Tokenizer Fertility and Zero-Shot Performance of Foundation Models on Ukrainian Legal Text: A Comparative Study
Pith reviewed 2026-05-20 21:04 UTC · model grok-4.3
The pith
Tokenizer fertility varies by a factor of 1.6 across foundation models on Ukrainian legal text, a cost factor ignored in current model selection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
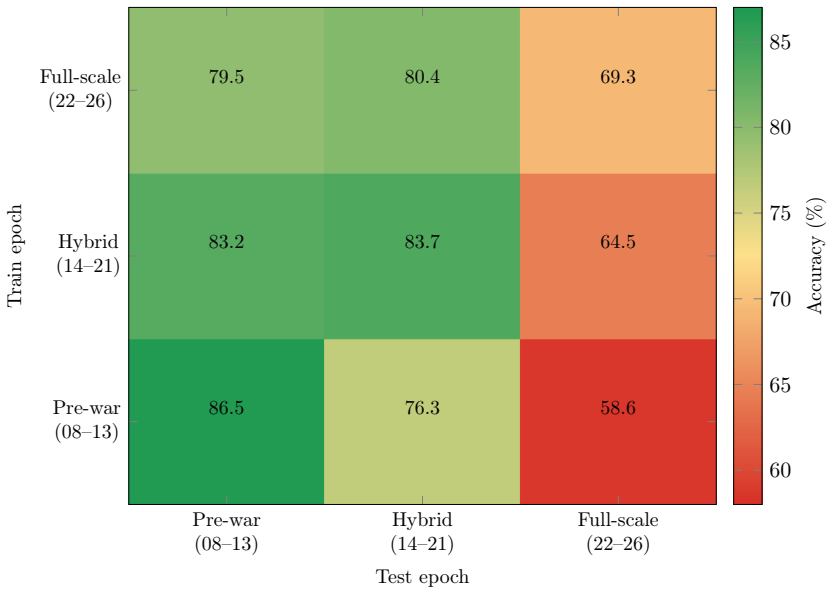
Tokenizer fertility, defined as the number of tokens a model uses for a given text, ranges from lowest in Llama-family models to 60 percent higher in Qwen 3 models on Ukrainian legal inputs. NVIDIA Nemotron Super 3 (120B) scores highest overall while costing less than larger alternatives. Few-shot prompting lowers performance by up to 26 points due to language-specific effects. Classifiers lose 27.9 points when tested on post-invasion decisions after training on pre-war ones, with newer models transferring better backward than forward.
What carries the argument
Tokenizer fertility, which counts the tokens needed to represent fixed legal text and thereby sets the effective cost and context length for any downstream task.
If this is right
- Model selection for Ukrainian legal applications must include tokenizer fertility checks to avoid unnecessary cost increases.
- Zero-shot prompting is more reliable than few-shot for this morphologically rich language.
- Model parameter count does not reliably predict performance on specialized legal classification tasks.
- Legal classifiers require regular updates or validation when the underlying social and legal context changes over time.
- Public release of annotated Ukrainian court data fills a gap in existing benchmarks for non-English legal NLP.
Where Pith is reading between the lines
- Token efficiency differences likely affect other languages with complex morphology beyond Ukrainian.
- Systems could dynamically route inputs to the most fertile tokenizer for a given language or domain.
- The observed asymmetry in temporal transfer may generalize to other domains experiencing rapid language evolution.
- Dataset releases like this one enable future work on conflict-related shifts in legal language.
Load-bearing premise
The 273 court decisions drawn from the state registry stand in for the broader Ukrainian legal language and the three evaluation tasks across the studied time periods.
What would settle it
A follow-up experiment that applies the same tokenization and task measurements to a larger, independently collected sample of Ukrainian legal texts and finds no 1.6x fertility spread or the reported performance gaps would falsify the central claims.
Figures



read the original abstract
Tokenizer fertility varies 1.6x across foundation models on Ukrainian legal text, yet this cost-critical dimension is absent from model selection practice. We benchmark seven models from five providers on 273 validated court decisions from Ukraine's state registry (EDRSR), measuring tokenizer fertility and zero-shot performance on three tasks. Four findings emerge. (1) Qwen 3 models consume 60% more tokens than Llama-family models on identical input, making tokenizer analysis a prerequisite for cost-efficient deployment. (2) NVIDIA Nemotron Super 3 (120B) achieves the highest composite score (83.1), outperforming Mistral Large 3 (5.6x more total parameters) at one-third the API cost model scale is a poor proxy for domain performance. (3) Few-shot prompting degrades performance by up to 26 percentage points; stratified and prompt-sensitivity ablations confirm this is intrinsic to Ukrainian-language demonstrations, not an artifact of example selection. (4) A cross-temporal generalization experiment reveals that classifiers trained on pre-war court ecisions (2008-2013) lose 27.9 percentage points when applied to full-scale invasion era decisions (2022-2026), with a pronounced forward-backward asymmetry: newer models transfer backward (+14.6 pp above forward transfer), but older models fail catastrophically on wartime legal language. For practitioners: tokenizer analysis should precede model selection, and zero-shot is a more reliable default than few-shot for morphologically rich languages. To support reproducibility and address the absence of Ukrainian from legal NLP benchmarks, we release a public dataset of 14,452 court decisions spanning 2008-2026, annotated with seven outcome labels across three temporal epochs that capture the impact of armed conflict on judicial proceedings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that tokenizer fertility varies by a factor of 1.6 across seven foundation models on Ukrainian legal text, with Qwen 3 models consuming 60% more tokens than Llama-family models on the same inputs. Benchmarking on 273 validated court decisions from the EDRSR registry shows that NVIDIA Nemotron Super 3 (120B) achieves the highest composite score while being cheaper than larger models, that few-shot prompting degrades performance by up to 26 points due to intrinsic issues with Ukrainian demonstrations, and that cross-temporal generalization from pre-war (2008-2013) to wartime (2022-2026) decisions drops by 27.9 points with asymmetric transfer favoring newer models. The authors release a dataset of 14,452 annotated decisions spanning 2008-2026 to support reproducibility.
Significance. If the empirical measurements hold, the work demonstrates that tokenizer fertility is a first-order cost factor for deploying LLMs in morphologically rich, low-resource legal domains and that model scale is a poor proxy for domain performance. The public release of the large temporally stratified dataset fills a gap in legal NLP resources and enables studies of language shift under armed conflict, strengthening the practical recommendation that tokenizer analysis should precede model selection for Ukrainian legal applications.
major comments (2)
- [Dataset and Experimental Setup] The headline 1.6x fertility variation and all performance results are measured exclusively on the 273 validated EDRSR decisions. The manuscript releases 14,452 decisions but provides no stratification, sampling justification, or robustness checks across subsamples by case type, court level, document length, or temporal epoch. This makes it unclear whether the reported ratios (e.g., Qwen 3 vs. Llama-family) are stable properties of Ukrainian legal text or artifacts of the validated subset, directly weakening the claim that tokenizer analysis must precede model selection in practice.
- [Cross-Temporal Generalization Experiment] The cross-temporal experiment reports a 27.9 pp drop when training on 2008-2013 decisions and testing on 2022-2026 decisions, with a +14.6 pp backward-transfer advantage for newer models. Without explicit details on the classifier architecture, input representation, or controls for document-length and vocabulary-shift confounds, it is difficult to attribute the asymmetry specifically to wartime language change rather than other distributional differences.
minor comments (2)
- [Abstract] The abstract refers to performance on 'three tasks' without naming or briefly describing them; adding this information in the abstract or early introduction would improve readability and allow readers to assess the scope of the zero-shot and few-shot claims.
- [Results] Tables reporting accuracy or composite scores should include standard errors or confidence intervals and the exact number of examples per condition to support the comparative statements (e.g., Nemotron outperforming Mistral Large 3).
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. Below we provide point-by-point responses to the major comments and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Dataset and Experimental Setup] The headline 1.6x fertility variation and all performance results are measured exclusively on the 273 validated EDRSR decisions. The manuscript releases 14,452 decisions but provides no stratification, sampling justification, or robustness checks across subsamples by case type, court level, document length, or temporal epoch. This makes it unclear whether the reported ratios (e.g., Qwen 3 vs. Llama-family) are stable properties of Ukrainian legal text or artifacts of the validated subset, directly weakening the claim that tokenizer analysis must precede model selection in practice.
Authors: We agree that additional details on the dataset construction and robustness would strengthen the paper. The 273 decisions represent a carefully validated subset selected for annotation quality and task suitability from the larger corpus of 14,452 decisions. To address the concern, we will include in the revised manuscript a new appendix or subsection detailing the sampling justification, including available stratifications by case type, court level, and temporal distribution. We will also conduct and report robustness checks by computing tokenizer fertility ratios on multiple random subsamples of the full released dataset to demonstrate that the 1.6x variation is not specific to the validated subset. revision: yes
-
Referee: [Cross-Temporal Generalization Experiment] The cross-temporal experiment reports a 27.9 pp drop when training on 2008-2013 decisions and testing on 2022-2026 decisions, with a +14.6 pp backward-transfer advantage for newer models. Without explicit details on the classifier architecture, input representation, or controls for document-length and vocabulary-shift confounds, it is difficult to attribute the asymmetry specifically to wartime language change rather than other distributional differences.
Authors: We thank the referee for this feedback. While the manuscript describes the overall experimental design, we recognize that more granular details are warranted to support the attribution to language change. In the revised version, we will expand the relevant section to provide explicit details on the classifier architecture, the input representation and preprocessing steps, and add controls including document length normalization and measures of vocabulary shift between the pre-war and wartime periods. These additions will help clarify the sources of the observed asymmetry. revision: yes
Circularity Check
No circularity: direct empirical measurements on external models and new dataset
full rationale
The paper reports tokenizer fertility ratios and zero-shot/few-shot performance scores obtained by applying seven public foundation models to a fixed set of 273 court decisions drawn from the released EDRSR corpus. No equations, fitted parameters, or derivations appear; the 1.6x fertility variation and composite scores are direct counts and accuracy measurements rather than quantities defined in terms of themselves. The cross-temporal generalization experiment likewise consists of training and testing classifiers on temporally partitioned subsets of the same external data. No self-citation is invoked to justify a uniqueness theorem or ansatz, and the central claims remain independent of any internal fitting loop. The study is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The three tasks on court decisions validly measure model performance on Ukrainian legal text understanding.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Tokenizer fertility varies 1.6× across foundation models on Ukrainian legal text... Qwen 3 models consume 60% more tokens than Llama-family models on identical input
-
IndisputableMonolith/Foundation/ArrowOfTime.leanarrow_from_z unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
cross-temporal generalization experiment reveals that classifiers trained on pre-war court decisions (2008–2013) lose 27.9 percentage points when applied to full-scale invasion era decisions (2022–2026)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
NVIDIA Nemotron Super 3 (120B) achieves the highest composite score (83.1), outperforming Mistral Large 3 (5.6× more total parameters)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
How Good is Your Tokenizer? On the Monolingual Performance of Multilingual Language Models
Rust, P., Pfeiffer, J., Vuli\' c , I., Ruder, S., and Gurevych, I. How Good is Your Tokenizer? On the Monolingual Performance of Multilingual Language Models. Proceedings of the 59th Annual Meeting of the ACL, pages 3118--3135, 2021. https://aclanthology.org/2021.acl-long.243/
work page 2021
-
[2]
Language Model Tokenizers Introduce Unfairness Between Languages
Petrov, A., La Malfa, E., Torr, P., and Bibi, A. Language Model Tokenizers Introduce Unfairness Between Languages. Advances in Neural Information Processing Systems, 37, 2024. https://arxiv.org/abs/2305.15425
-
[3]
I., Kreutzer, J., and Hooker, S
Ahia, O., Ogueji, K., Winata, G. I., Kreutzer, J., and Hooker, S. Do All Languages Cost the Same? Tokenization in the Era of Commercial Language Models. Proceedings of EMNLP 2023, pages 9524--9538, 2023. https://aclanthology.org/2023.emnlp-main.614/
work page 2023
-
[4]
Neural Machine Translation of Rare Words with Subword Units
Sennrich, R., Haddow, B., and Birch, A. Neural Machine Translation of Rare Words with Subword Units. Proceedings of the 54th Annual Meeting of the ACL, pages 1715--1725, 2016. https://aclanthology.org/P16-1162/
work page 2016
-
[5]
Kudo, T. and Richardson, J. SentencePiece: A Simple and Language Independent Subword Tokenizer and Detokenizer for Neural Text Processing. Proceedings of EMNLP 2018: System Demonstrations, pages 66--71, 2018. https://aclanthology.org/D18-2012/
work page 2018
-
[6]
LEGAL-BERT: The Muppets straight out of Law School
Chalkidis, I., Fergadiotis, M., Malakasiotis, P., Aletras, N., and Androutsopoulos, I. LEGAL-BERT: The Muppets straight out of Law School. Findings of EMNLP 2020, pages 2898--2904, 2020. https://aclanthology.org/2020.findings-emnlp.261/
work page 2020
-
[7]
LEXTREME : A Multi-Lingual and Multi-Task Benchmark for the Legal Domain
Niklaus, J., Matoshi, V., Rani, P., Galassi, A., St \"u rmer, M., and Chalkidis, I. LEXTREME : A Multi-Lingual and Multi-Task Benchmark for the Legal Domain. Findings of EMNLP 2023, pages 12898--12916, 2023. https://aclanthology.org/2023.findings-emnlp.865/
work page 2023
-
[8]
Measuring Massive Multitask Language Understanding
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring Massive Multitask Language Understanding. Proceedings of ICLR, 2021. https://arxiv.org/abs/2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Language Models are Few-Shot Learners
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., et al. Language Models are Few-Shot Learners. Advances in Neural Information Processing Systems, 33:1877--1901, 2020. https://arxiv.org/abs/2005.14165
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[10]
Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity
Lu, Y., Bartolo, M., Moore, A., Riedel, S., and Stenetorp, P. Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity. Proceedings of the 60th Annual Meeting of the ACL, pages 8086--8098, 2022. https://aclanthology.org/2022.acl-long.556/
work page 2022
-
[11]
Min, S., Lyu, X., Holtzman, A., Arber, M., Lewis, M., Hajishirzi, H., and Zettlemoyer, L. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? Proceedings of EMNLP 2022, pages 11048--11064, 2022. https://aclanthology.org/2022.emnlp-main.759/
work page 2022
-
[12]
Lai, V. D., Ngo, N. T., Veyseh, A. P. B., Man, H., Dernoncourt, F., Bui, T., and Nguyen, T. H. ChatGPT Beyond English: Towards a Comprehensive Evaluation of Large Language Models in Multilingual Learning. Findings of EMNLP 2023, pages 13171--13189, 2023. https://aclanthology.org/2023.findings-emnlp.878/
work page 2023
-
[13]
Unsupervised Cross-lingual Representation Learning at Scale
Conneau, A., Khandelwal, K., Goyal, N., Chaudhary, V., Wenzek, G., et al. Unsupervised Cross-lingual Representation Learning at Scale. Proceedings of the 58th Annual Meeting of the ACL, pages 8440--8451, 2020. https://aclanthology.org/2020.acl-main.747/
work page 2020
-
[14]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., et al. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv preprint arXiv:2307.09288, 2023. https://arxiv.org/abs/2307.09288
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Grattafiori, A., Dubey, A., Jauhri, A., et al. The Llama 3 Herd of Models. arXiv preprint arXiv:2407.21783, 2024. https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
A Survey of AI Agent Protocols.arXiv preprint arXiv:2504.16736, 2025
Meta AI . The Llama 4 Herd of Models. arXiv preprint arXiv:2504.16736, 2025. https://arxiv.org/abs/2504.16736
-
[17]
Mistral AI . Mistral Large. Technical report, 2024. https://mistral.ai/news/mistral-large-2407/
work page 2024
-
[18]
Nemotron Super: Open Hybrid Mamba-Transformer Models
NVIDIA . Nemotron Super: Open Hybrid Mamba-Transformer Models. Technical report, 2025. https://developer.nvidia.com/blog/nemotron-super-open-model-for-enterprise-reasoning/
work page 2025
-
[19]
Amazon Nova: Foundation Models for Enterprise AI
Amazon Web Services . Amazon Nova: Foundation Models for Enterprise AI. Technical report, 2024. https://aws.amazon.com/ai/generative-ai/nova/
work page 2024
-
[20]
Qwen Team . Qwen3 Technical Report. Technical report, 2025. https://qwenlm.github.io/blog/qwen3/
work page 2025
-
[21]
Finetuned Language Models Are Zero-Shot Learners
Wei, J., Bosma, M., Zhao, V., Guu, K., Yu, A. W., Lester, B., Du, N., Dai, A. M., and Le, Q. V. Finetuned Language Models Are Zero-Shot Learners. Proceedings of ICLR, 2022. https://arxiv.org/abs/2109.01652
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Zheng, L., Chiang, W.-L., Sheng, Y., et al. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. Advances in Neural Information Processing Systems, 36, 2024. https://arxiv.org/abs/2306.05685
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
lang-uk: Building a Comprehensive Corpus and Language Technology for Ukrainian
Kotsyba, N., Mykulyak, A., and Shvedova, M. lang-uk: Building a Comprehensive Corpus and Language Technology for Ukrainian. Proceedings of LREC 2018, 2018. https://lang.org.ua/en/
work page 2018
-
[24]
Syvokon, O. and Nahorna, O. UA-GEC : Grammatical Error Correction and Fluency Corpus for the Ukrainian Language. Proceedings of the Second UNLP Workshop, pages 96--102, 2023. https://aclanthology.org/2023.unlp-1.12/
work page 2023
-
[25]
Introducing UberText 2.0: A Corpus of Modern Ukrainian at Scale
Chaplynskyi, D. Introducing UberText 2.0: A Corpus of Modern Ukrainian at Scale. Proceedings of the Second UNLP Workshop, pages 1--10, 2023. https://aclanthology.org/2023.unlp-1.1/
work page 2023
-
[26]
Regularization Paths for Generalized Linear Models via Coordinate Descent
Friedman, J., Hastie, T., and Tibshirani, R. Regularization Paths for Generalized Linear Models via Coordinate Descent. Journal of Statistical Software, 33(1):1--22, 2010. https://www.jstatsoft.org/article/view/v033i01
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.