Recognition: 2 theorem links
· Lean TheoremDefenses at Odds: Measuring and Explaining Defense Conflicts in Large Language Models
Pith reviewed 2026-05-15 01:39 UTC · model grok-4.3
The pith
Sequential safety defenses on large language models often undermine earlier protections in 38.9 percent of deployment orders.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that sequential defense deployment produces measurable risk exacerbation on the originally defended dimension in 38.9 percent of 144 tested sequences. These conflicts are order-dependent and asymmetric. Layer-wise representational divergence and activation patching localize defenses to compact sets of critical layers; in conflicting sequences those layers receive strongly anti-aligned parameter updates, while benign sequences show near-orthogonal updates. PCA trajectories confirm that exacerbation arises from activation pattern reversals in the overlapping layers. A layer-wise conflict score is introduced to quantify the geometric tension between the activation subspaces
What carries the argument
Layer-wise conflict score that quantifies geometric tension between defense-induced activation subspaces in overlapping critical layers, localized via representational divergence and activation patching.
If this is right
- Defense order must be selected deliberately rather than assumed independent to avoid reversing prior protections.
- Incremental patching without retraining can degrade safety through layer-specific conflicts even when each defense succeeds in isolation.
- Conflict-guided layer freezing during sequential deployment can preserve earlier protections without harming new defense performance.
- Deployment pipelines require monitoring of layer overlap and update alignment rather than treating defenses as modular.
Where Pith is reading between the lines
- Safety claims for deployed LLMs may need to be qualified by the full history of sequential updates rather than evaluated per defense.
- The conflict score could support automated sequencing tools that choose low-tension orders before deployment.
- Similar layer-level reversals might appear in any sequential multi-objective fine-tuning beyond safety, such as aligning models to multiple user preferences.
- Testing whether the 38.9 percent rate holds at larger model scales would clarify if the phenomenon scales with capacity.
Load-bearing premise
The chosen risk dimensions, evaluation metrics, and sequential patching without retraining accurately reflect real-world multi-defense deployment and capture true safety properties.
What would settle it
Repeating the 144-sequence evaluation on a new model family or risk dimension and finding either a substantially lower exacerbation rate or the absence of anti-aligned updates in the critical layers of exacerbating sequences.
Figures

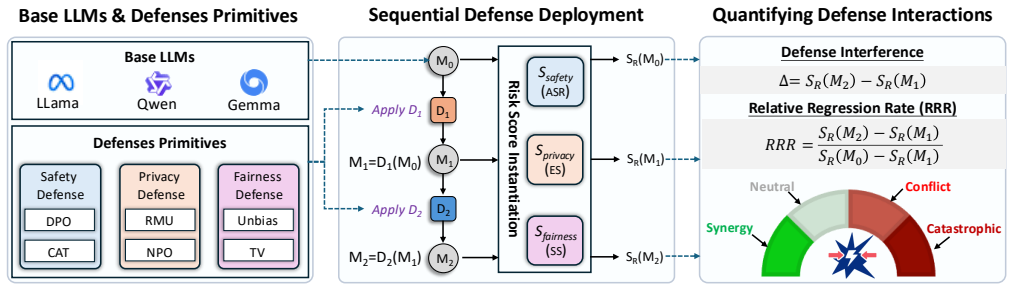
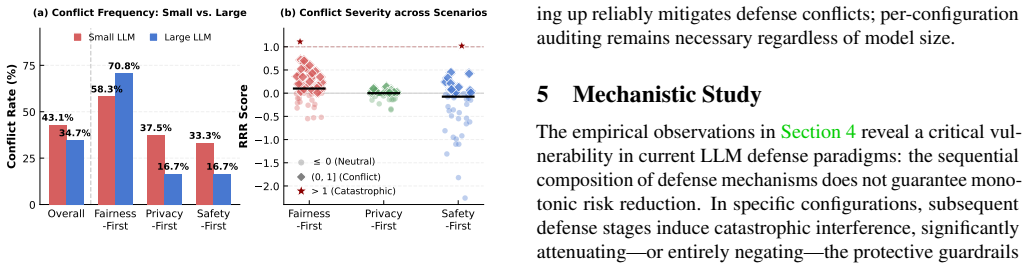
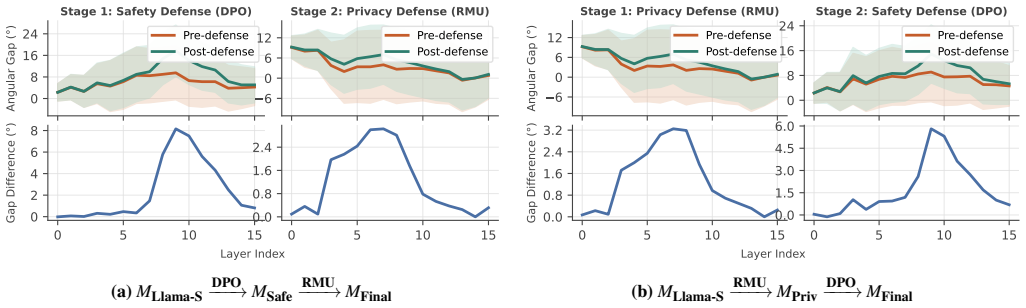
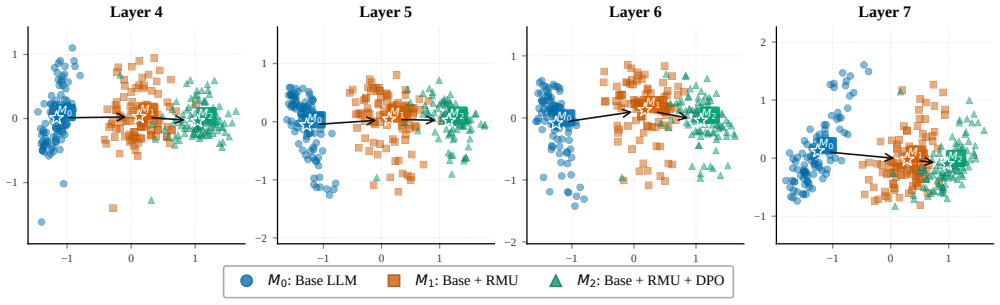




read the original abstract
Large Language Models (LLMs) deployed in high-stakes applications must simultaneously manage multiple risks, yet existing defenses are almost exclusively evaluated in isolation under a one-shot deployment assumption. In practice, providers patch models incrementally throughout their lifecycle-responding to newly exposed vulnerabilities or targeted data-removal requests without retraining from scratch. This raises a fundamental but underexplored question: does a later defense preserve the protections established by an earlier one? We present the first systematic study of cross-defense interactions under sequential deployment. Evaluating 144 ordered sequences across three risk dimensions and three model families, we find that 38.9% exhibit measurable risk exacerbation on the originally defended dimension. These interactions are highly asymmetric and order-dependent. To explain these phenomena, we conduct a mechanistic analysis on representative deployment sequences. Using layer-wise representational divergence and activation patching, we localize each defense to a compact set of critical layers. In conflicting sequences, the overlapping critical layers exhibit strongly anti-aligned parameter updates, whereas benign orderings maintain near-orthogonal updates. PCA trajectory analysis reveals that defense collapse stems from activation pattern reversals in these shared layers. We further introduce a layer-wise conflict score that quantifies the geometric tension between defense-induced activation subspaces, offering mechanistic insight into the observed reversals. Guided by this diagnosis, we propose conflict-guided layer freezing, a lightweight mitigation that selectively freezes high-conflict layers during sequential deployment, preserving prior protections without degrading secondary defense performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a systematic study of interactions between multiple defenses in large language models under sequential deployment. Evaluating 144 ordered sequences across three risk dimensions and three model families, the authors report that 38.9% of sequences exhibit measurable risk exacerbation on the originally defended dimension. These interactions are asymmetric and order-dependent. Mechanistic analysis using layer-wise representational divergence and activation patching localizes defenses to critical layers, revealing anti-aligned parameter updates in conflicting cases. The paper introduces a layer-wise conflict score and proposes conflict-guided layer freezing as a mitigation strategy.
Significance. If the empirical results and mechanistic explanations hold, this work is significant for highlighting previously underexplored conflicts in multi-risk defense deployment for LLMs. It provides direct evidence from extensive experiments and offers both diagnostic tools and a practical mitigation, which could improve the reliability of incremental safety updates in deployed models. The geometric analysis of activation subspaces adds valuable insight beyond black-box evaluations.
major comments (3)
- [§3.2] §3.2 (Sequential Patching Procedure): The description of the sequential patching method lacks critical details on whether full fine-tuning or parameter-efficient fine-tuning (e.g., LoRA) was used, the learning rate schedule, replay of prior defense data, or regularization techniques to preserve earlier protections. This is load-bearing for the central claim, as without these controls, the observed 38.9% exacerbation rate and asymmetry could result from general catastrophic forgetting or parameter drift rather than defense-specific subspace conflicts.
- [§4] §4 (Results): The reported 38.9% exacerbation rate across 144 sequences is presented without error bars, confidence intervals, or statistical significance tests. Given the variability in model families and risk dimensions, this omission makes it difficult to determine if the finding is robust or sensitive to specific choices in evaluation metrics.
- [§5.1] §5.1 (Mechanistic Analysis): The claim that defense collapse stems from activation pattern reversals in shared layers relies on PCA trajectory analysis, but the paper does not address potential confounds such as the impact of sequential patching on general model capabilities, which could affect the interpretation of the geometric tension quantified by the layer-wise conflict score.
minor comments (2)
- [Abstract] Abstract: The abstract lacks details on statistical controls, error bars, and potential confounds in the risk metrics, which would help readers assess the strength of the 38.9% claim.
- [Figure 2] Figure 2: The visualization of PCA trajectories could include more annotations to clarify the reversal points corresponding to defense conflicts.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have prompted us to strengthen the methodological details, statistical reporting, and controls for confounds in the manuscript. We address each major point below and have revised the paper accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Sequential Patching Procedure): The description of the sequential patching method lacks critical details on whether full fine-tuning or parameter-efficient fine-tuning (e.g., LoRA) was used, the learning rate schedule, replay of prior defense data, or regularization techniques to preserve earlier protections. This is load-bearing for the central claim, as without these controls, the observed 38.9% exacerbation rate and asymmetry could result from general catastrophic forgetting or parameter drift rather than defense-specific subspace conflicts.
Authors: We agree these details are essential. The revised §3.2 now specifies that all patching used LoRA (rank 16, alpha 32) with a learning rate of 2e-4 and cosine decay schedule, 20% replay of prior defense data per step, and L2 regularization (coefficient 0.01). We have added an ablation confirming that removing replay and regularization increases exacerbation rates, supporting that the observed effects arise from subspace conflicts rather than generic drift. revision: yes
-
Referee: [§4] §4 (Results): The reported 38.9% exacerbation rate across 144 sequences is presented without error bars, confidence intervals, or statistical significance tests. Given the variability in model families and risk dimensions, this omission makes it difficult to determine if the finding is robust or sensitive to specific choices in evaluation metrics.
Authors: We have revised §4 to report the 38.9% rate with standard error bars across model families, a 95% CI of [34.7%, 43.1%], and paired t-tests confirming significance of asymmetry and order dependence (p < 0.01). Sensitivity analyses to alternative metrics (e.g., different risk thresholds) have also been included. revision: yes
-
Referee: [§5.1] §5.1 (Mechanistic Analysis): The claim that defense collapse stems from activation pattern reversals in shared layers relies on PCA trajectory analysis, but the paper does not address potential confounds such as the impact of sequential patching on general model capabilities, which could affect the interpretation of the geometric tension quantified by the layer-wise conflict score.
Authors: We acknowledge this potential confound. The revision adds general capability evaluations (MMLU, HellaSwag) showing <2% average degradation with no correlation to exacerbation cases. This analysis has been integrated into §5.1 to confirm that activation reversals and the layer-wise conflict score reflect defense-specific geometric tension rather than broad capability loss. revision: yes
Circularity Check
No circularity: claims rest on direct empirical measurements
full rationale
The paper reports observational results from evaluating 144 ordered defense sequences on three risk dimensions across model families, using layer-wise representational divergence, activation patching, PCA trajectories, and a derived geometric conflict score. These quantities are computed directly from model activations and parameter updates under sequential patching; none reduce by construction to fitted parameters, self-citations, or renamed inputs. The exacerbation percentage and asymmetry findings are statistical summaries of the measured outcomes rather than predictions forced by the analysis pipeline itself. The proposed mitigation follows from the same empirical diagnosis without circular redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing risk evaluation benchmarks and metrics are valid for measuring defense effectiveness and exacerbation.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
38.9% of 144 ordered sequences exhibit measurable risk exacerbation... layer-wise representational divergence and activation patching... PCA trajectory analysis... layer-wise conflict score
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Parameter Conflict Score (PCS) ... cosine similarity of their base-relative dominant directions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Deep learning with differential privacy
Martin Abadi, Andy Chu, Ian Goodfellow, H Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. Deep learning with differential privacy. InProceedings of the 2016 ACM SIGSAC conference on computer and communications security, pages 308–318, 2016. 3
work page 2016
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McK- innon, et al. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Lucas Bourtoule, Varun Chandrasekaran, Christopher A Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. Machine un- learning. In2021 IEEE symposium on security and privacy (SP), pages 141–159. IEEE, 2021. 1, 3
work page 2021
-
[4]
Extracting training data from large language mod- els
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. Extracting training data from large language mod- els. In30th USENIX security symposium (USENIX Se- curity 21), pages 2633–2650, 2021. 1, 2, 6
work page 2021
-
[5]
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe rlhf: Safe reinforcement learning from human feedback. arXiv preprint arXiv:2310.12773, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Toxicity in chatgpt: Analyzing persona-assigned language models
Ameet Deshpande, Vishvak Murahari, Tanmay Rajpuro- hit, Ashwin Kalyan, and Karthik Narasimhan. Toxicity in chatgpt: Analyzing persona-assigned language mod- els.arXiv preprint arXiv:2304.05335, 2023. 2
-
[7]
arXiv preprint arXiv:2506.12618 , year=
Vineeth Dorna, Anmol Mekala, Wenlong Zhao, An- drew McCallum, Zachary C Lipton, J Zico Kolter, and Pratyush Maini. Openunlearning: Accelerating llm un- learning via unified benchmarking of methods and met- rics.arXiv preprint arXiv:2506.12618, 2025. 6
-
[8]
Who’s harry potter? approximate unlearning in llms, 2023.URL https://arxiv
Ronen Eldan and Mark Russinovich. Who’s harry potter? approximate unlearning in llms, 2023.URL https://arxiv. org/abs/2310.02238, 1(2):8, 2024. 3
-
[9]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. Toy models of superposition.arXiv preprint arXiv:2209.10652, 2022. 9
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Rob- bie: Robust bias evaluation of large generative language models
David Esiobu, Xiaoqing Tan, Saghar Hosseini, Megan Ung, Yuchen Zhang, Jude Fernandes, Jane Dwivedi-Yu, Eleonora Presani, Adina Williams, and Eric Smith. Rob- bie: Robust bias evaluation of large generative language models. InProceedings of the 2023 Conference on Em- pirical Methods in Natural Language Processing, pages 3764–3814, 2023. 2
work page 2023
-
[11]
Bias and fairness in large language models: A survey
Isabel O Gallegos, Ryan A Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernon- court, Tong Yu, Ruiyi Zhang, and Nesreen K Ahmed. Bias and fairness in large language models: A survey. Computational linguistics, 50(3):1097–1179, 2024. 1, 2
work page 2024
-
[12]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, et al. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned.arXiv preprint arXiv:2209.07858, 2022. 3 13
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Google. gemma-2-2b-it model card. https:// huggingface.co/google/gemma-2-2b-it, 2024. 5
work page 2024
-
[14]
Google. gemma-7b-it model card. https:// huggingface.co/google/gemma-7b-it, 2024. 5
work page 2024
-
[15]
Introducing the frontier safety framework
Google DeepMind. Introducing the frontier safety framework. https://deepmind.google/blog/ introducing-the-frontier-safety-framework/ , May 2024. Accessed: 2026-03-31. 1, 3
work page 2024
-
[16]
Kai He, Rui Mao, Qika Lin, Yucheng Ruan, Xiang Lan, Mengling Feng, and Erik Cambria. A survey of large lan- guage models for healthcare: from data, technology, and applications to accountability and ethics.Information Fusion, 118:102963, 2025. 1
work page 2025
-
[17]
Anthropic: Responsible scaling policy
Evan Hubinger. Anthropic: Responsible scaling policy. SuperIntelligence-Robotics-Safety & Alignment, 2(1),
-
[18]
Editing Models with Task Arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Worts- man, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic.arXiv preprint arXiv:2212.04089, 2022. 1, 3, 5, 11
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. Llama guard: Llm-based input-output safeguard for human-ai conversations.arXiv preprint arXiv:2312.06674, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Knowledge unlearning for mitigating privacy risks in language models
Joel Jang, Dongkeun Yoon, Sohee Yang, Sungmin Cha, Moontae Lee, Lajanugen Logeswaran, and Minjoon Seo. Knowledge unlearning for mitigating privacy risks in language models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers), pages 14389–14408, 2023. 3
work page 2023
-
[21]
Pku-saferlhf: To- wards multi-level safety alignment for llms with human preference
Jiaming Ji, Donghai Hong, Borong Zhang, Boyuan Chen, Josef Dai, Boren Zheng, Tianyi Alex Qiu, Jiayi Zhou, Kaile Wang, Boxun Li, et al. Pku-saferlhf: To- wards multi-level safety alignment for llms with human preference. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), pages 31983–32016, 2...
work page 2025
-
[22]
Enkelejda Kasneci, Kathrin Seßler, Stefan Küchemann, Maria Bannert, Daryna Dementieva, Frank Fischer, Urs Gasser, Georg Groh, Stephan Günnemann, Eyke Hüller- meier, et al. Chatgpt for good? on opportunities and chal- lenges of large language models for education.Learning and individual differences, 103:102274, 2023. 1
work page 2023
-
[23]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic for- getting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017. 12
work page 2017
-
[24]
Salad- bench: A hierarchical and comprehensive safety bench- mark for large language models
Lijun Li, Bowen Dong, Ruohui Wang, Xuhao Hu, Wang- meng Zuo, Dahua Lin, Yu Qiao, and Jing Shao. Salad- bench: A hierarchical and comprehensive safety bench- mark for large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 3923–3954, 2024. 5
work page 2024
-
[25]
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D Li, Ann- Kathrin Dombrowski, Shashwat Goel, Long Phan, et al. The wmdp benchmark: Measuring and reduc- ing malicious use with unlearning.arXiv preprint arXiv:2403.03218, 2024. 1, 2, 3, 5
-
[26]
Shen Li, Liuyi Yao, Lan Zhang, and Yaliang Li. Safety layers in aligned large language models: The key to llm security.arXiv preprint arXiv:2408.17003, 2024. 2, 9, 13
-
[27]
Xuechen Li, Florian Tramer, Percy Liang, and Tat- sunori Hashimoto. Large language models can be strong differentially private learners.arXiv preprint arXiv:2110.05679, 2021. 3
-
[28]
Large language models in finance: A survey
Yinheng Li, Shaofei Wang, Han Ding, and Hang Chen. Large language models in finance: A survey. InPro- ceedings of the fourth ACM international conference on AI in finance, pages 374–382, 2023. 1
work page 2023
-
[29]
Rouge: A package for automatic evalua- tion of summaries
Chin-Yew Lin. Rouge: A package for automatic evalua- tion of summaries. InText summarization branches out, pages 74–81, 2004. 6
work page 2004
-
[30]
Mitigating biases in language models via bias unlearn- ing
Dianqing Liu, Yi Liu, Guoqing Jin, and Zhendong Mao. Mitigating biases in language models via bias unlearn- ing. InProceedings of the 2025 Conference on Empir- ical Methods in Natural Language Processing, pages 4160–4178, 2025. 5, 6, 16
work page 2025
-
[31]
arXiv preprint arXiv:2401.06121 , year=
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C Lipton, and J Zico Kolter. Tofu: A task of fictitious unlearning for llms.arXiv preprint arXiv:2401.06121, 2024. 4, 5, 6
-
[32]
A holistic approach to undesired content detection in the real world
Todor Markov, Chong Zhang, Sandhini Agarwal, Flo- rentine Eloundou Nekoul, Theodore Lee, Steven Adler, Angela Jiang, and Lilian Weng. A holistic approach to undesired content detection in the real world. InProceed- ings of the AAAI conference on artificial intelligence, volume 37, pages 15009–15018, 2023. 3
work page 2023
-
[33]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249, 2024. 5, 16
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022. 2, 3, 10, 13
work page 2022
-
[35]
Llama-3.2-1b-instruct model card
Meta Llama Team. Llama-3.2-1b-instruct model card. https://huggingface.co/meta-llama/Llama- 3.2-1B-Instruct, 2024. Accessed: 2024-09-25. 5, 9 14
work page 2024
-
[36]
Meta-llama-3-8b-instruct model card
Meta Llama Team. Meta-llama-3-8b-instruct model card. https://huggingface.co/meta-llama/Meta- Llama-3-8B-Instruct, 2024. 5
work page 2024
-
[37]
Julian Minder, Clément Dumas, Stewart Slocum, He- lena Casademunt, Cameron Holmes, Robert West, and Neel Nanda. Narrow finetuning leaves clearly read- able traces in activation differences.arXiv preprint arXiv:2510.13900, 2025. 12, 13
-
[38]
Stere- oset: Measuring stereotypical bias in pretrained lan- guage models
Moin Nadeem, Anna Bethke, and Siva Reddy. Stere- oset: Measuring stereotypical bias in pretrained lan- guage models. InProceedings of the 59th annual meet- ing of the association for computational linguistics and the 11th international joint conference on natural lan- guage processing (volume 1: long papers), pages 5356– 5371, 2021. 3, 5, 6, 16
work page 2021
-
[39]
Updated preparedness framework
OpenAI. Updated preparedness framework. https://openai.com/index/updating-our- preparedness-framework/, Apr 2025. Accessed: 2026-03-31. 1, 3
work page 2025
-
[40]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information pro- cessing systems, 35:27730–27744, 2022. 1, 3, 12
work page 2022
-
[41]
Wenbo Pan, Zhichao Liu, Qiguang Chen, Xiangyang Zhou, Haining Yu, and Xiaohua Jia. The hidden di- mensions of llm alignment: A multi-dimensional anal- ysis of orthogonal safety directions.arXiv preprint arXiv:2502.09674, 2025. 12, 13
-
[42]
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine- tuning aligned language models compromises safety, even when users do not intend to!arXiv preprint arXiv:2310.03693, 2023. 7, 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Qwen2.5-1.5b-instruct model card
Qwen Team, Alibaba Group. Qwen2.5-1.5b-instruct model card. https://huggingface.co/Qwen/Qwen2. 5-1.5B-Instruct, 2024. 5
work page 2024
-
[44]
Qwen2.5-7b-instruct model card
Qwen Team, Alibaba Group. Qwen2.5-7b-instruct model card. https://huggingface.co/Qwen/Qwen2. 5-7B-Instruct, 2024. 5
work page 2024
-
[45]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural informa- tion processing systems, 36:53728–53741, 2023. 1, 3, 5, 16
work page 2023
-
[46]
Trustllm: Trustworthiness in large language models
Lichao Sun, Yue Huang, Haoran Wang, Siyuan Wu, Qihui Zhang, Chujie Gao, Yixin Huang, Wenhan Lyu, Yixuan Zhang, Xiner Li, et al. Trustllm: Trustwor- thiness in large language models.arXiv preprint arXiv:2401.05561, 3, 2024. 1, 2
-
[47]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Decodingtrust: A comprehensive assessment of trustworthiness in {GPT} models
Boxin Wang, Weixin Chen, Hengzhi Pei, Chulin Xie, Mintong Kang, Chenhui Zhang, Chejian Xu, Zidi Xiong, Ritik Dutta, Rylan Schaeffer, et al. Decodingtrust: A comprehensive assessment of trustworthiness in {GPT} models. 2023. 2
work page 2023
-
[49]
Changsheng Wang, Yihua Zhang, Jinghan Jia, Parik- shit Ram, Dennis Wei, Yuguang Yao, Soumyadeep Pal, Nathalie Baracaldo, and Sijia Liu. Invariance makes llm unlearning resilient even to unanticipated downstream fine-tuning.arXiv preprint arXiv:2506.01339, 2025. 2, 7, 12, 13
-
[50]
Taxonomy of risks posed by language models
Laura Weidinger, Jonathan Uesato, Maribeth Rauh, Conor Griffin, Po-Sen Huang, John Mellor, Amelia Glaese, Myra Cheng, Borja Balle, Atoosa Kasirzadeh, et al. Taxonomy of risks posed by language models. In Proceedings of the 2022 ACM conference on fairness, accountability, and transparency, pages 214–229, 2022. 1, 2
work page 2022
-
[51]
Sophie Xhonneux, Alessandro Sordoni, Stephan Günne- mann, Gauthier Gidel, and Leo Schwinn. Efficient adver- sarial training in llms with continuous attacks.Advances in Neural Information Processing Systems, 37:1502– 1530, 2024. 1, 3, 5, 16
work page 2024
-
[52]
Biasfreebench: a benchmark for mitigating bias in large language model responses
Xin Xu, Xunzhi He, Churan Zhi, Ruizhe Chen, Julian McAuley, and Zexue He. Biasfreebench: a benchmark for mitigating bias in large language model responses. arXiv preprint arXiv:2510.00232, 2025. 5, 6, 16
-
[53]
Yifan Yao, Jinhao Duan, Kaidi Xu, Yuanfang Cai, Zhibo Sun, and Yue Zhang. A survey on large language model (llm) security and privacy: The good, the bad, and the ugly.High-Confidence Computing, 4(2):100211, 2024. 2
work page 2024
-
[54]
arXiv preprint arXiv:2404.05868 , year=
Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei. Negative preference optimization: From catastrophic collapse to effective unlearning.arXiv preprint arXiv:2404.05868, 2024. 1, 5
-
[55]
Shenyi Zhang, Yuchen Zhai, Keyan Guo, Hongxin Hu, Shengnan Guo, Zheng Fang, Lingchen Zhao, Chao Shen, Cong Wang, and Qian Wang. {JBShield}: Defending large language models from jailbreak attacks through activated concept analysis and manipulation. In34th USENIX Security Symposium (USENIX Security 25), pages 8215–8234, 2025. 3
work page 2025
-
[56]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Rep- resentation engineering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and trans- ferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043, 2023. 1 15 A Mechanistic Experimental Results To complement the main results, we provide mechanistic anal- yses of the interfering sequence (Seq III): MGemma-S...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.