Recognition: no theorem link
Does RAG Know When Retrieval Is Wrong? Diagnosing Context Compliance under Knowledge Conflict
Pith reviewed 2026-05-15 01:59 UTC · model grok-4.3
The pith
Context-Driven Decomposition diagnoses when RAG follows conflicting retrieved context over its own knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
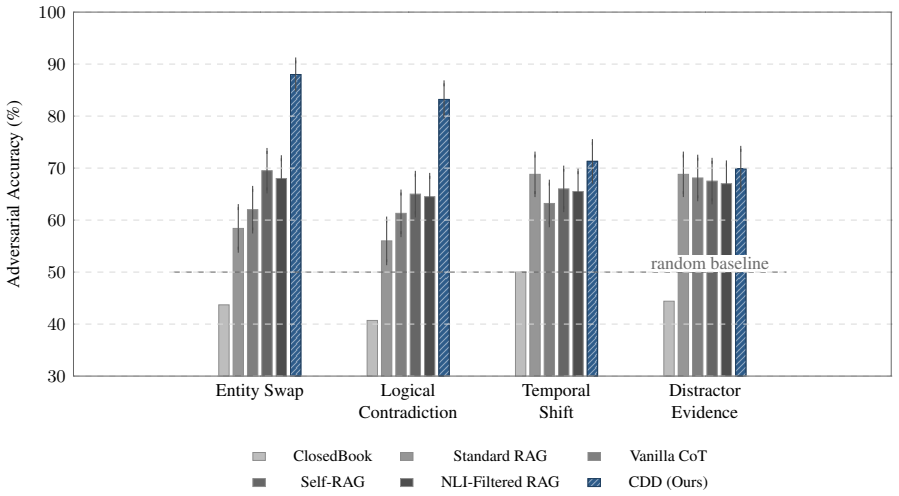
CDD serves as a belief-decomposition probe that operates at inference time as an intervention mechanism for controlled retrieval conflict. Across stress tests it reveals that standard RAG reaches 15.0 percent accuracy on TruthfulQA misconception injection, that accuracy gains transfer across models but rationale-answer causal coupling does not, and that explicit conflict decomposition reaches 71.3 percent under temporal drift and 69.9 percent under noisy distractors on the Epi-Scale benchmark.
What carries the argument
Context-Driven Decomposition (CDD), an inference-time belief-decomposition probe that isolates and controls the causal contribution of retrieved context under knowledge conflict.
If this is right
- Standard RAG exhibits measurable context compliance and low accuracy under adversarial misconception injection.
- Accuracy improvements from CDD transfer across different model families.
- Explicit conflict decomposition raises performance under temporal drift and noisy distractor conditions.
- Context compliance forms a distinct structural axis separate from retrieval quality alone.
Where Pith is reading between the lines
- Model families may resolve context conflicts through different internal mechanisms when causal sensitivity varies.
- CDD-style interventions could be combined with existing retrieval pipelines to improve reliability on drifting facts.
- The Epi-Scale benchmark enables direct comparison of compliance behavior across retrieval methods and model scales.
Load-bearing premise
The belief-decomposition probe accurately isolates the causal contribution of retrieved context without the intervention itself altering the model's reasoning process.
What would settle it
An experiment that applies CDD to the same inputs but records final answers whose accuracy or causal sensitivity deviates substantially from the predicted decomposition trace.
Figures



read the original abstract
The Context-Compliance Regime in Retrieval-Augmented Generation (RAG) occurs when retrieved context dominates the final answer even when it conflicts with the model's parametric knowledge. Accuracy alone does not reveal how retrieved context causally shapes answers under such conflict. We introduce Context-Driven Decomposition (CDD), a belief-decomposition probe that operates at inference time and serves as an intervention mechanism for controlled retrieval conflict. Across Epi-Scale stress tests, TruthfulQA misconception injection, and cross- model reruns, CDD exposes three patterns. P1: context compliance is measurable in an upper-bound adversarial setting, where Standard RAG reaches 15.0% accuracy on TruthfulQA misconception injection (N=500). P2: adversarial accuracy gains transfer across model families: CDD improves accuracy on Gemini-2.5-Flash and on Claude Haiku/Sonnet/Opus, but rationale-answer causal coupling does not transfer. CDD reaches 64.1% mistake- injection causal sensitivity on Gemini-2.5-Flash, while sensitivities for all three Claude variants fall in the [-3%, +7%] range, suggesting that the Claude-side accuracy gains operate through a mechanism distinct from the explicit conflict-resolution trace. P3: explicit conflict decomposition improves robustness under temporal drift and noisy distractors, with CDD reaching 71.3% on temporal shifts and 69.9% on distractor evidence on the full Epi-Scale adversarial benchmark. These three patterns identify context-compliance as a structural axis along which standard RAG can be probed and intervened on, distinct from retrieval-quality or single-method robustness questions, and motivate releasing Epi-Scale for systematic study across model families and retrieval pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Context-Driven Decomposition (CDD), a belief-decomposition probe operating at inference time, to diagnose and intervene on context compliance in RAG when retrieved context conflicts with parametric knowledge. It reports three patterns: standard RAG reaches only 15.0% accuracy on TruthfulQA misconception injection (N=500); CDD accuracy gains transfer across Gemini-2.5-Flash and Claude models but causal coupling does not (64.1% mistake-injection sensitivity on Gemini vs. [-3%, +7%] on Claude variants); and CDD improves robustness to 71.3% under temporal drift and 69.9% under noisy distractors on the Epi-Scale benchmark. The work positions context compliance as a distinct structural axis and plans to release Epi-Scale.
Significance. If the CDD probe validly isolates the causal contribution of retrieved context, the results would meaningfully advance RAG diagnostics by separating context-driven compliance from retrieval quality or generic robustness, while highlighting model-family differences in rationale-answer coupling. The release of Epi-Scale as a reusable adversarial benchmark would support reproducible cross-model and cross-pipeline studies.
major comments (2)
- [Abstract] Abstract, P2: the claim that rationale-answer causal coupling fails to transfer (Gemini 64.1% vs. Claude [-3%, +7%]) rests on CDD cleanly isolating the causal effect of context; however, no placebo-prompt, non-decomposition baseline, or intervention-control condition is described, leaving open the possibility that observed differences reflect model-specific responses to the decomposition instruction itself rather than intrinsic compliance regimes.
- [Abstract] Abstract: the central claims require that the belief-decomposition probe does not itself alter the model's reasoning process, yet the manuscript provides neither the exact decomposition equations nor controls for intervention artifacts, which are load-bearing for validating P1–P3.
minor comments (2)
- [Abstract] Abstract: accuracy figures (15.0%, 64.1%, 71.3%, 69.9%) are presented without error bars, confidence intervals, or details on the number of runs or statistical tests.
- [Abstract] Abstract: no mention of pre-registered analysis plans or adjustments for multiple comparisons in the cross-model reruns.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on validating the causal claims of Context-Driven Decomposition (CDD). We address each major comment below and will revise the manuscript to strengthen the controls and documentation.
read point-by-point responses
-
Referee: [Abstract] Abstract, P2: the claim that rationale-answer causal coupling fails to transfer (Gemini 64.1% vs. Claude [-3%, +7%]) rests on CDD cleanly isolating the causal effect of context; however, no placebo-prompt, non-decomposition baseline, or intervention-control condition is described, leaving open the possibility that observed differences reflect model-specific responses to the decomposition instruction itself rather than intrinsic compliance regimes.
Authors: We agree that additional baselines would more rigorously isolate the causal contribution of context. The current experiments compare CDD directly against standard RAG (no decomposition) as the primary control, and the divergent coupling patterns persist despite uniform accuracy gains across families. However, we acknowledge the value of a placebo prompt (e.g., neutral rephrasing without explicit conflict decomposition). We will add this baseline in the revision, reporting results on both TruthfulQA and Epi-Scale to confirm that the observed model-family differences in rationale-answer coupling are not artifacts of the instruction format. revision: yes
-
Referee: [Abstract] Abstract: the central claims require that the belief-decomposition probe does not itself alter the model's reasoning process, yet the manuscript provides neither the exact decomposition equations nor controls for intervention artifacts, which are load-bearing for validating P1–P3.
Authors: We will include the precise decomposition equations (including the belief-separation and recombination steps) in the Methods section of the revised manuscript. Regarding intervention artifacts, CDD is intentionally an active probe rather than a passive measurement; its effect is quantified via the delta from standard RAG. To further address potential artifacts, we will add an ablation study applying decomposition prompts without knowledge conflict. These additions will directly support validation of P1–P3. revision: yes
Circularity Check
No significant circularity; empirical results on external benchmarks
full rationale
The paper introduces CDD as an inference-time intervention and reports empirical accuracies and sensitivities (e.g., 15.0% on TruthfulQA, 64.1% causal sensitivity on Gemini) measured directly on external adversarial benchmarks TruthfulQA and Epi-Scale. No equations, fitted parameters, or self-definitional reductions appear; claims do not reduce to quantities defined by the method itself. Results are tied to observable benchmark outcomes rather than internal tautologies or load-bearing self-citations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Belief decomposition at inference time can isolate the causal effect of retrieved context on the generated answer
invented entities (1)
-
Context-Driven Decomposition (CDD)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Alchourr´on, Peter G¨ardenfors, and David Makinson
Carlos E. Alchourr´on, Peter G¨ardenfors, and David Makinson. On the logic of theory change: Partial meet contraction and revi- sion functions.The Journal of Symbolic Logic, 50(2):510–530, 1985
work page 1985
-
[2]
Self- RAG: Learning to retrieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self- RAG: Learning to retrieve, generate, and critique through self-reflection. InInterna- tional Conference on Learning Representa- tions, 2024
work page 2024
-
[3]
Wenhu Chen, Hongyi Huang, Xueguang Wang, et al. Rich knowledge sources bring complex knowledge conflicts: Recalibrating models to reflect conflicting evidence. In Proceedings of the 2022 Conference on Em- pirical Methods in Natural Language Pro- cessing, 2022
work page 2022
-
[4]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, 2020
work page 2020
-
[5]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Rad- hakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, et al. Measuring faithful- ness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Retrieval- augmented generation for knowledge- intensive nlp tasks
Patrick Lewis, Ethan Perez, et al. Retrieval- augmented generation for knowledge- intensive nlp tasks. InAdvances in Neural Information Processing Systems, 2020
work page 2020
-
[7]
TruthfulQA: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA: Measuring how models mimic human falsehoods. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics, 2022
work page 2022
-
[8]
Entity-based knowledge conflicts in question answering
Shayne Longpre, Yi Lu, Nan Du, Diyi Yang, and Mohit Iyyer. Entity-based knowledge conflicts in question answering. InProceed- ings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021
work page 2021
-
[9]
Alex Mallen, Akari Asai, Victor Zhong, Ra- jarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. When not to trust language mod- els: Investigating effectiveness of paramet- ric and non-parametric memories. InPro- ceedings of the 61st Annual Meeting of the Association for Computational Linguistics, 2023
work page 2023
-
[10]
Trusting your evidence: Hallucinate less with context- aware decoding
Freda Shi, Xinyun Chen, et al. Trusting your evidence: Hallucinate less with context- aware decoding. InProceedings of the 2023 Conference of the North American Chapter of the Association for Computational Lin- guistics, 2023
work page 2023
-
[11]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting. InAdvances in Neural Information Process- ing Systems, 2023
work page 2023
- [12]
-
[13]
Chain- of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuur- mans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain- of-thought prompting elicits reasoning in large language models. InAdvances in Neu- ral Information Processing Systems, 2022
work page 2022
-
[14]
ClashE- val: Quantifying the tug-of-war between an LLM’s internal prior and external evidence
Kevin Wu, Eric Wu, and James Zou. ClashE- val: Quantifying the tug-of-war between an LLM’s internal prior and external evidence. arXiv preprint arXiv:2404.10198, 2024
-
[15]
Jian Xie et al. Adaptive chameleon or stub- born sloth? unraveling the behavior of large language models in knowledge conflicts. In International Conference on Learning Rep- resentations, 2023
work page 2023
-
[16]
Knowledge conflicts for LLMs: A survey
Rongwu Xu, Zehan Qi, Zhijiang Guo, Cunx- iang Wang, Hongru Wang, Yue Zhang, and Wei Xu. Knowledge conflicts for LLMs: A survey. InFindings of EMNLP 2024, 2024
work page 2024
-
[17]
Corrective Retrieval Augmented Generation
Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, and Zhen-Hua Ling. Corrective retrieval augmented generation.arXiv preprint arXiv:2401.15884, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Making retrieval- augmented language models robust to irrel- evant context
Ori Yoran, Tomer Wolfson, Ori Ram, and Jonathan Berant. Making retrieval- augmented language models robust to irrel- evant context. InInternational Conference on Learning Representations, 2023
work page 2023
-
[19]
Wei Zou, Runpeng Wang, Xiaowei Yang, et al. PoisonedRAG: Knowledge poisoning attacks to retrieval-augmented generation of large language models.arXiv preprint arXiv:2402.07867, 2024. A Appendix: Reproducibility De- tails All evaluations use temperature 0.0 and greedy decoding constraints. String normalization mapping for FEVER: [supports, true, yes] → Tru...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.