Recognition: 2 theorem links
· Lean TheoremGeoVista: Visually Grounded Active Perception for Ultra-High-Resolution Remote Sensing Understanding
Pith reviewed 2026-05-15 02:36 UTC · model grok-4.3
The pith
GeoVista builds a global exploration plan then performs branch-wise inspections while tracking evidence to interpret ultra-high-resolution remote sensing images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GeoVista is a planning-driven active perception framework that first builds a global exploration plan, then verifies multiple candidate regions through branch-wise local inspection while maintaining an explicit evidence state for cross-region aggregation and de-duplication. It introduces APEX-GRO, a cold-start supervised trajectory corpus that reformulates diverse UHR tasks as Global-Region-Object interactive reasoning processes with a unified, scale-invariant spatial representation. The model uses an Observe-Plan-Track mechanism and aligns with a GRPO-based strategy using step-wise rewards for planning, localization, and final answer correctness.
What carries the argument
The Observe-Plan-Track mechanism for global observation, adaptive region inspection, and evidence tracking, enabled by the APEX-GRO trajectory corpus and GRPO alignment with step-wise rewards.
If this is right
- Supports cross-region aggregation of findings while avoiding repeated counts of the same evidence.
- Enables scale-invariant interactive reasoning from global scene to individual objects in one unified format.
- Trains models to produce step-wise rewards for better planning and localization quality.
- Delivers state-of-the-art results on RSHR-Bench, XLRS-Bench, and LRS-VQA through structured exploration.
Where Pith is reading between the lines
- The explicit evidence state could reduce duplication errors when counting small objects scattered over very large areas.
- Branch-wise inspection after a global plan might generalize to other large-image search tasks such as anomaly detection in aerial surveys.
- The trajectory corpus approach could support training for similar active perception in domains beyond remote sensing.
- Parallel branch execution might further improve efficiency once the global plan identifies independent regions.
Load-bearing premise
A global exploration plan followed by branch-wise local inspection with explicit evidence state maintenance will reliably cover sparse tiny evidence across large scenes without losing context or causing duplication.
What would settle it
A direct test showing single-path sequential exploration without global planning or evidence tracking matches or exceeds GeoVista accuracy on RSHR-Bench, XLRS-Bench, and LRS-VQA would challenge the claimed necessity of the multi-branch approach.
Figures









read the original abstract
Interpreting ultra-high-resolution (UHR) remote sensing images requires models to search for sparse and tiny visual evidence across large-scale scenes. Existing remote sensing vision-language models can inspect local regions with zooming and cropping tools, but most exploration strategies follow either a one-shot focus or a single sequential trajectory. Such single-path exploration can lose global context, leave scattered regions unvisited, and revisit or count the same evidence multiple times. To this end, we propose GeoVista, a planning-driven active perception framework for UHR remote sensing interpretation. Instead of committing to one zooming path, GeoVista first builds a global exploration plan, then verifies multiple candidate regions through branch-wise local inspection, while maintaining an explicit evidence state for cross-region aggregation and de-duplication. To enable this behavior, we introduce APEX-GRO, a cold-start supervised trajectory corpus that reformulates diverse UHR tasks as Global-Region-Object interactive reasoning processes with a unified, scale-invariant spatial representation. We further design an Observe-Plan-Track mechanism for global observation, adaptive region inspection, and evidence tracking, and align the model with a GRPO-based strategy using step-wise rewards for planning, localization, and final answer correctness. Experiments on RSHR-Bench, XLRS-Bench, and LRS-VQA show that GeoVista achieves state-of-the-art performance. Code and dataset are available at https://github.com/ryan6073/GeoVista
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GeoVista, a planning-driven active perception framework for interpreting ultra-high-resolution remote sensing images. It first constructs a global exploration plan, then performs branch-wise local inspection while maintaining an explicit evidence state for cross-region aggregation and de-duplication. This is enabled by the APEX-GRO cold-start trajectory corpus (reformulating tasks as Global-Region-Object reasoning), an Observe-Plan-Track mechanism, and GRPO-based step-wise reward alignment for planning, localization, and answer correctness. The central claim is that this approach achieves state-of-the-art performance on RSHR-Bench, XLRS-Bench, and LRS-VQA.
Significance. If the results hold, the work could meaningfully advance active perception for remote sensing by addressing single-path exploration failures on sparse tiny evidence in large scenes. The APEX-GRO corpus and GRPO alignment provide concrete, reproducible resources that could support further research on scale-invariant spatial reasoning and evidence tracking.
major comments (2)
- [Abstract] Abstract: The assertion of state-of-the-art performance on RSHR-Bench, XLRS-Bench, and LRS-VQA is presented without any quantitative metrics, tables, ablation studies, or error analysis, which is load-bearing for verifying whether gains arise from the Observe-Plan-Track mechanism rather than model capacity or benchmark artifacts.
- [Observe-Plan-Track mechanism] Observe-Plan-Track mechanism: The claim that global planning plus branch-wise inspection with explicit evidence state reliably avoids context loss, revisits, and missed regions on sparse targets depends on the effectiveness of APEX-GRO and GRPO alignment, yet the manuscript supplies no targeted validation, failure-case analysis, or comparison to single-path baselines that would substantiate this attribution.
minor comments (1)
- [Code and dataset availability] The GitHub link for code and dataset is provided, but the manuscript lacks any description of experimental setup details, hyperparameter choices, or reproducibility instructions that would allow independent verification.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the abstract and provide additional targeted validation for the Observe-Plan-Track mechanism.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion of state-of-the-art performance on RSHR-Bench, XLRS-Bench, and LRS-VQA is presented without any quantitative metrics, tables, ablation studies, or error analysis, which is load-bearing for verifying whether gains arise from the Observe-Plan-Track mechanism rather than model capacity or benchmark artifacts.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The full manuscript contains detailed tables, ablations, and error analysis in Sections 4 and 5, but the abstract currently states the SOTA claim without specific numbers. In the revision we will update the abstract to report the main accuracy gains on each benchmark (e.g., absolute improvements over the strongest baselines) so readers can immediately assess the contribution. revision: yes
-
Referee: [Observe-Plan-Track mechanism] Observe-Plan-Track mechanism: The claim that global planning plus branch-wise inspection with explicit evidence state reliably avoids context loss, revisits, and missed regions on sparse targets depends on the effectiveness of APEX-GRO and GRPO alignment, yet the manuscript supplies no targeted validation, failure-case analysis, or comparison to single-path baselines that would substantiate this attribution.
Authors: We acknowledge the value of more explicit attribution. The current manuscript already reports comparisons against single-path baselines and component ablations in Sections 4.3–4.4. To directly address the request for targeted validation, we will add a dedicated subsection containing (1) quantitative metrics on revisit rate and region coverage, (2) failure-case analysis with qualitative examples of context loss in single-path runs, and (3) side-by-side evidence-tracking visualizations. These additions will make the contribution of the Observe-Plan-Track mechanism clearer. revision: yes
Circularity Check
No significant circularity; new framework components are independently constructed
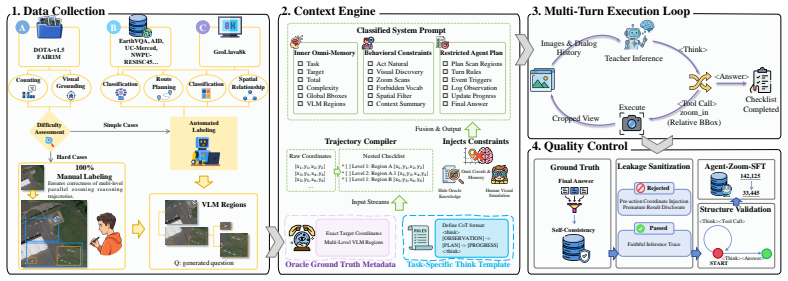
full rationale
The paper proposes GeoVista as a novel planning-driven active perception framework that first builds a global exploration plan then performs branch-wise local inspection with explicit evidence state maintenance. This is enabled by the newly introduced APEX-GRO cold-start corpus (reformulating tasks as Global-Region-Object reasoning) and an Observe-Plan-Track mechanism aligned via GRPO step-wise rewards. All core claims rest on these new constructions plus empirical SOTA results on RSHR-Bench, XLRS-Bench, and LRS-VQA rather than any derivation, equation, or parameter fit that reduces to the inputs by construction. No self-citations are load-bearing, no uniqueness theorems are imported from the authors' prior work, and no ansatz or known result is smuggled in via citation. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language models can be effectively aligned using step-wise rewards for planning, localization, and answer correctness in remote sensing tasks.
invented entities (3)
-
GeoVista framework
no independent evidence
-
APEX-GRO dataset
no independent evidence
-
Observe-Plan-Track mechanism
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GeoVista first builds a global exploration plan, then verifies multiple candidate regions through branch-wise local inspection, while maintaining an explicit evidence state for cross-region aggregation and de-duplication.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Observe-Plan-Track mechanism for global observation, adaptive region inspection, and evidence tracking
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Gong Cheng, Xiang Yuan, Xiwen Yao, Kebing Yan, Qinghua Zeng, Xingxing Xie, and Junwei Han. Towards large-scale small object detection: Survey and benchmarks.IEEE transactions on pattern analysis and machine intelligence, 45(11):13467–13488, 2023
work page 2023
-
[2]
Yansheng Li, Linlin Wang, Tingzhu Wang, Xue Yang, Junwei Luo, Qi Wang, Youming Deng, Wenbin Wang, Xian Sun, Haifeng Li, et al. Star: A first-ever dataset and a large-scale benchmark for scene graph generation in large-size satellite imagery.IEEE Trans. Pattern Anal. Mach. Intell., 47(3):1832–1849, 2025
work page 2025
-
[3]
Junwei Luo, Yingying Zhang, Xue Yang, Kang Wu, Qi Zhu, Lei Liang, Jingdong Chen, and Yansheng Li. When large vision-language model meets large remote sensing imagery: Coarse- to-fine text-guided token pruning.ArXiv, abs/2503.07588, 2025
-
[4]
Fengxiang Wang, Mingshuo Chen, Yueying Li, Yajie Yang, Yifan Zhang, Long Lan, Xue Yang, Hongda Sun, Yulin Wang, Di Wang, et al. Geoeyes: On-demand visual focusing for evidence-grounded understanding of ultra-high-resolution remote sensing imagery.arXiv preprint arXiv:2602.14201, 2026
-
[5]
Geollava-8k: Scaling remote-sensing multimodal large language models to 8k resolution
Fengxiang Wang, Mingshuo Chen, Yueying Li, Di Wang, Haotian Wang, Zonghao Guo, Zefan Wang, Boqi Shan, Long Lan, Yulin Wang, Hongzhen Wang, Wenjing Yang, Bo Du, and Jing Zhang. Geollava-8k: Scaling remote-sensing multimodal large language models to 8k resolution. ArXiv, abs/2505.21375, 2025
-
[6]
Ruixun Liu, Bowen Fu, Jiayi Song, Kaiyu Li, Wanchen Li, Lanxuan Xue, Hui Qiao, Weizhan Zhang, Deyu Meng, and Xiangyong Cao. Zoomearth: Active perception for ultra-high-resolution geospatial vision-language tasks.arXiv preprint arXiv:2511.12267, 2025
-
[7]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.ArXiv, abs/2304.08485, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26286–26296, 2023
work page 2024
-
[11]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer.ArXiv, abs/2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond, 2023
work page 2023
-
[13]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Ke-Yang Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision- language model’s perception of the world at any resolution.ArXiv, abs/2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. A...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Rsgpt: A remote sensing vision language model and benchmark.ArXiv, abs/2307.15266, 2023
Yuan Hu, Jianlong Yuan, Congcong Wen, Xiaonan Lu, and Xiang Li. Rsgpt: A remote sensing vision language model and benchmark.ArXiv, abs/2307.15266, 2023
-
[16]
Yangfan Zhan, Zhitong Xiong, and Yuan Yuan. Skyeyegpt: Unifying remote sensing vision- language tasks via instruction tuning with large language model.ArXiv, abs/2401.09712, 2024
-
[17]
Kartik Kuckreja, Muhammad Sohail Danish, Muzammal Naseer, Abhijit Das, Salman H. Khan, and Fahad Shahbaz Khan. Geochat:grounded large vision-language model for remote sensing. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 27831–27840, 2023
work page 2024
-
[18]
Yan Shu, Bin Ren, Zhitong Xiong, Danda Pani Paudel, Luc Van Gool, Begüm Demir, Nicu Sebe, and Paolo Rota. Earthmind: Leveraging cross-sensor data for advanced earth observation interpretation with a unified multimodal llm, 2025
work page 2025
-
[19]
Junjue Wang, Yanfei Zhong, Zihang Chen, Zhuo Zheng, Ailong Ma, and Liangpei Zhang. Earthvl: A progressive earth vision-language understanding and generation framework.ArXiv, abs/2601.02783, 2026
-
[20]
Zhao yu Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, Linjie Li, Yu Cheng, Heng Ji, Junxian He, and Yi R. Fung. Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers. ArXiv, abs/2506.23918, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deepeyes: Incentivizing" thinking with images" via reinforcement learning.arXiv preprint arXiv:2505.14362, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Yong Xien Chng, Tao Hu, Wenwen Tong, Xueheng Li, Jiandong Chen, Haojia Yu, Jiefan Lu, Hewei Guo, Hanming Deng, Chengjun Xie, et al. Sensenova-mars: Empowering multimodal agentic reasoning and search via reinforcement learning.arXiv preprint arXiv:2512.24330, 2025
-
[23]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Xu Tang, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
MedVR: Annotation-Free Medical Visual Reasoning via Agentic Reinforcement Learning
Zheng Jiang, Heng Guo, Chengyu Fang, Changchen Xiao, Xinyang Hu, Lifeng Sun, and Minfeng Xu. Medvr: Annotation-free medical visual reasoning via agentic reinforcement learning.arXiv preprint arXiv:2604.08203, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Sylvain Lobry, Diego Marcos, Jesse Murray, and Devis Tuia. Rsvqa: Visual question answering for remote sensing data.IEEE Transactions on Geoscience and Remote Sensing, 58(12):8555– 8566, 2020
work page 2020
-
[26]
Junjue Wang, Zhuo Zheng, Zihang Chen, Ailong Ma, and Yanfei Zhong. Earthvqa: Towards queryable earth via relational reasoning-based remote sensing visual question answering. In Proceedings of the AAAI conference on artificial intelligence, pages 5481–5489, 2024
work page 2024
-
[27]
Dota: A large-scale dataset for object detection in aerial images
Gui-Song Xia, Xiang Bai, Jian Ding, Zhen Zhu, Serge Belongie, Jiebo Luo, Mihai Datcu, Marcello Pelillo, and Liangpei Zhang. Dota: A large-scale dataset for object detection in aerial images. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3974–3983, 2018
work page 2018
-
[28]
Xian Sun, Peijin Wang, Zhiyuan Yan, Feng Xu, Ruiping Wang, Wenhui Diao, Jin Chen, Jihao Li, Yingchao Feng, Tao Xu, et al. Fair1m: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery.ISPRS Journal of Photogrammetry and Remote Sensing, 184:116–130, 2022
work page 2022
-
[29]
Gui-Song Xia, Jingwen Hu, Fan Hu, Baoguang Shi, Xiang Bai, Yanfei Zhong, Liangpei Zhang, and Xiaoqiang Lu. Aid: A benchmark data set for performance evaluation of aerial scene classification.IEEE Transactions on Geoscience and Remote Sensing, 55(7):3965–3981, 2017. 11
work page 2017
-
[30]
Bag-of-visual-words and spatial extensions for land-use clas- sification
Yi Yang and Shawn Newsam. Bag-of-visual-words and spatial extensions for land-use clas- sification. InProceedings of the 18th SIGSPATIAL international conference on advances in geographic information systems, pages 270–279, 2010
work page 2010
-
[31]
Gong Cheng, Junwei Han, and Xiaoqiang Lu. Remote sensing image scene classification: Benchmark and state of the art.Proceedings of the IEEE, 105(10):1865–1883, 2017
work page 2017
-
[32]
Dengxin Dai and Wen Yang. Satellite image classification via two-layer sparse coding with biased image representation.IEEE Geoscience and remote sensing letters, 8(1):173–176, 2010
work page 2010
-
[33]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Anthropic. Introducing claude 4. Technical report, Anthropic, 2025
work page 2025
-
[35]
Shichu Sun, Yichen Zhang, Haolin Song, Zonghao Guo, Chi Chen, Yidan Zhang, Yuan Yao, Zhiyuan Liu, and Maosong Sun. Llava-uhd v3: Progressive visual compression for efficient native-resolution encoding in mllms.ArXiv, abs/2511.21150, 2025
-
[36]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. Deepseek-vl2: Mixture-of-experts vision- language models for advanced multimodal understanding.arXiv preprint arXiv:2412.10302, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Team Glm, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, et al. Chatglm: A family of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Vhm: Versatile and honest vision language model for remote sensing image analysis
Chao Pang, Xingxing Weng, Jiang Wu, Jiayu Li, Yi Liu, Jiaxing Sun, Weijia Li, Shuai Wang, Litong Feng, Gui-Song Xia, et al. Vhm: Versatile and honest vision language model for remote sensing image analysis. InProceedings of the AAAI Conference on Artificial Intelligence, pages 6381–6388, 2025
work page 2025
-
[40]
Earthdial: Turning multi-sensory earth observations to interactive dialogues
Sagar Soni, Akshay Dudhane, Hiyam Debary, Mustansar Fiaz, Muhammad Akhtar Munir, Muhammad Sohail Danish, Paolo Fraccaro, Campbell D Watson, Levente J Klein, Fahad Shah- baz Khan, et al. Earthdial: Turning multi-sensory earth observations to interactive dialogues. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 14303–14313, 2025
work page 2025
-
[41]
Junwei Luo, Yingying Zhang, Xue Yang, Kang Wu, Qi Zhu, Lei Liang, Jingdong Chen, and Yansheng Li. When large vision-language model meets large remote sensing imagery: Coarse- to-fine text-guided token pruning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9206–9217, 2025
work page 2025
-
[42]
Yunqi Zhou, Chengjie Jiang, Chun Yuan, and Jing Li. Look where it matters: Training-free ultra-hr remote sensing vqa via adaptive zoom search.ArXiv, abs/2511.20460, 2025
-
[43]
Asking like Socrates: Socrates helps VLMs understand remote sensing images
Run Shao, Ziyu Li, Zhaoyang Zhang, Linrui Xu, Xinran He, Hongyuan Yuan, Bolei He, Yongxing Dai, Yiming Yan, Yijun Chen, et al. Asking like socrates: Socrates helps vlms understand remote sensing images.arXiv preprint arXiv:2511.22396, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Qwen-agent cookbook: Thinking with images
Qwen Team. Qwen-agent cookbook: Thinking with images. https://github.com/QwenLM/ Qwen-Agent/blob/main/examples/cookbook_think_with_images.ipynb, 2025. Ac- cessed: 2025-09-23
work page 2025
-
[45]
Fengxiang Wang, Hongzhen Wang, Zonghao Guo, Di Wang, Yulin Wang, Mingshuo Chen, Qiang Ma, Long Lan, Wenjing Yang, Jing Zhang, et al. Xlrs-bench: Could your multimodal llms understand extremely large ultra-high-resolution remote sensing imagery? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14325–14336, 2025. 12
work page 2025
-
[46]
A benchmark for ultra-high-resolution remote sensing mllms.arXiv preprint arXiv:2512.17319, 2025
Yunkai Dang, Meiyi Zhu, Donghao Wang, Yizhuo Zhang, Jiacheng Yang, Qi Fan, Yuekun Yang, Wenbin Li, Feng Miao, and Yang Gao. A benchmark for ultra-high-resolution remote sensing mllms.arXiv preprint arXiv:2512.17319, 2025
-
[47]
Wordnet: a lexical database for english.Communications of the ACM, 38(11):39–41, 1995
George A Miller. Wordnet: a lexical database for english.Communications of the ACM, 38(11):39–41, 1995. A Data Construction Pipeline A.1 APEX-GRO Fine-grained Annotation Data Construction Pipeline To generate high-quality, leakage-free, end-to-end reasoning trajectories, APEX-GRO employs an automated and human-in-the-loop pipeline comprising four core mod...
work page 1995
-
[48]
Data Collection & Difficulty Assessment The pipeline first collects samples from multi-source remote sensing datasets (e.g., DOTA-v1.5, FAIR1M, EarthVQA), covering diverse tasks such as counting, visual grounding, route planning, classification, and spatial relationships. To ensure data quality, the system introduces a Difficulty Assessment mechanism, cat...
-
[49]
Context Engine & Constraints Injection After acquiring the foundational data, the context engine is responsible for generating structured prompts. This engine fuses three major input streams: • Trajectory Compiler:Converts raw coordinates into a Nested Checklist to provide structured targets. •Task-Specific SOP Template:Strictly defines the output format ...
work page 2059
-
[50]
Multi-Turn Execution Loop In the multi-turn reasoning phase, the Teacher Inference model engages in closed-loop interaction based on the system prompt, the initial image, and the dialogue history. In each turn, the model first outputs a <Think> process to plan the current step, followed by initiating a <Tool Call> to invoke the zoom_in tool, passing in th...
-
[51]
Quality Control & Leakage Sanitization To ensure the reliability and interpretability of the final SFT data, the generated trajectories must undergo rigorous quality filtering: •Leakage Sanitization:Rejects samples with Pre-action Coordinate Injection. •Structure Validation:Verifies that the data follows a legal interaction graph structure. 13 • Ground Tr...
-
[52]
zoom_in: { "name": "zoom_in", "arguments": { "source_image_id": "<COPY_EXACT_ID_HERE>", "bbox": [x_min, y_min, x_max, y_max] } } * ID RULE: The source_image_id MUST be copied EXACTLY from theCurrent View: line in the most recent [System Observation]. DO NOT guess! * BBOX RULE: The bbox MUST be strictly RELATIVE to the CURRENT view on a 0-1000 scale. [0, 0...
-
[53]
ONE STEP AT A TIME: You must either explore using a tool OR output the final answer. NEVER DO BOTH IN ONE TURN
-
[54]
Do NOT hallucinate the tool result
IF CALLING A TOOL: Output your <think> reasoning, then output the <tool_call>, and then STOP IMMEDIATELY . Do NOT hallucinate the tool result. Wait for the [System Observation] to return the cropped image
-
[55]
Place your final answer inside the <answer></answer> tags
FINAL ANSWER: Once your investigation is complete, follow the specific output format required by your current Task (e.g., an integer count, a bounding box, or a classification letter). Place your final answer inside the <answer></answer> tags. Table 5: System Prompt 17 Prompt for Hierarchical Counting Interleaved CoT Generation Task: Global-Context Counti...
- [56]
-
[57]
Scan carefully across the entire image
-
[58]
MANDATORY FORMAT: You MUST explicitly list the accurate global coordinates [xmin, ymin, xmax, ymax] that enclose EVERY target you find inside your <think> block, strictly using this bulleted format: • Obj: [xmin, ymin, xmax, ymax] • Obj: [xmin, ymin, xmax, ymax]
-
[59]
NO PLANS: Do not write a [PLAN] or [PROGRESS]. Just list the objects
-
[60]
Task: Region-Exploration Counting Algorithm SOP (MAXIMUM 1 LAYER):
ONLY after closing </think>, output the final count in <answer>. Task: Region-Exploration Counting Algorithm SOP (MAXIMUM 1 LAYER):
-
[61]
• REASONING: Explicitly explain your zoom strategy
INITIAL REASONING & PLAN (Turn 1 ONLY): Observe the global view. • REASONING: Explicitly explain your zoom strategy. IF targets are clustered, state that you see specific clusters and will use custom boxes. IF targets are scattered globally, state that they are too dispersed and you will use a 4-quadrant split. • PLAN: After reasoning, write your checklis...
-
[62]
• PROGRESS: Update your checklist under [PROGRESS] (mark completed with [x])
EXECUTION & PROGRESS (Turn 2+): • REASONING: Briefly explain what you are examining in the current cropped view. • PROGRESS: Update your checklist under [PROGRESS] (mark completed with [x]). DO NOT output [PLAN] again
-
[63]
LOCAL SUMMARY (SPATIAL FILTERING): Whenever you inspect a cropped image, explicitly list the accurate GLOBAL coordinates formatted strictly as * Obj: [xmin, ymin, xmax, ymax] ONLY for objects that physically fall within the current crop
-
[64]
Group and dump ALL the global bounding boxes you calculated
FINAL AGGREGATION: ONLY when your [PROGRESS] shows all items as [x], you MUST write a [FINAL AGGREGATION] section. Group and dump ALL the global bounding boxes you calculated
-
[65]
Task: Object-Targeted Counting Algorithm SOP (MAXIMUM 2 LAYERS):
Close </think>, then output the total integer count in <answer>. Task: Object-Targeted Counting Algorithm SOP (MAXIMUM 2 LAYERS):
-
[66]
INITIAL REASONING & PLAN (Turn 1 ONLY): • REASONING: Explain your Layer 1 zoom strategy based on target distribution (Clustered vs. Scattered). • PLAN: Write your Layer 1 checklist under [PLAN]. NEVER use [0, 0, 1000, 1000]
-
[67]
• PROGRESS: Update your checklist under [PROGRESS]
EXECUTION & PROGRESS (Turn 2+): • REASONING: Before acting, briefly explain your visual findings in the current crop and whether a Layer 2 zoom is needed. • PROGRESS: Update your checklist under [PROGRESS]. Append Layer 2 zooms as indented nested items if necessary. DO NOT output [PLAN] again
-
[68]
LOCAL SUMMARY (SPATIAL FILTERING): For EVERY object found INSIDE THE CURRENT CROP, list the accurate GLOBAL coordinates strictly formatted as * Obj: [xmin, ymin, xmax, ymax]
-
[69]
FINAL AGGREGATION: ONLY when your [PROGRESS] is completely exhausted (all items are [x]), you MUST write a [FINAL AGGREGATION] section listing EVERY single global bounding box you discovered, grouped by region
-
[70]
Ensure </think> is closed BEFORE outputting <answer>. Table 6: Prompt for Hierarchical Counting CoT 18 Prompt for Visual Grounding Interleaved CoT Generation Task: Visual Grounding Algorithm SOP (DYNAMIC ZOOMING, MAXIMUM 2 LAYERS):
-
[71]
Observe the global view to locate the specific target described in the prompt
-
[72]
SMART ZOOM DECISION (Dynamic): •No Zoom:If the target is large and clearly visible in the global view, do NOT zoom. • Targeted Zoom:If the target is small or unclear, execute a precise ‘zoom_in’ on the region containing it. • Recursive Zoom:If it is STILL unclear in the cropped image, execute a secondary ‘zoom_in’ on that crop
-
[74]
IMMEDIATE GLOBAL MAPPING: Once you can clearly identify the target, state your finding and immediately output its exact GLOBAL coordinates [xmin, ymin, xmax, ymax] (0-1000 scale) inside your <think> block
-
[75]
CONFIDENT FINAL ANSWER: In your final turn, explicitly restate the exact global bounding box inside your <think> block
-
[76]
Close </think>, then output ONLY the exact global bounding box array in <answer> (e.g., <answer>[xmin, ymin, xmax, ymax]</answer>). Table 7: Prompt for Visual Grounding CoT Prompt for Classification Interleaved CoT Generation Task: Image/Object Classification Algorithm SOP (DYNAMIC ZOOMING, MAXIMUM 1 LAYER):
-
[77]
Observe the given view and read the multiple-choice options provided in the prompt carefully
-
[78]
SMART ZOOM DECISION (Dynamic): • No Zoom (Preferred for Global/Low-Res):If the image resolution is low, or the overall scene/object is already clear enough to classify, do NOT use ‘zoom_in’ tools. • Targeted Zoom:If the image is large and the specific object mentioned in the prompt is too small to recognize confidently, plan ONE precise ‘ zoom_in’ to conf...
-
[79]
VISUAL FEATURE DEDUCTION: Before concluding, explicitly describe the visual features, textures, colors, or structural layouts you observe that match one of the given categories
-
[80]
CONFIDENT CONCLUSION: State which option best aligns with your visual analysis
-
[81]
FINAL OUTPUT FORMAT: Close </think>, then output ONLY the exact letter corre- sponding to the correct answer inside <answer> (e.g., <answer>A</answer>). Table 8: Prompt for Classification CoT Prompt for Spatial Relationship Interleaved CoT Generation Task: Spatial Relationship Algorithm SOP (DYNAMIC ZOOMING, MAXIMUM 2 LAYERS):
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.