Ghosted Layers: Unconstrained Activation Alignment for Recovering Layer-Pruned LLMs
Pith reviewed 2026-05-19 16:10 UTC · model grok-4.3
The pith
A closed-form linear operator derived from calibration data can reconstruct the hidden-state mismatch caused by removing entire layers from large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
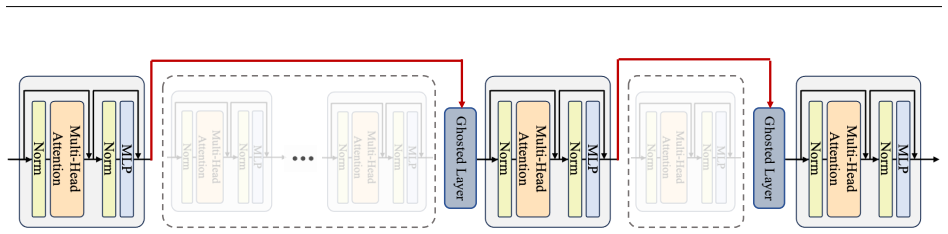
Layer pruning removes entire Transformer decoder blocks from large language models, but introduces a mismatch between the hidden state received by the next surviving layer and the distribution it was trained to process, leading to significant performance degradation. Ghosted Layers address this by solving a boundary activation alignment problem. The method derives a closed-form optimal linear operator from a small calibration set to reconstruct the activation discrepancy introduced by the pruned layers. This solution corresponds to the unconstrained optimum of the alignment objective, whereas existing methods are restricted to constrained solutions over limited operator subspaces.
What carries the argument
The closed-form optimal linear operator for boundary activation alignment, obtained by solving the least-squares problem on a calibration set to minimize the difference between pruned and original activations.
If this is right
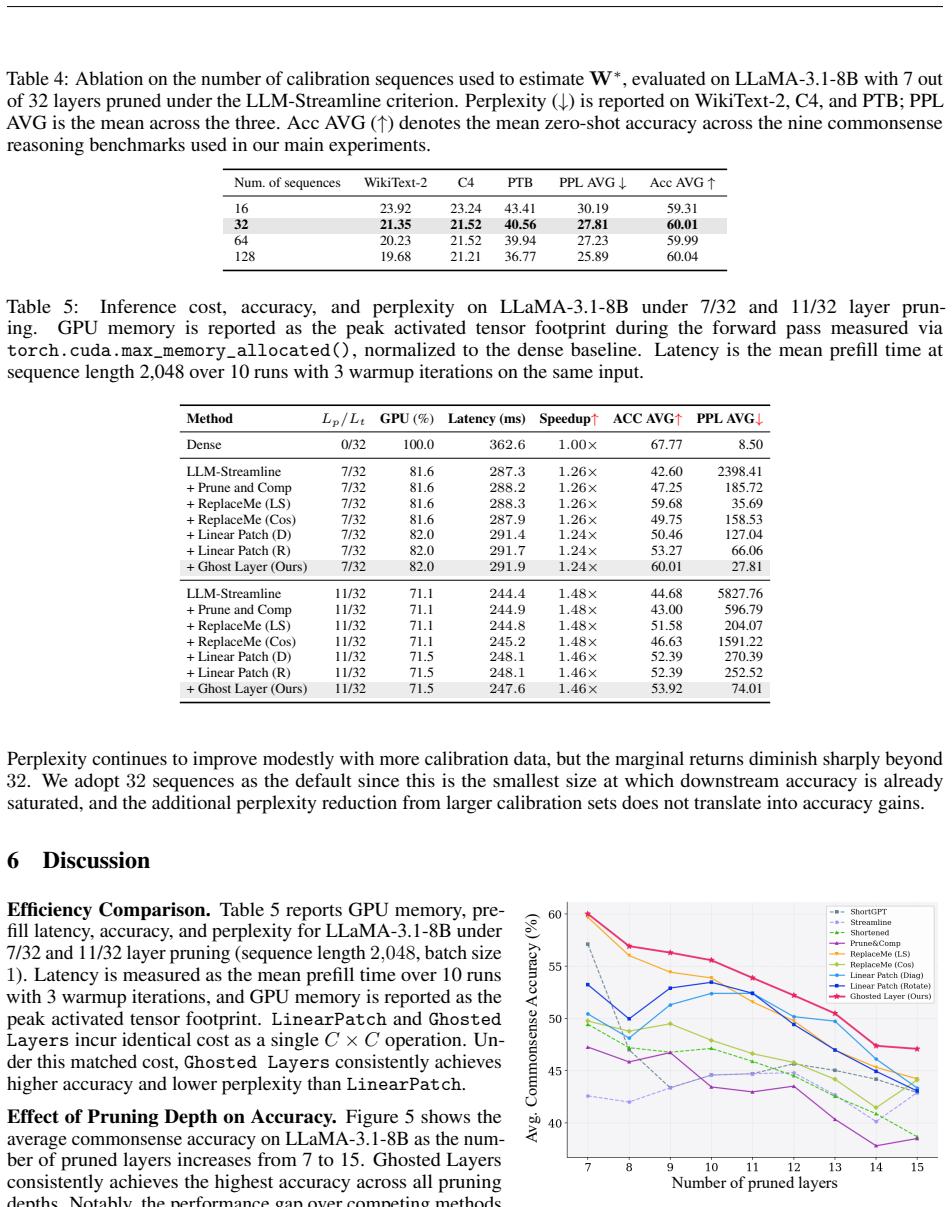
- The method yields higher accuracy and lower perplexity than prior training-free recovery techniques on multiple LLM families and pruning strategies.
- The efficiency gains from layer pruning, such as reduced inference latency and memory use, remain intact because the added operator is a single matrix multiplication.
- Because the solution is the true unconstrained optimum rather than an approximation inside a restricted subspace, further improvements would require changing the objective itself rather than searching harder within the same family.
- The approach is training-free and uses only a small calibration set, so it can be applied after any pruning decision without additional optimization.
Where Pith is reading between the lines
- If the discrepancy introduced by pruning turns out to be largely linear, similar closed-form operators might correct other compression artifacts such as those from low-rank adaptation or early-exit mechanisms.
- The calibration-set requirement suggests that periodically refitting the operator on recent user data could keep recovery quality high when the input distribution shifts over time.
- Because the operator is derived once and then fixed, it could be fused into the adjacent layers at deployment time to eliminate any extra runtime cost beyond the original pruning savings.
Load-bearing premise
The activation discrepancy caused by removed layers can be accurately captured and reversed by one linear transformation that was fitted on limited calibration examples and then works for every input the model will see later.
What would settle it
If the linear operator fitted on the calibration set produces no measurable reduction in activation mismatch or no gain in perplexity and accuracy when tested on a large, held-out set of diverse inputs, the claim that it provides the effective unconstrained recovery would be falsified.
Figures



read the original abstract
Layer pruning removes entire Transformer decoder blocks from large language models, but introduces a mismatch between the hidden state received by the next surviving layer and the distribution it was trained to process, leading to significant performance degradation. We propose Ghosted Layers, a training-free recovery module that addresses this issue by solving a boundary activation alignment problem. Our method derives a closed-form optimal linear operator from a small calibration set to reconstruct the activation discrepancy introduced by the pruned layers. We show that this solution corresponds to the unconstrained optimum of the alignment objective, whereas existing methods are restricted to constrained solutions over limited operator subspaces. Experiments across multiple LLM backbones and pruning strategies demonstrate that our method consistently improves accuracy and perplexity over prior training-free baselines, while preserving the efficiency gains of layer pruning. Official code repository: https://github.com/daniel-eai/ghosted_layers_official_repository/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that layer pruning in LLMs creates a boundary activation mismatch that can be recovered training-free by Ghosted Layers: a closed-form optimal linear operator fitted on a small calibration set to reconstruct the pruned-layer activation discrepancy. It asserts this operator is the unconstrained optimum of the alignment objective (unlike prior methods limited to constrained subspaces), and reports consistent accuracy and perplexity gains over baselines across multiple LLM backbones and pruning strategies.
Significance. If the linear operator generalizes beyond the calibration distribution and the closed-form derivation is independent of downstream task loss, the approach would offer a lightweight, training-free way to mitigate pruning-induced degradation while retaining the efficiency benefits of layer removal. The parameter-free character of the claimed optimum would be a notable strength for reproducibility.
major comments (3)
- [Abstract / boundary activation alignment problem] Abstract and boundary activation alignment paragraph: the claim that a single linear operator fitted on a small calibration set reconstructs the discrepancy and remains effective across the full inference distribution lacks any robustness argument or bound on distribution shift; subsequent nonlinear Transformer layers can alter the required mapping, and no explicit test of this assumption is supplied.
- [Abstract] Abstract: the statement that the solution 'corresponds to the unconstrained optimum' is presented without derivation details, equations, or a proof that the operator is independent of the downstream task loss; without these, it is unclear whether the closed-form reduces to an empirical fit on the calibration data rather than a true unconstrained optimum.
- [Experiments] Experiments section: no error bars, standard deviations, or details on calibration-set selection and size are provided, making it impossible to assess whether the reported consistent gains are statistically reliable or sensitive to the choice of calibration data.
minor comments (2)
- The manuscript should include a clear statement of the exact least-squares objective and the resulting closed-form expression for the linear operator (presumably W = Y X^+ or equivalent) so readers can verify the unconstrained claim.
- Figure and table captions would benefit from explicit mention of the calibration-set size and the pruning ratios tested to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback on our manuscript. We have addressed each major comment below and revised the paper accordingly to improve clarity, rigor, and reproducibility.
read point-by-point responses
-
Referee: [Abstract / boundary activation alignment problem] Abstract and boundary activation alignment paragraph: the claim that a single linear operator fitted on a small calibration set reconstructs the discrepancy and remains effective across the full inference distribution lacks any robustness argument or bound on distribution shift; subsequent nonlinear Transformer layers can alter the required mapping, and no explicit test of this assumption is supplied.
Authors: We agree that a formal robustness bound or theoretical analysis of distribution shift would strengthen the claims. The linear operator is derived to minimize the immediate boundary mismatch on the calibration set, and while subsequent nonlinear layers can in principle modify the effective mapping, the alignment is applied precisely at the interface to reduce propagation of the discrepancy. Our experiments already test generalization across multiple models, pruning ratios, and evaluation datasets that differ from the calibration distribution. In the revision we have added a dedicated paragraph in Section 3.2 discussing the modeling assumptions and limitations, and we include new experiments evaluating performance on out-of-distribution prompts to provide more explicit empirical support for the assumption. revision: partial
-
Referee: [Abstract] Abstract: the statement that the solution 'corresponds to the unconstrained optimum' is presented without derivation details, equations, or a proof that the operator is independent of the downstream task loss; without these, it is unclear whether the closed-form reduces to an empirical fit on the calibration data rather than a true unconstrained optimum.
Authors: We appreciate this observation. The full derivation appears in Section 3, where we formulate the alignment objective as an unconstrained least-squares problem over the linear operator and obtain the closed-form solution via the normal equations; this solution depends only on the observed activation pairs from the calibration set and contains no dependence on any downstream task loss. To address the referee's concern we have expanded the abstract to include a brief reference to the derivation and added a pointer to the relevant equations (Eqs. 3–6) so that readers can immediately locate the proof that the operator is the unconstrained optimum. revision: yes
-
Referee: [Experiments] Experiments section: no error bars, standard deviations, or details on calibration-set selection and size are provided, making it impossible to assess whether the reported consistent gains are statistically reliable or sensitive to the choice of calibration data.
Authors: We thank the referee for noting this gap in reporting. The revised Experiments section now reports mean performance together with standard deviations and error bars computed over five independent random seeds for every metric and model. We have also added a new paragraph detailing the calibration-set construction: for each experiment we randomly sample 256 sequences (each of length 512 tokens) from the training split of the respective dataset, with the random seed fixed for reproducibility; sensitivity to calibration-set size is additionally explored in an appendix table. revision: yes
Circularity Check
No significant circularity; derivation is a standard closed-form solution to an explicitly stated alignment objective
full rationale
The paper defines a boundary activation alignment objective and derives its unconstrained optimum as a closed-form linear operator fitted on calibration activations. This is a direct mathematical solution to the stated minimization problem rather than a reduction of the claimed result to its own inputs by construction. No self-citations are invoked as load-bearing premises, no uniqueness theorems are imported from prior author work, and no fitted parameter is relabeled as an independent prediction. The central claim remains that the derived operator is unconstrained (in contrast to prior constrained subspaces), which follows from the problem formulation itself without tautology. Generalization from calibration to inference is an empirical assumption but does not render the derivation chain circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The activation discrepancy at layer boundaries after pruning is reconstructible by a linear operator derived from a small calibration set.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.