Recognition: no theorem link
When Answers Stray from Questions: Hallucination Detection via Question-Answer Orthogonal Decomposition
Pith reviewed 2026-05-15 01:54 UTC · model grok-4.3
The pith
Projecting away the question direction from answer representations isolates reliable factuality signals for hallucination detection in LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
QAOD projects away the question-aligned direction from the answer representation to obtain a question-orthogonal component that suppresses domain-conditioned variation. Layer and neuron selection via Fisher scoring identify informative signals. The joint probe with question context maximizes in-domain discriminability, while the orthogonal component alone preserves domain-agnostic factuality signals for robust OOD transfer.
What carries the argument
The question-orthogonal component of the answer representation, obtained by projecting away the question-aligned direction.
If this is right
- The joint probe achieves the best in-domain AUROC across all evaluated model-dataset pairs.
- The orthogonal-only probe delivers the strongest OOD transfer, surpassing the best white-box baseline by up to 21% on BioASQ.
- This is achieved at under 25% of the generation cost of consistency methods.
- Layer selection via diversity-penalized Fisher scoring and discriminative neurons via Fisher importance identify the informative signals.
Where Pith is reading between the lines
- This decomposition suggests that much of the domain shift in hallucination signals aligns with question features in the representation space.
- The method could be extended to other single-pass detection tasks where separating context from content is useful.
- Further gains might come from applying similar orthogonal projections in multimodal or multi-turn settings.
Load-bearing premise
Removing the question-aligned direction from the answer representation suppresses domain-conditioned variation and isolates reliable factuality signals usable for both in-domain and OOD detection.
What would settle it
Running the orthogonal-only probe on a held-out domain shift dataset such as BioASQ and observing AUROC no better than the best white-box baseline would falsify the OOD robustness claim.
Figures


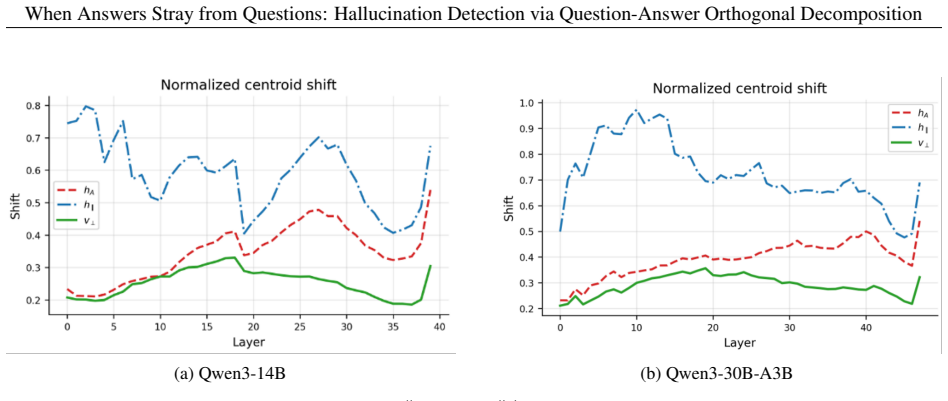



read the original abstract
Hallucination detection in large language models (LLMs) requires balancing accu racy, efficiency, and robustness to distribution shift. Black-box consistency methods are effective but demand repeated inference; single-pass white-box probes are effi cient yet treat answer representations in isolation, often degrading sharply under domain shift. We propose QAOD (Question-Answer Orthogonal Decomposition), a single-pass framework that projects away the question-aligned direction from the answer representation to obtain a question-orthogonal component that suppresses domain-conditioned variation. To identify informative signals, QAOD further selects layers via diversity-penalized Fisher scoring and discriminative neurons via Fisher importance. To address both in-domain detection and cross-domain generalization, we design two complementary probing strategies: pairing the or thogonal component with question context yields a joint probe that maximizes in-domain discriminability, while using the orthogonal component alone preserves domain-agnostic factuality signals for robust transfer. QAOD's joint probe achieves the best in-domain AUROC across all evaluated model-dataset pairs, while the orthogonal-only probe delivers the strongest OOD transfer, surpassing the best white-box baseline by up to 21% on BioASQ at under 25% of generation cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces QAOD, a single-pass hallucination detection framework for LLMs that performs orthogonal decomposition on answer hidden states to remove question-aligned directions, thereby suppressing domain-specific variation. It uses diversity-penalized Fisher scoring to select layers and Fisher importance for neurons, and proposes a joint probe (orthogonal component + question context) for in-domain detection and an orthogonal-only probe for OOD generalization. The authors claim that the joint probe achieves the best in-domain AUROC across evaluated models and datasets, while the orthogonal-only probe provides the strongest OOD transfer, outperforming white-box baselines by up to 21% on BioASQ with less than 25% of the generation cost.
Significance. If the empirical results are robust and the core assumption holds, this approach offers a promising balance of efficiency and robustness for hallucination detection, particularly in cross-domain settings where consistency-based methods are computationally expensive. The use of orthogonal projection to isolate factuality signals could advance white-box probing techniques.
major comments (3)
- [Method] The central claim that the question-orthogonal component isolates domain-agnostic factuality signals rests on an untested assumption; no analysis demonstrates that the removed question-aligned subspace correlates more strongly with domain labels than with hallucination labels (see the decomposition construction and OOD transfer claims).
- [Abstract and Experiments] Performance numbers in the abstract (e.g., best in-domain AUROC and up to 21% OOD gain on BioASQ) are stated without accompanying experimental details such as dataset sizes, number of runs, error bars, or ablation results on layer/neuron selection, undermining verifiability of the reported superiority.
- [§3.2] The diversity-penalized Fisher scoring for layer selection introduces free parameters that appear tuned on evaluation data, creating a risk of circularity in the reported in-domain and OOD results.
minor comments (2)
- [Abstract] The abstract contains typographical errors (e.g., 'accu racy', 'or thogonal') that should be corrected for clarity.
- [Method] An explicit equation for the orthogonal projection operator would improve the readability of the decomposition step.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Method] The central claim that the question-orthogonal component isolates domain-agnostic factuality signals rests on an untested assumption; no analysis demonstrates that the removed question-aligned subspace correlates more strongly with domain labels than with hallucination labels (see the decomposition construction and OOD transfer claims).
Authors: We agree that a direct quantitative comparison of correlations between the question-aligned subspace and domain versus hallucination labels would provide stronger support for the claim. The current evidence is primarily indirect via the OOD transfer gains of the orthogonal-only probe. In the revision we will add an analysis computing Pearson correlations of the removed directions with domain labels and hallucination labels across layers, and report these results in a new subsection of Section 3. revision: yes
-
Referee: [Abstract and Experiments] Performance numbers in the abstract (e.g., best in-domain AUROC and up to 21% OOD gain on BioASQ) are stated without accompanying experimental details such as dataset sizes, number of runs, error bars, or ablation results on layer/neuron selection, undermining verifiability of the reported superiority.
Authors: The full experimental details (dataset sizes, number of runs, standard deviations, and layer/neuron ablation tables) are already present in Section 4 and Appendix B. To improve verifiability we will revise the abstract to briefly note the number of runs and report mean AUROC with standard deviation for the key claims, while retaining the concise summary format. revision: partial
-
Referee: [§3.2] The diversity-penalized Fisher scoring for layer selection introduces free parameters that appear tuned on evaluation data, creating a risk of circularity in the reported in-domain and OOD results.
Authors: The diversity penalty coefficient and layer-selection threshold were chosen on a held-out validation split drawn from the in-domain training distribution, separate from both the in-domain test sets and the OOD evaluation sets. We will expand Section 3.2 to explicitly describe this validation procedure, list the exact hyperparameter values, and add a sensitivity plot showing performance variation with the penalty coefficient. revision: yes
Circularity Check
No significant circularity in QAOD derivation chain
full rationale
The paper's core construction applies standard orthogonal projection to remove a question-aligned direction from answer representations, followed by Fisher-based layer and neuron selection. These steps are presented as methodological choices whose outputs are then evaluated empirically on in-domain and OOD benchmarks. No equation or procedure reduces by construction to its own inputs, no fitted parameter is relabeled as a prediction, and no load-bearing premise rests on self-citation. The reported AUROC gains are empirical outcomes rather than tautological consequences of the decomposition definition. The framework remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- diversity-penalized Fisher scoring parameters
axioms (1)
- domain assumption Projecting away the question-aligned direction suppresses domain-conditioned variation
Reference graph
Works this paper leans on
-
[1]
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models , author=. 2023 , eprint=
work page 2023
-
[2]
doi: 10.1038/ s41586-024-07421-0
Farquhar, Sebastian and Kossen, Jannik and Kuhn, Lorenz and Gal, Yarin , title =. Nature , year =. doi:10.1038/s41586-024-07421-0 , url =
-
[3]
Language Models (Mostly) Know What They Know , author=. 2022 , eprint=
work page 2022
-
[4]
Unsupervised Real-Time Hallucination Detection based on the Internal States of Large Language Models
Su, Weihang and Wang, Changyue and Ai, Qingyao and Hu, Yiran and Wu, Zhijing and Zhou, Yujia and Liu, Yiqun. Unsupervised Real-Time Hallucination Detection based on the Internal States of Large Language Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.854
-
[5]
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author=. 2024 , eprint=
work page 2024
-
[6]
Implicit Representations of Meaning in Neural Language Models , author=. 2021 , eprint=
work page 2021
-
[7]
The Internal State of an LLM Knows When It's Lying , author=. 2023 , eprint=
work page 2023
-
[8]
Levinstein, Benjamin A. and Herrmann, Daniel A. , year=. Still no lie detector for language models: probing empirical and conceptual roadblocks , volume=. Philosophical Studies , publisher=. doi:10.1007/s11098-023-02094-3 , number=
-
[9]
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models , author=. 2024 , eprint=
work page 2024
-
[10]
SINdex: Semantic INconsistency Index for Hallucination Detection in LLMs , author=. 2025 , eprint=
work page 2025
-
[11]
INSIDE: LLMs' Internal States Retain the Power of Hallucination Detection , author=. 2024 , eprint=
work page 2024
-
[12]
Detecting LLM Hallucination Through Layer-wise Information Deficiency: Analysis of Ambiguous Prompts and Unanswerable Questions , author=. 2025 , eprint=
work page 2025
-
[13]
T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Joshi, Mandar and Choi, Eunsol and Weld, Daniel and Zettlemoyer, Luke. T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1147
-
[14]
https://aclanthology.org/ Q19-1026/
Kwiatkowski, Tom and Palomaki, Jennimaria and Redfield, Olivia and Collins, Michael and Parikh, Ankur and Alberti, Chris and Epstein, Danielle and Polosukhin, Illia and Devlin, Jacob and Lee, Kenton and Toutanova, Kristina and Jones, Llion and Kelcey, Matthew and Chang, Ming-Wei and Dai, Andrew M. and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav , title...
-
[15]
Know What You Don't Know: Unanswerable Questions for SQuAD , author=. 2018 , eprint=
work page 2018
-
[16]
Krithara, Anastasia and Nentidis, Anastasios and Bougiatiotis, Konstantinos and Paliouras, Georgios , title =. 2022 , doi =. https://www.biorxiv.org/content/early/2022/12/16/2022.12.14.520213.full.pdf , journal =
work page 2022
-
[17]
Gemma 2: Improving Open Language Models at a Practical Size , author=. 2024 , eprint=
work page 2024
-
[18]
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
work page 2023
- [19]
-
[20]
A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models , author=. 2024 , eprint=
work page 2024
-
[21]
Huang, Lei and Yu, Weijiang and Ma, Weitao and Zhong, Weihong and Feng, Zhangyin and Wang, Haotian and Chen, Qianglong and Peng, Weihua and Feng, Xiaocheng and Qin, Bing and Liu, Ting , year=. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions , volume=. ACM Transactions on Information Systems , publis...
-
[22]
Ji, Ziwei and Lee, Nayeon and Frieske, Rita and Yu, Tiezheng and Su, Dan and Xu, Yan and Ishii, Etsuko and Bang, Ye Jin and Madotto, Andrea and Fung, Pascale , year=. Survey of Hallucination in Natural Language Generation , volume=. ACM Computing Surveys , publisher=. doi:10.1145/3571730 , number=
-
[23]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
work page 2023
-
[24]
Large language models and the perils of their hallucinations , volume =
Azamfirei, Razvan and Kudchadkar, Sapna and Fackler, James , year =. Large language models and the perils of their hallucinations , volume =. Critical Care , doi =
-
[25]
Teaching Models to Express Their Uncertainty in Words , author=. 2022 , eprint=
work page 2022
-
[26]
Computational Linguistics , year =
Belinkov, Yonatan. Probing Classifiers: Promises, Shortcomings, and Advances. Computational Linguistics. 2022. doi:10.1162/coli_a_00422
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[27]
Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models , author=. 2024 , eprint=
work page 2024
-
[28]
LLM-Check: Investigating Detection of Hallucinations in Large Language Models , url =
Sriramanan, Gaurang and Bharti, Siddhant and Sadasivan, Vinu Sankar and Saha, Shoumik and Kattakinda, Priyatham and Feizi, Soheil , booktitle =. LLM-Check: Investigating Detection of Hallucinations in Large Language Models , url =. doi:10.52202/079017-1077 , editor =
-
[29]
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author=. 2024 , eprint=
work page 2024
-
[30]
Factuality of Large Language Models: A Survey , author=. 2024 , eprint=
work page 2024
-
[31]
Hallucination Detection: Robustly Discerning Reliable Answers in Large Language Models , author=. 2024 , eprint=
work page 2024
-
[32]
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models , author=. 2025 , eprint=
work page 2025
-
[33]
Representation Engineering: A Top-Down Approach to AI Transparency , author=. 2025 , eprint=
work page 2025
-
[34]
FacTool: Factuality Detection in Generative AI -- A Tool Augmented Framework for Multi-Task and Multi-Domain Scenarios , author=. 2023 , eprint=
work page 2023
-
[35]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,
Detecting Hallucination in Large Language Models Through Deep Internal Representation Analysis , author =. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,. 2025 , month =. doi:10.24963/ijcai.2025/929 , url =
- [36]
-
[37]
Similarity of Neural Network Representations Revisited , author=. 2019 , eprint=
work page 2019
-
[38]
Ranked Voting based Self-Consistency of Large Language Models
Wang, Weiqin and Wang, Yile and Huang, Hui. Ranked Voting based Self-Consistency of Large Language Models. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.744
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.