Persian MusicGen: A Large-Scale Dataset and Culturally-Aware Generative Model for Persian Music
Pith reviewed 2026-06-30 20:22 UTC · model grok-4.3
The pith
Fine-tuning MusicGen on a new 900-hour Persian dataset yields compositions that align more closely with Persian stylistic conventions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Curating a diverse 900-hour Persian audio dataset and fine-tuning MusicGen on it produces generated music whose semantic content more accurately matches Persian style tags and conventions than the base model does.
What carries the argument
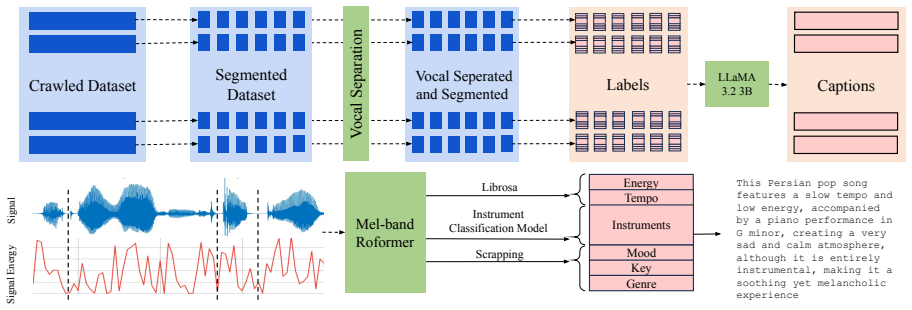
The 900-hour curated Persian music dataset, which supplies the training signal for adapting MusicGen's generation to Persian tonalities, modalities, and rhythms.
If this is right
- Music generation models become usable for Persian sub-genres without requiring entirely new architectures.
- Tag-conditioned generation can reflect modal and rhythmic features specific to Dastgah-based music.
- The same dataset-plus-fine-tuning approach can be repeated for other underrepresented musical traditions.
- Objective tag-accuracy scores become a practical proxy for cultural alignment in generative music.
Where Pith is reading between the lines
- Future work could test whether the same fine-tuned model transfers to related modal traditions such as Arabic or Turkish music.
- The dataset itself could support research on automatic transcription or analysis of Persian rhythmic cycles.
- If tag accuracy correlates with human preference, similar metrics might accelerate evaluation for other low-resource music domains.
Load-bearing premise
The dataset captures a representative sample of Persian music's full diversity and the chosen metrics validly measure stylistic alignment without bias from the evaluation process itself.
What would settle it
A controlled listening study or tag-accuracy test in which the fine-tuned model shows no improvement over the base MusicGen on Persian-specific style tags or human judgments of cultural fit.
Figures

read the original abstract
Persian music, with its unique tonalities, modal systems (Dastgah), and rhythmic structures, presents significant challenges for music generation models trained primarily on Western music. We address this gap by curating the first large-scale dataset of Persian songs, comprising over 900 hours high-quality audio samples across diverse sub-genres, including pop, traditional, and contemporary styles. This dataset captures the rich melodic and cultural diversity of Persian music and serves as the foundation for fine-tuning MusicGen, a state-of-the-art generative music model. We adapt MusicGen to this domain and evaluate its performance by utilizing subjective and objective metrics. To assess the semantic alignment between generated music and intended style tags, we report the proportion of relevant tags accurately reflected in the generated outputs. Our results demonstrate that the fine-tuned model produces compositions that more align with Persian stylistic conventions. This work introduces a new resource for generative music research and illustrates the adaptability of music generation models to underrepresented cultural and linguistic contexts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to curate the first large-scale Persian music dataset (>900 hours across pop, traditional, and contemporary sub-genres) and fine-tune MusicGen on it, reporting that the resulting model produces outputs with greater alignment to Persian stylistic conventions (Dastgah, rhythms) as measured by the proportion of relevant tags accurately reflected plus unspecified subjective metrics.
Significance. If the central empirical claim holds after details are supplied, the work supplies a valuable new public resource for culturally diverse music generation research and illustrates domain adaptation of a Western-centric model. The scale and genre coverage of the dataset constitute a concrete contribution to addressing under-representation in audio AI.
major comments (4)
- [Abstract] Abstract: the headline claim that fine-tuning yields compositions that 'more align with Persian stylistic conventions' is unsupported by any reported numerical values for tag accuracy, any baseline comparisons, any statistical tests, or any description of the subjective metrics.
- [Methods] Methods / fine-tuning description: no procedure, hyperparameters, optimizer settings, or training schedule are supplied, rendering the adaptation step unreproducible and preventing assessment of whether the reported alignment improvement is attributable to the Persian data rather than generic fine-tuning effects.
- [Dataset] Dataset curation section: selection criteria, quality filtering, annotation protocol for style tags, and coverage of microtonal/modal (Dastgah) and rhythmic conventions are not described, so the representativeness assumption required for the cultural-alignment claim cannot be evaluated.
- [Evaluation] Evaluation: the tag-accuracy metric is not shown to be sensitive to Persian-specific features (e.g., microtonality, Dastgah modal structure) rather than generic timbral or rhythmic similarity; no expert validation or bias controls for the subjective scores are reported.
minor comments (1)
- [Introduction] Add explicit citation to the original MusicGen paper and to any prior non-Western music-generation datasets for context.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below. Where the manuscript is missing required details for reproducibility and substantiation of claims, we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that fine-tuning yields compositions that 'more align with Persian stylistic conventions' is unsupported by any reported numerical values for tag accuracy, any baseline comparisons, any statistical tests, or any description of the subjective metrics.
Authors: We agree the abstract does not contain the supporting numbers or comparisons. In the revision we will add the specific tag-accuracy proportions, baseline results against the original MusicGen, any statistical tests performed, and a concise description of the subjective metrics. revision: yes
-
Referee: [Methods] Methods / fine-tuning description: no procedure, hyperparameters, optimizer settings, or training schedule are supplied, rendering the adaptation step unreproducible and preventing assessment of whether the reported alignment improvement is attributable to the Persian data rather than generic fine-tuning effects.
Authors: We will insert a complete fine-tuning subsection that specifies the procedure, all hyperparameters, optimizer, learning-rate schedule, and training duration so that the adaptation can be reproduced and its effect isolated from generic fine-tuning. revision: yes
-
Referee: [Dataset] Dataset curation section: selection criteria, quality filtering, annotation protocol for style tags, and coverage of microtonal/modal (Dastgah) and rhythmic conventions are not described, so the representativeness assumption required for the cultural-alignment claim cannot be evaluated.
Authors: We will expand the dataset section with explicit selection criteria, quality-filtering steps, the annotation protocol used for style tags, and evidence of coverage for Dastgah modal systems and rhythmic conventions. revision: yes
-
Referee: [Evaluation] Evaluation: the tag-accuracy metric is not shown to be sensitive to Persian-specific features (e.g., microtonality, Dastgah modal structure) rather than generic timbral or rhythmic similarity; no expert validation or bias controls for the subjective scores are reported.
Authors: We will add supporting analysis or justification that the tag-accuracy metric captures Persian-specific features such as microtonality and Dastgah structure. We will also report any expert validation performed and describe bias-control procedures for the subjective scores; if these were not conducted we will state the limitation and the rationale for the chosen protocol. revision: partial
Circularity Check
No circularity: empirical dataset curation and fine-tuning with external metrics
full rationale
The paper is an applied empirical study: it curates a dataset of Persian audio, fine-tunes the pre-existing MusicGen model, and reports tag accuracy plus subjective scores. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim rests on measured outputs from an external model and human/objective evaluators rather than any derivation that reduces to its own inputs by construction. This is the normal non-circular case for dataset-plus-fine-tuning papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
MusicLM: Generating Music From Text
Andrea Agostinelli, Timo I. Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, Matt Sharifi, Neil Zeghidour, and Christian Frank. 2023. https://arxiv.org/abs/2301.11325 Musiclm: Generating music from text . Preprint, arXiv:2301.11325
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
B. Baba Ali, A. Gorgan Mohammadi, and A. Faraji Dizaji. 2019. https://doi.org/10.22034/jasp.2019.10444 Nava: A persian traditional music database for the dastgah and instrument recognition tasks . Advanced Signal Processing, 3(2):125--134
-
[5]
Dmitry Bogdanov, Minz Won, Philip Tovstogan, Alastair Porter, and Xavier Serra. 2019. http://hdl.handle.net/10230/42015 The mtg-jamendo dataset for automatic music tagging . In Machine Learning for Music Discovery Workshop, International Conference on Machine Learning (ICML 2019), Long Beach, CA, United States
2019
- [6]
-
[7]
Micha\"el Defferrard, Kirell Benzi, Pierre Vandergheynst, and Xavier Bresson. 2017. https://arxiv.org/abs/1612.01840 FMA : A dataset for music analysis . In 18th International Society for Music Information Retrieval Conference (ISMIR)
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [8]
- [9]
- [10]
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Curtis Hawthorne, Andriy Stasyuk, Adam Roberts, Ian Simon, Cheng-Zhi Anna Huang, Sander Dieleman, Erich Elsen, Jesse Engel, and Douglas Eck. 2019. https://arxiv.org/abs/1810.12247 Enabling factorized piano music modeling and generation with the maestro dataset . Preprint, arXiv:1810.12247
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [13]
- [14]
- [15]
-
[16]
Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, and Mark D Plumbley. 2024. Audioldm 2: Learning holistic audio generation with self-supervised pretraining. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 32:2871--2883
2024
- [17]
- [18]
-
[19]
Ethan Manilow, Gordon Wichern, Prem Seetharaman, and Jonathan Le Roux. 2019. Cutting music source separation some Slakh : A dataset to study the impact of training data quality and quantity. In Proc. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA). IEEE
2019
- [20]
- [21]
-
[22]
Seyed Muhammad Hossein Mousavi, VB Surya Prasath, and Seyed Muhammad Hassan Mousavi. 2019. Persian classical music instrument recognition (pcmir) using a novel persian music database. In 2019 9th International Conference on Computer and Knowledge Engineering (ICCKE), pages 122--130. IEEE
2019
-
[23]
Babak Nikzat and Rafael Caro Repetto. 2022. https://doi.org/10.5281/zenodo.7316660 Kdc: an open corpus for computational research of dastgāhi music . In Proceedings of the 23rd International Society for Music Information Retrieval Conference, pages 321--328. ISMIR
-
[24]
Colin Raffel. 2016. https://doi.org/10.7916/D8N58MHV Learning-Based Methods for Comparing Sequences, with Applications to Audio-to-MIDI Alignment and Matching . Ph.D. thesis, Columbia University, USA
- [25]
-
[26]
Sepideh Shafiei and Shapour Hakam. 2025. https://doi.org/10.1145/3748336.3748341 The irma dataset: A structured audio–midi corpus for iranian classical music . In Proceedings of the 12th International Conference on Digital Libraries for Musicology, DLfM 2025, page 36–43. ACM
-
[27]
John Thickstun, Zaid Harchaoui, and Sham M. Kakade. 2016. https://doi.org/10.5281/zenodo.5120004 Musicnet
- [28]
- [29]
-
[30]
Ruibin Yuan, Yinghao Ma, Yizhi Li, Ge Zhang, Xingran Chen, Hanzhi Yin, Yiqi Liu, Jiawen Huang, Zeyue Tian, Binyue Deng, and 1 others. 2023. Marble: Music audio representation benchmark for universal evaluation. Advances in Neural Information Processing Systems, 36:39626--39647
2023
-
[31]
Chong Zhang, Yukun Ma, Qian Chen, Wen Wang, Shengkui Zhao, Zexu Pan, Hao Wang, Chongjia Ni, Trung Hieu Nguyen, Kun Zhou, and 1 others. 2025. Inspiremusic: Integrating super resolution and large language model for high-fidelity long-form music generation. arXiv preprint arXiv:2503.00084
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.