Recognition: no theorem link
Vision-Core Guided Contrastive Learning for Balanced Multi-modal Prognosis Prediction of Stroke
Pith reviewed 2026-05-15 04:43 UTC · model grok-4.3
The pith
Vision features condition the fusion of LLM-generated text with clinical data to enable effective tri-modal stroke prognosis prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By generating semi-structured diagnostic text from brain MRIs with an LLM and feeding visual features as a conditional prior into the Vision-Conditioned Dual Alignment Fusion Module, the model performs fine-grained bidirectional alignment with the text through a dual semantic alignment loss, thereby integrating the three modalities of images, structured clinical data, and unstructured text for ischemic stroke prognosis prediction.
What carries the argument
The Vision-Conditioned Dual Alignment Fusion Module (VDAFM), which uses visual features as a conditional prior to guide alignment and fusion with LLM-generated text via dual semantic alignment loss.
If this is right
- Extends multi-modal fusion from dual-modal to tri-modal setups for stroke prognosis.
- Uses vision as a guiding prior to reduce heterogeneity between image and text modalities.
- Generates text descriptions automatically to bypass the need for additional expert annotations.
- Achieves state-of-the-art results on a real-world clinical dataset through the combined enrichment and alignment steps.
Where Pith is reading between the lines
- The same vision-guided text alignment pattern could be tested on other prognosis tasks such as heart failure or cancer where paired imaging and notes are available but incomplete.
- If the generated text proves stable across different LLMs, hospitals could insert the pipeline into existing imaging workflows with minimal new labeling effort.
- The contrastive component implied by the title suggests a route to prevent any single modality from dominating the learned representation.
- Broader validation on multi-site stroke registries would be needed to check whether the reported gains hold when MRI protocols and patient demographics vary.
Load-bearing premise
The text automatically produced by the LLM from MRIs is accurate enough and free of hallucinations to serve as reliable semantic input for the fusion process.
What would settle it
Replacing the LLM-generated text with expert radiologist reports and observing no gain or a performance drop over strong dual-modal baselines on the same clinical dataset would falsify the benefit of the proposed enrichment and alignment steps.
Figures




read the original abstract
Deep learning and multi-modal fusion have demonstrated transformative potential in medical diagnosis by integrating diverse data sources. However, accurate prognosis for ischemic stroke remains challenging due to limitations in existing multi-modal approaches. First, current methods are predominantly confined to dual-modal fusion, lacking a framework that effectively integrates the trifecta of medical images, structured clinical data, and unstructured text. Second, they often fail to establish deep bidirectional interactions between modalities; To address these critical gaps, this paper proposes a novel tri-modal fusion model for ischemic stroke prognosis. Our approach first enriches the data representation by employing a Large Language Model (LLM) to automatically generate semi-structured diagnostic text from brain MRIs. This process not only addresses the scarcity of expert annotations but also serves as a regularized semantic enhancement, improving multimodal fusion robustness. Furthermore, we design a core component termed the Vision-Conditioned Dual Alignment Fusion Module (VDAFM), which strategically uses visual features as a conditional prior to guide fine-grained interaction with the generated text. This module achieves a dynamic and profound fusion through a dual semantic alignment loss, effectively mitigating modal heterogeneity. Extensive experiments on a real-world clinical dataset demonstrate that our model achieves state-of-the-art performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a tri-modal fusion model for ischemic stroke prognosis prediction that integrates brain MRI images, structured clinical data, and LLM-generated semi-structured diagnostic text from MRIs. It introduces the Vision-Conditioned Dual Alignment Fusion Module (VDAFM) to use visual features as a conditional prior for guiding fine-grained interaction with the generated text, employing a dual semantic alignment loss to mitigate modal heterogeneity. The authors claim that extensive experiments on a real-world clinical dataset demonstrate state-of-the-art performance.
Significance. If the central performance claims hold after proper validation, the work could advance multi-modal medical AI by providing a framework for tri-modal integration that addresses data scarcity via LLM augmentation and reduces heterogeneity through vision-conditioned alignment. The VDAFM design offers a concrete mechanism for bidirectional interaction that goes beyond standard dual-modal fusion. However, without reported metrics or validation of the LLM component, the practical significance remains difficult to evaluate.
major comments (2)
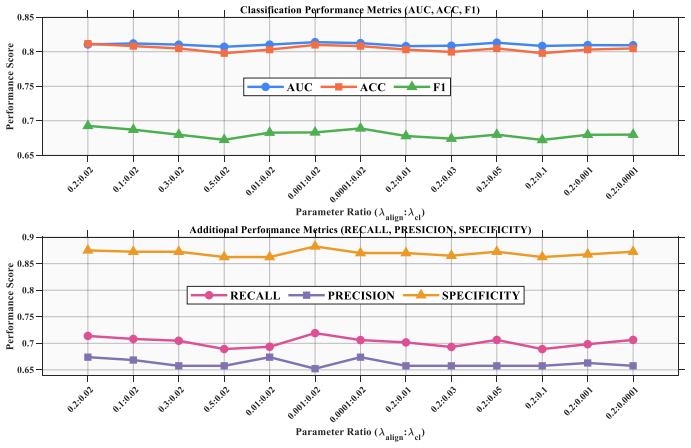
- Abstract: The assertion that the model 'achieves state-of-the-art performance' is load-bearing for the central claim but is unsupported by any quantitative metrics, baselines, error bars, statistical tests, or dataset characteristics, rendering the performance gains unverifiable.
- Abstract (and implied experimental section): The dual semantic alignment loss and VDAFM effectiveness rest on the assumption that LLM-generated diagnostic text provides accurate, unbiased semantic enhancement without hallucinations or systematic biases relative to the source MRIs; no validation, error analysis, or comparison to expert annotations is reported, which directly undermines the tri-modal fusion claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our contributions. We address each major point below and commit to revisions that strengthen verifiability without altering the core technical claims.
read point-by-point responses
-
Referee: Abstract: The assertion that the model 'achieves state-of-the-art performance' is load-bearing for the central claim but is unsupported by any quantitative metrics, baselines, error bars, statistical tests, or dataset characteristics, rendering the performance gains unverifiable.
Authors: We agree that the abstract should provide concrete quantitative support. In the revised version we will insert the key results (AUC, accuracy, F1 with standard deviations across 5-fold cross-validation), list the primary baselines, report dataset size and class balance, and add a brief statement on statistical significance testing. These numbers are already present in the experimental tables and will be summarized concisely in the abstract. revision: yes
-
Referee: Abstract (and implied experimental section): The dual semantic alignment loss and VDAFM effectiveness rest on the assumption that LLM-generated diagnostic text provides accurate, unbiased semantic enhancement without hallucinations or systematic biases relative to the source MRIs; no validation, error analysis, or comparison to expert annotations is reported, which directly undermines the tri-modal fusion claims.
Authors: We acknowledge the absence of explicit LLM-text validation in the current draft. We will add a dedicated subsection (Section 4.4) that reports: (i) a manual review of 200 randomly sampled LLM outputs by two neuroradiologists, (ii) quantitative metrics (BERTScore, entity-level precision/recall against expert notes where available), and (iii) an error analysis categorizing hallucinations and biases. This analysis will be used to justify the dual-alignment loss design and will be referenced in the abstract. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes a tri-modal fusion architecture (LLM-generated text from MRIs plus VDAFM with dual semantic alignment loss) and supports its SOTA claim solely via experimental results on a clinical dataset. No equations, derivation steps, or self-citation chains are exhibited in the provided text that reduce the performance claims to fitted parameters, self-definitions, or renamed inputs by construction. The central argument therefore remains self-contained against external benchmarks rather than internally forced.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-generated text from MRIs serves as accurate and regularized semantic enhancement without introducing bias or errors
invented entities (1)
-
Vision-Conditioned Dual Alignment Fusion Module (VDAFM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
V . L. Feigin, M. D. Abate, Y . H. Abate, S. Abd ElHafeez, F. Abd-Allah, A. Abde- lalim, A. Abdelkader, M. Abdelmasseh, S. Abd-Elsalam, P. Abdi, et al., Global, regional, and national burden of stroke and its risk factors, 1990–2021: a system- atic analysis for the global burden of disease study 2021, The Lancet Neurology 23 (10) (2024) 973–1003
work page 1990
-
[2]
S. Liu, Y . Li, X. Lan, L. Wang, H. Li, D. Gu, M. Wang, J. Liu, Global, regional, and national trends in ischaemic stroke burden and risk factors among adults aged 20+years (1990–2021): a systematic analysis of data from the global burden of disease study 2021 with projections into 2050, Frontiers in Public Health 13 (2025) 1567275
work page 1990
-
[3]
H. Yu, Z. Wang, Y . Sun, W. Bo, K. Duan, C. Song, Y . Hu, J. Zhou, Z. Mu, N. Wu, Prognosis of ischemic stroke predicted by machine learning based on multi-modal mri radiomics, Frontiers in Psychiatry 13 (2023) 1105496. 27
work page 2023
-
[4]
S. A. Alaka, B. K. Menon, A. Brobbey, T. Williamson, M. Goyal, A. M. Dem- chuk, M. D. Hill, T. T. Sajobi, Functional outcome prediction in ischemic stroke: a comparison of machine learning algorithms and regression models, Frontiers in neurology 11 (2020) 889
work page 2020
-
[5]
T. K. Ho, Random decision forests, in: Proceedings of 3rd international confer- ence on document analysis and recognition, V ol. 1, IEEE, 1995, pp. 278–282
work page 1995
-
[6]
M. M. Ghiasi, S. Zendehboudi, A. A. Mohsenipour, Decision tree-based diagno- sis of coronary artery disease: Cart model, Computer methods and programs in biomedicine 192 (2020) 105400
work page 2020
-
[7]
B. Sahu, S. N. Mohanty, Cmba-svm: a clinical approach for parkinson disease diagnosis, International Journal of Information Technology 13 (2) (2021) 647– 655
work page 2021
-
[8]
S. Nusinovici, Y . C. Tham, M. Y . C. Yan, D. S. W. Ting, J. Li, C. Sabanayagam, T. Y . Wong, C.-Y . Cheng, Logistic regression was as good as machine learning for predicting major chronic diseases, Journal of clinical epidemiology 122 (2020) 56–69
work page 2020
-
[9]
S. Shurrab, A. Guerra-Manzanares, A. Magid, B. Piechowski-Jozwiak, S. F. Atashzar, F. E. Shamout, Multimodal machine learning for stroke prognosis and diagnosis: A systematic review, IEEE Journal of Biomedical and Health Infor- matics (2024)
work page 2024
-
[10]
H. Yu, Z. Wang, Y . Sun, W. Bo, K. Duan, C. Song, Y . Hu, J. Zhou, Z. Mu, N. Wu, Prognosis of ischemic stroke predicted by machine learning based on multi-modal mri radiomics, Frontiers in Psychiatry 13 (2023) 1105496
work page 2023
-
[11]
D. Ma, M. Wang, A. Xiang, Z. Qi, Q. Yang, Transformer-based classification outcome prediction for multimodal stroke treatment, in: 2024 IEEE 2nd Interna- tional Conference on Sensors, Electronics and Computer Engineering (ICSECE), IEEE, 2024, pp. 383–386. 28
work page 2024
-
[12]
G. Brugnara, U. Neuberger, M. A. Mahmutoglu, M. Foltyn, C. Herweh, S. Nagel, S. Schönenberger, S. Heiland, C. Ulfert, P. A. Ringleb, et al., Multimodal predic- tive modeling of endovascular treatment outcome for acute ischemic stroke using machine-learning, Stroke (2020)
work page 2020
-
[13]
Z. A. Samak, P. Clatworthy, M. Mirmehdi, Prediction of thrombectomy functional outcomes using multimodal data, in: Annual Conference on Medical Image Un- derstanding and Analysis, Springer, 2020, pp. 267–279
work page 2020
-
[14]
A. K. Bonkhoff, C. Grefkes, Precision medicine in stroke: towards personalized outcome predictions using artificial intelligence, Brain 145 (2) (2022) 457–475
work page 2022
- [15]
-
[16]
L. Sun, C. Ahuja, P. Chen, M. D’Zmura, K. Batmanghelich, P. Bontrager, Multi- modal large language models are effective vision learners, in: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV), IEEE, 2025, pp. 8617–8626
work page 2025
-
[17]
Z. Li, H. Lu, H. Fu, F. Meng, G. Gu, Csan: cross-coupled semantic adversarial network for cross-modal retrieval, Artificial Intelligence Review 58 (5) (2025) 1–27
work page 2025
-
[18]
X. Liu, F. Hou, H. Qin, A. Hao, Multi-view multi-scale cnns for lung nodule type classification from ct images, Pattern Recognition 77 (2018) 262–275
work page 2018
-
[19]
G. Amit, R. Ben-Ari, O. Hadad, E. Monovich, N. Granot, S. Hashoul, Classi- fication of breast mri lesions using small-size training sets: comparison of deep learning approaches, in: Medical Imaging 2017: Computer-Aided Diagnosis, V ol. 10134, SPIE, 2017, pp. 374–379
work page 2017
- [20]
-
[21]
A. Nielsen, M. B. Hansen, A. Tietze, K. Mouridsen, Prediction of tissue outcome and assessment of treatment effect in acute ischemic stroke using deep learning, Stroke 49 (6) (2018) 1394–1401
work page 2018
-
[22]
X. Li, X. Pan, C. Jiang, M. Wu, Y . Liu, F. Wang, X. Zheng, J. Yang, C. Sun, Y . Zhu, et al., Predicting 6-month unfavorable outcome of acute ischemic stroke using machine learning, Frontiers in neurology 11 (2020) 539509
work page 2020
-
[23]
J. Heo, J. G. Yoon, H. Park, Y . D. Kim, H. S. Nam, J. H. Heo, Machine learning– based model for prediction of outcomes in acute stroke, Stroke 50 (5) (2019) 1263–1265
work page 2019
-
[24]
L. A. Vale-Silva, K. Rohr, Long-term cancer survival prediction using multimodal deep learning, Scientific Reports 11 (1) (2021) 13505
work page 2021
-
[25]
G. Lee, K. Nho, B. Kang, K.-A. Sohn, D. Kim, Predicting alzheimer’s disease progression using multi-modal deep learning approach, Scientific reports 9 (1) (2019) 1952
work page 2019
-
[26]
M. Zarrabi, H. Parsaei, R. Boostani, A. Zare, Z. Dorfeshan, K. Zarrabi, J. Ko- juri, A system for accurately predicting the risk of myocardial infarction using pcg, ecg and clinical features, Biomedical Engineering: Applications, Basis and Communications 29 (03) (2017) 1750023
work page 2017
-
[27]
T. Xiao, L. Shi, H. Wang, Z. Wang, Y . Lin, Stroke outcome prediction via multi- level feature and multi-modal fusion network, in: 2024 IEEE International Con- ference on Bioinformatics and Biomedicine (BIBM), IEEE, 2024, pp. 6732– 6739
work page 2024
-
[28]
Z. A. Samak, P. Clatworthy, M. Mirmehdi, Automatic prediction of stroke treat- ment outcomes: latest advances and perspectives, Biomedical Engineering Let- ters (2025) 1–22
work page 2025
-
[29]
Z. Liu, M. Liu, J. Chen, J. Xu, B. Cui, C. He, W. Zhang, Fusion: Fully integration of vision-language representations for deep cross-modal understanding (2025). 30
work page 2025
- [30]
- [31]
-
[32]
C. Yoon, S. Misra, K.-J. Kim, C. Kim, B. J. Kim, Collaborative multi-modal deep learning and radiomic features for classification of strokes within 6 h, Expert Systems with Applications 228 (2023) 120473
work page 2023
-
[33]
T. Shi, H. Jiang, B. Zheng, C 2 ma-net: Cross-modal cross-attention network for acute ischemic stroke lesion segmentation based on ct perfusion scans, IEEE Transactions on Biomedical Engineering 69 (1) (2021) 108–118
work page 2021
-
[34]
A. W. Salehi, S. Khan, G. Gupta, B. I. Alabduallah, A. Almjally, H. Alsolai, T. Siddiqui, A. Mellit, A study of cnn and transfer learning in medical imaging: Advantages, challenges, future scope, Sustainability 15 (7) (2023) 5930
work page 2023
-
[35]
A. B. Parsa, A. Movahedi, H. Taghipour, S. Derrible, A. K. Mohammadian, To- ward safer highways, application of xgboost and shap for real-time accident de- tection and feature analysis, Accident Analysis & Prevention 136 (2020) 105405
work page 2020
-
[36]
D. E. Rumelhart, G. E. Hinton, R. J. Williams, Learning representations by back- propagating errors, nature 323 (6088) (1986) 533–536. 31
work page 1986
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.