One Step to the Side: Why Defenses Against Malicious Finetuning Fail Under Adaptive Adversaries
Pith reviewed 2026-06-30 20:58 UTC · model grok-4.3
The pith
Defenses against malicious fine-tuning only block the attacks they were designed against.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
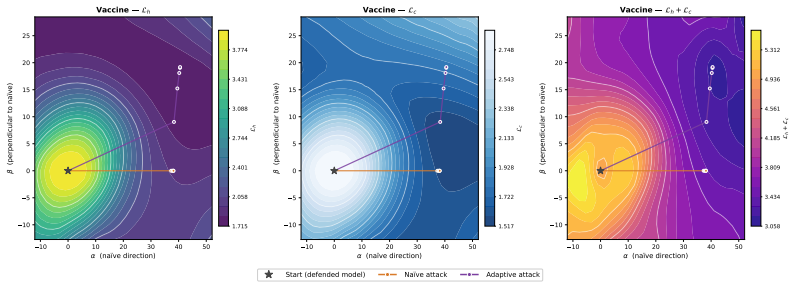
Surveying 15 defenses shows they all share one mechanism: they obscure the path to harmful behavior without removing the behavior. A single unified adaptive attack then succeeds against every defense in the survey, proving that current methods supply security only against the fixed attacks used during their development.
What carries the argument
The unified adaptive attack, which identifies alternative fine-tuning paths to harmful outputs that evade each defense's specific hiding mechanism.
If this is right
- Security claims based on fixed-attack testing are unreliable.
- Model providers cannot count on current defenses to block harmful fine-tuning by adaptive users.
- New defenses must be designed and evaluated against adversaries that adapt to the defense itself.
- Evaluation protocols that ignore adaptive attacks will continue to produce overstated robustness results.
Where Pith is reading between the lines
- Providers may need to restrict fine-tuning access rather than rely on post-alignment defenses.
- Research should shift toward methods that actually delete harmful capabilities instead of masking them.
- Standardized adaptive attack suites could become a required test for any new defense paper.
- The same hiding-versus-removal distinction may appear in other AI safety settings evaluated only against static threats.
Load-bearing premise
The fifteen surveyed defenses capture the main approaches in the field and the adaptive attack is not specially tuned to just those defenses.
What would settle it
Finding even one new defense that survives the unified adaptive attack while still permitting useful fine-tuning would falsify the central claim.
Figures


read the original abstract
Model providers increasingly release open weights or allow users to fine-tune foundation models through APIs. Although these models are safety-aligned before release, their safeguards can often be removed by fine-tuning on harmful data. Recent defenses aim to make models robust to such malicious fine-tuning, but they are largely evaluated only against fixed attacks that do not account for the defense. We show that these robustness claims are incomplete. Surveying 15 recent defenses, we identify several defense mechanisms and show that they share a single weakness: they obscure or misdirect the path to harmful behavior without removing the behavior itself. We then develop a unified adaptive attack that breaks defenses across all defense mechanisms. Our results show that current approaches do not provide robust security; they mainly stop the attacks they were designed against. We hope that our unified adaptive adversary for this domain will help future researchers and practitioners stress-test new defenses before deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys 15 recent defenses against malicious fine-tuning of safety-aligned foundation models. It categorizes their mechanisms and argues they share a common weakness: obscuring or misdirecting the path to harmful behavior without removing the underlying capability. The authors then construct a unified adaptive attack that succeeds against defenses from all categories, concluding that current defenses mainly stop the fixed attacks they were designed against rather than providing robust security under adaptive adversaries.
Significance. If the unified attack is shown to be general rather than tuned to the surveyed set, the work would be significant for AI safety research. It supplies a concrete adaptive adversary and evaluation methodology that future defenses can be stress-tested against, addressing a gap in how robustness claims are currently validated. Explicit provision of the attack framework for reproducibility would strengthen its utility to the community.
major comments (2)
- [Abstract] Abstract and the paragraph on surveying defenses and developing the attack: The central claim that the unified adaptive attack reveals a fundamental shared weakness (rather than an ensemble of per-defense exploits) is load-bearing. The manuscript must demonstrate that the attack was not constructed by first categorizing the 15 defenses and then tailoring components to each; evidence such as success on a held-out defense mechanism or a newly proposed defense outside the survey is required to support generality.
- [Attack construction section] The section describing the unified attack construction: Without an ablation study isolating whether individual attack components depend on knowledge of specific defense mechanisms (e.g., which layers or objectives are modified), it remains unclear whether the attack would transfer to unsurveyed defenses. This directly affects the claim that 'current approaches do not provide robust security.'
minor comments (1)
- [Introduction] The manuscript would benefit from explicit discussion of the threat model assumptions, particularly the level of adversary knowledge about the defense (white-box vs. black-box access).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The concerns about demonstrating the generality of the unified attack beyond the surveyed defenses are substantive, and we respond to each major comment below with clarifications on our methodology.
read point-by-point responses
-
Referee: [Abstract] Abstract and the paragraph on surveying defenses and developing the attack: The central claim that the unified adaptive attack reveals a fundamental shared weakness (rather than an ensemble of per-defense exploits) is load-bearing. The manuscript must demonstrate that the attack was not constructed by first categorizing the 15 defenses and then tailoring components to each; evidence such as success on a held-out defense mechanism or a newly proposed defense outside the survey is required to support generality.
Authors: The attack was developed from the identified common weakness that all 15 defenses obscure or misdirect harmful capabilities without removing them, rather than by tailoring to individual mechanisms. The same adaptive fine-tuning strategy is applied uniformly across categories, and its success on all surveyed defenses supports that it is not an ensemble of per-defense exploits. We acknowledge that a held-out test on an external defense would provide stronger evidence of generality; the current manuscript does not include such a test. We will revise the relevant sections to more explicitly document the attack development sequence and emphasize its basis in the shared weakness. revision: partial
-
Referee: [Attack construction section] The section describing the unified attack construction: Without an ablation study isolating whether individual attack components depend on knowledge of specific defense mechanisms (e.g., which layers or objectives are modified), it remains unclear whether the attack would transfer to unsurveyed defenses. This directly affects the claim that 'current approaches do not provide robust security.'
Authors: The attack components target the general property of capability obscuration and do not incorporate knowledge of specific defense mechanisms such as particular layers or objectives. The evaluation across 15 defenses from distinct categories already demonstrates transfer without per-defense customization. We agree an ablation study would further isolate component contributions and strengthen the transfer claim. We will add a short discussion in the attack construction section clarifying the general nature of the components and their independence from defense-specific details. revision: partial
Circularity Check
No circularity: empirical survey and attack construction
full rationale
The paper performs a survey of 15 existing defenses, categorizes mechanisms, identifies a shared weakness via direct analysis of those defenses, and constructs then empirically evaluates a unified adaptive attack against them. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing claims. The central result rests on external benchmarks (the surveyed defenses) and falsifiable attack success rates rather than any self-referential reduction or ansatz smuggled via prior work. This is a standard empirical security evaluation with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Safety-aligned models can have safeguards removed by fine-tuning on harmful data
Reference graph
Works this paper leans on
-
[1]
Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples
Anish Athalye, Nicholas Carlini, and David Wagner. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 274–283. PMLR, 2018
2018
-
[2]
Evasion attacks against machine learning at test time
Battista Biggio, Igino Corona, Davide Maiorca, Blaine Nelson, Nedim Šrndi´c, Pavel Laskov, Giorgio Giacinto, and Fabio Roli. Evasion attacks against machine learning at test time. In Machine Learning and Knowledge Discovery in Databases, volume 8190 ofLecture Notes in Computer Science, pages 387–402. Springer, 2013
2013
-
[3]
Adversarial examples are not easily detected: Bypassing ten detection methods
Nicholas Carlini and David Wagner. Adversarial examples are not easily detected: Bypassing ten detection methods. InProceedings of the 10th ACM Workshop on Artificial Intelligence and Security, pages 3–14. Association for Computing Machinery, 2017
2017
-
[4]
Towards evaluating the robustness of neural networks
Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. In 2017 IEEE Symposium on Security and Privacy (SP), pages 39–57. IEEE, 2017
2017
-
[5]
Pappas, and Eric Wong
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[6]
Liang Chen, Xueting Han, Li Shen, Jing Bai, and Kam-Fai Wong. Vulnerability-aware align- ment: Mitigating uneven forgetting in harmful fine-tuning.arXiv preprint arXiv:2506.03850, 2025
-
[7]
Sdd: Self-degraded defense against malicious fine-tuning
Zixuan Chen, Weikai Lu, Xin Lin, and Ziqian Zeng. Sdd: Self-degraded defense against malicious fine-tuning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 29109–29125, 2025
2025
-
[8]
On weaponization-resistant large language models with prospect theoretic alignment
Zehua Cheng, Manying Zhang, Jiahao Sun, and Wei Dai. On weaponization-resistant large language models with prospect theoretic alignment. InProceedings of the 31st International Conference on Computational Linguistics, pages 10309–10324, 2025. 10
2025
-
[9]
Think you have solved question answering? try ARC, the AI2 reasoning challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1110–1115, 2018
2018
-
[10]
AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents
Edoardo Debenedetti, Jie Zhang, Mislav Balunovi´c, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024
2024
-
[11]
Chongyu Fan, Jinghan Jia, Yihua Zhang, Anil Ramakrishna, Mingyi Hong, and Sijia Liu. To- wards llm unlearning resilient to relearning attacks: A sharpness-aware minimization perspective and beyond.arXiv preprint arXiv:2502.05374, 2025
-
[12]
Goodfellow, Jonathon Shlens, and Christian Szegedy
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adver- sarial examples. InInternational Conference on Learning Representations, 2015
2015
-
[13]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Self- destructing models: Increasing the costs of harmful dual uses of foundation models
Peter Henderson, Eric Mitchell, Christopher Manning, Dan Jurafsky, and Chelsea Finn. Self- destructing models: Increasing the costs of harmful dual uses of foundation models. In Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society, pages 287–296, 2023
2023
-
[15]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations, 2021
2021
-
[16]
Tiansheng Huang, Sihao Hu, Fatih Ilhan, Selim Furkan Tekin, and Ling Liu. Booster: Tackling harmful fine-tuning for large language models via attenuating harmful perturbation.arXiv preprint arXiv:2409.01586, 2024
-
[17]
Vaccine: Perturbation-aware alignment for large language models against harmful fine-tuning attack.Advances in Neural Information Processing Systems, 37:74058–74088, 2024
Tiansheng Huang, Sihao Hu, and Ling Liu. Vaccine: Perturbation-aware alignment for large language models against harmful fine-tuning attack.Advances in Neural Information Processing Systems, 37:74058–74088, 2024
2024
-
[18]
Beavertails: Towards improved safety alignment of llm via a human-preference dataset.Advances in Neural Information Processing Systems, 36:24678–24704, 2023
Jiaming Ji, Mickel Liu, Josef Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. Beavertails: Towards improved safety alignment of llm via a human-preference dataset.Advances in Neural Information Processing Systems, 36:24678–24704, 2023
2023
-
[19]
Simon Lermen, Charlie Rogers-Smith, and Jeffrey Ladish. LoRA fine-tuning efficiently undoes safety training in Llama 2-chat 70b.arXiv preprint arXiv:2310.20624, 2023
-
[20]
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D. Li, Ann-Kathrin Dombrowski, Shashwat Goel, Gabriel Mukobi, Nathan Helm-Burger, Rassin Lababidi, Lennart Justen, Andrew Bo Liu, Michael Chen, Isabelle Barrass, Oliver Zhang, Xiaoyuan Zhu, Rishub Tamirisa, Bhrugu Bharathi, Ariel Herbert-V oss, Cort B Breuer, Andy Z...
2024
-
[21]
Truthfulqa: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. InProceedings of the 60th Annual Meeting of the Association for Computa- tional Linguistics, pages 3214–3252, 2022. 11
2022
-
[22]
Targeted vaccine: Safety alignment for large language models against harmful fine-tuning via layer-wise perturbation.IEEE Transactions on Information Forensics and Security, 2025
Guozhi Liu, Weiwei Lin, Qi Mu, Tiansheng Huang, Ruichao Mo, Yuren Tao, and Li Shen. Targeted vaccine: Safety alignment for large language models against harmful fine-tuning via layer-wise perturbation.IEEE Transactions on Information Forensics and Security, 2025
2025
-
[23]
Guozhi Liu, Qi Mu, Tiansheng Huang, Xinhua Wang, Li Shen, Weiwei Lin, and Zhang Li. Pharmacist: Safety alignment data curation for large language models against harmful fine- tuning.arXiv preprint arXiv:2510.10085, 2025
-
[24]
Xiaoqun Liu, Jiacheng Liang, Muchao Ye, and Zhaohan Xi. Robustifying safety-aligned large language models through clean data curation.arXiv preprint arXiv:2405.19358, 2024
-
[25]
Harmbench: A standardized evaluation framework for automated red teaming and robust refusal, 2024
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal, 2024
2024
-
[26]
Are defenses for graph neural networks robust? InAdvances in Neural Information Processing Systems, volume 35, pages 8954–8968, 2022
Felix Mujkanovic, Simon Geisler, Stephan Günnemann, and Aleksandar Bojchevski. Are defenses for graph neural networks robust? InAdvances in Neural Information Processing Systems, volume 35, pages 8954–8968, 2022
2022
-
[27]
Milad Nasr, Nicholas Carlini, Chawin Sitawarin, Sander V . Schulhoff, Jamie Hayes, Michael Ilie, Juliette Pluto, Shuang Song, Harsh Chaudhari, Ilia Shumailov, Abhradeep Thakurta, Kai Yuanqing Xiao, Andreas Terzis, and Florian Tramèr. The attacker moves second: Stronger adaptive attacks bypass defenses against LLM jailbreaks and prompt injections.arXiv pre...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Quoc Minh Nguyen, Trung Le, Jing Wu, Anh Tuan Bui, and Mehrtash Harandi. Antibody: Strengthening defense against harmful fine-tuning for large language models via attenuating harmful gradient influence.arXiv preprint arXiv:2603.00498, 2026
-
[29]
Gabriel J Perin, Runjin Chen, Xuxi Chen, Nina ST Hirata, Zhangyang Wang, and Junyuan Hong. Lox: Low-rank extrapolation robustifies llm safety against fine-tuning.arXiv preprint arXiv:2506.15606, 2025
-
[30]
On evaluating the durability of safeguards for open-weight LLMs
Xiangyu Qi, Boyi Wei, Nicholas Carlini, Yangsibo Huang, Tinghao Xie, Luxi He, Matthew Jagielski, Milad Nasr, Prateek Mittal, and Peter Henderson. On evaluating the durability of safeguards for open-weight LLMs. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[31]
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine-tuning aligned language models compromises safety, even when users do not intend to! arXiv preprint arXiv:2310.03693, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Locking open weight models with spectral deformation
Domenic Rosati, Sebastian Dionicio, Xijie Zeng, Subhabrata Majumdar, Frank Rudzicz, and Hassan Sajjad. Locking open weight models with spectral deformation. InICML Workshop on Technical AI Governance (TAIG), 2025
2025
-
[33]
Representation noising: A defence mechanism against harmful finetuning.Advances in Neural Information Processing Systems, 37:12636–12676, 2024
Domenic Rosati, Jan Wehner, Kai Williams, Łukasz Bartoszcze, David Atanasov, Robie Gonza- les, Subhabrata Majumdar, Carsten Maple, Hassan Sajjad, and Frank Rudzicz. Representation noising: A defence mechanism against harmful finetuning.Advances in Neural Information Processing Systems, 37:12636–12676, 2024
2024
-
[34]
Antidote: Bi-level adversarial training for tamper-resistant llms
Debdeep Sanyal, Manodeep Ray, and Murari Mandal. Antidote: Bi-level adversarial training for tamper-resistant llms. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 32893–32901, 2026
2026
-
[35]
Eleutherai/lm-evaluation- harness: v0
Lintang Sutawika, Hailey Schoelkopf, Leo Gao, Baber Abbasi, Stella Biderman, Jonathan Tow, Charles Lovering, Jason Phang, Anish Thite, Thomas Wang, et al. Eleutherai/lm-evaluation- harness: v0. 4.9.Zenodo, 2025
2025
-
[36]
Intriguing properties of neural networks
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Good- fellow, and Rob Fergus. Intriguing properties of neural networks. InInternational Conference on Learning Representations, 2014. 12
2014
-
[37]
Tamper-resistant safeguards for open-weight llms.arXiv preprint arXiv:2408.00761, 2024
Rishub Tamirisa, Bhrugu Bharathi, Long Phan, Andy Zhou, Alice Gatti, Tarun Suresh, Maxwell Lin, Justin Wang, Rowan Wang, Ron Arel, et al. Tamper-resistant safeguards for open-weight llms.arXiv preprint arXiv:2408.00761, 2024
-
[38]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Alpaca: A strong, replicable instruction-following model. Stanford Center for Research on Foundation Models, 2023
2023
-
[39]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
On adaptive attacks to adversarial example defenses
Florian Tramèr, Nicholas Carlini, Wieland Brendel, and Aleksander Madry. On adaptive attacks to adversarial example defenses. InAdvances in Neural Information Processing Systems, volume 33, pages 1633–1645, 2020
2020
-
[41]
Self-destructive language model.arXiv preprint arXiv:2505.12186, 2025
Yuhui Wang, Rongyi Zhu, and Ting Wang. Self-destructive language model.arXiv preprint arXiv:2505.12186, 2025
-
[42]
Assessing the brittleness of safety alignment via pruning and low-rank modifications
Boyi Wei, Kaixuan Huang, Yangsibo Huang, Tinghao Xie, Xiangyu Qi, Mengzhou Xia, Prateek Mittal, Mengdi Wang, and Peter Henderson. Assessing the brittleness of safety alignment via pruning and low-rank modifications. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 52588–52...
2024
-
[43]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Xianjun Yang, Xiao Wang, Qi Zhang, Linda Ruth Petzold, William Yang Wang, Xun Zhao, and Dahua Lin. Shadow alignment: The ease of subverting safely-aligned language models.arXiv preprint arXiv:2310.02949, 2023
-
[46]
Biao Yi, Tiansheng Huang, Baolei Zhang, Tong Li, Lihai Nie, Zheli Liu, and Li Shen. Ctrap: Embedding collapse trap to safeguard large language models from harmful fine-tuning.arXiv preprint arXiv:2505.16559, 2025
-
[47]
Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, 2019
2019
-
[48]
Removing RLHF protections in GPT-4 via fine-tuning
Qiusi Zhan, Richard Fang, Rohan Bindu, Akul Gupta, Tatsunori Hashimoto, and Daniel Kang. Removing RLHF protections in GPT-4 via fine-tuning. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), pages 681–687. Association for Computational ...
2024
-
[49]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023. 13 A Ethics and dual-use considerations This work studies adaptive attacks on defenses against malicious fine-tuning, and is therefore dual- use: the same ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
as an automated judge to score whether a model response to a held-out BeaverTails prompt is harmful. Both uses are standard in the MFT-defense literature we evaluate against, and we apply the same judge identically to base, defended, and attacked checkpoints so that any reported delta is judge-consistent across conditions. We also use LLMs for writing ass...
-
[51]
LoRA (r, α,drop)
LoRA configuration: rank r= 16 , α= 32 , dropout 0.05, applied to the full set of attention and MLP projections {q,k,v,o,gate,up,down}_proj, task type CAUSAL_LM, no bias adaptation. The mixed objective Lattack =λ h Lharm +λ b Lbenign uses λh =λ b = 1.0 (equivalently λ= 0.5 in the normalized form of Appendix F). The same configuration is used across all th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.