Recognition: 2 theorem links
· Lean TheoremWhen Robots Do the Chores: A Benchmark and Agent for Long-Horizon Household Task Execution
Pith reviewed 2026-05-15 01:55 UTC · model grok-4.3
The pith
HoloMind agent with DAG planner and dual memories raises long-horizon household task success while cutting dependence on model size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LongAct evaluates high-level autonomy in long-horizon household tasks by abstracting embodiment-specific control, and HoloMind improves results through a DAG-based hierarchical planner, Multimodal Spatial Memory for persistent world modeling, Episodic Memory for experience reuse, and a global Critic for reflective supervision, all while lowering reliance on base-model scale.
What carries the argument
DAG-based long-horizon hierarchical planner combined with Multimodal Spatial Memory, Episodic Memory, and global Critic.
If this is right
- Structured memory and explicit planning let agents manage task dependencies across many steps without larger models.
- Free-form instructions expose gaps in current VLMs that fixed-category benchmarks hide.
- Full-task success stays low even when goal completion improves, indicating that plan repair and recovery remain unsolved.
- The same architecture could be ported to other long-sequence domains once low-level control is reattached.
Where Pith is reading between the lines
- The abstraction may let researchers iterate on planning logic faster than full robot simulators allow.
- If memory modules prove decisive, future agents could store compact scene graphs rather than raw video histories.
- Extending LongAct with cost or time metrics would test whether the planner also produces efficient sequences.
- Hybrid systems that keep explicit memory may scale better than pure end-to-end VLMs for chores lasting tens of minutes.
Load-bearing premise
High-level cognitive skills such as instruction understanding and adaptive planning can be measured accurately once low-level physical control is removed from the task.
What would settle it
A controlled test that adds realistic low-level actuation noise or partial observability to LongAct tasks and checks whether HoloMind's reported gains over baseline VLMs disappear.
Figures









read the original abstract
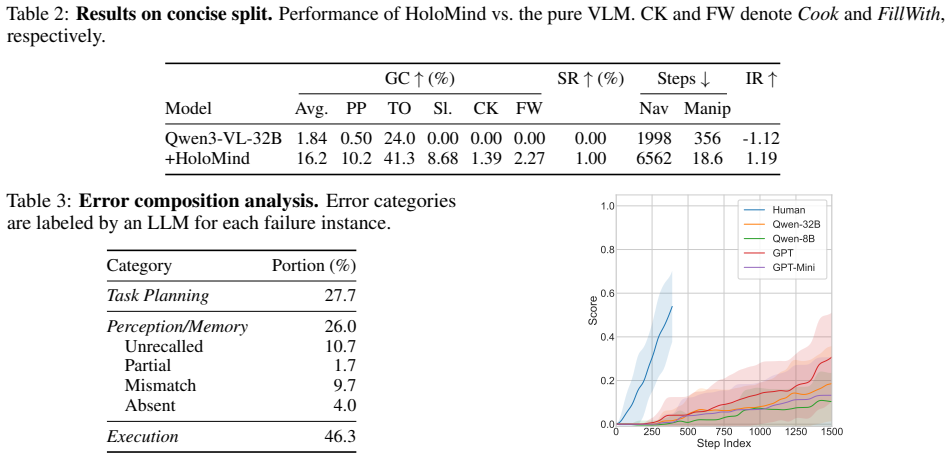
Long-horizon household tasks demand robust high-level planning and sustained reasoning capabilities, which are largely overlooked by existing embodied AI benchmarks that emphasize short-horizon navigation or manipulation and rely on fixed task categories. We introduce LongAct, a benchmark designed to evaluate planning-level autonomy in long-horizon household tasks specified through free-form instructions. By abstracting away embodiment-specific low-level control, LongAct isolates high-level cognitive capabilities such as instruction understanding, dependency management, memory maintenance, and adaptive planning. We further propose HoloMind, a VLM-driven agent with a DAG-based long-horizon hierarchical planner, a Multimodal Spatial Memory for persistent world modeling, an Episodic Memory for experience reuse, and a global Critic for reflective supervision. Experiments with GPT-5 and Qwen3-VL models show that HoloMind substantially improves long-horizon performance while reducing reliance on model scale. Even top models achieve only 59% goal completion and 16% full-task success, underscoring the difficulty of LongAct and the need for stronger long-horizon planning in embodied agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LongAct, a benchmark for long-horizon household task execution that abstracts away embodiment-specific low-level control to isolate high-level capabilities such as instruction understanding, dependency management, memory maintenance, and adaptive planning. It also proposes HoloMind, a VLM-driven agent using a DAG-based hierarchical planner, Multimodal Spatial Memory, Episodic Memory, and a global Critic. Experiments with GPT-5 and Qwen3-VL models report that HoloMind yields substantial gains while reducing reliance on model scale, although absolute performance remains low (59% goal completion, 16% full-task success).
Significance. If the abstraction and results hold, the work addresses a clear gap in embodied AI by providing a benchmark focused on sustained planning rather than short-horizon navigation or manipulation, and demonstrates an agent architecture whose components (DAG planner, persistent multimodal memory, critic) can improve long-horizon performance without larger models. The low absolute success rates supply a concrete, falsifiable signal of remaining challenges in memory and adaptive re-planning.
major comments (3)
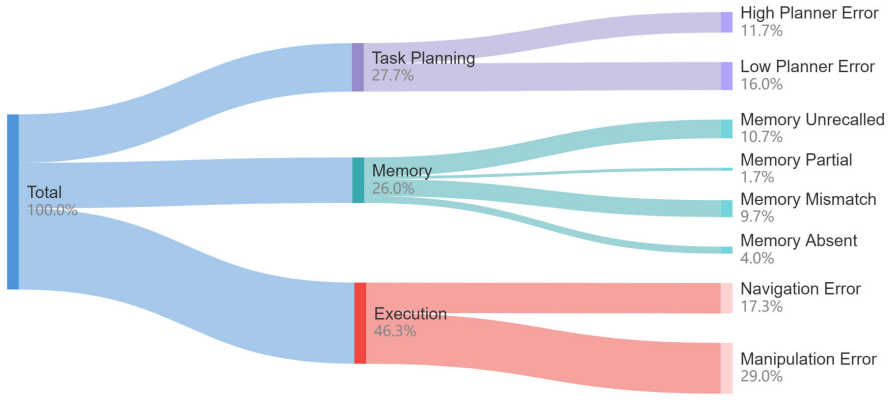
- [§3] §3 (Benchmark Design): The claim that abstracting low-level control successfully isolates high-level cognitive capabilities without losing essential task realism is load-bearing for the entire evaluation; the manuscript provides no analysis or ablation showing how perfect state observations affect cascading re-planning, dependency re-evaluation, or memory updates relative to realistic execution errors (grasp slippage, navigation drift, partial occlusions).
- [§5] §5 (Experiments and Results): The headline metrics (59% goal completion, 16% full-task success) are presented without reported variance across runs, number of trials per task, or statistical tests; this prevents verification that HoloMind's reported gains are robust rather than sensitive to particular task instances or random seeds.
- [§4.1] §4.1 (HoloMind Architecture): The global Critic's reflective supervision mechanism and its precise interface with the DAG planner and Multimodal Spatial Memory are described only at a high level; without explicit update rules or pseudocode, it is impossible to determine whether the reported improvements stem from the critic or from other unablated components.
minor comments (2)
- [Abstract] The abstract and §4 refer to 'GPT-5'; clarify the exact model version used (e.g., GPT-4o or a hypothetical successor) to avoid confusion.
- [Figure 2] Figure 2 (agent overview) would benefit from explicit arrows or labels showing data flow between the Critic, Episodic Memory, and DAG planner.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the benchmark design, experimental reporting, and architectural details. We address each major comment below and will revise the manuscript to incorporate additional analysis, statistical reporting, and implementation specifics where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Design): The claim that abstracting low-level control successfully isolates high-level cognitive capabilities without losing essential task realism is load-bearing for the entire evaluation; the manuscript provides no analysis or ablation showing how perfect state observations affect cascading re-planning, dependency re-evaluation, or memory updates relative to realistic execution errors (grasp slippage, navigation drift, partial occlusions).
Authors: We agree that the abstraction's validity requires explicit validation against execution noise. In the revised manuscript we will add a dedicated ablation subsection that injects simulated errors (navigation drift, grasp failures, and partial occlusions) into the observation stream and quantifies their downstream effects on re-planning frequency, dependency re-evaluation, and memory-update accuracy. This will clarify the extent to which the reported performance gap is attributable to high-level reasoning versus low-level uncertainty. revision: yes
-
Referee: [§5] §5 (Experiments and Results): The headline metrics (59% goal completion, 16% full-task success) are presented without reported variance across runs, number of trials per task, or statistical tests; this prevents verification that HoloMind's reported gains are robust rather than sensitive to particular task instances or random seeds.
Authors: We acknowledge the omission of variance and statistical detail. The original experiments used five independent runs per task; we will report mean and standard deviation for all metrics, specify the exact trial count, and include paired t-tests (or Wilcoxon tests where appropriate) comparing HoloMind against baselines to establish statistical significance of the observed gains. revision: yes
-
Referee: [§4.1] §4.1 (HoloMind Architecture): The global Critic's reflective supervision mechanism and its precise interface with the DAG planner and Multimodal Spatial Memory are described only at a high level; without explicit update rules or pseudocode, it is impossible to determine whether the reported improvements stem from the critic or from other unablated components.
Authors: We agree that the current description is insufficient for reproducibility. In the revision we will expand Section 4.1 with explicit update rules for the Critic, its read/write interface to the DAG planner and Multimodal Spatial Memory, and pseudocode in the appendix. We will also add an ablation that disables the Critic while keeping all other modules fixed, thereby isolating its contribution to the reported performance lift. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces LongAct benchmark by abstracting low-level control to isolate high-level capabilities (instruction understanding, dependency management, memory, adaptive planning) and proposes HoloMind agent with DAG planner, Multimodal Spatial Memory, Episodic Memory, and global Critic. These are presented as independent design choices evaluated via experiments on external models (GPT-5, Qwen3-VL) yielding concrete metrics (59% goal completion, 16% full-task success). No equations, fitted parameters, self-citations, or uniqueness theorems are invoked in a load-bearing way; the derivation from benchmark definition to agent performance does not reduce to inputs by construction and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (3)
-
Multimodal Spatial Memory
no independent evidence
-
Episodic Memory
no independent evidence
-
global Critic
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
HoloMind employs a hierarchical planning architecture in which a high-level planner decomposes instructions into a directed acyclic graph (DAG) of goals... Multimodal Spatial Memory... Episodic Memory... global Critic for reflective supervision.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Improvement Rate (IR) ... slope of the best linear least-squares fit ... ak = L(αk,1, …, αk,k)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
H. Liu, C. Li, Q. Wu, and Y . J. Lee. Visual instruction tuning.Advances in Neural Information Processing Systems, 36:1–19, 2023
work page 2023
-
[4]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities.arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025. 10 Running Title for Header
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Reverie: Remote embodied visual referring expression in real indoor environments
Yuankai Qi, Qi Wu, Peter Anderson, Xin Wang, William Yang Wang, Chunhua Shen, and Anton van den Hengel. Reverie: Remote embodied visual referring expression in real indoor environments. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9982–9991, 2020
work page 2020
-
[8]
Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sünderhauf, Ian Reid, Stephen Gould, and Anton Van Den Hengel. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3674–3683, 2018
work page 2018
-
[9]
Hm3d-ovon: A dataset and benchmark for open-vocabulary object goal navigation
Naoki Yokoyama, Ram Ramrakhya, Abhishek Das, Dhruv Batra, and Sehoon Ha. Hm3d-ovon: A dataset and benchmark for open-vocabulary object goal navigation. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5543–5550. IEEE, 2024
work page 2024
-
[10]
Goat-bench: A benchmark for multi-modal lifelong navigation
Mukul Khanna, Ram Ramrakhya, Gunjan Chhablani, Sriram Yenamandra, Theophile Gervet, Matthew Chang, Zsolt Kira, Devendra Singh Chaplot, Dhruv Batra, and Roozbeh Mottaghi. Goat-bench: A benchmark for multi-modal lifelong navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16373–16383, 2024
work page 2024
-
[11]
Soundspaces: Audio-visual navigation in 3d environments
Changan Chen, Unnat Jain, Carl Schissler, Sebastia Vicenc Amengual Gari, Ziad Al-Halah, Vamsi Krishna Ithapu, Philip Robinson, and Kristen Grauman. Soundspaces: Audio-visual navigation in 3d environments. InEuropean conference on computer vision, pages 17–36. Springer, 2020
work page 2020
-
[12]
Dhruv Batra, Aaron Gokaslan, Aniruddha Kembhavi, Oleksandr Maksymets, Roozbeh Mottaghi, Manolis Savva, Alexander Toshev, and Erik Wijmans. Objectnav revisited: On evaluation of embodied agents navigating to objects.arXiv preprint arXiv:2006.13171, 2020
-
[13]
C-NAV: Towards Self-Evolving Continual Object Navigation in Open World
Ming-Ming Yu, Fei Zhu, Wenzhuo Liu, Yirong Yang, Qunbo Wang, Wenjun Wu, and Jing Liu. C-nav: Towards self-evolving continual object navigation in open world.arXiv preprint arXiv:2510.20685, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Robotwin: Dual-arm robot benchmark with generative digital twins (early version)
Yao Mu, Tianxing Chen, Shijia Peng, Zanxin Chen, Zeyu Gao, Yude Zou, Lunkai Lin, Zhiqiang Xie, and Ping Luo. Robotwin: Dual-arm robot benchmark with generative digital twins (early version). InEuropean Conference on Computer Vision, pages 264–273. Springer, 2024
work page 2024
-
[15]
Alfred: A benchmark for interpreting grounded instructions for everyday tasks
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Zettle- moyer, and Dieter Fox. Alfred: A benchmark for interpreting grounded instructions for everyday tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10740–10749, 2020
work page 2020
-
[16]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning.arXiv preprint arXiv:2010.03768, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[17]
Rearrangement: A challenge for embodied ai.arXiv preprint arXiv:2011.01975, 2020
Dhruv Batra, Angel X Chang, Sonia Chernova, Andrew J Davison, Jia Deng, Vladlen Koltun, Sergey Levine, Jitendra Malik, Igor Mordatch, Roozbeh Mottaghi, et al. Rearrangement: A challenge for embodied ai.arXiv preprint arXiv:2011.01975, 2020
-
[18]
Chuang Gan, Siyuan Zhou, Jeremy Schwartz, Seth Alter, Abhishek Bhandwaldar, Dan Gutfreund, Daniel LK Yamins, James J DiCarlo, Josh McDermott, Antonio Torralba, et al. The threedworld transport challenge: A visually guided task-and-motion planning benchmark towards physically realistic embodied ai. In2022 International conference on robotics and automation...
work page 2022
-
[19]
AI2-THOR: An Interactive 3D Environment for Visual AI
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, et al. Ai2-thor: An interactive 3d environment for visual ai.arXiv preprint arXiv:1712.05474, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
Tutorial on directed acyclic graphs.Journal of Clinical Epidemiology, 142:264–267, 2022
Jean C Digitale, Jeffrey N Martin, and Medellena Maria Glymour. Tutorial on directed acyclic graphs.Journal of Clinical Epidemiology, 142:264–267, 2022
work page 2022
-
[21]
Openai gpt-5 system card, 2025
work page 2025
-
[22]
Habitat: A platform for embodied ai research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. InProceedings of the IEEE/CVF international conference on computer vision, pages 9339–9347, 2019
work page 2019
-
[23]
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
Santhosh K Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alex Clegg, John Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X Chang, et al. Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai.arXiv preprint arXiv:2109.08238, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[24]
Xavier Puig, Tianmin Shu, Shuang Li, Zilin Wang, Yuan-Hong Liao, Joshua B Tenenbaum, Sanja Fidler, and Antonio Torralba. Watch-and-help: A challenge for social perception and human-ai collaboration.arXiv preprint arXiv:2010.09890, 2020. 11 Running Title for Header
-
[25]
Jae-Woo Choi, Youngwoo Yoon, Hyobin Ong, Jaehong Kim, and Minsu Jang. Lota-bench: Benchmarking language-oriented task planners for embodied agents.arXiv preprint arXiv:2402.08178, 2024
-
[26]
Goat-bench: A benchmark for multi-modal lifelong navigation, 2024
Mukul Khanna, Ram Ramrakhya, Gunjan Chhablani, Sriram Yenamandra, Theophile Gervet, Matthew Chang, Zsolt Kira, Devendra Singh Chaplot, Dhruv Batra, and Roozbeh Mottaghi. Goat-bench: A benchmark for multi-modal lifelong navigation, 2024
work page 2024
-
[27]
Karen Liu, Jiajun Wu, and Li Fei-Fei
Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gokmen, Sanjana Srivastava, Roberto Martín-Martín, Chen Wang, Gabrael Levine, Wensi Ai, Benjamin Martinez, Hang Yin, Michael Lingelbach, Minjune Hwang, Ayano Hiranaka, Sujay Garlanka, Arman Aydin, Sharon Lee, Jiankai Sun, Mona Anvari, Manasi Sharma, Dhruva Bansal, Samuel Hunter, Kyu-Young Kim, Alan Lou, Caleb R ...
work page 2024
-
[28]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Siwei Chen, Anxing Xiao, and David Hsu. Llm-state: Expandable state representation for long-horizon task planning in the open world.CoRR, 2023
work page 2023
-
[31]
Krishan Rana, Jesse Haviland, Sourav Garg, Jad Abou-Chakra, Ian Reid, and Niko Suenderhauf. Sayplan: Grounding large language models using 3d scene graphs for scalable robot task planning.arXiv preprint arXiv:2307.06135, 2023
-
[32]
Progprompt: Generating situated robot task plans using large language models
Ishika Singh, Valts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay, Dieter Fox, Jesse Thomason, and Animesh Garg. Progprompt: Generating situated robot task plans using large language models. arXiv preprint arXiv:2209.11302, 2022
-
[33]
Film: Following instructions in language with modular methods.arXiv preprint arXiv:2110.07342, 2021
So Yeon Min, Devendra Singh Chaplot, Pradeep Ravikumar, Yonatan Bisk, and Ruslan Salakhutdinov. Film: Following instructions in language with modular methods.arXiv preprint arXiv:2110.07342, 2021
-
[34]
Qi Zhao, Haotian Fu, Chen Sun, and George Konidaris. Epo: Hierarchical llm agents with environment preference optimization.arXiv preprint arXiv:2408.16090, 2024
-
[35]
Robogpt: an llm-based long-term decision-making embodied agent for instruction following tasks
Yaran Chen, Wenbo Cui, Yuanwen Chen, Mining Tan, Xinyao Zhang, Jinrui Liu, Haoran Li, Dongbin Zhao, and He Wang. Robogpt: an llm-based long-term decision-making embodied agent for instruction following tasks. IEEE Transactions on Cognitive and Developmental Systems, 2025
work page 2025
-
[36]
Llm-planner: Few-shot grounded planning for embodied agents with large language models
Chan Hee Song, Jiaman Wu, Clayton Washington, Brian M Sadler, Wei-Lun Chao, and Yu Su. Llm-planner: Few-shot grounded planning for embodied agents with large language models. InProceedings of the IEEE/CVF international conference on computer vision, pages 2998–3009, 2023
work page 2023
-
[37]
Context-aware planning and environment-aware memory for instruction following embodied agents
Byeonghwi Kim, Jinyeon Kim, Yuyeong Kim, Cheolhong Min, and Jonghyun Choi. Context-aware planning and environment-aware memory for instruction following embodied agents. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10936–10946, 2023
work page 2023
-
[38]
Zijun Lin, Chao Tang, Hanjing Ye, and Hong Zhang. Flowplan: Zero-shot task planning with llm flow engineering for robotic instruction following.arXiv preprint arXiv:2503.02698, 2025
-
[39]
Procthor: Large-scale embodied ai using procedural generation, 2022
Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Jordi Salvador, Kiana Ehsani, Winson Han, Eric Kolve, Ali Farhadi, Aniruddha Kembhavi, and Roozbeh Mottaghi. Procthor: Large-scale embodied ai using procedural generation, 2022
work page 2022
-
[40]
Ai2-thor: An interactive 3d environment for visual ai, 2022
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, Aniruddha Kembhavi, Abhinav Gupta, and Ali Farhadi. Ai2-thor: An interactive 3d environment for visual ai, 2022
work page 2022
-
[41]
Visual language maps for robot navigation, 2023
Chenguang Huang, Oier Mees, Andy Zeng, and Wolfram Burgard. Visual language maps for robot navigation, 2023
work page 2023
-
[42]
Audio visual language maps for robot navigation
Chenguang Huang, Oier Mees, Andy Zeng, and Wolfram Burgard. Audio visual language maps for robot navigation. InProceedings of the International Symposium on Experimental Robotics (ISER), Chiang Mai, Thailand, 2023
work page 2023
-
[43]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 12 Running Title for Header Appendix A Comparison with...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.