Recognition: no theorem link
FuzzAgent: Multi-Agent System for Evolutionary Library Fuzzing
Pith reviewed 2026-05-15 02:11 UTC · model grok-4.3
The pith
A multi-agent system automates the full library fuzzing lifecycle by evolving harnesses from runtime feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
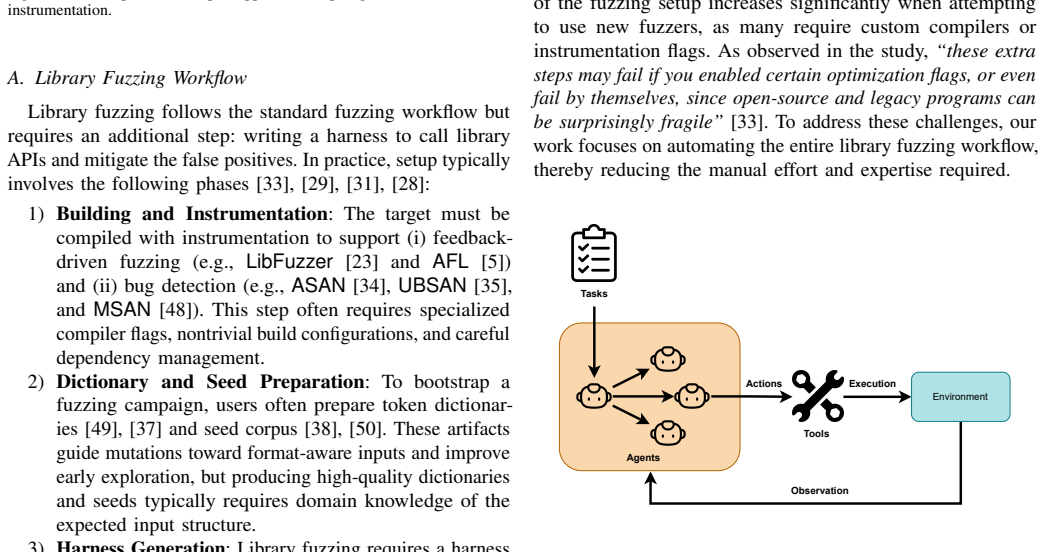
FuzzAgent is a multi-agent system that converts library fuzzing into an evolutionary process: a team of agents collaborates across the full lifecycle, grounding every choice in runtime evidence so that harness suites are successively refined toward deeper coverage and higher-fidelity crash reports across successive rounds.
What carries the argument
The multi-agent evolutionary loop that uses runtime coverage and crash signals to iteratively refine harnesses and bug triage.
If this is right
- Fuzzing campaigns can continue from prior results instead of restarting from scratch each time.
- Higher branch coverage becomes achievable without expert-written harnesses for each library.
- Reported bugs are more likely to be accepted by upstream maintainers.
- The full fuzzing pipeline runs to completion on new libraries with no human setup or filtering.
- Coverage and bug counts improve measurably over repeated rounds on the same target.
Where Pith is reading between the lines
- Similar agent-driven evolution could be applied to other code-generation tasks such as test-case synthesis or API migration.
- If the runtime-feedback loop generalizes, the cost barrier to continuous library hardening drops enough for routine use in open-source maintenance.
- Extending the agent roles to include formal verification hints might further raise the fraction of reported issues that are true positives.
- The same iterative structure could be tested on libraries in other languages once equivalent runtime instrumentation exists.
Load-bearing premise
Runtime signals alone let the agents reliably tell genuine library bugs apart from crashes introduced by the harness itself.
What would settle it
A controlled experiment on one library in which FuzzAgent reports a crash that later analysis proves is caused only by the harness and not by the library code.
Figures












read the original abstract
Library fuzzing is essential for hardening the software supply chain, but adopting it at scale remains expensive. Practitioners still spend substantial effort on environment setup, struggle to generate harnesses that respect intricate API constraints, and lack reliable means to tell genuine library bugs from harness-induced crashes. Recent LLM-based systems automate parts of this pipeline, yet they typically operate as one-shot code generators that ignore runtime feedback, which limits both the depth of code they reach and the validity of the bugs they report. We argue that effective library fuzzing is iterative by nature: each campaign exposes new coverage bottlenecks and crashes, and the next campaign should evolve from these signals rather than restart from scratch. Building on this insight, we present FuzzAgent, a multi-agent system that turns library fuzzing into an evolutionary process, in which a team of specialized agents collaborates over the full fuzzing lifecycle and grounds every decision in concrete runtime evidence, so that the harness suite is successively refined toward deeper coverage and higher-fidelity crash analysis across rounds. We evaluate FuzzAgent on 20 real-world C/C++ libraries against four state-of-the-art baselines (OSS-Fuzz, OSS-Fuzz-Gen, PromptFuzz, and PromeFuzz). FuzzAgent completes the full fuzzing lifecycle for all 20 libraries without human intervention and reaches 179619 branches, exceeding OSS-Fuzz, PromptFuzz, PromeFuzz, and OSS-Fuzz-Gen by 45.1%, 73.2%, 92.1%, and 191.2%, respectively. FuzzAgent also identifies 102 genuine library bugs, 78 of which have already been acknowledged and fixed by upstream maintainers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents FuzzAgent, a multi-agent system that automates the full library fuzzing lifecycle for C/C++ libraries via iterative evolution grounded in runtime feedback. On 20 real-world libraries it reports completing the process without human intervention, achieving 179619 branches covered (exceeding OSS-Fuzz by 45.1%, PromptFuzz by 73.2%, PromeFuzz by 92.1%, and OSS-Fuzz-Gen by 191.2%) and identifying 102 genuine bugs of which 78 have been acknowledged and fixed upstream.
Significance. If the empirical results and triage process are rigorously validated, the work could meaningfully advance automated software security by lowering the barrier to comprehensive library fuzzing and enabling deeper, higher-fidelity vulnerability discovery across the software supply chain.
major comments (2)
- [Evaluation] The central claim of 102 genuine library bugs (and the associated no-human-intervention assertion) rests on the multi-agent triage logic distinguishing library defects from harness crashes, yet the manuscript provides no explicit triage rules, decision criteria, false-positive rate, or independent validation protocol for these classifications.
- [Evaluation] The reported coverage improvements (45.1%–191.2%) and branch total of 179619 are presented without sufficient detail on baseline configurations, harness generation consistency, coverage instrumentation, or measurement methodology, preventing verification that the comparisons are fair and that the evolutionary loop is the source of the gains.
minor comments (2)
- A dedicated section or appendix describing the agent roles, prompts, and exact runtime feedback signals used in each iteration would improve reproducibility.
- Clarify the precise definition of 'branches' used for coverage and confirm that the same metric and instrumentation were applied uniformly to FuzzAgent and all baselines.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We have revised the manuscript to address the concerns about explicit triage criteria and evaluation reproducibility. The changes strengthen the validation of our claims without altering the core contributions.
read point-by-point responses
-
Referee: [Evaluation] The central claim of 102 genuine library bugs (and the associated no-human-intervention assertion) rests on the multi-agent triage logic distinguishing library defects from harness crashes, yet the manuscript provides no explicit triage rules, decision criteria, false-positive rate, or independent validation protocol for these classifications.
Authors: We agree that the original manuscript lacked sufficient detail on the triage process. In the revised version we have added a dedicated subsection (Section 4.3) that explicitly documents the triage agent's decision rules: a crash is classified as a library bug only if (1) the faulting instruction lies within library code (determined via ASan reports and symbol resolution), (2) the crash is reproducible with a minimal harness that exercises only the reported API sequence, and (3) the same crash does not occur when the harness is run against a patched library version. We also report a manual false-positive audit on 50 randomly sampled triage decisions (false-positive rate 6%) and note that 78 of the 102 bugs have received upstream acknowledgments. The full triage logs and decision traces are now included in the supplementary material to enable independent verification. revision: yes
-
Referee: [Evaluation] The reported coverage improvements (45.1%–191.2%) and branch total of 179619 are presented without sufficient detail on baseline configurations, harness generation consistency, coverage instrumentation, or measurement methodology, preventing verification that the comparisons are fair and that the evolutionary loop is the source of the gains.
Authors: We acknowledge the need for greater methodological transparency. The revised evaluation section (Section 5) now includes: (a) exact baseline configurations (OSS-Fuzz commit hash, PromptFuzz and PromeFuzz prompt templates and temperature settings, OSS-Fuzz-Gen generation parameters); (b) harness-generation protocol ensuring identical initial API lists and seed corpora across all systems; (c) coverage instrumentation details (gcov for C, llvm-cov for C++ with -fprofile-arcs -ftest-coverage flags and branch-counting via gcovr); and (d) measurement methodology (five independent 24-hour runs per library, median branch counts, and Wilcoxon signed-rank tests confirming statistical significance of the gains). These additions demonstrate that the observed improvements stem from the iterative multi-agent evolution rather than differences in experimental setup. revision: yes
Circularity Check
No significant circularity; claims are direct empirical measurements
full rationale
The paper presents an empirical system evaluation on 20 libraries, reporting concrete coverage numbers (179619 branches) and bug counts (102 genuine bugs) obtained from full-lifecycle runs against four baselines. No equations, fitted parameters, self-definitional quantities, or load-bearing self-citations appear in the provided text. The iterative multi-agent loop is motivated by runtime feedback but the headline results are measured outcomes, not quantities that reduce to the authors' own prior definitions or fits by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The art, science, and engineering of fuzzing: A survey,
V . J. M. Man`es, H. Han, C. Han, S. K. Cha, M. Egele, E. J. Schwartz, and M. Woo, “The art, science, and engineering of fuzzing: A survey,”IEEE Transactions on Software Engineering, vol. 47, no. 11, pp. 2312–2331, 2021
work page 2021
-
[2]
Fuzzers for stateful systems: Survey and research directions,
C. Daniele, S. B. Andarzian, and E. Poll, “Fuzzers for stateful systems: Survey and research directions,”ACM Comput. Surv., vol. 56, no. 9, Apr. 2024. [Online]. Available: https://doi.org/10.1145/3648468
-
[3]
Fuzzing vulnerability discovery techniques: Survey, challenges and future directions,
C. Beaman, M. Redbourne, J. D. Mummery, and S. Hakak, “Fuzzing vulnerability discovery techniques: Survey, challenges and future directions,”Computers & Security, vol. 120, p. 102813, 2022. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S016740482 2002073
work page 2022
-
[4]
A survey of fuzzing open-source operating systems,
K. Hu, Q. Chen, Z. Lu, W. Zhang, B. Chen, Y . Lu, H. Jiang, B. Sun, X. Peng, and W. Zhao, “A survey of fuzzing open-source operating systems,” 2025. [Online]. Available: https://arxiv.org/abs/2502.13163
-
[5]
M. Zalewski, “American fuzzy lop,” http://lcamtuf.coredump.cx/afl/, Accessed 2026
work page 2026
-
[6]
Coverage-based greybox fuzzing as markov chain,
M. B ¨ohme, V .-T. Pham, and A. Roychoudhury, “Coverage-based greybox fuzzing as markov chain,” inProceedings of the 2016 ACM SIGSAC Con- ference on Computer and Communications Security, 2016, p. 1032–1043
work page 2016
-
[7]
Z.-M. Jiang, J.-J. Bai, and Z. Su, “DynSQL: Stateful fuzzing for database management systems with complex and valid SQL query generation,” in32nd USENIX Security Symposium (USENIX Security 23). Anaheim, CA: USENIX Association, Aug. 2023, pp. 4949–4965. [Online]. Available: https://www.usenix.org/conference/usenixsecurity23 /presentation/jiang-zu-ming
work page 2023
-
[8]
WingFuzz: Implementing continuous fuzzing for DBMSs,
J. Liang, Z. Wu, J. Fu, Y . Bai, Q. Zhang, and Y . Jiang, “WingFuzz: Implementing continuous fuzzing for DBMSs,” in2024 USENIX Annual Technical Conference (USENIX ATC 24). Santa Clara, CA: USENIX Association, Jul. 2024, pp. 479–492. [Online]. Available: https://www.usenix.org/conference/atc24/presentation/liang
work page 2024
-
[9]
Symbolic execution with SymCC: Don’t interpret, compile!
S. Poeplau and A. Francillon, “Symbolic execution with SymCC: Don’t interpret, compile!” in29th USENIX Security Symposium (USENIX Security 20). USENIX Association, Aug. 2020, pp. 181–198. [Online]. Available: https://www.usenix.org/conference/usenixsecurity20/presentat ion/poeplau
work page 2020
-
[10]
H. Tu, S. Lee, Y . Li, P. Chen, L. Jiang, and M. B ¨ohme, “Cottontail: Large Language Model-Driven Concolic Execution for Highly Structured Test Input Generation,” in2026 IEEE Symposium on Security and Privacy (SP). Los Alamitos, CA, USA: IEEE Computer Society, 2026, pp. 2064–2082. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/SP63933.2...
-
[11]
OSS-Fuzz-google’s continuous fuzzing service for open source software,
K. Serebryany, “OSS-Fuzz-google’s continuous fuzzing service for open source software,” inProceedings of the 26th USENIX Conference on Security Symposium (technical sessions). USENIX Association, 2017
work page 2017
-
[12]
Beyond the coverage plateau: A comprehensive study of fuzz blockers (registered report),
W. Gao, V .-T. Pham, D. Liu, O. Chang, T. Murray, and B. I. Rubinstein, “Beyond the coverage plateau: A comprehensive study of fuzz blockers (registered report),” inProceedings of the 2nd International Fuzzing Workshop, ser. FUZZING 2023. New York, NY , USA: Association for Computing Machinery, 2023, p. 47–55. [Online]. Available: https://doi.org/10.1145/...
-
[13]
Fudge: fuzz driver generation at scale,
D. Babi´c, S. Bucur, Y . Chen, F. Ivanˇci´c, T. King, M. Kusano, C. Lemieux, L. Szekeres, and W. Wang, “Fudge: fuzz driver generation at scale,” in Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2019, pp. 975–985
work page 2019
-
[14]
FuzzGen: Automatic fuzzer generation,
K. Ispoglou, D. Austin, V . Mohan, and M. Payer, “FuzzGen: Automatic fuzzer generation,” in29th USENIX Security Symposium (USENIX Security 20), 2020, pp. 2271–2287
work page 2020
-
[15]
Intelligen: Automatic driver synthesis for fuzz testing,
M. Zhang, J. Liu, F. Ma, H. Zhang, and Y . Jiang, “Intelligen: Automatic driver synthesis for fuzz testing,” in2021 IEEE/ACM 43rd International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE, 2021, pp. 318–327
work page 2021
-
[16]
APICraft: Fuzz driver generation for closed-source SDK libraries,
C. Zhang, X. Lin, Y . Li, Y . Xue, J. Xie, H. Chen, X. Ying, J. Wang, and Y . Liu, “APICraft: Fuzz driver generation for closed-source SDK libraries,” in30th USENIX Security Symposium (USENIX Security 21), 2021, pp. 2811–2828. 14
work page 2021
-
[17]
Graphfuzz: Library api fuzzing with lifetime-aware dataflow graphs,
H. Green and T. Avgerinos, “Graphfuzz: Library api fuzzing with lifetime-aware dataflow graphs,” in2022 IEEE/ACM 44th International Conference on Software Engineering (ICSE), 2022, pp. 1070–1081
work page 2022
-
[18]
Hopper: Interpretative fuzzing for libraries,
P. Chen, Y . Xie, Y . Lyu, Y . Wang, and H. Chen, “Hopper: Interpretative fuzzing for libraries,” inACM Conference on Computer and Communi- cations Security (CCS), Copenhagen, Denmark, 2023
work page 2023
-
[19]
Afgen: Whole- function fuzzing for applications and libraries,
Y . Liu, Y . Wang, T. Bao, X. Jia, Z. Zhang, and P. Su, “Afgen: Whole- function fuzzing for applications and libraries,” in2024 IEEE Symposium on Security and Privacy (SP), 2024, pp. 11–11
work page 2024
-
[20]
Prompt fuzzing for fuzz driver generation,
Y . Lyu, Y . Xie, P. Chen, and H. Chen, “Prompt fuzzing for fuzz driver generation,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 3793–3807. [Online]. Available: https://doi.org/10.1145/3658644.3670396
-
[21]
Y . Deng, C. S. Xia, H. Peng, C. Yang, and L. Zhang, “Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models,” inProceedings of the 32nd ACM SIGSOFT Interna- tional Symposium on Software Testing and Analysis, 2023, p. 423–435
work page 2023
-
[22]
Promefuzz: A knowledge-driven approach to fuzzing harness generation with large language models,
Y . Liu, J. Deng, X. Jia, Y . Wang, M. Wang, L. Huang, T. Wei, and P. Su, “Promefuzz: A knowledge-driven approach to fuzzing harness generation with large language models,” inProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 1559–1573. [Onl...
-
[23]
libfuzzer – a library for coverage-guided fuzz testing,
LLVM, “libfuzzer – a library for coverage-guided fuzz testing,” https: //llvm.org/docs/LibFuzzer.html, Accessed 2026
work page 2026
-
[24]
Utopia: Automatic generation of fuzz driver using unit tests,
B. Jeong, J. Jang, H. Yi, J. Moon, J. Kim, I. Jeon, T. Kim, W. Shim, and Y . H. Hwang, “Utopia: Automatic generation of fuzz driver using unit tests,” in2023 IEEE Symposium on Security and Privacy (SP). IEEE Computer Society, 2022, pp. 746–762
work page 2022
-
[25]
Automatic library fuzzing through API relation evolvement,
J. Lin, Q. Zhang, J. Li, C. Sun, H. Zhou, C. Luo, and C. Qian, “Automatic library fuzzing through API relation evolvement,” in32nd Annual Network and Distributed System Security Symposium, NDSS 2025, San Diego, California, USA, February 24-28, 2025. The Internet Society, 2025. [Online]. Available: https://www.ndss-symposium.org/nds s-paper/automatic-libra...
work page 2025
-
[26]
Google, “oss-fuzz-gen,” https://github.com/google/oss- fuzz- gen, Accessed 2026
work page 2026
-
[27]
Ckgfuzzer: Llm-based fuzz driver generation enhanced by code knowledge graph,
H. Xu, W. Ma, T. Zhou, Y . Zhao, K. Chen, Q. Hu, Y . Liu, and H. Wang, “Ckgfuzzer: Llm-based fuzz driver generation enhanced by code knowledge graph,” inProceedings of the IEEE/ACM 47th International Conference on Software Engineering: Companion Proceedings, ser. ICSE ’25. IEEE Press, 2025, p. 243–254. [Online]. Available: https://doi.org/10.1109/ICSE-Com...
-
[28]
Oss-fuzz guide: Setting up a new project,
“Oss-fuzz guide: Setting up a new project,” https://google.github.io/oss-f uzz/getting-started/new-project-guide/, Accessed 2026
work page 2026
-
[29]
S. Pl ¨oger, M. Meier, and M. Smith, “A qualitative usability evaluation of the clang static analyzer and libfuzzer with cs students and ctf players,” in Proceedings of the Seventeenth USENIX Conference on Usable Privacy and Security, ser. SOUPS’21. USA: USENIX Association, 2021
work page 2021
-
[30]
A survey of human-machine collabora- tion in fuzzing,
Q. Yan, M. Huang, and H. Cao, “A survey of human-machine collabora- tion in fuzzing,” in2022 7th IEEE International Conference on Data Science in Cyberspace (DSC), 2022, pp. 375–382
work page 2022
-
[31]
A usability evaluation of afl and libfuzzer with cs students,
S. Pl ¨oger, M. Meier, and M. Smith, “A usability evaluation of afl and libfuzzer with cs students,” inProceedings of the 2023 CHI Conference on Human Factors in Computing Systems, ser. CHI ’23. New York, NY , USA: Association for Computing Machinery, 2023. [Online]. Available: https://doi.org/10.1145/3544548.3581178
-
[32]
The human side of fuzzing: Challenges faced by developers during fuzzing activities,
O. Nourry, Y . Kashiwa, B. Lin, G. Bavota, M. Lanza, and Y . Kamei, “The human side of fuzzing: Challenges faced by developers during fuzzing activities,”ACM Trans. Softw. Eng. Methodol., vol. 33, no. 1, Nov. 2023. [Online]. Available: https://doi.org/10.1145/3611668
-
[33]
A qualitative analysis of fuzzer usability and challenges,
Y . Zhao, W. Guo, H. Goldstein, D. V otipka, K. R. Fulton, and M. L. Mazurek, “A qualitative analysis of fuzzer usability and challenges,” inProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 2504–2518. [Online]. Available: https://doi.org/1...
-
[34]
Address- sanitizer: A fast address sanity checker,
K. Serebryany, D. Bruening, A. Potapenko, and D. Vyukov, “Address- sanitizer: A fast address sanity checker,” inProceedings of the 2012 USENIX Conference on Annual Technical Conference, ser. USENIX ATC’12. USENIX Association, 2012, p. 28
work page 2012
-
[35]
Undefined behavior sanitizer - official documentation,
LLVM, “Undefined behavior sanitizer - official documentation,” https: //clang.llvm.org/docs/UndefinedBehaviorSanitizer.html, Accessed 2026
work page 2026
-
[36]
Oss-fuzz guide: Setting up a new project (builds),
“Oss-fuzz guide: Setting up a new project (builds),” https://google.githu b.io/oss-fuzz/getting-started/new-project-guide/#buildsh, Accessed 2026
work page 2026
-
[37]
Fuzzingdriver: the missing dictionary to increase code coverage in fuzzers,
A. A. Ebrahim, M. Hazhirpasand, O. Nierstrasz, and M. Ghafari, “Fuzzingdriver: the missing dictionary to increase code coverage in fuzzers,” in2022 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), 2022, pp. 268–272
work page 2022
-
[38]
How to prepare the seed corpus for oss-fuzz,
Google, “How to prepare the seed corpus for oss-fuzz,” https://goog le.github.io/oss-fuzz/getting-started/new-project-guide/#seed-corpus, Accessed 2026
work page 2026
-
[39]
Fuzzing: Challenges and reflections,
M. Boehme, C. Cadar, and A. ROYCHOUDHURY , “Fuzzing: Challenges and reflections,”IEEE Software, vol. 38, no. 3, pp. 79–86, 2021
work page 2021
-
[40]
Large legal fictions: Profiling legal hallucinations in large language models,
M. Dahl, V . Magesh, M. Suzgun, and D. E. Ho, “Large legal fictions: Profiling legal hallucinations in large language models,” Journal of Legal Analysis, vol. 16, no. 1, 2024. [Online]. Available: http://dx.doi.org/10.1093/jla/laae003
-
[41]
HalluLens: LLM hallucination benchmark,
Y . Bang, Z. Ji, A. Schelten, A. Hartshorn, T. Fowler, C. Zhang, N. Cancedda, and P. Fung, “HalluLens: LLM hallucination benchmark,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2025. [Online]. Available: https: //aclanthology.org/2025.acl-long.1176/
work page 2025
-
[42]
DeepRAG: Thinking to retrieve step by step for large language models,
X. Guan, J. Zeng, F. Meng, C. Xin, Y . Lu, H. Lin, X. Han, L. Sun, and J. Zhou, “DeepRAG: Thinking to retrieve step by step for large language models,” inThe Fourteenth International Conference on Learning Representations, 2026. [Online]. Available: https://openreview.net/forum?id=VI2YaggHIF
work page 2026
-
[43]
S. Jeong, J. Baek, S. Cho, S. J. Hwang, and J. C. Park, “Adaptive-rag: Learning to adapt retrieval-augmented large language models through question complexity,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2024, pp. 7036–7050
work page 2024
-
[44]
H. Tan, F. Sun, W. Yang, Y . Wang, Q. Cao, and X. Cheng, “Blinded by generated contexts: How language models merge generated and retrieved contexts when knowledge conflicts?” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 6207–6227
work page 2024
-
[45]
Large language model based multi-agents: A survey of progress and challenges,
T. Guo, X. Chen, Y . Wang, R. Chang, S. Pei, N. V . Chawla, O. Wiest, and X. Zhang, “Large language model based multi-agents: A survey of progress and challenges,” inProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24, K. Larson, Ed. International Joint Conferences on Artificial Intelligence Organization, 8 ...
-
[46]
A survey on llm- based multi-agent systems: workflow, infrastructure, and challenges,
X. Li, S. Wang, S. Zeng, Y . Wu, and Y . Yang, “A survey on llm- based multi-agent systems: workflow, infrastructure, and challenges,” Vicinagearth, 2024
work page 2024
-
[47]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. R. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable automated software engineering,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://arxiv.org/abs/2405.15793
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Memorysanitizer - official documentation,
LLVM, “Memorysanitizer - official documentation,” https://clang.llvm.o rg/docs/MemorySanitizer.html, Accessed 2026
work page 2026
-
[49]
Learning input tokens for effective fuzzing,
B. Mathis, R. Gopinath, and A. Zeller, “Learning input tokens for effective fuzzing,” inProceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA
-
[50]
New York, NY , USA: Association for Computing Machinery, 2020, p. 27–37. [Online]. Available: https://doi.org/10.1145/3395363.3397348
-
[51]
Seed selection for successful fuzzing,
A. Herrera, H. Gunadi, S. Magrath, M. Norrish, M. Payer, and A. L. Hosking, “Seed selection for successful fuzzing,” inProceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA 2021. New York, NY , USA: Association for Computing Machinery, 2021, p. 230–243. [Online]. Available: https://doi.org/10.1145/3460319.3464795
-
[52]
AFL++ : Combining incremental steps of fuzzing research,
A. Fioraldi, D. Maier, H. Eißfeldt, and M. Heuse, “AFL++ : Combining incremental steps of fuzzing research,” in14th USENIX Workshop on Offensive Technologies (WOOT 20), 2020
work page 2020
-
[53]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning,
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, X. Zhang, X. Yu, Y . Wu, Z. F. Wu, Z. Gou, Z. Shao, Z. Li, Z. Gao, A. Liu, B. Xue, B. Wang, B. Wu, B. Feng, C. Lu, C. Zhao, C. Deng, C. Ruan, D. Dai, D. Chen, D. Ji, E. Li, F. Lin, 15 F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Xu, H. Ding, H. Gao, H. Qu, H. Li, J...
-
[54]
Available: http://dx.doi.org/10.1038/s41586-025-09422-z
[Online]. Available: http://dx.doi.org/10.1038/s41586-025-09422-z
-
[55]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,”arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[56]
A practical guide to building agents,
OpenAI, “A practical guide to building agents,” https://cdn.openai.com/b usiness-guides-and-resources/a-practical-guide-to-building-agents.pdf, Accessed 2026
work page 2026
-
[57]
Writing effective tools for agents,
M. team., “Writing effective tools for agents,” https://modelcontextprot ocol.info/docs/tutorials/writing-effective-tools/, Accessed 2026
work page 2026
-
[58]
Fuzz introspector – introspect, extend and optimise fuzzers,
O. S. S. F. (OpenSSF), “Fuzz introspector – introspect, extend and optimise fuzzers,” Accessed 2022. [Online]. Available: https: //github.com/ossf/fuzz-introspector
work page 2022
-
[59]
Casr-Cluster: Crash clustering for linux applications,
G. Savidov and A. Fedotov, “Casr-Cluster: Crash clustering for linux applications,” in2021 Ivannikov ISPRAS Open Conference (ISPRAS). IEEE, 2021, pp. 47–51
work page 2021
-
[60]
Gdb non-interactive batch mode,
I. Free Software Foundation, “Gdb non-interactive batch mode,” https: //www.sourceware.org/gdb/current/onlinedocs/gdb.html/Mode-Options .html, Accessed 2026
work page 2026
-
[61]
B. Liu, X. Li, J. Zhang, J. Wang, T. He, S. Hong, H. Liu, S. Zhang, K. Song, K. Zhu, Y . Cheng, S. Wang, X. Wang, Y . Luo, H. Jin, P. Zhang, O. Liu, J. Chen, H. Zhang, Z. Yu, H. Shi, B. Li, D. Wu, F. Teng, X. Jia, J. Xu, J. Xiang, Y . Lin, T. Liu, T. Liu, Y . Su, H. Sun, G. Berseth, J. Nie, I. Foster, L. Ward, Q. Wu, Y . Gu, M. Zhuge, X. Liang, X. Tang, H...
-
[62]
S. Han, Q. Zhang, Y . Yao, W. Jin, and Z. Xu, “Llm multi-agent systems: Challenges and open problems,” 2025. [Online]. Available: https://arxiv.org/abs/2402.03578
-
[63]
Demystifying llm-based software engineering agents,
C. S. Xia, Y . Deng, S. Dunn, and L. Zhang, “Demystifying llm-based software engineering agents,”Proc. ACM Softw. Eng., vol. 2, no. FSE, Jun. 2025. [Online]. Available: https://doi.org/10.1145/3715754
-
[64]
LLVM, “Source-based code coverage,” Accessed 2026. [Online]. Available: https://clang.llvm.org/docs/SourceBasedCodeCoverage.html
work page 2026
-
[65]
travitch, “Whole program llvm (wllvm),” https://github.com/travitch/wh ole-program-llvm, Accessed 2026
work page 2026
-
[66]
Redqueen: Fuzzing with input-to-state correspondence,
C. Aschermann, S. Schumilo, T. Blazytko, R. Gawlik, and T. Holz, “Redqueen: Fuzzing with input-to-state correspondence,” inSymposium on Network and Distributed System Security (NDSS), 2019
work page 2019
-
[67]
Codamosa: Escaping coverage plateaus in test generation with pre-trained large language models,
C. Lemieux, J. P. Inala, S. K. Lahiri, and S. Sen, “Codamosa: Escaping coverage plateaus in test generation with pre-trained large language models,” in2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), 2023, pp. 919–931
work page 2023
-
[68]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI, A. Liu, A. Mei, B. Lin, B. Xue, B. Wang, B. Xu, B. Wu, B. Zhang, C. Lin, C. Dong, C. Lu, C. Zhao, C. Deng, C. Xu, C. Ruan, D. Dai, D. Guo, D. Yang, D. Chen, E. Li, F. Zhou, F. Lin, F. Dai, G. Hao, G. Chen, G. Li, H. Zhang, H. Xu, H. Li, H. Liang, H. Wei, H. Zhang, H. Luo, H. Ji, H. Ding, H. Tang, H. Cao, H. Gao, H. Qu, H. Zeng, J. Huang, J. L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
In: Proceedings of the 29th Symposium on Operating Systems Principles
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the 29th Symposium on Operating Systems Principles, ser. SOSP ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 611–626. [Online]. Availabl...
-
[70]
Hugging face: Deepseek v3.2 model,
DeepSeek-AI, “Hugging face: Deepseek v3.2 model,” https://huggingfac e.co/deepseek-ai/DeepSeek-V3.2, Accessed 2026
work page 2026
-
[71]
llvm-cov - emit coverage information,
LLVM, “llvm-cov - emit coverage information,” Accessed 2026. [Online]. Available: https://llvm.org/docs/CommandGuide/llvm-cov.html
work page 2026
-
[72]
G. Klees, A. Ruef, B. Cooper, S. Wei, and M. Hicks, “Evaluating fuzz testing,” inProceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’18. New York, NY , USA: Association for Computing Machinery, 2018, p. 2123–2138. [Online]. Available: https://doi.org/10.1145/3243734.3243804
-
[73]
Promptfuzz author response to its official release,
P. developers, “Promptfuzz author response to its official release,” https: //github.com/FuzzAnything/PromptFuzz/releases/tag/v1.0.0, Accessed 2026
work page 2026
-
[74]
Can promefuzz be used to fuzz openssl?
——, “Can promefuzz be used to fuzz openssl?” https://github.com/pvz 122/PromeFuzz/issues/8, Accessed 2026
work page 2026
-
[75]
Rulf: Rust library fuzzing via api dependency graph traversal,
J. Jiang, H. Xu, and Y . Zhou, “Rulf: Rust library fuzzing via api dependency graph traversal,” in2021 36th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2021, pp. 581–592
work page 2021
-
[76]
Y . Deng, C. S. Xia, H. Peng, C. Yang, and L. Zhang, “Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models,” inProceedings of the 32nd ACM SIGSOFT Interna- tional Symposium on Software Testing and Analysis, 2023, pp. 423–435
work page 2023
-
[77]
Universal fuzzing via large language models,
C. S. Xia, M. Paltenghi, J. L. Tian, M. Pradel, and L. Zhang, “Universal fuzzing via large language models,”arXiv preprint arXiv:2308.04748, 2023
-
[78]
Directed greybox fuzzing via large language model,
H. Xu, Y . Zhao, and H. Wang, “Directed greybox fuzzing via large language model,” 2025. [Online]. Available: https: //arxiv.org/abs/2505.03425
-
[79]
“Github rest api,” https://docs.github.com/en/rest?apiVersion=2022-11-2 8, Accessed 2026
work page 2022
-
[80]
Agent design lessons from claude code,
Janne, “Agent design lessons from claude code,” https://jannesklaas.gith ub.io/ai/2025/07/20/claude-code-agent-design.html, Accessed 2026. APPENDIX A. Open Science We are committed to reproducible research. However, as discussed in the Ethical Considerations section, the dual-use potential ofFuzzAgentprecludes an open-source release of its 16 implementati...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.