Concurrency without Model Changes: Future-based Asynchronous Function Calling for LLMs
Pith reviewed 2026-06-30 20:25 UTC · model grok-4.3
The pith
LLMs can natively reason over symbolic futures to enable asynchronous function calling without any model or protocol changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
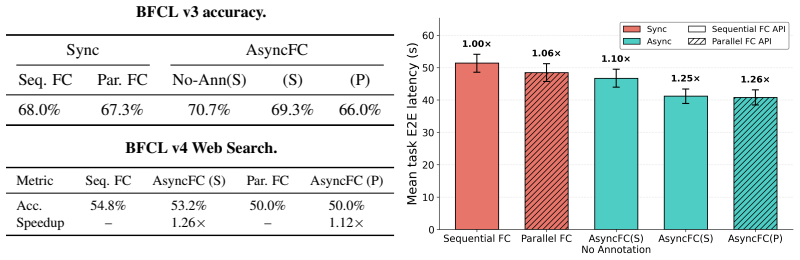
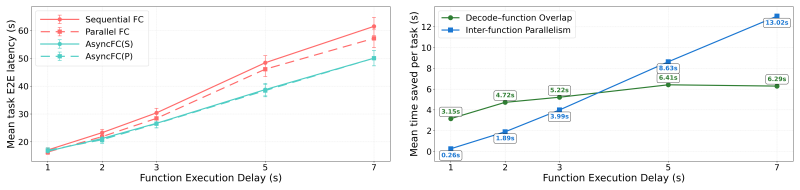
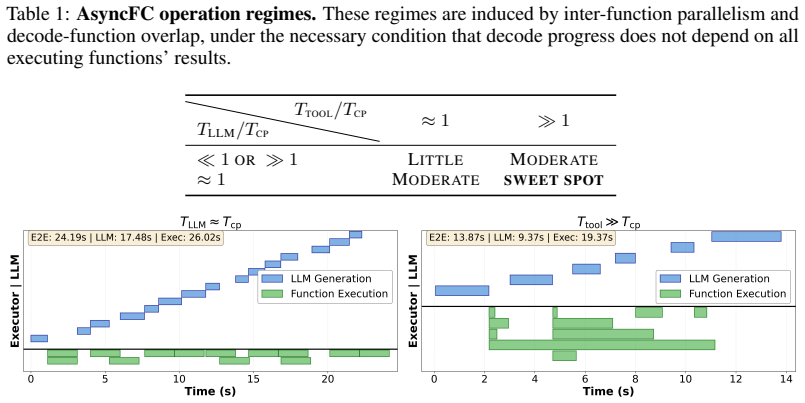
AsyncFC is an execution-layer framework that decouples LLM decoding from function execution by representing unresolved results as symbolic futures. This enables overlap of decoding and execution as well as inter-function parallelism. It works with existing models and unmodified function implementations using the standard synchronous protocol. Experiments show significant reductions in end-to-end task completion time with no loss in task accuracy, revealing LLMs' native ability to reason over such futures.
What carries the argument
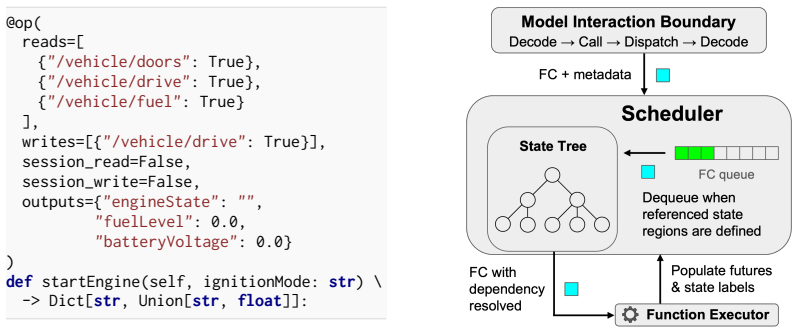
Symbolic futures representing unresolved execution results, allowing the LLM to proceed without waiting for results.
If this is right
- Overlap between model decoding and function execution reduces end-to-end latency.
- Inter-function parallelism occurs when dependencies permit.
- The method requires no fine-tuning or changes to the synchronous protocol.
- Task accuracy is maintained on both standard and adapted benchmarks.
Where Pith is reading between the lines
- This could improve efficiency in real-time LLM agent applications.
- It may generalize to other external tool or API interactions.
- Greater speedups are possible in tasks with higher degrees of independent calls.
Load-bearing premise
The standard synchronous function-calling protocol remains usable without modification and benchmark tasks contain sufficient independent calls to permit measurable parallelism without affecting accuracy.
What would settle it
A benchmark consisting only of strictly sequential dependent function calls where AsyncFC shows no time reduction or causes accuracy drops.
Figures


read the original abstract
Function calling, also known as tool use, is a core capability of modern LLM agents but is typically constrained by synchronous execution semantics. Under these semantics, LLM decoding is blocked until each function call completes, resulting in increasing end-to-end latency. In this work, we introduce AsyncFC, a pure execution-layer framework that decouples LLM decoding from function execution, enabling overlap between model decoding and function execution as well as inter-function parallelism when dependencies permit. AsyncFC layers over existing models and unmodified function implementations, requiring no fine-tuning or changes to the standard synchronous function-calling protocol. Across standard function-calling benchmarks and adapted software engineering benchmarks, AsyncFC significantly reduces end-to-end task completion time while preserving task accuracy. Furthermore, these results reveal that LLMs possess a native capability to reason over symbolic futures that represent unresolved execution results, enabling an asynchronous paradigm for model-tool interaction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AsyncFC, a pure execution-layer framework that enables asynchronous function calling for LLMs by decoupling decoding from execution via symbolic futures representing unresolved results. It claims this permits overlap between model decoding and function execution plus inter-function parallelism when dependencies allow, all while layering over existing models and unmodified function implementations with no fine-tuning or changes to the standard synchronous function-calling protocol. The work reports significant reductions in end-to-end task completion time on standard function-calling benchmarks and adapted software engineering benchmarks while preserving task accuracy, and interprets the results as evidence that LLMs possess a native capability to reason over symbolic futures.
Significance. If the results hold, the framework could improve efficiency of LLM agents by enabling concurrency without model or protocol modifications, a strength given the emphasis on no changes to the synchronous interface. The potential to reveal native symbolic-future reasoning would be of interest if the empirical support is made verifiable.
major comments (2)
- [Abstract] Abstract: the central claims of benchmark improvements (reduced latency, preserved accuracy) and native symbolic-future reasoning are asserted without any methods, error bars, dataset details, or statistical tests, rendering the claims unverifiable from the provided text and undermining soundness of the load-bearing empirical results.
- [Abstract] Abstract: the load-bearing assumption that the unmodified synchronous function-calling protocol suffices for symbolic future reasoning (i.e., that the execution layer can substitute future placeholders into tool responses such that subsequent model-generated calls can reference them via IDs or tokens without any JSON schema, prompt, or decoding changes) receives no concrete representation details, leaving open whether the reported latency gains and accuracy preservation actually demonstrate the claimed native capability.
minor comments (1)
- [Abstract] The abstract would benefit from a brief parenthetical on the exact symbolic representation used for futures to allow readers to assess the 'no model changes' claim immediately.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on the abstract. We address each major comment below and will revise the manuscript to improve verifiability of the claims while preserving the paper's core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of benchmark improvements (reduced latency, preserved accuracy) and native symbolic-future reasoning are asserted without any methods, error bars, dataset details, or statistical tests, rendering the claims unverifiable from the provided text and undermining soundness of the load-bearing empirical results.
Authors: We agree the abstract, as a high-level summary, omits these specifics. The full manuscript details the methods, benchmarks (standard function-calling and adapted software engineering tasks), error bars, accuracy metrics, and statistical tests in the Evaluation section. We will revise the abstract to include brief references to the evaluation setup, observed latency reductions, and accuracy preservation to enhance immediate verifiability. revision: yes
-
Referee: [Abstract] Abstract: the load-bearing assumption that the unmodified synchronous function-calling protocol suffices for symbolic future reasoning (i.e., that the execution layer can substitute future placeholders into tool responses such that subsequent model-generated calls can reference them via IDs or tokens without any JSON schema, prompt, or decoding changes) receives no concrete representation details, leaving open whether the reported latency gains and accuracy preservation actually demonstrate the claimed native capability.
Authors: Section 3 of the manuscript specifies the mechanism: the execution layer inserts symbolic future placeholders as standard IDs or tokens into tool responses using the existing synchronous protocol format. The LLM then references these via the protocol's native ID mechanism in follow-up calls, with no schema, prompt, or decoding modifications required. This substitution is handled purely at the execution layer, directly supporting the native reasoning claim. We will add a concise clarifying phrase and example reference to the revised abstract. revision: yes
Circularity Check
No significant circularity; framework is execution-layer addition with no derivations or self-referential claims
full rationale
The paper introduces AsyncFC as a pure execution-layer framework that layers over existing models and unmodified synchronous function-calling protocols without fine-tuning or changes. No equations, fitted parameters, derivations, or self-referential structures are described in the abstract or claims. The inference that LLMs possess a native capability to reason over symbolic futures is presented as an empirical revelation from benchmark results, not as a load-bearing assumption that reduces to itself or prior self-citations. No patterns matching self-definitional, fitted-input-called-prediction, self-citation-load-bearing, or related circularity kinds are present. The work is self-contained as an engineering framework evaluated on standard benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
symbolic futures
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Ghost Tool Calls: Issue-Time Privacy for Speculative Agent Tools
Ghost tool calls from speculative dispatch create persistent intent leaks that only issue-time policies changing or suppressing call arguments or destinations can reduce, per evaluations of twelve policies on three corpora.
Reference graph
Works this paper leans on
- [1]
-
[2]
H. C. Baker Jr and C. Hewitt. The incremental garbage collection of processes.ACM SIGART Bulletin, (64):55–59, 1977
1977
-
[3]
Bauer, S
M. Bauer, S. Treichler, E. Slaughter, and A. Aiken. Legion: Expressing locality and independence with logical regions. InSC’12: Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, pages 1–11. IEEE, 2012
2012
- [4]
-
[5]
L. E. Erdogan, N. Lee, S. Jha, S. Kim, R. Tabrizi, S. Moon, C. R. C. Hooper, G. Anumanchipalli, K. Keutzer, and A. Gholami. Tinyagent: Function calling at the edge. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 80–88, 2024. 10
2024
- [6]
- [7]
-
[8]
Function calling with the gemini api
Google AI. Function calling with the gemini api. https://ai.google.dev/gemini-api/docs/ function-calling?example=meeting, 2025. Accessed: Jan. 27, 2026
2025
-
[9]
Huang, A
K.-H. Huang, A. Prabhakar, S. Dhawan, Y . Mao, H. Wang, S. Savarese, C. Xiong, P. Laban, and C.-S. Wu. Crmarena: Understanding the capacity of llm agents to perform professional crm tasks in realistic environments. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language T...
2025
-
[10]
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
S. Kim, S. Moon, R. Tabrizi, N. Lee, M. W. Mahoney, K. Keutzer, and A. Gholami. An llm compiler for parallel function calling. InForty-first International Conference on Machine Learning, 2024
2024
-
[12]
Kulkarni, V
M. Kulkarni, V . Mazzia, J. Gaspers, C. Hench, J. FitzGerald, and A. Amazon. Massive-agents: A benchmark for multilingual function-calling in 52 languages. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 20193–20215, 2025
2025
-
[13]
Liskov and L
B. Liskov and L. Shrira. Promises: Linguistic support for efficient asynchronous procedure calls in distributed systems.ACM Sigplan Notices, 23(7):260–267, 1988
1988
- [14]
-
[15]
Q. McNemar. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika, 12(2):153–157, 1947
1947
- [16]
-
[17]
Function calling
OpenAI. Function calling. https://platform.openai.com/docs/guides/function-calling, 2025. Accessed: Jan. 27, 2026
2025
-
[18]
Packer, V
C. Packer, V . Fang, S. Patil, K. Lin, S. Wooders, and J. Gonzalez. Memgpt: towards llms as operating systems. 2023
2023
-
[19]
Pantiukhin, B
D. Pantiukhin, B. Shapkin, I. Kuznetsov, A. A. Jost, and N. Koldunov. Accelerating earth science discovery via multi-agent llm systems.Frontiers in Artificial Intelligence, 8:1674927, 2025
2025
-
[20]
S. G. Patil, T. Zhang, X. Wang, and J. E. Gonzalez. Gorilla: Large language model connected with massive apis.Advances in Neural Information Processing Systems, 37:126544–126565, 2024
2024
-
[21]
S. G. Patil, H. Mao, F. Yan, C. C.-J. Ji, V . Suresh, I. Stoica, and J. E. Gonzalez. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InForty-second International Conference on Machine Learning, 2025
2025
-
[22]
Y . Qin, S. Liang, Y . Ye, K. Zhu, L. Yan, Y . Lu, Y . Lin, X. Cong, X. Tang, B. Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis.arXiv preprint arXiv:2307.16789, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Y . Ruan, H. Dong, A. Wang, S. Pitis, Y . Zhou, J. Ba, Y . Dubois, C. J. Maddison, and T. Hashimoto. Identifying the risks of lm agents with an lm-emulated sandbox.arXiv preprint arXiv:2309.15817, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Schick, J
T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539–68551, 2023
2023
-
[25]
J. E. Thornton. Parallel operation in the control data 6600. InProceedings of the October 27-29, 1964, fall joint computer conference, part II: very high speed computer systems, pages 33–40, 1964
1964
-
[26]
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
M. Wang, Y . Zhang, B. Yu, B. Hao, C. Peng, Y . Chen, W. Zhou, J. Gu, C. Zhuang, R. Guo, et al. Function calling in large language models: Industrial practices, challenges, and future directions.ACM Computing Surveys, 58(9):1–37, 2026
2026
-
[28]
B. Xu, Z. Peng, B. Lei, S. Mukherjee, Y . Liu, and D. Xu. Rewoo: Decoupling reasoning from observations for efficient augmented language models.arXiv preprint arXiv:2305.18323, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press. Swe-agent: Agent- computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
2024
-
[30]
Z. Yang, P. Qi, S. Zhang, Y . Bengio, W. Cohen, R. Salakhutdinov, and C. D. Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380, 2018
2018
-
[31]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
J. Ye, G. Li, S. Gao, C. Huang, Y . Wu, S. Li, X. Fan, S. Dou, T. Ji, Q. Zhang, et al. Tooleyes: Fine-grained evaluation for tool learning capabilities of large language models in real-world scenarios. InProceedings of the 31st international conference on computational linguistics, pages 156–187, 2025
2025
-
[33]
Zhuang, Y
Y . Zhuang, Y . Yu, K. Wang, H. Sun, and C. Zhang. Toolqa: A dataset for llm question answering with external tools.Advances in Neural Information Processing Systems, 36:50117–50143, 2023. A Details for Dependency Specification with Labeling. To enable developers to supply these annotations, AsyncFC introduces a lightweight unified labeling mechanism via ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.