Recognition: 2 theorem links
· Lean TheoremScaling Laws from Sequential Feature Recovery: A Solvable Hierarchical Model
Pith reviewed 2026-05-15 01:35 UTC · model grok-4.3
The pith
A layer-wise spectral algorithm on a hierarchical target with power-law feature weights recovers latent directions sequentially and aggregates their sharp thresholds into an explicit power-law decay of prediction error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
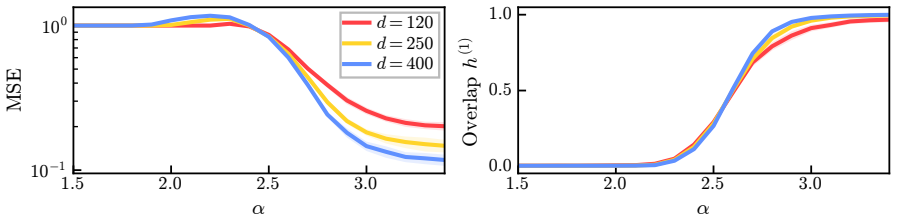
In the solvable hierarchical model the layer-wise spectral algorithm recovers the latent directions sequentially: strong features become detectable at small sample sizes while weaker features require larger samples. Sharp feature-wise recovery thresholds are proved via resolvent-based perturbation arguments that give matching upper and lower bounds. Aggregating these thresholds produces an explicit power-law decay of the prediction error, with improved scaling relative to shallow non-adaptive methods.
What carries the argument
The layer-wise spectral algorithm adapted to the compositional structure, together with resolvent-based perturbation bounds that establish sharp eigenvector recovery thresholds.
If this is right
- Strong features become detectable at small sample sizes while weaker features require more data.
- Aggregating the sequence of sharp thresholds produces an explicit power-law decay of prediction error.
- The layer-wise method outperforms shallow non-adaptive kernels in scaling.
- Finite-size effects smooth the thresholds but preserve the overall power-law trend.
Where Pith is reading between the lines
- Networks trained on real data with similar hierarchical structure may display analogous sequential feature acquisition.
- The same resolvent technique could be applied to other layer-wise or greedy algorithms to obtain explicit thresholds.
- Removing the power-law weight assumption should eliminate the smooth scaling and leave only abrupt jumps.
Load-bearing premise
The high-dimensional target can be written as a combination of latent compositional features whose weights decrease as a power law, and the algorithm is specifically designed to exploit that structure.
What would settle it
Numerical or analytic evidence that the aggregated error decay deviates from power-law form, or that individual feature thresholds are not sharp, would falsify the central claim.
Figures




read the original abstract
We propose a simple mechanism by which scaling laws emerge from feature learning in multi-layer networks. We study a high-dimensional hierarchical target that is a globally high-degree function, but that can be represented by a combination of latent compositional features whose weights decrease as a power law. We show that a layer-wise spectral algorithm adapted to this compositional structure achieves improved scaling relative to shallow, non-adaptive methods, and recovers the latent directions sequentially: strong features become detectable at small sample sizes, while weaker features require more data. We prove sharp feature-wise recovery thresholds and show that aggregating these transitions yields an explicit power-law decay of the prediction error. Technically, the analysis relies on random matrix methods and a resolvent-based perturbation argument, which gives matching upper and lower bounds for individual eigenvector recovery beyond what standard gap-based perturbation bounds provide. Numerical experiments confirm the predicted sequential recovery, finite-size smoothing of the thresholds, and separation from non-hierarchical kernel baselines. Together, these results show how smooth scaling laws can emerge from a cascade of sharp feature-learning transitions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a solvable hierarchical model in which a high-dimensional target is expressed as a combination of latent compositional features whose weights decay as a power law. It analyzes a layer-wise spectral algorithm that recovers these features sequentially, deriving sharp per-feature recovery thresholds via random-matrix resolvent perturbation that supply matching upper and lower bounds. Aggregation of the ordered thresholds then produces an explicit power-law decay of the prediction error, offering a mechanistic account of scaling laws. Numerical experiments confirm the sequential recovery, finite-size smoothing, and advantage over non-hierarchical kernel baselines.
Significance. If the central claims hold, the work supplies a concrete, analytically tractable example in which smooth scaling laws emerge directly from the summation of sharp, theoretically derived feature-recovery transitions rather than from post-hoc fitting. The resolvent-based perturbation technique yields tighter eigenvector bounds than standard gap arguments, and the explicit construction of the power-law hierarchy is a technical strength. The separation from kernel baselines underscores the benefit of the adapted multi-layer procedure.
major comments (2)
- [§3] §3 (resolvent perturbation argument): the matching upper and lower bounds on eigenvector recovery are derived under the assumption that the minimal eigenvalue gap scales with the power-law exponent; the dependence of the perturbation remainder on this gap is not stated explicitly, which is load-bearing for the subsequent aggregation into a clean power-law error decay.
- [§4.2] §4.2 (numerical validation): the experiments illustrate finite-size smoothing of the thresholds, yet no quantitative bound or scaling for the width of the transition region is provided; without this, it is difficult to verify that the asymptotic power-law remains a good approximation at the moderate sample sizes shown in the figures.
minor comments (2)
- The definition of the latent compositional features and the precise form of the layer-wise spectral update could be stated once in the main text (rather than only in the appendix) to improve readability for readers unfamiliar with the construction.
- A short high-level proof sketch of the resolvent perturbation step would help readers follow the argument without immediately consulting the appendix.
Simulated Author's Rebuttal
We are grateful to the referee for the thorough review and the encouraging assessment of our manuscript. The comments highlight important points for clarification, which we address below. We believe these revisions will further strengthen the presentation of our results.
read point-by-point responses
-
Referee: [§3] §3 (resolvent perturbation argument): the matching upper and lower bounds on eigenvector recovery are derived under the assumption that the minimal eigenvalue gap scales with the power-law exponent; the dependence of the perturbation remainder on this gap is not stated explicitly, which is load-bearing for the subsequent aggregation into a clean power-law error decay.
Authors: We thank the referee for pointing this out. In the original derivation, the resolvent perturbation bound indeed depends on the eigenvalue gap, which for our power-law model scales as λ_k - λ_{k+1} ∼ k^{-α-1}. We will revise §3 to explicitly state the dependence of the remainder term on this gap, showing that it remains controlled under the power-law assumption. This will make the step to the aggregated power-law error decay fully rigorous and transparent. We will also add a short appendix remark if needed. revision: yes
-
Referee: [§4.2] §4.2 (numerical validation): the experiments illustrate finite-size smoothing of the thresholds, yet no quantitative bound or scaling for the width of the transition region is provided; without this, it is difficult to verify that the asymptotic power-law remains a good approximation at the moderate sample sizes shown in the figures.
Authors: We agree that quantifying the transition width would be valuable. While a full rigorous bound on the smoothing width is technically challenging and outside the main scope (as it would require more refined large-deviation estimates), we will add a discussion in §4.2 referencing standard random matrix theory results, where the transition width typically scales as O(n^{-1/2}) for eigenvector perturbations. We will also include a supplementary figure showing the empirical width scaling with sample size n to support that the asymptotic regime is approached at the depicted sizes. This constitutes a partial revision. revision: partial
Circularity Check
No significant circularity identified
full rationale
The derivation begins from an explicit model assumption that the target is a combination of latent compositional features with power-law decaying weights. Sharp per-feature recovery thresholds are obtained via resolvent perturbation and random-matrix analysis, with matching upper and lower bounds. Aggregating these thresholds then produces an explicit power-law decay for the prediction error as a direct summation over the ordered transitions. This step is a standard analytic consequence of the input power-law weights and the derived thresholds; it does not involve fitting the final exponent, renaming a known result, or reducing to a self-citation chain. No load-bearing self-citations, self-definitional steps, or fitted inputs presented as predictions appear in the chain. The result remains self-contained once the hierarchical model is granted.
Axiom & Free-Parameter Ledger
free parameters (1)
- power-law exponent of feature weights
axioms (1)
- standard math High-dimensional limit with random matrix concentration for eigenvector recovery
invented entities (1)
-
latent compositional features with power-law weights
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We prove sharp feature-wise recovery thresholds and show that aggregating these transitions yields an explicit power-law decay of the prediction error... ni ≍ d^q / a_i² ... MSE(n) ≍ (n/d^q)^{-1+1/(2γ)}
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the target admits a representation as a combination of latent compositional features whose weights decrease as a power law
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Random matrix methods for machine learning , author=. 2022 , publisher=
work page 2022
-
[2]
Introduction to the non-asymptotic analysis of random matrices
Introduction to the non-asymptotic analysis of random matrices , author=. arXiv preprint arXiv:1011.3027 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Applied and Computational Harmonic Analysis , volume=
Generalization error of random feature and kernel methods: Hypercontractivity and kernel matrix concentration , author=. Applied and Computational Harmonic Analysis , volume=. 2022 , publisher=
2022
-
[4]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[5]
arXiv preprint arXiv:2305.15501 , year=
Deriving language models from masked language models , author=. arXiv preprint arXiv:2305.15501 , year=
-
[6]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Characterizing a joint probability distribution by conditionals , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 1993 , publisher=
work page 1993
-
[7]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Roberta: A robustly optimized bert pretraining approach , author=. arXiv preprint arXiv:1907.11692 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[8]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Masked language model scoring , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[9]
arXiv preprint arXiv:1904.09324 , year=
Mask-predict: Parallel decoding of conditional masked language models , author=. arXiv preprint arXiv:1904.09324 , year=
-
[10]
On the inductive bias of masked language modeling: From statistical to syntactic dependencies , author=. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
work page 2021
-
[11]
arXiv preprint arXiv:2104.06644 , year=
Masked language modeling and the distributional hypothesis: Order word matters pre-training for little , author=. arXiv preprint arXiv:2104.06644 , year=
-
[12]
arXiv preprint arXiv:2407.21046 , year=
Promises and pitfalls of generative masked language modeling: Theoretical framework and practical guidelines , author=. arXiv preprint arXiv:2407.21046 , year=
-
[13]
Advances in Neural Information Processing Systems , volume=
How mask matters: Towards theoretical understandings of masked autoencoders , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
The Annals of Statistics , volume=
Dimension free ridge regression , author=. The Annals of Statistics , volume=. 2024 , publisher=
2024
-
[15]
SIAM Journal on Mathematics of Data Science , volume=
High-dimensional analysis of double descent for linear regression with random projections , author=. SIAM Journal on Mathematics of Data Science , volume=. 2024 , publisher=
work page 2024
-
[16]
Isotropic local laws for sample covariance and generalized Wigner matrices , author=
-
[17]
A first course in random matrix theory: for physicists, engineers and data scientists , author=. 2020 , publisher=
work page 2020
-
[18]
Narayan, Onuttom and Shastry, B. Sriram , journal =. The Toeplitz matrix
-
[19]
Journal of Rational Mechanics and Analysis , volume=
On the eigenvalues of certain Hermitian forms , author=. Journal of Rational Mechanics and Analysis , volume=. 1953 , publisher=
work page 1953
-
[20]
An introduction to matrix concentration inequalities , author=. Foundations and trends. 2015 , publisher=
work page 2015
-
[21]
arXiv preprint arXiv:2512.03325 , year=
When does Gaussian equivalence fail and how to fix it: Non-universal behavior of random features with quadratic scaling , author=. arXiv preprint arXiv:2512.03325 , year=
-
[22]
arXiv preprint arXiv:2311.13774 , year=
Learning hierarchical polynomials with three-layer neural networks , author=. arXiv preprint arXiv:2311.13774 , year=
-
[23]
Annual review of neuroscience , volume=
Natural image statistics and neural representation , author=. Annual review of neuroscience , volume=. 2001 , publisher=
work page 2001
- [24]
-
[25]
Boucheron, St\'ephane and Lugosi, G\'abor and Massart, Pascal , TITLE =. 2013 , PAGES =. doi:10.1093/acprof:oso/9780199535255.001.0001 , URL =
work page doi:10.1093/acprof:oso/9780199535255.001.0001 2013
- [26]
-
[27]
Multivariate normal approximation using Stein's method and Malliavin calculus , author=. Annales de l'IHP Probabilit
-
[28]
The Annals of Probability , volume=
Central Limit Theorems For Sequences Of Multiple Stochastic Integrals , author=. The Annals of Probability , volume=
-
[29]
arXiv preprint arXiv:2603.14573 , year=
Rigorous Asymptotics for First-Order Algorithms Through the Dynamical Cavity Method , author=. arXiv preprint arXiv:2603.14573 , year=
-
[30]
2018 , publisher=
High-dimensional probability: An introduction with applications in data science , author=. 2018 , publisher=
2018
-
[31]
Normal approximations with Malliavin calculus: from Stein's method to universality , author=. 2012 , publisher=
work page 2012
-
[32]
Deep Learning of Compositional Targets with Hierarchical Spectral Methods , author =. 2026 , eprint =
work page 2026
-
[33]
arXiv preprint arXiv:2602.05846 , year=
Optimal scaling laws in learning hierarchical multi-index models , author=. arXiv preprint arXiv:2602.05846 , year=
-
[34]
Ren, Yunwei and Nichani, Eshaan and Wu, Denny and Lee, Jason D. , year =. Emergence and Scaling Laws in. 2504.19983 , archivePrefix =
-
[35]
Workshop on Scientific Methods for Understanding Deep Learning , year=
Single-Head Attention in High Dimensions: A Theory of Generalization, Weights Spectra, and Scaling Laws , author=. Workshop on Scientific Methods for Understanding Deep Learning , year=
-
[36]
Advances in Neural Information Processing Systems , volume=
Tuning large neural networks via zero-shot hyperparameter transfer , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Advances in Neural Information Processing Systems , volume=
4+3 phases of compute-optimal neural scaling laws , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
arXiv preprint arXiv:2603.18168 , year=
Resnets of all shapes and sizes: Convergence of training dynamics in the large-scale limit , author=. arXiv preprint arXiv:2603.18168 , year=
-
[39]
12th International Conference on Learning Representations, ICLR 2024 , year=
Depthwise hyperparameter transfer in residual networks: Dynamics and scaling limit , author=. 12th International Conference on Learning Representations, ICLR 2024 , year=
work page 2024
-
[40]
Advances in Neural Information Processing Systems , volume=
The feature speed formula: a flexible approach to scale hyper-parameters of deep neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
Proceedings of the 41st International Conference on Machine Learning , pages=
A dynamical model of neural scaling laws , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[42]
Scaling and renormalization in high-dimensional regression
Scaling and renormalization in high-dimensional regression , author=. arXiv preprint arXiv:2405.00592 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
arXiv preprint arXiv:2210.16859 , year=
A solvable model of neural scaling laws , author=. arXiv preprint arXiv:2210.16859 , year=
-
[44]
2025 , eprint =
The Computational Advantage of Depth: Learning High-Dimensional Hierarchical Functions with Gradient Descent , author =. 2025 , eprint =
2025
-
[45]
arXiv preprint arXiv:2508.03688 , year=
Learning quadratic neural networks in high dimensions: SGD dynamics and scaling laws , author=. arXiv preprint arXiv:2508.03688 , year=
-
[46]
How Deep Neural Networks Learn Compositional Data: The Random Hierarchy Model , author =. Physical Review X , volume =. 2024 , doi =
work page 2024
-
[47]
Advances in Neural Information Processing Systems , volume =
Provable Guarantees for Nonlinear Feature Learning in Three-Layer Neural Networks , author =. Advances in Neural Information Processing Systems , volume =
-
[48]
International Conference on Learning Representations , year =
Learning Hierarchical Polynomials of Multiple Nonlinear Features with Three-Layer Networks , author =. International Conference on Learning Representations , year =
-
[49]
2020 , eprint =
Scaling Laws for Neural Language Models , author =. 2020 , eprint =
2020
-
[50]
Advances in Neural Information Processing Systems , volume =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems , volume =
-
[51]
Advances in Neural Information Processing Systems , volume =
An Empirical Analysis of Compute-Optimal Large Language Model Training , author =. Advances in Neural Information Processing Systems , volume =
-
[52]
Proceedings of the National Academy of Sciences , volume =
Explaining Neural Scaling Laws , author =. Proceedings of the National Academy of Sciences , volume =
-
[53]
Foundations of Computational Mathematics , volume =
Optimal Rates for the Regularized Least-Squares Algorithm , author =. Foundations of Computational Mathematics , volume =
-
[54]
International Conference on Machine Learning , pages =
Spectrum Dependent Learning Curves in Kernel Regression and Wide Neural Networks , author =. International Conference on Machine Learning , pages =
-
[55]
Journal of Statistical Mechanics: Theory and Experiment , volume =
Asymptotic Learning Curves of Kernel Methods: Empirical Data versus Teacher--Student Paradigm , author =. Journal of Statistical Mechanics: Theory and Experiment , volume =
-
[56]
Advances in Neural Information Processing Systems , volume =
Generalization Error Rates in Kernel Regression: The Crossover from the Noiseless to Noisy Regime , author =. Advances in Neural Information Processing Systems , volume =
-
[57]
Machine Learning: Science and Technology , volume =
Error Scaling Laws for Kernel Classification under Source and Capacity Conditions , author =. Machine Learning: Science and Technology , volume =
-
[58]
Advances in Neural Information Processing Systems , volume =
Dimension-Free Deterministic Equivalents and Scaling Laws for Random Feature Regression , author =. Advances in Neural Information Processing Systems , volume =
-
[59]
International Conference on Learning Representations , year =
Exact Solutions to the Nonlinear Dynamics of Learning in Deep Linear Neural Networks , author =. International Conference on Learning Representations , year =
-
[60]
2022 , eprint =
Emergent Abilities of Large Language Models , author =. 2022 , eprint =
2022
-
[61]
Advances in Neural Information Processing Systems , volume =
Are Emergent Abilities of Large Language Models a Mirage? , author =. Advances in Neural Information Processing Systems , volume =
-
[62]
, journal =
Davis, Chandler and Kahan, William M. , journal =. The Rotation of Eigenvectors by a Perturbation. 1970 , doi =
1970
-
[63]
Perturbation Theory for Linear Operators , author =
-
[64]
The Fourteenth International Conference on Learning Representations , year=
Scaling Laws and Spectra of Shallow Neural Networks in the Feature Learning Regime , author=. The Fourteenth International Conference on Learning Representations , year=
-
[65]
2011 , publisher=
Wiener Chaos: Moments, Cumulants and Diagrams: A survey with computer implementation , author=. 2011 , publisher=
2011
-
[66]
Algorithmic learning theory , pages=
Unperturbed: spectral analysis beyond Davis-Kahan , author=. Algorithmic learning theory , pages=. 2018 , organization=
2018
-
[67]
First-order perturbation theory for eigenvalues and eigenvectors , author=. SIAM review , volume=. 2020 , publisher=
work page 2020
-
[68]
Probability Theory and Related Fields , volume=
Stein’s method on Wiener chaos , author=. Probability Theory and Related Fields , volume=. 2009 , publisher=
2009
-
[69]
arXiv preprint arXiv:2410.18162 , year=
Stochastic gradient descent in high dimensions for multi-spiked tensor PCA , author=. arXiv preprint arXiv:2410.18162 , year=
-
[70]
Learning with kernels: support vector machines, regularization, optimization, and beyond , author=. 2002 , publisher=
work page 2002
-
[71]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
Spherical Harmonics in p Dimensions
Spherical harmonics in p dimensions , author=. arXiv preprint arXiv:1205.3548 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
Lecture Notes (Princeton University) , volume=
Probability in high dimension , author=. Lecture Notes (Princeton University) , volume=
- [74]
-
[75]
American Journal of Mathematics , volume=
Logarithmic sobolev inequalities , author=. American Journal of Mathematics , volume=. 1975 , publisher=
work page 1975
-
[76]
A generalization of the Lindeberg principle , volume=
Chatterjee, Sourav , year=. A generalization of the Lindeberg principle , volume=. The Annals of Probability , publisher=. doi:10.1214/009117906000000575 , number=
-
[77]
Conference On Learning Theory , pages=
Algorithmic regularization in over-parameterized matrix sensing and neural networks with quadratic activations , author=. Conference On Learning Theory , pages=. 2018 , organization=
2018
-
[78]
Advances in Neural Information Processing Systems , volume=
What Can ResNet Learn Efficiently, Going Beyond Kernels? , author=. Advances in Neural Information Processing Systems , volume=
-
[79]
Boucheron, Stéphane and Lugosi, Gábor and Massart, Pascal , title =. 2013 , month =
work page 2013
-
[80]
International Journal of Automation and Computing , volume=
Why and when can deep-but not shallow-networks avoid the curse of dimensionality: a review , author=. International Journal of Automation and Computing , volume=. 2017 , publisher=
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.