Recognition: no theorem link
Synthesizing POMDP Policies: Sampling Meets Model-checking via Learning
Pith reviewed 2026-05-15 01:51 UTC · model grok-4.3
The pith
Sampling as a membership oracle and model-checking as an equivalence oracle synthesize finite-state POMDP controllers with formal guarantees when the induced policy is regular.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a synthesis framework integrating sampling, automata learning, and model-checking produces finite-state controllers for POMDPs with formal guarantees whenever the sampling-induced policy is regular. Sampling serves as the membership oracle and model-checking as the equivalence oracle in an L*-style learner. The framework includes a relative completeness result and a prototype implementation that solves threshold-safety problems beyond the reach of existing formal tools.
What carries the argument
An automata learning procedure modeled on Angluin's L* algorithm that uses sampling to answer membership queries and model-checking to answer equivalence queries, thereby constructing a regular finite-state policy for the POMDP.
If this is right
- Finite-state controllers are produced that satisfy the given threshold-safety properties by construction.
- Relative completeness holds: whenever a regular policy exists that meets the specification, the procedure will find one.
- Threshold-safety problems that defeat current formal synthesis tools become solvable in practice.
- The method can serve as one component inside a portfolio of algorithms for POMDP synthesis.
Where Pith is reading between the lines
- If many practical POMDP policies are close to regular, the method could be paired with approximation steps that project sampled behaviors onto regular languages.
- Replacing the exact oracles with probabilistic or bounded-error versions would let the same structure handle noisy observations and approximate model-checking.
- The oracle separation suggests similar learning loops could be applied to other undecidable controller synthesis problems such as those involving hybrid dynamics.
Load-bearing premise
The sampling procedure must induce a regular policy and both sampling and model-checking must function as exact oracles without noise or approximation error.
What would settle it
A concrete POMDP threshold-safety instance in which the algorithm returns a controller that violates the safety threshold, or fails to terminate on a problem known to possess a regular satisfying policy.
Figures


read the original abstract
Partially Observable Markov Decision Processes (POMDPs) are the standard framework for decision-making under uncertainty. While sampling-based methods scale well, they lack formal correctness guarantees, making them unsuitable for safety-critical applications. Conversely, formal synthesis techniques provide correctness-by-construction but often struggle with scalability, as general POMDP synthesis is undecidable. To bridge this gap, we propose a synthesis framework that integrates sampling, automata learning, and model-checking. Inspired by Angluin's $L^*$ algorithm, our approach utilizes sampling as a membership oracle and model-checking as an equivalence oracle. This enables the synthesis of finite-state controllers with formal guarantees, provided the sampling-induced policy is regular. We establish a relative completeness result for this framework. Experimental results from our prototypical implementation demonstrate that this method successfully solves threshold-safety problems that remain challenging for existing formal synthesis tools. We believe our algorithm serves as a valuable component in a portfolio approach to tackling the inherent difficulty of POMDP synthesis problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a synthesis framework for POMDPs that combines sampling-based policy generation with automata learning (inspired by Angluin's L*) and model-checking. Sampling serves as a membership oracle and model-checking as an equivalence oracle to construct finite-state controllers. The central claim is a relative completeness result for threshold-safety problems, provided the sampling-induced policy is regular; experiments on a prototypical implementation are reported to solve instances that challenge existing formal tools.
Significance. If the relative completeness result holds under the stated regularity condition, the work would meaningfully bridge scalable sampling methods (which lack guarantees) and correct-by-construction formal synthesis (which struggles with scalability and undecidability) for POMDPs. The use of standard automata-theoretic oracles without fitted parameters is a strength, and successful experiments on hard threshold-safety cases would position the approach as a practical portfolio component for safety-critical decision-making under partial observability.
major comments (2)
- [Relative completeness result] The relative completeness theorem (stated in the abstract and presumably §4 or §5) rests on the assumption that the sampling-induced policy is exactly regular. However, POMDP sampling is finite and stochastic, so the induced policy is at best approximately regular; no error bounds, convergence analysis, or handling of membership-oracle noise are provided to justify that finite samples suffice for exact queries or that model-checking equivalence remains reliable under approximation.
- [Experimental results] The experimental evaluation reports positive results on threshold-safety problems but provides no error bars, variance estimates across sampling runs, or discussion of how stochastic sampling noise affects controller correctness (abstract and experimental section). This weakens support for the claim that the method reliably solves instances challenging for existing tools.
minor comments (1)
- [Abstract] The abstract would benefit from a one-sentence clarification of the POMDP model assumptions (e.g., finite state/action/observation spaces) and the precise notion of 'regular' policy used in the completeness statement.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and limitations of our relative-completeness result. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Relative completeness result] The relative completeness theorem (stated in the abstract and presumably §4 or §5) rests on the assumption that the sampling-induced policy is exactly regular. However, POMDP sampling is finite and stochastic, so the induced policy is at best approximately regular; no error bounds, convergence analysis, or handling of membership-oracle noise are provided to justify that finite samples suffice for exact queries or that model-checking equivalence remains reliable under approximation.
Authors: The theorem is stated as relative completeness under the explicit assumption that the policy induced by the sampling oracle is regular (see abstract and Theorem 1 in §4). The L* procedure uses sampling only to answer membership queries for this regular target; once a candidate controller is produced, the model-checking equivalence oracle verifies it exactly against the POMDP and specification, discarding any controller that fails. We agree that finite sampling can introduce transient noise and that the manuscript would benefit from an expanded discussion of this practical gap. In the revision we will add a dedicated paragraph in §4.3 clarifying that the guarantee holds only in the limit of exhaustive sampling and that the final model-check step protects against incorrect acceptance, while acknowledging that quantitative error bounds are not derived in the current work. revision: partial
-
Referee: [Experimental results] The experimental evaluation reports positive results on threshold-safety problems but provides no error bars, variance estimates across sampling runs, or discussion of how stochastic sampling noise affects controller correctness (abstract and experimental section). This weakens support for the claim that the method reliably solves instances challenging for existing tools.
Authors: We accept the observation. The current experimental section reports only success/failure on individual instances. In the revised version we will rerun all benchmarks with 10 independent sampling seeds, report mean runtime and success rate together with standard deviation, and add a short paragraph explaining that any controller returned by the learner is subsequently model-checked on the concrete POMDP, thereby eliminating controllers that would have been accepted due to sampling noise. revision: yes
Circularity Check
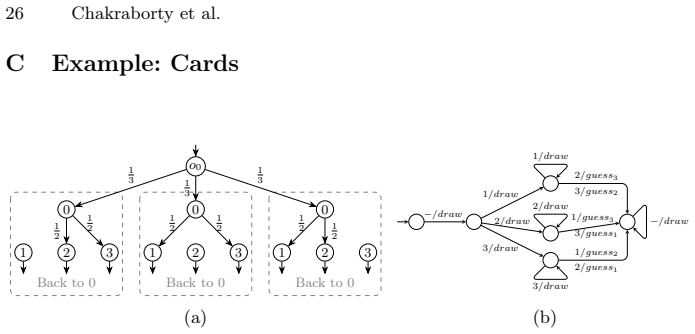
No circularity: relative completeness follows from standard L* oracle correctness under explicit regularity assumption
full rationale
The paper defines a synthesis procedure that invokes sampling as a membership oracle and model-checking as an equivalence oracle, then invokes the known correctness of Angluin's L* algorithm to obtain a relative completeness theorem: if a regular policy satisfying the threshold-safety property exists, the procedure will find a finite-state controller. This chain rests on external, independently established automata-learning results and on the paper's stated assumption that the sampling-induced policy is regular; neither the assumption nor the oracles are defined in terms of the target result. No parameters are fitted, no quantity is renamed as a prediction, and no self-citation supplies a load-bearing uniqueness or ansatz. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption General POMDP synthesis is undecidable
- ad hoc to paper Sampling-induced policy is regular
Reference graph
Works this paper leans on
-
[1]
In: Principles of Systems Design: Essays Dedicated to Thomas A
Alur, R., Bansal, S., Bastani, O., Jothimurugan, K.: A framework for transforming specifications in reinforcement learning. In: Principles of Systems Design: Essays Dedicated to Thomas A. Henzinger on the Occasion of His 60th Birthday, pp. 604–624. Springer (2022)
work page 2022
-
[2]
In: International Con- ference on Computer Aided Verification
Andriushchenko, R., Bork, A., Češka, M., Junges, S., Katoen, J.P., Macák, F.: Search and explore: Symbiotic policy synthesis in pomdps. In: International Con- ference on Computer Aided Verification. pp. 113–135. Springer (2023)
work page 2023
-
[3]
In: International Conference on Computer Aided Verification
Andriushchenko, R., Češka, M., Junges, S., Katoen, J.P., Stupinsk` y, Š.: Paynt: a tool for inductive synthesis of probabilistic programs. In: International Conference on Computer Aided Verification. pp. 856–869. Springer (2021)
work page 2021
-
[4]
Angluin, D.: Learning regular sets from queries and counterexamples. Inf. Comput. 75(2), 87–106 (1987)
work page 1987
-
[5]
Baier, C., Katoen, J.P.: Principles of model checking. MIT press (2008)
work page 2008
-
[6]
In: International Conference on Tools and Algorithms for the Construction and Analysis of Systems
Bork, A., Chakraborty, D., Grover, K., Křetínský, J., Mohr, S.: Learning explain- able and better performing representations of pomdp strategies. In: International Conference on Tools and Algorithms for the Construction and Analysis of Systems. pp. 299–319. Springer (2024)
work page 2024
-
[7]
In: International Symposium on Automated Technology for Verification and Analysis
Bork, A., Junges, S., Katoen, J.P., Quatmann, T.: Verification of indefinite-horizon pomdps. In: International Symposium on Automated Technology for Verification and Analysis. pp. 288–304. Springer (2020)
work page 2020
-
[8]
In: International Conference on Tools and Algorithms for the Construction and Analysis of Systems
Bork, A., Katoen, J.P., Quatmann, T.: Under-approximating expected total re- wards in pomdps. In: International Conference on Tools and Algorithms for the Construction and Analysis of Systems. pp. 22–40. Springer (2022)
work page 2022
-
[9]
Bouyer, P., Brihaye, T., Bruyère, V., Raskin, J.: On the optimal reachability prob- lem of weighted timed automata. Formal Methods Syst. Des.31(2), 135–175 (2007)
work page 2007
-
[10]
Brihaye, T., Bruyère, V., Raskin, J.: On optimal timed strategies. In: FORMATS. Lecture Notes in Computer Science, vol. 3829, pp. 49–64. Springer (2005)
work page 2005
-
[11]
Journal of Artificial Intelligence Re- search72, 819–847 (2021)
Carr, S., Jansen, N., Topcu, U.: Task-aware verifiable rnn-based policies for par- tially observable markov decision processes. Journal of Artificial Intelligence Re- search72, 819–847 (2021)
work page 2021
-
[12]
synthesizing pomdp policies: Sampling meets model-checking via learning
Chakraborty, D., Majumdar, A., Mathew, P., Mukherjee, S., Raskin, J.F.: Artifact for "synthesizing pomdp policies: Sampling meets model-checking via learning" (May 2026). https://doi.org/10.5281/zenodo.20084734
-
[13]
In: International Symposium on Mathematical Foundations of Computer Science
Chatterjee, K., Doyen, L., Gimbert, H., Henzinger, T.A.: Randomness for free. In: International Symposium on Mathematical Foundations of Computer Science. pp. 246–257. Springer (2010)
work page 2010
-
[14]
Logical Methods in Computer Science 3(2007)
Chatterjee, K., Doyen, L., Henzinger, T.A., Raskin, J.F.: Algorithms for omega- regular games with imperfect information. Logical Methods in Computer Science 3(2007)
work page 2007
- [15]
-
[16]
Drews, S., D’Antoni, L.: Learning symbolic automata. In: TACAS (1). Lecture Notes in Computer Science, vol. 10205, pp. 173–189 (2017)
work page 2017
-
[17]
In: International Sym- posium on Automated Technology for Verification and Analysis
Fujinami, H., Waga, M., An, J., Suenaga, K., Yanagisawa, N., Iseri, H., Hasuo, I.: Componentwise automata learning for system integration. In: International Sym- posium on Automated Technology for Verification and Analysis. pp. 3–26. Springer (2025)
work page 2025
-
[18]
In: Inter- national Conference on Tools and Algorithms for the Construction and Analysis of Systems
Han, T., Katoen, J.P.: Counterexamples in probabilistic model checking. In: Inter- national Conference on Tools and Algorithms for the Construction and Analysis of Systems. pp. 72–86. Springer (2007)
work page 2007
- [19]
-
[20]
Hensel, C., Junges, S., Katoen, J., Quatmann, T., Volk, M.: The probabilistic model checker Storm. Int. J. Softw. Tools Technol. Transf.24(4), 589–610 (2022)
work page 2022
-
[21]
Jiménez, V.M., Marzal, A.: Computing the k shortest paths: A new algorithm and an experimental comparison. In: Algorithm Engineering: 3rd International Work- shop, WAE’99 London, UK, July 19–21, 1999 Proceedings 3. pp. 15–29. Springer (1999)
work page 1999
-
[22]
In: International Conference on Computer Aided Verification
Junges, S., Jansen, N., Seshia, S.A.: Enforcing almost-sure reachability in pomdps. In: International Conference on Computer Aided Verification. pp. 602–625. Springer (2021)
work page 2021
-
[23]
Kaelbling, L.P.: Learning policies for partially observable environments: Scaling up. In: Machine Learning Proceedings 1995: Proceedings of the Twelfth International Conference on Machine Learning, Tahoe City, California, July 9-12 1995. p. 362. Morgan Kaufmann (1995)
work page 1995
-
[24]
In: European con- ference on machine learning
Kocsis, L., Szepesvári, C.: Bandit based monte-carlo planning. In: European con- ference on machine learning. pp. 282–293. Springer (2006)
work page 2006
-
[25]
In: Robotics: Science and systems
Kurniawati, H., Hsu, D., Lee, W.S.: Sarsop: Efficient point-based pomdp plan- ning by approximating optimally reachable belief spaces. In: Robotics: Science and systems. vol. 2008. Citeseer (2008)
work page 2008
-
[26]
Kwiatkowska, M.Z., Norman, G., Parker, D.: PRISM 4.0: Verification of proba- bilistic real-time systems. In: CAV. Lecture Notes in Computer Science, vol. 6806, pp. 585–591. Springer (2011)
work page 2011
-
[27]
In: International Conference on Foundations of Soft- ware Science and Computation Structures
Labbaf, F., Groote, J.F., Hojjat, H., Mousavi, M.R.: Compositional learning for in- terleaving parallel automata. In: International Conference on Foundations of Soft- ware Science and Computation Structures. pp. 413–435. Springer (2023)
work page 2023
-
[28]
Madani, O., Hanks, S., Condon, A.: On the undecidability of probabilistic plan- ning and infinite-horizon partially observable markov decision problems. AAAI 10(315149.315395) (1999)
-
[29]
McCallum, R.A.: First results with utile distinction memory for reinforcement learning (1992)
work page 1992
-
[30]
Innovations in Systems and Software Engineering18(3), 417–426 (2022)
Muškardin, E., Aichernig, B.K., Pill, I., Pferscher, A., Tappler, M.: Aalpy: an active automata learning library. Innovations in Systems and Software Engineering18(3), 417–426 (2022)
work page 2022
-
[31]
In: International Conference on Fundamental Approaches to Software Engi- neering
Neele, T., Sammartino, M.: Compositional automata learning of synchronous sys- tems. In: International Conference on Fundamental Approaches to Software Engi- neering. pp. 47–66. Springer (2023)
work page 2023
-
[32]
Real-Time Systems53, 354–402 (2017)
Norman, G., Parker, D., Zou, X.: Verification and control of partially observable probabilistic systems. Real-Time Systems53, 354–402 (2017)
work page 2017
-
[33]
Peled, D.A., Vardi, M.Y., Yannakakis, M.: Black box checking. J. Autom. Lang. Comb.7(2), 225–246 (2002) 22 Chakraborty et al
work page 2002
- [34]
-
[35]
Rivest, R.L., Schapire, R.E.: Inference of finite automata using homing sequences. Inf. Comput.103(2), 299–347 (1993)
work page 1993
-
[36]
In: International Symposium on Formal Methods
Shahbaz, M., Groz, R.: Inferring mealy machines. In: International Symposium on Formal Methods. pp. 207–222. Springer (2009)
work page 2009
-
[37]
Shijubo,J.,Waga,M.,Suenaga,K.:Efficientblack-boxcheckingviamodelchecking with strengthened specifications. In: RV. pp. 100–120. Lecture Notes in Computer Science, Springer (2021)
work page 2021
-
[38]
Advances in neural information processing systems23(2010)
Silver, D., Veness, J.: Monte-carlo planning in large pomdps. Advances in neural information processing systems23(2010)
work page 2010
-
[39]
Smith,T.,Simmons,R.:Heuristicsearchvalueiterationforpomdps.arXivpreprint arXiv:1207.4166 (2012)
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[40]
Advances in neural information processing systems26(2013)
Somani, A., Ye, N., Hsu, D., Lee, W.S.: Despot: Online pomdp planning with regularization. Advances in neural information processing systems26(2013)
work page 2013
-
[41]
Journal of artificial intelligence research24, 195–220 (2005)
Spaan, M.T., Vlassis, N.: Perseus: Randomized point-based value iteration for pomdps. Journal of artificial intelligence research24, 195–220 (2005)
work page 2005
-
[42]
Wu, B., Zhang, X., Lin, H.: Supervisor synthesis of POMDP via automata learning. Autom.129, 109654 (2021) Synthesizing POMDP Policies 23 A Missing Proofs from Section 3 Lemma 1.There exists a finite memory policyσsuch that for every belief state b∈W,P σ BP (□¬Bad|initial beliefb) = 1. Proof.Winning a safety objective with probability1can only be achieved ...
work page 2021
-
[43]
there exists a discount factorλ∈(0,1), such that if there is a policyσ satisfying1 +E σ P r (Rewλ)> α, thenP σ P (□¬Bad)> α−ε
-
[44]
if there exists a policyσsuch thatP σ P (□¬Bad)> α, then, there exists a discount factorλ∈(0,1)such that1 +E σ P r (Rewλ)> α−ε. Proof.1. Recall that, for POMDPsP,P r, Pσ P (□¬Bad) = 1 + lim λ→1 Eσ P r (Rewλ) = lim λ→1 (1 +E σ P r (Rewλ)) From the above equation, we get that asλ→1,(1 +E σ P r (Rewλ))→ Pσ M (□¬Bad). Then, we can deduce that for everyε >0, t...
-
[45]
The proof of the second statement is analogous.⊓ ⊔ 24 Chakraborty et al. B Missing Proofs from Section 4 Lemma 4.LetHbe a hypothesis not satisfying the safety specification,i.e., PP×H (□¬Bad)≤α. Further, letG:={σ|P σ P (□¬Bad)> α}be the set of all threshold-safe policies. IfRis a counterexample for the model-checking query on H, then∀σ∈ G,∃ρ∈ Rsuch thatρ̸...
-
[46]
When the agent becomes confident about which card is missing, it can play the corresponding guessi. Guessing the correct card leads to a winning state, while choosing it in- correctly leads to a separate sink state (these two states are not shown in the figure). The objective of the agent is to correctly guess the missing card. Figure 5b depicts a policy ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.