorem links
· Lean TheoremOptimal Pattern Detection Tree for Symbolic Rule-Based Classification
Pith reviewed 2026-05-15 02:41 UTC · model grok-4.3
The pith
The Optimal Pattern Detection Tree uses mixed-integer programming to identify a single optimal symbolic rule that maximizes coverage while minimizing false positives in binary classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
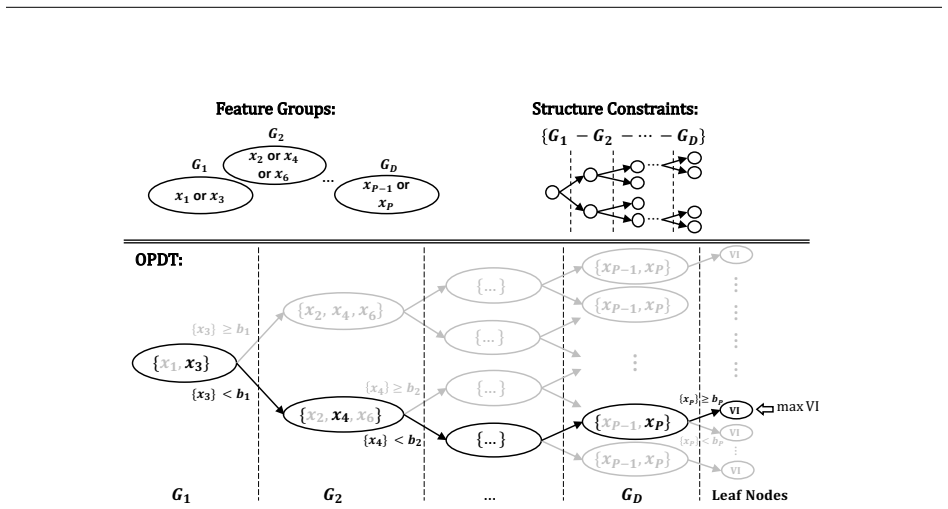
OPDT discovers a hidden underlying pattern in datasets, when it exists, by identifying an optimal rule that maximizes coverage while minimizing the false positive rate due to misclassification. The model is built through a novel mixed-integer programming formulation that constructs the decision tree structure. The Branching Structure Constraints framework further allows direct encoding of prior knowledge and compliance requirements into the branching decisions.
What carries the argument
The Optimal Pattern Detection Tree (OPDT), a decision tree whose structure and splits are chosen by a mixed-integer program to encode one optimal classification rule.
If this is right
- Yields human-interpretable rules with proven optimality for binary classification tasks.
- Allows direct insertion of domain constraints and compliance rules through the BSC framework.
- Applies directly to pattern discovery in healthcare, risk assessment, and equipment maintenance.
- Delivers results on moderate-sized datasets within practical computation limits.
Where Pith is reading between the lines
- Scaling beyond moderate sizes may require specialized solvers or decomposition techniques not explored here.
- Combining OPDT with ensemble methods could improve robustness while preserving interpretability.
- Applying the same formulation to multi-class or regression problems would test its generality beyond binary cases.
Load-bearing premise
The data contains exactly one hidden optimal pattern that the mixed-integer program can locate with exact optimality guarantees on moderately sized instances.
What would settle it
Running the solver on a dataset engineered with a known single optimal pattern and observing that it returns a suboptimal rule or fails to converge within reasonable time would disprove the optimality guarantee.
Figures

read the original abstract
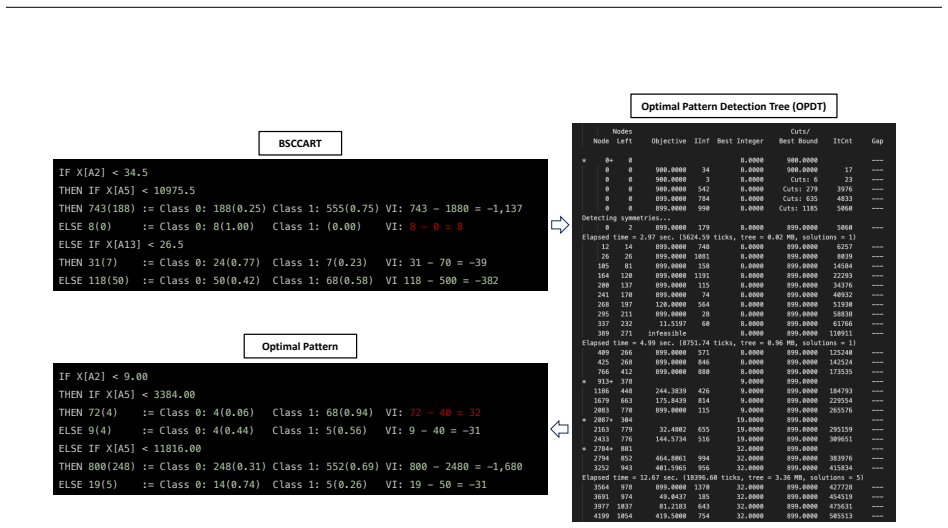
Pattern discovery in data plays a crucial role across diverse domains, including healthcare, risk assessment, and machinery maintenance. In contrast to black-box deep learning models, symbolic rule discovery emerges as a key data mining task, generating human-interpretable rules that offer both transparency and intuitive explainability. This paper introduces the Optimal Pattern Detection Tree (OPDT), a rule-based machine learning model based on novel mixed-integer programming to discover a single optimal pattern in data through binary classification. To incorporate prior knowledge and compliance requirements, we further introduce the Branching Structure Constraints (BSC) framework, which enables decision makers to encode domain knowledge and constraints directly into the model. This optimization-based approach discovers a hidden underlying pattern in datasets, when it exists, by identifying an optimal rule that maximizes coverage while minimizing the false positive rate due to misclassification. Our computational experiments show that OPDT discovers a pattern with optimality guarantees on moderately sized datasets within reasonable runtime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Optimal Pattern Detection Tree (OPDT), a mixed-integer programming formulation for discovering a single optimal symbolic rule in binary classification by maximizing coverage while minimizing the false-positive rate due to misclassification. It further proposes the Branching Structure Constraints (BSC) framework to encode domain knowledge and compliance requirements directly into the optimization model. The central claim is that computational experiments demonstrate OPDT recovers hidden patterns with optimality guarantees on moderately sized datasets within reasonable runtime.
Significance. If the MIP formulation is exact and the reported experiments establish proven optimality (zero gap), the work would offer a transparent, constraint-aware alternative to heuristic rule learners, with direct utility in high-stakes domains such as healthcare and risk assessment where both interpretability and formal guarantees matter.
major comments (2)
- [Computational experiments] Computational experiments section: the abstract asserts that OPDT 'discovers a pattern with optimality guarantees,' yet no variable or constraint counts, integrality-gap statistics, solver termination criteria, or scaling curves are supplied. Without explicit evidence that the branch-and-bound process closed the gap to zero on the tested instances, the optimality-guarantee claim remains unsubstantiated.
- [Model formulation] Model formulation: the objective that 'maximizes coverage while minimizing the false positive rate' must be encoded exactly in the MIP; any linearization or relaxation of the tree-structure or misclassification penalties could introduce a modeling gap that invalidates the optimality claim even when the solver reports a solution.
minor comments (1)
- [Abstract] The abstract would be strengthened by a single sentence listing the dataset sizes, number of instances, and baseline methods against which OPDT was compared.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will revise the paper to provide the requested details and clarifications on the computational results and model formulation.
read point-by-point responses
-
Referee: [Computational experiments] Computational experiments section: the abstract asserts that OPDT 'discovers a pattern with optimality guarantees,' yet no variable or constraint counts, integrality-gap statistics, solver termination criteria, or scaling curves are supplied. Without explicit evidence that the branch-and-bound process closed the gap to zero on the tested instances, the optimality-guarantee claim remains unsubstantiated.
Authors: We agree that additional documentation is required to substantiate the optimality claims. In the revised manuscript we will add tables listing the number of variables and constraints per instance, the final integrality gap (zero in all reported optimal solutions), solver termination criteria including time limits and gap tolerance, and scaling curves of runtime versus dataset size. These additions will explicitly confirm that branch-and-bound closed the gap to zero on the tested instances. revision: yes
-
Referee: [Model formulation] Model formulation: the objective that 'maximizes coverage while minimizing the false positive rate' must be encoded exactly in the MIP; any linearization or relaxation of the tree-structure or misclassification penalties could introduce a modeling gap that invalidates the optimality claim even when the solver reports a solution.
Authors: The objective is encoded exactly as a linear combination of binary coverage and misclassification indicator variables with no relaxation or approximation. The tree structure is enforced through exact linear constraints. In the revision we will expand the formulation section to display the complete objective and constraint set, making the absence of modeling gaps explicit. revision: yes
Circularity Check
No significant circularity: new MIP formulation stands independently
full rationale
The paper presents OPDT as a novel mixed-integer programming model that directly encodes the objective of maximizing coverage while minimizing false-positive misclassifications for binary classification pattern discovery. The claimed optimality guarantees follow from standard MIP solver behavior on the formulated objective and constraints (including the optional BSC framework for domain knowledge), without any reduction to prior fitted parameters, self-citations, or renamed empirical patterns. No equations or steps in the provided abstract or description equate a derived result to its own inputs by construction; the approach is self-contained as an optimization encoding rather than a statistical fit or self-referential definition.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
volume-impurity (VI) index = volume gain − w × misclassification loss ... OPDT formulation adopts three fundamental constraints from Bertsimas & Dunn (2017)’s OCT: tree structure constraints, sample routing constraints, and misclassification constraints
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Branching Structure Constraints (BSC) ... feature groups ... numerical-categorical group separation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume =
Lightgbm: A highly efficient gradient boosting decision tree , author =. Advances in neural information processing systems , volume =
-
[2]
Financial fraud detection based on machine learning: a systematic literature review , author =. Applied Sciences , volume =. 2022 , publisher =
work page 2022
-
[3]
Proceedings of the 1999 IEEE symposium on security and privacy (Cat
A data mining framework for building intrusion detection models , author =. Proceedings of the 1999 IEEE symposium on security and privacy (Cat. No. 99CB36344) , pages =. 1999 , organization =
work page 1999
-
[4]
2009 Second International Conference on Intelligent Computation Technology and Automation , volume =
Large rotating machinery fault diagnosis and knowledge rules acquiring based on improved RIPPER , author =. 2009 Second International Conference on Intelligent Computation Technology and Automation , volume =. 2009 , organization =
work page 2009
-
[5]
Journal of statistical software , volume =
Feature selection with the Boruta package , author =. Journal of statistical software , volume =
-
[6]
Advances in neural information processing systems , volume =
A unified approach to interpreting model predictions , author =. Advances in neural information processing systems , volume =
-
[7]
2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP) , pages =
Learning sparse two-level boolean rules , author =. 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP) , pages =. 2016 , organization =
work page 2016
-
[8]
Journal of Machine Learning Research , volume =
Interpretable and fair boolean rule sets via column generation , author =. Journal of Machine Learning Research , volume =
-
[9]
European Journal of Operational Research , volume =
Optimization problems for machine learning: A survey , author =. European Journal of Operational Research , volume =. 2021 , publisher =
work page 2021
-
[10]
Optimization methods for large-scale machine learning , author =. SIAM review , volume =. 2018 , publisher =
work page 2018
-
[11]
Computers & Operations Research , volume =
New optimization models for optimal classification trees , author =. Computers & Operations Research , volume =. 2024 , publisher =
work page 2024
-
[12]
Interpretable machine learning: Fundamental principles and 10 grand challenges , author =. Statistic Surveys , volume =. 2022 , publisher =
work page 2022
-
[13]
Nature machine intelligence , volume =
Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead , author =. Nature machine intelligence , volume =. 2019 , publisher =
work page 2019
-
[14]
Computers & Operations Research , volume =
Column generation based heuristic for learning classification trees , author =. Computers & Operations Research , volume =. 2020 , publisher =
work page 2020
-
[15]
Strong optimal classification trees , author =. Operations Research , year =
-
[16]
The Annals of Applied Statistics , volume =
Predictive learning via rule ensembles , author =. The Annals of Applied Statistics , volume =. 2008 , publisher =
work page 2008
-
[17]
Gradient Directed Regularization , author =
-
[18]
Interpretable decision sets: A joint framework for description and prediction , author =. Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining , pages =
-
[19]
Journal of Machine Learning Research , volume =
A bayesian framework for learning rule sets for interpretable classification , author =. Journal of Machine Learning Research , volume =
-
[20]
Proceedings of the twelfth international conference on machine learning , pages =
Fast effective rule induction , author =. Proceedings of the twelfth international conference on machine learning , pages =
-
[21]
Machine learning proceedings 1994 , pages =
Incremental reduced error pruning , author =. Machine learning proceedings 1994 , pages =. 1994 , publisher =
work page 1994
-
[22]
Nicolas Goix and Vighnesh Birodkar and Florian Gardin and Jean-Matthieu Schertzer and HOEBIN JEONG and manoj kumar and Alexandre Gramfort and Tim Staley and Tom Dupré la Tour and Boyuan Deng and C and Fabian Pedregosa and Lawrence Wu and Ariel Rokem and Kyle Jackson and mrahim , title =. 2020 , publisher =. doi:10.5281/zenodo.4316671 , url =
-
[23]
arXiv preprint arXiv:2106.07296 , year =
RRULES: An improvement of the RULES rule-based classifier , author =. arXiv preprint arXiv:2106.07296 , year =
-
[24]
Knowledge-Based Systems , volume =
PRISM: An algorithm for inducing modular rules , author =. Knowledge-Based Systems , volume =
-
[25]
Expert Systems with Applications , volume =
RULES: A simple rule extraction system , author =. Expert Systems with Applications , volume =. 1995 , publisher =
work page 1995
-
[26]
BioMed research international , volume =
Pattern recognition in medical decision support , author =. BioMed research international , volume =. 2019 , publisher =
work page 2019
-
[27]
Biomedical informatics insights , volume =
Big data application in biomedical research and health care: a literature review , author =. Biomedical informatics insights , volume =. 2016 , publisher =
work page 2016
-
[28]
Journal of biomedical informatics , volume =
Building a robust, scalable and standards-driven infrastructure for secondary use of EHR data: the SHARPn project , author =. Journal of biomedical informatics , volume =. 2012 , publisher =
work page 2012
-
[29]
Biomedical signal and image processing for clinical decision support systems. , author =. Comput. Math. Methods Medicine , volume =
-
[30]
American journal of public health , volume =
Effectiveness of computerized decision support systems linked to electronic health records: a systematic review and meta-analysis , author =. American journal of public health , volume =. 2014 , publisher =
work page 2014
-
[31]
Lubicz, M. and Pawelczyk, K. and Rzechonek, A. and Kolodziej, J. , title =. 2014 , howpublished =
work page 2014
- [32]
- [33]
-
[34]
Surendra Prasad and Venkateswarlu, Nagasuri Bala , title =
Ramana, Bendi Venkata and Babu, M. Surendra Prasad and Venkateswarlu, Nagasuri Bala , title =. 2012 , howpublished =
work page 2012
- [35]
-
[36]
Chicco, Davide and Jurman, Giuseppe , title =. 2020 , howpublished =
work page 2020
- [37]
- [38]
-
[39]
Islam, M. M. Faniqul and Ferdousi, Rahatara and Rahman, Sadikur and Bushra, Humayra Yasmin , title =. 2020 , howpublished =
work page 2020
-
[40]
Rubini, L. and Soundarapandian, P. and Eswaran, P. , title =. 2015 , howpublished =
work page 2015
- [41]
- [42]
-
[43]
Janosi,Andras and Steinbrunn,William and Pfisterer,Matthias and Detrano,Robert , title =. 1988 , howpublished =
work page 1988
- [44]
- [45]
-
[46]
UCI Machine Learning Repository , url =
Kelly, Markelle and Longjohn, Rachel and Nottingham, Kolby , year =. UCI Machine Learning Repository , url =
-
[47]
Algorithmic bias: From discrimination discovery to fairness-aware data mining , author =. Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining , pages =
-
[48]
How the machine ‘thinks’: Understanding opacity in machine learning algorithms , author =. Big data & society , volume =. 2016 , publisher =
work page 2016
-
[49]
Interpretable machine learning in healthcare , author =. Proceedings of the 2018 ACM international conference on bioinformatics, computational biology, and health informatics , pages =
work page 2018
-
[50]
Frontiers in big data , volume =
Interpretability of machine learning solutions in public healthcare: The CRISP-ML approach , author =. Frontiers in big data , volume =. 2021 , publisher =
work page 2021
-
[51]
ACM Computing Surveys (CSUR) , volume =
Constraint Enforcement on Decision Trees: A Survey , author =. ACM Computing Surveys (CSUR) , volume =. 2022 , publisher =
work page 2022
-
[52]
Twentieth IEEE International Symposium on Computer-Based Medical Systems (CBMS'07) , pages =
Increasing acceptability of decision trees with domain attributes partial orders , author =. Twentieth IEEE International Symposium on Computer-Based Medical Systems (CBMS'07) , pages =. 2007 , organization =
work page 2007
-
[53]
Information processing letters , volume =
Constructing optimal binary decision trees is NP-complete , author =. Information processing letters , volume =
-
[54]
Notions of explainability and evaluation approaches for explainable artificial intelligence , author =. Information Fusion , volume =. 2021 , publisher =
work page 2021
-
[55]
Proceedings of the National Academy of Sciences , volume =
Definitions, methods, and applications in interpretable machine learning , author =. Proceedings of the National Academy of Sciences , volume =. 2019 , publisher =
work page 2019
-
[56]
Classification and regression trees , author =. 1984 , publisher =
work page 1984
-
[57]
Journal of global optimization , volume =
Optimal decision trees for categorical data via integer programming , author =. Journal of global optimization , volume =. 2021 , publisher =
work page 2021
-
[58]
Proceedings of the AAAI conference on artificial intelligence , volume =
Learning optimal classification trees using a binary linear program formulation , author =. Proceedings of the AAAI conference on artificial intelligence , volume =
-
[59]
Optimal classification trees , author =. Machine Learning , volume =. 2017 , publisher =
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.