Recognition: no theorem link
FutureSim: Replaying World Events to Evaluate Adaptive Agents
Pith reviewed 2026-05-15 03:08 UTC · model grok-4.3
The pith
FutureSim evaluates AI agents by replaying real historical events in order and shows even the best achieve only 25 percent accuracy on future predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FutureSim builds grounded simulations that replay real-world events in the order they occurred, allowing agents to forecast world events beyond their knowledge cutoff while interacting with chronological real news articles and resolving questions. When frontier agents are tested over January to March 2026, the benchmark reveals a clear separation in capabilities, with the best agent's accuracy at 25 percent and many agents showing worse Brier skill scores than making no prediction at all.
What carries the argument
FutureSim, a simulation that replays real news articles arriving and questions resolving over a simulated period in chronological order without future knowledge leakage.
Load-bearing premise
That replaying real historical events chronologically without future knowledge leakage accurately measures an agent's adaptive capabilities in open-ended real-world settings.
What would settle it
Running the same questions with agents given full access to future information and observing whether accuracy remains low would show the benchmark fails to isolate adaptation from prior knowledge.
Figures






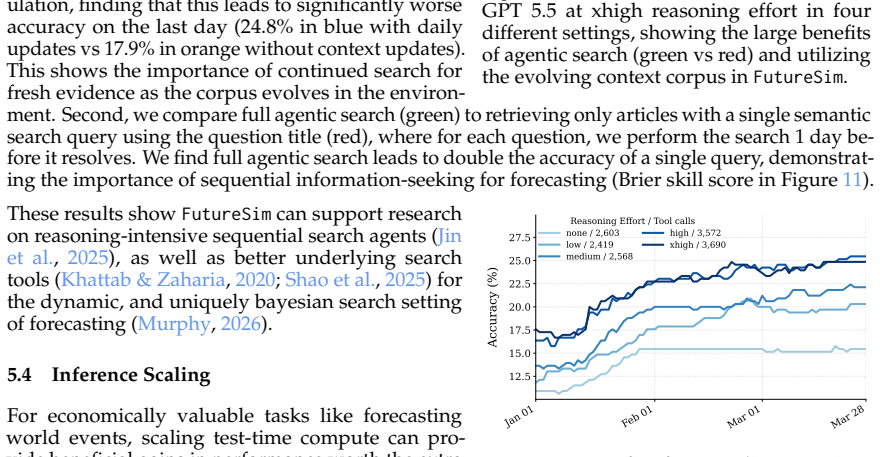

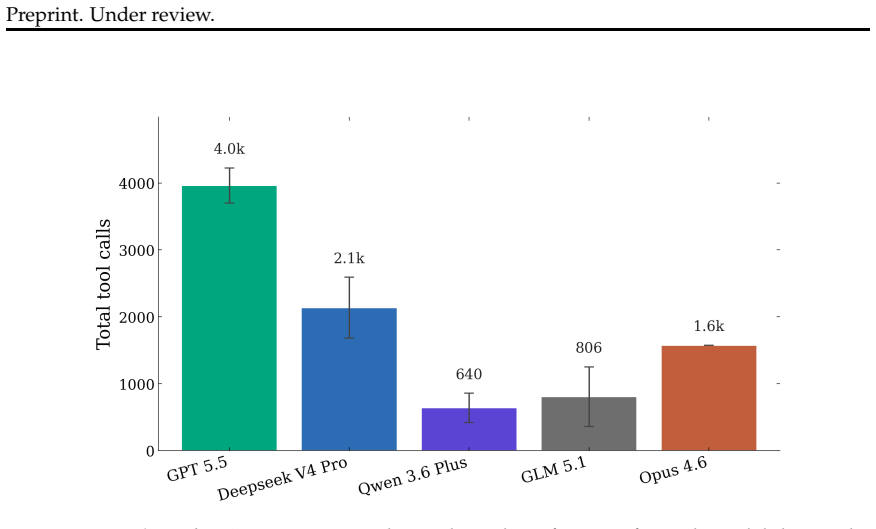




read the original abstract
AI agents are being increasingly deployed in dynamic, open-ended environments that require adapting to new information as it arrives. To efficiently measure this capability for realistic use-cases, we propose building grounded simulations that replay real-world events in the order they occurred. We build FutureSim, where agents forecast world events beyond their knowledge cutoff while interacting with a chronological replay of the world: real news articles arriving and questions resolving over the simulated period. We evaluate frontier agents in their native harness, testing their ability to predict world events over a three-month period from January to March 2026. FutureSim reveals a clear separation in their capabilities, with the best agent's accuracy being 25%, and many having worse Brier skill score than making no prediction at all. Through careful ablations, we show how FutureSim offers a realistic setting to study emerging research directions like long-horizon test-time adaptation, search, memory, and reasoning about uncertainty. Overall, we hope our benchmark design paves the way to measure AI progress on open-ended adaptation spanning long time-horizons in the real world.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FutureSim, a benchmark that replays real historical news articles in chronological order to evaluate frontier AI agents' ability to adapt and forecast world events over a three-month period (January–March 2026) beyond their training cutoffs. It reports a best-agent accuracy of 25% with several agents showing Brier skill scores worse than a no-prediction baseline, and presents ablations on long-horizon adaptation, search, memory, and uncertainty reasoning.
Significance. If the evaluation design successfully isolates test-time adaptation from pre-trained knowledge, FutureSim would offer a grounded, reproducible way to measure open-ended real-world forecasting capabilities over long horizons, filling a gap left by static benchmarks or synthetic environments. The chronological replay approach and use of native agent harnesses are strengths that could support falsifiable claims about adaptation.
major comments (2)
- [Abstract / Evaluation] Abstract and evaluation section: the headline claim of capability separation (25% accuracy, Brier scores worse than null) assumes performance derives from adaptation to the replay stream rather than pre-trained knowledge of 2026 events. No control is reported in which the replay is replaced by a static prompt or empty context; without this, the observed differences could reflect training-corpus overlap instead of adaptive behavior.
- [Abstract] Abstract: concrete numerical results (25% accuracy, Brier skill comparisons) are presented without accompanying methodological details on event selection criteria, question resolution process, statistical significance testing, or how agent predictions are elicited and scored. These omissions make the support for the central claims unverifiable.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of our evaluation design and presentation. We have revised the manuscript to strengthen the claims regarding adaptation versus pre-trained knowledge and to provide fuller methodological details. Below we respond point by point.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation section: the headline claim of capability separation (25% accuracy, Brier scores worse than null) assumes performance derives from adaptation to the replay stream rather than pre-trained knowledge. No control is reported in which the replay is replaced by a static prompt or empty context; without this, the observed differences could reflect training-corpus overlap instead of adaptive behavior.
Authors: We agree that an explicit control isolating the contribution of the chronological replay is necessary to support claims of test-time adaptation. In the revised manuscript we have added this control: agents receive the same initial setup and questions but with an empty or static context instead of the live news replay stream. Results show a substantial drop in both accuracy and Brier skill score under the no-replay condition, consistent with the interpretation that observed performance reflects adaptation to incoming information rather than leakage from pre-training data. We have updated the abstract, evaluation section, and added a new subsection describing the control. revision: yes
-
Referee: [Abstract] Abstract: concrete numerical results (25% accuracy, Brier skill comparisons) are presented without accompanying methodological details on event selection criteria, question resolution process, statistical significance testing, or how agent predictions are elicited and scored. These omissions make the support for the central claims unverifiable.
Authors: We accept that the original abstract was too terse on methodology. The revised version now includes a concise methods paragraph summarizing: (i) event selection (real-world news items with verifiable post-hoc outcomes drawn from public sources), (ii) question resolution (binary or probabilistic outcomes determined by official records after the simulated period ends), (iii) statistical testing (bootstrap confidence intervals and paired significance tests reported in the main text), and (iv) prediction elicitation and scoring (standardized prompts within each agent's native harness, evaluated via Brier score and accuracy). A new dedicated Methods section expands on these points with full procedural details. revision: yes
Circularity Check
No significant circularity in benchmark construction or reported results
full rationale
The paper defines FutureSim as an external simulation that replays verifiable real-world news articles and event resolutions in chronological order from January to March 2026. The headline empirical claims (best-agent accuracy of 25%, multiple agents below null Brier skill) are obtained by executing frontier models in their native harnesses and computing standard metrics on the resulting forecasts. No equations, parameter fits, or self-citations are used to derive these numbers; the separation is an observed outcome of the external evaluation. Ablations on adaptation, search, memory, and uncertainty are described as diagnostic tools rather than load-bearing premises that reduce to the paper's own inputs. The derivation chain therefore remains self-contained against independent real-world events and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Trapit Bansal, Jakub Pachocki, Szymon Sidor, Ilya Sutskever, and Igor Mordatch
URLhttps://arxiv.org/abs/2502.15840. Trapit Bansal, Jakub Pachocki, Szymon Sidor, Ilya Sutskever, and Igor Mordatch. Emergent com- plexity via multi-agent competition. InInternational Conference on Learning Representations, 2018. URLhttps://openreview.net/forum?id=Sy0GnUxCb. Noam Brown, Anton Bakhtin, Emily Dinan, Gabriele Farina, Colin Flaherty, Daniel F...
-
[2]
URLhttps://proceedings.mlr.press/v119/perdomo20a.html. Preethi Seshadri, Samuel Cahyawijaya, Ayomide Odumakinde, Sameer Singh, and Seraphina Goldfarb-Tarrant. Lost in simulation: Llm-simulated users are unreliable proxies for human users in agentic evaluations, 2026. URLhttps://arxiv.org/abs/2601.17087. Rulin Shao, Rui Qiao, Varsha Kishore, Niklas Muennig...
-
[3]
just give the model shell and tool access
We provide the prompt in Appendix E.4. • We remove questions that models can answer confidently using search capped to June 2025, as they are too stale or easy. We also remove questions that models still fail to answer even with full web search access as of April 2026, as this might be due to label noise. This approach makes our evaluation quite distinct ...
work page 2025
-
[4]
Context consumption feedback:After each tool call, the agent receives feedback about remaining context budget and approximate context occupancy. This is useful because the task spans thousands of turns, and without explicit budget awareness, agents often spend a lot of context browsing or performing repeated file reads, leaving too little room for final r...
-
[5]
Structured memory tools:Instead of asking the agent to maintain free-form notes arbitrarily in its workspace, we expose external memory through explicit tool calls with named entries and bounded fields. The goal is to make memory writing and retrieval deliberate actions rather than accidental byproducts of shell usage. This structure also makes it easier ...
-
[6]
Per-question memory:In addition to global notes, the harness maintains memory entries attached to individual questions. This is motivated by the fact that forecasting requires a mix of cross-question lessons and question-specific evidence: a general lesson about overconfidence should be stored differently from a candidate list or event-specific rationale ...
-
[7]
Forced memory phase:When the agent ends a day, or when the context budget becomes too tight, the harness enters an explicit memory-update phase before actually advancing. During this phase, the agent is encouraged to compress what it learned into persistent notes and leave a cleaner state for the next day. The motivation is to prevent a common failure 18 ...
-
[8]
Procedural forecasting scaffolding:The prompt encourages a concrete workflow: inspect the active questions, prioritize the ones most worth updating, search for relevant evidence, submit forecasts, update memory, and only then proceed to the next day. This scaffolding is intentionally lightweight: it does not tell the model what the answer is, but it does ...
work page 2025
-
[14]
No Placeholders: "Unknown", "TBD", and "Other" hurt your score. ## AVAILABLE DATA You have access to a news article database, which is updated daily through a search tool, that you can use to find evidence for your forecasts.,→ You can access the market.csv file (READ-ONLY) in your workspace containing <num_questions> questions (<num_active> active/unreso...
-
[15]
Questions resolving the next day (filter`market.csv`by`resolution_date`== tomorrow) -- make sure your prediction is up-to-date before calling next_day.,→
-
[16]
Questions without predictions (if any)
-
[17]
Questions where today's news search reveals new information
-
[18]
Questions approaching resolution date that you haven't checked recently
-
[19]
Skip questions where there is no new evidence ## YOUR MEMORY Current meta-insights with their indices: <meta_insight_index> `mem_df`holds your per-question notes (reasoning, evidence, calibration) -- 1 row per question. Columns: qid (str), question (str), last_updated (str), memory (str), category (str) <prior_memory_location_or_empty_memory_note> Inspect...
-
[20]
Accuracy + Calibration: assign calibrated probabilities that reflect true likelihoods
-
[21]
Time-Weighted Score: forecasts made earlier matter, but updating is rewarded when new evidence arrives
-
[22]
Prediction-Count Incentive: unanswered active questions receive zero contribution
-
[23]
End-of-Session Metrics are shown after each session
-
[24]
Max Outcomes: submit at most <max_outcomes_per_question> outcomes per question
-
[25]
No Placeholders: "Unknown", "TBD", and "Other" hurt your score. ## AVAILABLE DATA You have access to a news article database which is updated daily through a search tool, that you can use to find evidence for your forecasts.,→ You also have access to a read-only`market.csv`file in your workspace with <num_questions> questions (<num_active> active/unresolv...
-
[26]
Update`mem_df`for questions you researched or forecasted today using`mcp__forecast__mem_add`/ `mcp__forecast__mem_update`.,→
-
[27]
If today's work revealed a reusable pattern, lesson, or calibration rule, promote it into a meta-insight
-
[28]
If a prior meta-insight is stale or contradicted, revise or delete it. Do not use meta-insights as a daily activity log. If you learned nothing reusable today, it is fine to skip meta-insight writes.,→ ## SUBMISSION RULES - qid must be from an active (`is_resolved=False`) question you identified from market.csv. - Each`mcp__forecast__submit_forecasts`call...
-
[29]
<existing_prediction_1>
-
[30]
<existing_prediction_2> ... N. <existing_prediction_N> Does the new prediction match any of the existing predictions semantically? - Match if they mean the same thing or if new prediction is more specific - Do NOT match if new prediction is vaguer/more general If yes, respond with ONLY the number (e.g., "1" or "3"). If no match exists, respond with "None"...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.