DrugSAGE:Self-evolving Agent Experience for Efficient State-of-the-Art Drug Discovery
Pith reviewed 2026-05-19 15:21 UTC · model grok-4.3
pith:NBARWHG3 Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{NBARWHG3}
Prints a linked pith:NBARWHG3 badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
A self-evolving agent reuses cross-task memory to reach state-of-the-art drug discovery models with little or no new search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
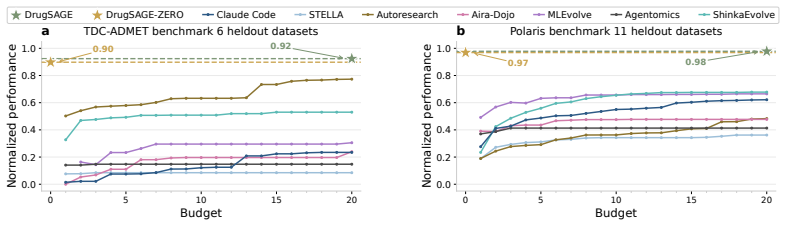
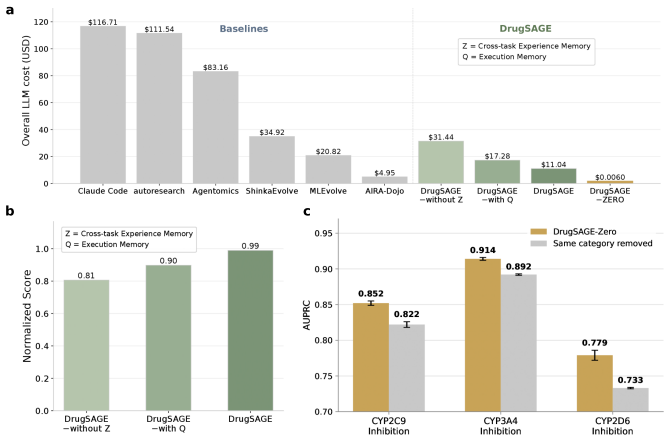
DrugSAGE maintains a cross-task memory of verified skills, statistical evidence about effective strategies, and records of recurring errors with their fixes. The agent draws on this memory to transfer working solutions to new molecular property prediction tasks, sometimes without any test-time search. In evaluations on 33 tasks it ranks first among nine compared agents in the single-task regime; after memory is built from 16 smaller tasks it reaches an averaged normalized score of 0.935 on 17 held-out tasks and exceeds baseline agents by 10-30 percent under a zero-test-time search condition.
What carries the argument
Cross-task memory storing verified skills, statistical evidence on strategies, and error-fix records that enables direct transfer or reduced search on new molecular property tasks.
If this is right
- Single-task performance on molecular property prediction reaches the top rank among nine state-of-the-art agents.
- Memory accumulated from 16 prior tasks supports an averaged normalized score of 0.935 on 17 unseen tasks.
- Zero-test-time search yields 10-30 percent gains over baseline agents on held-out tasks.
- Working solutions can be applied directly to new tasks when the memory already contains a matching skill or strategy.
Where Pith is reading between the lines
- The same memory structure could be tested on other scientific modeling domains that involve repeated architecture and strategy search, such as materials property prediction.
- Long-term growth of the memory might reduce the need for human oversight in deciding which past records to retain or compress.
- If transfer succeeds across many tasks, the framework could support incremental improvement of a single agent system rather than repeated independent searches.
Load-bearing premise
Experience gathered on one collection of molecular property tasks can be transferred to new tasks without introducing harmful biases from differences in task distributions.
What would settle it
On a fresh collection of held-out molecular tasks drawn from markedly different distributions, the agent equipped with prior memory would perform no better than or worse than agents lacking that memory.
Figures




read the original abstract
Building state-of-the-art (SOTA) predictive models for drug discovery requires expensive search over tools, architectures, and training strategies. Current LLM-based agents can find SOTA solutions through extensive trial and error, but they do not retain the experience accumulated along the way and therefore pay the full search cost on every new task. We propose \method (Self-evolving Agent Experience), a framework that accumulates and reuses experience across tasks to build SOTA drug discovery models efficiently. \method maintains a cross-task memory of verified skills, statistical evidence about effective strategies, and a record of recurring errors and their fixes. In some cases, \method transfers a working solution directly without test-time search. In 33 molecular property prediction tasks, \method ranks first among nine SOTA agents in a single-task setting. With memory accumulated from 16 smaller tasks, \method achieves an averaged normalized score of 0.935 on 17 held-out tasks in a cross-task evaluation setting and outperforms all baseline agents by 10-30\% in a zero-test-time search regime. In summary, our work shows the advantage of cross-task memory for efficient SOTA model development in drug discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DrugSAGE, a self-evolving LLM agent framework for drug discovery that maintains a cross-task memory of verified skills, statistical evidence on strategies, and records of errors/fixes. It claims that in single-task settings across 33 molecular property prediction tasks, DrugSAGE ranks first among nine SOTA agents; with memory accumulated from 16 smaller tasks, it reaches an averaged normalized score of 0.935 on 17 held-out tasks and outperforms baselines by 10-30% in a zero-test-time search regime.
Significance. If the cross-task transfer results hold under distribution shift, the work could meaningfully reduce repeated search costs for SOTA model development in molecular property prediction by enabling reuse of accumulated experience. The scale of the evaluation (50 tasks total) and the zero-search regime are concrete strengths that would support broader adoption of experience-reuse mechanisms in LLM agents for scientific domains.
major comments (2)
- [Abstract / cross-task evaluation] Abstract and cross-task evaluation section: The headline result of 0.935 normalized score and 10-30% gains in the zero-test-time regime rests on the assumption that memory from the 16 smaller tasks transfers effectively to the 17 held-out tasks. The manuscript provides no quantitative measure of task diversity (e.g., molecular scaffold overlap, property range statistics, or dataset source analysis) or ablation that isolates the memory components, leaving open whether gains reflect true self-evolution or partial distributional overlap.
- [Experiments] Experimental results: The reported first-place ranking among nine agents on 33 tasks and the percentage improvements require explicit details on baseline re-implementations, data splits, and statistical tests (e.g., standard errors or p-values across runs). Without these, the central performance claims cannot be fully verified as robust.
minor comments (2)
- [Methods] The description of memory components (verified skills, strategy statistics, error-fix records) would benefit from a clearer tabular summary or pseudocode in the methods to improve reproducibility.
- [Figures] Figure captions for task performance plots should explicitly state the normalization procedure used for the averaged score.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the potential of cross-task experience reuse to reduce repeated search costs in LLM-based drug discovery. We address each major comment below with clarifications and commitments to strengthen the manuscript where needed.
read point-by-point responses
-
Referee: [Abstract / cross-task evaluation] Abstract and cross-task evaluation section: The headline result of 0.935 normalized score and 10-30% gains in the zero-test-time regime rests on the assumption that memory from the 16 smaller tasks transfers effectively to the 17 held-out tasks. The manuscript provides no quantitative measure of task diversity (e.g., molecular scaffold overlap, property range statistics, or dataset source analysis) or ablation that isolates the memory components, leaving open whether gains reflect true self-evolution or partial distributional overlap.
Authors: We agree that explicit quantification of task diversity and component-wise ablations would further substantiate the cross-task results. In the revised manuscript we will add: (i) quantitative diversity metrics including average Tanimoto similarity of Bemis-Murcko scaffolds across the 16+17 tasks, summary statistics on property value ranges, and dataset provenance analysis; (ii) ablation experiments that successively remove each memory component (verified skills, statistical evidence, error/fix records) and measure the resulting drop in zero-test-time performance on the held-out tasks. These additions will clarify the degree of distributional overlap and isolate the contribution of self-evolution. revision: yes
-
Referee: [Experiments] Experimental results: The reported first-place ranking among nine agents on 33 tasks and the percentage improvements require explicit details on baseline re-implementations, data splits, and statistical tests (e.g., standard errors or p-values across runs). Without these, the central performance claims cannot be fully verified as robust.
Authors: We acknowledge that additional implementation and statistical details are required for full reproducibility and verification. In the revision we will expand the experimental section to include: complete descriptions of how each of the nine baseline agents was re-implemented (including any code adaptations or hyper-parameter choices); precise train/validation/test splits for every task; and statistical robustness measures such as standard errors over at least five independent runs together with p-values from paired statistical tests (e.g., Wilcoxon signed-rank) comparing DrugSAGE against each baseline. These details will allow independent verification of the reported rankings and gains. revision: yes
Circularity Check
No circularity; empirical results on held-out tasks are independent of inputs
full rationale
The paper describes an empirical agent framework that accumulates cross-task memory of skills and strategies, then measures performance directly on 33 single-task and 17 held-out molecular property prediction benchmarks. No equations, derivations, or first-principles claims appear in the provided text; the headline normalized score of 0.935 and 10-30% gains are reported as experimental outcomes rather than quantities that reduce to fitted parameters or self-referential definitions by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to force the result. The evaluation on held-out tasks supplies external falsifiability, rendering the work self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.lean, Cost/FunctionalEquation.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DRUGSAGE maintains a cross-task memory of verified skills, statistical evidence about effective strategies, and a record of recurring errors and their fixes... experience-conditioned MCTS... zero-test-time routing
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jiaqi Wei, Yuejin Yang, Xiang Zhang, Yuhan Chen, Xiang Zhuang, Zhangyang Gao, Dongzhan Zhou, Guangshuai Wang, Zhiqiang Gao, Juntai Cao, et al. From ai for science to agentic science: A survey on autonomous scientific discovery.arXiv preprint arXiv:2508.14111, 2025
-
[2]
Biomni: A general-purpose biomedical ai agent
Kexin Huang, Serena Zhang, Hanchen Wang, Yuanhao Qu, Yingzhou Lu, Yusuf Roohani, Ryan Li, Lin Qiu, Gavin Li, Junze Zhang, et al. Biomni: A general-purpose biomedical ai agent. biorxiv, 2025
work page 2025
-
[3]
Stella: Self-evolving llm agent for biomedical research.arXiv preprint arXiv:2507.02004, 2025
Ruofan Jin, Zaixi Zhang, Mengdi Wang, and Le Cong. Stella: Self-evolving llm agent for biomedical research.arXiv preprint arXiv:2507.02004, 2025
-
[4]
Andrej Karpathy. autoresearch: Ai agents running research on single-gpu nanochat training automatically.https://github.com/karpathy/autoresearch, 2026
work page 2026
-
[5]
Tune: A Research Platform for Distributed Model Selection and Training
Richard Liaw, Eric Liang, Robert Nishihara, Philipp Moritz, Joseph E Gonzalez, and Ion Stoica. Tune: A research platform for distributed model selection and training.arXiv preprint arXiv:1807.05118, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Guangji Bai, Zheng Chai, Chen Ling, Shiyu Wang, Jiaying Lu, Nan Zhang, Tingwei Shi, Ziyang Yu, Mengdan Zhu, Yifei Zhang, et al. Beyond efficiency: A systematic survey of resource-efficient large language models.arXiv preprint arXiv:2401.00625, 2024
-
[7]
Kexin Huang, Tianfan Fu, Wenhao Gao, Yue Zhao, Yusuf Roohani, Jure Leskovec, Connor W Coley, Cao Xiao, Jimeng Sun, and Marinka Zitnik. Therapeutics data commons: Machine learning datasets and tasks for drug discovery and development.Advances in Neural Information Processing Systems, 2021
work page 2021
-
[8]
Polaris hub.https://github.com/polaris-hub/polaris, 2025
Polaris. Polaris hub.https://github.com/polaris-hub/polaris, 2025
work page 2025
-
[9]
Ds-agent: Automated data science by empowering large language models with case-based reasoning
Siyuan Guo, Cheng Deng, Ying Wen, Hechang Chen, Yi Chang, and Jun Wang. Ds-agent: Automated data science by empowering large language models with case-based reasoning. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[10]
Mle-star: Machine learning engineering agent via search and targeted refinement
Jaehyun Nam, Jinsung Yoon, Jiefeng Chen, Jinwoo Shin, Sercan O Arik, and Tomas Pfister. Mle-star: Machine learning engineering agent via search and targeted refinement. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[11]
AIDE: AI-Driven Exploration in the Space of Code
Zhengyao Jiang, Dominik Schmidt, Dhruv Srikanth, Dixing Xu, Ian Kaplan, Deniss Ja- cenko, and Yuxiang Wu. Aide: Ai-driven exploration in the space of code.arXiv preprint arXiv:2502.13138, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Ai research agents for machine learning: Search, exploration, and generalization in mle-bench
Edan Toledo, Karen Hambardzumyan, Martin Josifoski, RISHI HAZRA, Nicolas Baldwin, Alexis Audran-Reiss, Michael Kuchnik, Despoina Magka, Minqi Jiang, Alisia Maria Lupidi, et al. Ai research agents for machine learning: Search, exploration, and generalization in mle-bench. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[13]
Xu Yang, Xiao Yang, Shikai Fang, Bowen Xian, Yuante Li, Jian Wang, Minrui Xu, Haoran Pan, Xinpeng Hong, Weiqing Liu, et al. R&d-agent: Automating data-driven ai solution building through llm-powered automated research, development, and evolution.arXiv e-prints, pages arXiv–2505, 2025
work page 2025
-
[14]
The FM Agent, February 2026.https://arxiv.org/abs/2510.26144
Annan Li, Chufan Wu, Zengle Ge, Yee Hin Chong, Zhinan Hou, Lizhe Cao, Cheng Ju, Jianmin Wu, Huaiming Li, Haobo Zhang, et al. The fm agent.arXiv preprint arXiv:2510.26144, 2025. 10
-
[15]
Jiefeng Chen, Bhavana Dalvi Mishra, Jaehyun Nam, Rui Meng, Tomas Pfister, and Jinsung Yoon. Mars: Modular agent with reflective search for automated ai research.arXiv preprint arXiv:2602.02660, 2026
-
[16]
Shiyang Feng, Runmin Ma, Xiangchao Yan, Yue Fan, Yusong Hu, Songtao Huang, Shuaiyu Zhang, Zongsheng Cao, Tianshuo Peng, Jiakang Yuan, Zijie Guo, Zhijie Zhong, Shangheng Du, Weida Wang, Jinxin Shi, Yuhao Zhou, Xiaohan He, Zhiyin Yu, Fangchen Yu, Bihao Zhan, Qihao Zheng, Jiamin Wu, Mianxin Liu, Chi Zhang, Shaowei Hou, Shuya Li, Yankai Jiang, Wenjie Lou, Lil...
-
[17]
Alireza Nadafian, Alireza Mohammadshahi, and Majid Yazdani. Kapso: A knowledge- grounded framework for autonomous program synthesis and optimization.arXiv preprint arXiv:2601.21526, 2026
-
[18]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
work page 2023
-
[19]
Expel: Llm agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: Llm agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19632–19642, 2024
work page 2024
-
[20]
Minghao Chen, Yihang Li, Yanting Yang, Shiyu Yu, Binbin Lin, and Xiaofei He. Automanual: Constructing instruction manuals by llm agents via interactive environmental learning.Advances in Neural Information Processing Systems, 37:589–631, 2024
work page 2024
-
[21]
Dynamic cheatsheet: Test-time learning with adaptive memory
Mirac Suzgun, Mert Yuksekgonul, Federico Bianchi, Dan Jurafsky, and James Zou. Dynamic cheatsheet: Test-time learning with adaptive memory. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7080–7106, 2026
work page 2026
-
[22]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https: //openreview.net/forum?id=ehfRiF0R3a
work page 2024
-
[23]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=NTAhi2JEEE
work page 2025
-
[24]
Memp: Exploring Agent Procedural Memory
Runnan Fang, Yuan Liang, Xiaobin Wang, Jialong Wu, Shuofei Qiao, Pengjun Xie, Fei Huang, Huajun Chen, and Ningyu Zhang. Memp: Exploring agent procedural memory.arXiv preprint arXiv:2508.06433, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
CORAL: Towards Autonomous Multi-Agent Evolution for Open-Ended Discovery
Ao Qu, Han Zheng, Zijian Zhou, Yihao Yan, Yihong Tang, Shao Yong Ong, Fenglu Hong, Kaichen Zhou, Chonghe Jiang, Minwei Kong, et al. Coral: Towards autonomous multi-agent evolution for open-ended discovery.arXiv preprint arXiv:2604.01658, 2026
work page internal anchor Pith review arXiv 2026
-
[26]
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Boyuan Zheng, Michael Y Fatemi, Xiaolong Jin, Zora Zhiruo Wang, Apurva Gandhi, Yueqi Song, Yu Gu, Jayanth Srinivasa, Gaowen Liu, Graham Neubig, et al. Skillweaver: Web agents can self-improve by discovering and honing skills.arXiv preprint arXiv:2504.07079, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Xiangru Tang, Tianrui Qin, Tianhao Peng, Ziyang Zhou, Daniel Shao, Tingting Du, Xinming Wei, Peng Xia, Fang Wu, He Zhu, et al. Agent kb: Leveraging cross-domain experience for agentic problem solving.arXiv preprint arXiv:2507.06229, 2025
-
[28]
Yunzhong Xiao, Yangmin Li, Hewei Wang, Yunlong Tang, and Zora Zhiruo Wang. Toolmem: Enhancing multimodal agents with learnable tool capability memory.arXiv preprint arXiv:2510.06664, 2025. 11
-
[29]
Mathematical discoveries from program search with large language models
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models. Nature, 625(7995):468–475, 2024
work page 2024
-
[30]
Efficient evolutionary search over chemical space with large language models
Haorui Wang, Marta Skreta, Cher Tian Ser, Wenhao Gao, Lingkai Kong, Felix Strieth-Kalthoff, Chenru Duan, Yuchen Zhuang, Yue Yu, Yanqiao Zhu, et al. Efficient evolutionary search over chemical space with large language models. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[31]
Llm-sr: Scientific equation discovery via programming with large language models
Parshin Shojaee, Kazem Meidani, Shashank Gupta, Amir Barati Farimani, and Chandan K Reddy. Llm-sr: Scientific equation discovery via programming with large language models. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[32]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Autonomous chemical research with large language models.Nature, 624(7992):570–578, 2023
Daniil A Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models.Nature, 624(7992):570–578, 2023
work page 2023
-
[34]
Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D White, and Philippe Schwaller
Andres M. Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D White, and Philippe Schwaller. Augmenting large language models with chemistry tools.Nature machine intelli- gence, 6(5):525–535, 2024
work page 2024
-
[35]
Yuanqi Du, Botao Yu, Tianyu Liu, Tony Shen, Junwu Chen, Jan G Rittig, Kunyang Sun, Yikun Zhang, Zhangde Song, Bo Zhou, et al. Accelerating scientific discovery with autonomous goal-evolving agents.arXiv preprint arXiv:2512.21782, 2025
-
[36]
Vlastimil Martinek, Andrea Gariboldi, Dimosthenis Tzimotoudis, Mark Galea, Elissavet Zacharopoulou, Aitor Alberdi Escudero, Edward Blake, David ˇCechák, Luke Cassar, Alessan- dro Balestrucci, et al. Agentomics: An agentic system that autonomously develops novel state-of-the-art solutions for biomedical machine learning tasks.bioRxiv, pages 2026–01, 2026
work page 2026
-
[37]
ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution
Robert Tjarko Lange, Yuki Imajuku, and Edoardo Cetin. Shinkaevolve: Towards open-ended and sample-efficient program evolution.arXiv preprint arXiv:2509.19349, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Anthropic. Claude code documentation. https://code.claude.com/docs/en/overview,
-
[39]
Accessed: 2026-05-06
work page 2026
-
[40]
Jeremy R Ash, Cas Wognum, Raquel Rodríguez-Pérez, Matteo Aldeghi, Alan C Cheng, Djork- Arné Clevert, Ola Engkvist, Cheng Fang, Daniel J Price, Jacqueline M Hughes-Oliver, et al. Practically significant method comparison protocols for machine learning in small molecule drug discovery.Journal of chemical information and modeling, 65(18):9398–9411, 2025
work page 2025
-
[41]
Cheng Fang, Ye Wang, Richard Grater, Sudarshan Kapadnis, Cheryl Black, Patrick Trapa, and Simone Sciabola. Prospective validation of machine learning algorithms for absorption, distribution, metabolism, and excretion prediction: An industrial perspective.Journal of Chemical Information and Modeling, 63(11):3263–3274, 2023
work page 2023
-
[42]
Progress towards a public chemogenomic set for protein kinases and a call for contributions
David H Drewry, Carrow I Wells, David M Andrews, Richard Angell, Hassan Al-Ali, Alison D Axtman, Stephen J Capuzzi, Jonathan M Elkins, Peter Ettmayer, Mathias Frederiksen, et al. Progress towards a public chemogenomic set for protein kinases and a call for contributions. PloS one, 12(8):e0181585, 2017
work page 2017
-
[43]
Deep learning foundation models from classical molecular descriptors
William Green, Jackson Burns, Akshat Shirish Zalte, Charlles Abreu, Jochen Sieg, Christian Feldmann, and Miriam Mathea. Deep learning foundation models from classical molecular descriptors. 2026
work page 2026
-
[44]
Wassily Hoeffding. Probability inequalities for sums of bounded random variables.Journal of the American statistical association, 58(301):13–30, 1963. 12 Appendix for DrugSAGE A Benchmark Dataset Summary 15 B Dataset Partition 16 C Per-Baseline Protocols and Prompts 17 C.1 Autoresearch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ...
work page 1963
-
[45]
Check results.tsv for experiment history
-
[46]
Read train.py; plan one focused change
-
[47]
Run: python pipeline.py run-exp {DATASET}/{MODEL} --desc "..." --gpu 0
-
[48]
Strategy guide: Quick wins: tune LR, batch size, regularization
Keep if val metric improved; auto-revert otherwise. Strategy guide: Quick wins: tune LR, batch size, regularization. Medium effort: change model family, add CV. 17 High effort: ensemble methods, custom featurization. NEVER STOP -- continue autonomously until budget exhausted. C.2 ShinkaEvolve ShinkaEvolve [37] is an evolutionary algorithm optimization age...
-
[49]
Use prepare.py: load_data, load_seed_split, evaluate, save_predictions, save_summary, SEEDS
-
[50]
Iterate over ALL 5 seeds and train/evaluate each
-
[51]
Call save_predictions for each seed
-
[52]
Call save_summary() at the end
-
[53]
DATASET, METRIC, OUT variables are FIXED
-
[54]
Ensure all predictions are finite (no NaN/inf) STRATEGY: - Tune hyperparameters, feature engineering, architectures - Consider ensemble methods, stacking, or blending - Change ML library if beneficial - Classification: probabilities; Regression: continuous Mutation prompts are constructed by a PromptSampler: fordiffpatches (70% probability), the prompt ap...
-
[55]
Featurization, model, hyperparameters, training loop
**Create the task files for each task**: -`train.py`: the file you modify. Featurization, model, hyperparameters, training loop. -`prepare.py`(two levels up) : fixed data loading, evaluation, output
-
[56]
**Review experiment history**: Check`results.tsv`for what has already been tried. ## Constraints **What you CAN modify:** -`train.py`: everything is fair game: model hyperparameters, featurization, feature engineering, model architecture, ensemble strategies, preprocessing, training procedure. **What you CANNOT modify:** -`prepare.py`: read-only. Contains...
-
[57]
**Plan**: Look at experiment history in`results.tsv`, and make changes to`train.py`
-
[58]
Keep it focused one idea per experiment
**Modify`train.py`**: Make your change. Keep it focused one idea per experiment
-
[59]
**Snapshot**: The pipeline automatically saves a copy of`train.py`
-
[60]
**Run**: Run experiments
-
[61]
**Check results**: Read the output
-
[62]
**Record**: Log results
-
[63]
**Decide**: Take results or not
-
[64]
Develop a machine learning model that generalizes well to new unseen data
**Repeat** until budget exhausted. ## Output Format The`save_summary()`call writes`results/summary.json`with full details. ## NEVER STOP You need to save the best results and standard deviation in folder`./{task}_result/`. C.7 Agentomics Agentomics [36] is a multi-step ML agent that follows a fixed step sequence per iteration: iteration planning → data ex...
-
[65]
Proof.We follow the standard UCB analysis and carefully track the causal error termξ t(f)
lnT ∆f + 1 + π2 3 ∆f .(13) This is O(|F |lnT) , identical in asymptotic order to standard UCB; the causal factor only modifies the leading constant viaC 0. Proof.We follow the standard UCB analysis and carefully track the causal error termξ t(f). Step 1: High-probability bound on the optimal arm. By Hoeffding’s inequality [43], with probability at least1−...
-
[66]
lnT ∆2 f , where the last step uses (α+C 0/ p ln(t+ 1)) 2 ≤2(α 2 +C 2
-
[67]
Step 4: Expected number of pulls
by the AM–GM inequality, valid for allt≤T. Step 4: Expected number of pulls. Using the standard UCB analysis (tail-sum decomposition), E[NT (f)]≤ 8(α2 +C 2
-
[68]
lnT ∆2 f + 1 + π2 3 . Step 5: Cumulative regret. Summing over all suboptimal families: RT = X f: ∆f >0 ∆f ·E[N T (f)]≤ X f: ∆f >0 8(α2 +C 2
-
[69]
Key observation.The bound is O(lnT) , matching standard UCB
lnT ∆f + 1 + π2 3 ∆f . Key observation.The bound is O(lnT) , matching standard UCB. The causal factor contributes only throughC 0, which modifies the constant but not the asymptotic order. If we also consider the node-level regret bound, under the weighted sampler computation in 3, the bonus max(∆CEG(vi),0) now serves as a non-negative multiplicative dete...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.