Recognition: no theorem link
GroupMemBench: Benchmarking LLM Agent Memory in Multi-Party Conversations
Pith reviewed 2026-05-15 01:50 UTC · model grok-4.3
The pith
Benchmarking shows leading LLM memory systems reach only 46 percent accuracy in multi-party conversations, with BM25 matching most.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
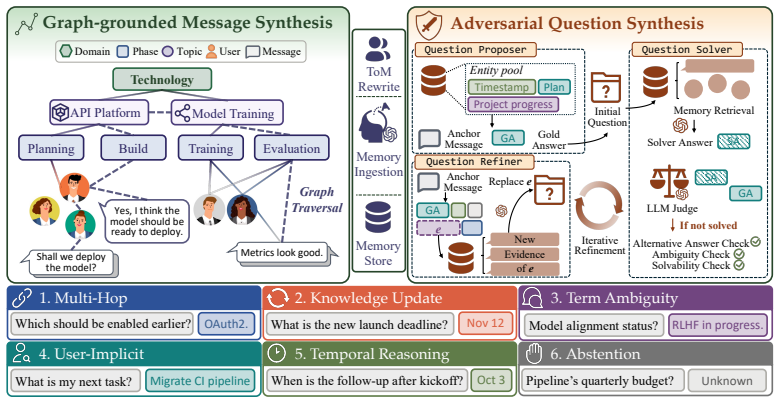
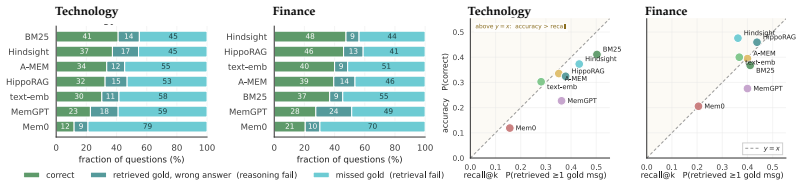
GroupMemBench uses a graph-grounded synthesis pipeline to produce multi-party conversations with controllable reply structure, each message conditioned on per-user personas and target audiences, together with an adversarial query pipeline that binds every question to a specific asker and iteratively searches challenging instances across multi-hop reasoning, knowledge update, term ambiguity, user-implicit reasoning, temporal reasoning, and abstention. Benchmarking leading memory systems on the resulting data shows a maximum average accuracy of 46.0 percent, with knowledge update at 27.1 percent and term ambiguity at 37.7 percent, while a basic BM25 baseline matches or exceeds most agent-based
What carries the argument
GroupMemBench, a benchmark whose graph-grounded synthesis pipeline generates multi-party conversations conditioned on per-user personas and audiences, paired with an adversarial query pipeline that produces asker-specific questions across six categories.
If this is right
- Memory systems must explicitly track per-user beliefs rather than flattening conversations into a single stream.
- Ingestion methods need to preserve reply structures and audience-specific lexical choices to support group interactions.
- Knowledge-update and term-ambiguity handling require dedicated improvements before multi-user memory becomes reliable.
- Simple lexical retrieval remains competitive, showing that architectural complexity alone does not solve group memory.
- Comprehensive testing must include abstention and implicit-reasoning queries to avoid overestimating capability.
Where Pith is reading between the lines
- Applying the same evaluation protocol to logs from actual workplace group chats would reveal whether synthesized data under- or over-states real difficulties.
- Future agent architectures could embed explicit user-identity graphs and audience modeling to retain the features the benchmark shows are currently lost.
- Collaborative AI tools in multi-user environments might first adopt hybrid retrieval-plus-persona tracking before pursuing fully agentic memory.
- Scaling the benchmark to groups larger than those synthesized here could expose additional scaling limits in current memory ingestion.
Load-bearing premise
The graph-grounded synthesis pipeline and adversarial query generation produce conversations and questions that faithfully capture group dynamics, speaker-grounded belief tracking, and audience-adapted language as they occur in real deployments.
What would settle it
Running the same leading memory systems on a corpus of genuine recorded multi-party chat logs and observing whether accuracy rises substantially above 46 percent or whether the performance gap to BM25 disappears would falsify the central performance claim.
Figures



read the original abstract
Large Language Model (LLM) agents increasingly serve as personal assistants and workplace collaborators, where their utility depends on memory systems that extract, retrieve, and apply information across long-running conversations. However, both existing memory systems and benchmarks are built around the dyadic, single-user setup, even though real deployments routinely span groups and channels with multiple users interacting with the agent and with each other. This mismatch leaves three properties of group memory unmeasured: (i) group dynamics that go beyond concatenated one-on-one chats, (ii) speaker-grounded belief tracking, where the per-user memory modeling is needed, and (iii) audience-adapted language, where Theory-of-Mind shifts produce role-specific vocabulary. We introduce GroupMemBench, a benchmark that exposes all three. A graph-grounded synthesis pipeline produces multi-party conversations with controllable reply structure and conditions each message on per-user personas and target audiences. An adversarial query pipeline then binds every question to a specific asker across six categories, spanning multi-hop reasoning, knowledge update, term ambiguity, user-implicit reasoning, temporal reasoning, and abstention, and iteratively searches challenging, realistic queries that reflect comprehensive memory capability. Benchmarking leading memory systems exposes a sharp collapse: the strongest one reaches only 46.0% average accuracy, with knowledge update at 27.1% and term ambiguity at 37.7%, while a simple BM25 baseline matches or exceeds most agent memory systems. This indicates current memory ingestion erases the structural and lexical features group memory depends on, leaving multi-user memory far from solved.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GroupMemBench, a benchmark for LLM agent memory in multi-party conversations. It identifies three unmeasured properties of group memory (group dynamics beyond concatenated dyads, speaker-grounded belief tracking, and audience-adapted language via Theory-of-Mind shifts) and constructs the benchmark via a graph-grounded synthesis pipeline that generates controllable multi-party conversations conditioned on per-user personas and target audiences, followed by an adversarial query pipeline that binds questions to specific askers across six categories (multi-hop reasoning, knowledge update, term ambiguity, user-implicit reasoning, temporal reasoning, abstention). Evaluation of leading memory systems shows a sharp collapse, with the strongest system reaching only 46.0% average accuracy (knowledge update at 27.1%, term ambiguity at 37.7%), while a simple BM25 baseline matches or exceeds most systems.
Significance. If the synthetic conversations and queries are representative, the work demonstrates that current memory ingestion pipelines erase structural and lexical features required for group memory, establishing a clear performance ceiling and motivating new architectures that preserve per-speaker and audience-specific information. The controllable generation pipeline and competitive baseline comparison provide a falsifiable signal that the gap is not an artifact of any single system.
minor comments (3)
- [§4.1] §4.1: The six query categories are well-defined, but adding one concrete example query per category (with its grounding in the conversation graph) would improve reproducibility and reader intuition for how adversarial search operates.
- [Table 2] Table 2: The per-system, per-category accuracy table lacks standard deviations or query counts per cell; including these would allow assessment of whether the reported gaps (e.g., 27.1% on knowledge update) are statistically stable.
- [Figure 2] Figure 2: The pipeline diagram clearly shows persona conditioning, but the distinction between speaker-grounded belief edges and audience-adaptation edges could be labeled more explicitly to avoid conflation with simple concatenation.
Simulated Author's Rebuttal
We thank the referee for their accurate summary of GroupMemBench and for recommending minor revision. The assessment correctly identifies the benchmark's focus on unmeasured group-memory properties and the performance gap relative to the BM25 baseline. We will incorporate minor clarifications and improvements in the revised version.
Circularity Check
No significant circularity
full rationale
The paper introduces GroupMemBench via a graph-grounded synthesis pipeline for multi-party conversations and an adversarial query generator; these steps are described as constructive procedures that generate new test instances rather than fitting parameters to existing results or re-deriving the benchmark from its own outputs. Evaluation proceeds by running external memory systems and a BM25 baseline on the generated data, with reported accuracies (46.0% max, 27.1% on knowledge update) serving as direct measurements rather than predictions that collapse back to fitted inputs. No self-citation chain, uniqueness theorem, or ansatz is invoked to justify the central claims; the benchmark construction and comparison remain independent of the tested systems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Graph-grounded synthesis with per-user personas and target audiences produces conversations that expose the three group memory properties
Reference graph
Works this paper leans on
-
[1]
OpenClaw-RL: Train Any Agent Simply by Talking
Yinjie Wang, Xuyang Chen, Xiaolong Jin, Mengdi Wang, and Ling Yang. Openclaw-rl: Train any agent simply by talking.arXiv preprint arXiv:2603.10165, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
Renjun Xu and Yang Yan. Agent skills for large language models: Architecture, acquisition, security, and the path forward.arXiv preprint arXiv:2602.12430, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Trust in ai chatbots: A systematic review.Telematics and Informatics, 97:102240, 2025
Sheryl Wei Ting Ng and Renwen Zhang. Trust in ai chatbots: A systematic review.Telematics and Informatics, 97:102240, 2025
work page 2025
-
[4]
Personal llm agents: Insights and survey about the capability, efficiency and security
Yuanchun Li, Hao Wen, Weijun Wang, Xiangyu Li, Yizhen Yuan, Guohong Liu, Jiacheng Liu, Wenxing Xu, Xiang Wang, Yi Sun, et al. Personal llm agents: Insights and survey about the capability, efficiency and security.arXiv preprint arXiv:2401.05459, 2024
-
[5]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
work page 2024
-
[6]
An introduction to microsoft copilot
Jess Stratton. An introduction to microsoft copilot. InCopilot for Microsoft 365: harness the power of generative AI in the Microsoft apps you use every day, pages 19–35. Springer, 2024
work page 2024
-
[7]
Wei-Chieh Huang, Weizhi Zhang, Yueqing Liang, Yuanchen Bei, Yankai Chen, Tao Feng, Xinyu Pan, Zhen Tan, Yu Wang, Tianxin Wei, et al. Rethinking memory mechanisms of foundation agents in the second half.arXiv preprint arXiv:2602.06052, 2026
-
[8]
Chris Latimer, Nicoló Boschi, Andrew Neeser, Chris Bartholomew, Gaurav Srivastava, Xuan Wang, and Naren Ramakrishnan. Hindsight is 20/20: Building agent memory that retains, recalls, and reflects.arXiv preprint arXiv:2512.12818, 2025
-
[9]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Zexue He, Yu Wang, Churan Zhi, Yuanzhe Hu, Tzu-Ping Chen, Lang Yin, Ze Chen, Tong Arthur Wu, Siru Ouyang, Zihan Wang, et al. Memoryarena: Benchmarking agent memory in interde- pendent multi-session agentic tasks.arXiv preprint arXiv:2602.16313, 2026
-
[11]
Ama-bench: Evaluating long-horizon memory for agentic applications, 2026
Yujie Zhao, Boqin Yuan, Junbo Huang, Haocheng Yuan, Zhongming Yu, Haozhou Xu, Lanxiang Hu, Abhilash Shankarampeta, Zimeng Huang, Wentao Ni, et al. Ama-bench: Evaluating long- horizon memory for agentic applications.arXiv preprint arXiv:2602.22769, 2026
-
[12]
MemoryBench: A Benchmark for Memory and Continual Learning in LLM Systems
Qingyao Ai, Yichen Tang, Changyue Wang, Jianming Long, Weihang Su, and Yiqun Liu. Memorybench: A benchmark for memory and continual learning in llm systems.arXiv preprint arXiv:2510.17281, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- memeval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Theory of mind.Current biology, 15(17):R644–R645, 2005
Chris Frith and Uta Frith. Theory of mind.Current biology, 15(17):R644–R645, 2005
work page 2005
-
[15]
Fantom: A benchmark for stress-testing machine theory of mind in interactions
Hyunwoo Kim, Melanie Sclar, Xuhui Zhou, Ronan Bras, Gunhee Kim, Yejin Choi, and Maarten Sap. Fantom: A benchmark for stress-testing machine theory of mind in interactions. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 14397–14413, 2023
work page 2023
-
[16]
Tomato: Verbalizing the mental states of role-playing llms for benchmarking theory of mind
Kazutoshi Shinoda, Nobukatsu Hojo, Kyosuke Nishida, Saki Mizuno, Keita Suzuki, Ryo Masumura, Hiroaki Sugiyama, and Kuniko Saito. Tomato: Verbalizing the mental states of role-playing llms for benchmarking theory of mind. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 1520–1528, 2025
work page 2025
-
[17]
Herbert H Clark and Susan E Brennan. Grounding in communication. 1991. 11
work page 1991
-
[18]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
work page 2020
-
[19]
Bernal J Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. Hipporag: Neurobio- logically inspired long-term memory for large language models.Advances in neural information processing systems, 37:59532–59569, 2024
work page 2024
-
[20]
Evaluating very long-term conversational memory of llm agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851–13870, 2024
work page 2024
-
[21]
Yuanzhe Hu, Yu Wang, and Julian McAuley. Evaluating memory in llm agents via incremental multi-turn interactions.arXiv preprint arXiv:2507.05257, 2025
-
[22]
Chuanrui Hu, Tong Li, Xingze Gao, Hongda Chen, Dannong Xu, Yi Bai, Tianwei Lin, Xinda Zhao, Xiaohong Li, Jiaqi An, et al. Evermembench: Benchmarking long-term interactive memory in large language modelsevermembench: Benchmarking long-term interactive memory in large language models.arXiv preprint arXiv:2602.01313, 2026
-
[23]
Memorybank: Enhancing large language models with long-term memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 19724–19731, 2024
work page 2024
-
[24]
A survey on the memory mechanism of large language model-based agents
Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. A survey on the memory mechanism of large language model-based agents. ACM Transactions on Information Systems, 43(6):1–47, 2025
work page 2025
-
[25]
In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents
Zhen Tan, Jun Yan, I-Hung Hsu, Rujun Han, Zifeng Wang, Long Le, Yiwen Song, Yanfei Chen, Hamid Palangi, George Lee, et al. In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8416–8439, 2025
work page 2025
-
[26]
Bowen Jiang, Yuan Yuan, Maohao Shen, Zhuoqun Hao, Zhangchen Xu, Zichen Chen, Ziyi Liu, Anvesh Rao Vijjini, Jiashu He, Hanchao Yu, et al. Personamem-v2: Towards person- alized intelligence via learning implicit user personas and agentic memory.arXiv preprint arXiv:2512.06688, 2025
-
[27]
MAGMA: A Multi-Graph based Agentic Memory Architecture for AI Agents
Dongming Jiang, Yi Li, Guanpeng Li, and Bingzhe Li. Magma: A multi-graph based agentic memory architecture for ai agents.arXiv preprint arXiv:2601.03236, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Memgpt: towards llms as operating systems
Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonza- lez. Memgpt: towards llms as operating systems. 2023
work page 2023
-
[29]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Membench: Towards more comprehensive evaluation on the memory of llm-based agents
Haoran Tan, Zeyu Zhang, Chen Ma, Xu Chen, Quanyu Dai, and Zhenhua Dong. Membench: Towards more comprehensive evaluation on the memory of llm-based agents. InFindings of the Association for Computational Linguistics: ACL 2025, pages 19336–19352, 2025
work page 2025
-
[31]
G-eval: Nlg evaluation using gpt-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment. InProceedings of the 2023 conference on empirical methods in natural language processing, 2023
work page 2023
-
[32]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130, 2024. 12 A Graph Schema Node types and attributes.The synthesis graph G contains four structu...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
If the suffix contains any ofincorrect,wrong, ornot correct, the verdict isIncorrect
-
[34]
Otherwise, if the suffix containscorrect, the verdict isCorrect
-
[35]
Otherwise, the verdict is recorded asUnclearand excluded from the accuracy denominator. Negative phrases are checked first becausenot correct is a substring of the positive trigger; the implementation is ineval_lib.py(lines 146–152). Reliability check.We manually re-examined 100 (question, gold answer, predicted answer, judge verdict) tuples sampled from ...
work page 2025
-
[37]
User_7 / Data Analyst / Risk: Formatting Inconsistencies
-
[38]
User_13 / Compliance Officer / 2025-07-19 (Msg_1545)
work page 2025
-
[39]
User_13 / Compliance Officer / 2025-07-23 (Msg_28294)← answer here Agent answer:“Finance and Data Engineering.” Why it works:the gpt-5 agent reads the full top-10 context and surfaces the correct phrasing from rank 7. The pipeline survives because nothing was rewritten—it just relied on a longer effective window than BM25 did. 21 hindsight ✓ Correct(LLM-r...
work page 2025
-
[40]
Author: User_7 / Data Analyst / phase=Risk: Formatting Inconsistencies (early)
-
[41]
Author: User_7 / Data Analyst / phase=Risk: Formatting Inconsistencies (mid)
-
[42]
Author: User_7 / Data Analyst / phase=Risk: Formatting Inconsistencies (late) What was lost.Speaker identity isn’t physically erased ( Author: User_7 is in every retrieved memory) but ithas been ignored at retrieval time: similarity-search returned 22 three near-duplicate posts about the same topic from a single louder speaker, and shadowed User_13’s actu...
-
[43]
Please weigh in from Finance and Data Engineering
User_12 (Compliance Officer): “...Please weigh in from Finance and Data Engineering ...”
-
[44]
cross-functional review: Finance, Data Engineering, QA, and template owners
User_4 (IT Systems Lead): “...cross-functional review: Finance, Data Engineering, QA, and template owners...”
-
[45]
I need Finance and Engineering to confirm
User_12 (Compliance Officer): “...I need Finance and Engineering to confirm ...” What was lost.The right entities (Finance, Data Engineering)arein the retrieval, but they are scattered across threeotherusers’ requests, each with slightly different counterparty lists. The agent unions the candidate sets rather than honoring the asker’s specific request. Ag...
-
[46]
User_7 (Data Analyst, early phase)
-
[47]
User_7 (Data Analyst, late phase)
-
[48]
Finance, Operations, Reporting Owners, Compliance,Data Engineering, QA, and Template Owners
User_4 (IT Systems Lead, late phase) Agent answer:“Finance, Operations, Reporting Owners, Compliance,Data Engineering, QA, and Template Owners.” Why it fails.Same root cause as hipporag: the asker’s specific request was never retrieved, so the agent assembled a “who-has-ever-been-mentioned” list. The two correct names (Finance, Data Engineering) are in th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.