Text-RSIR: A Text-Guided Framework for Efficient Remote Sensing Image Transmission and Reconstruction
Pith reviewed 2026-05-19 19:55 UTC · model grok-4.3
pith:SAV53V4Z Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{SAV53V4Z}
Prints a linked pith:SAV53V4Z badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
A text-guided system transmits remote sensing images at roughly 2% of original data volume while reconstructing them to PSNRs of 16-27 dB.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
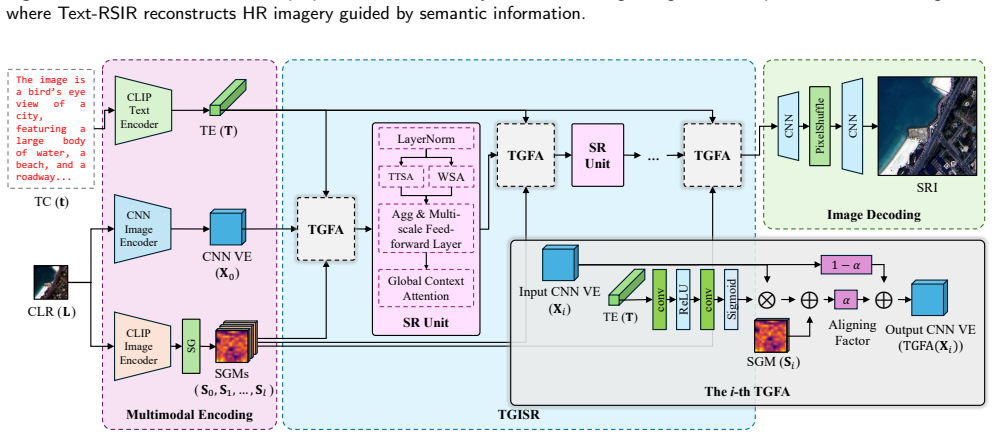
The central claim is that a text-guided remote sensing image transmission system replaces complete high-resolution data with low-resolution images accompanied by compact textual descriptions, reducing the transmitted data volume to approximately 2% of the original size, and achieves reconstruction PSNRs of 16.36 dB, 26.87 dB, and 27.41 dB on the Alsat-2B, UC Merced Land Use, and Aerial Image datasets through cross-modal learning in a text-conditioned image restoration model.
What carries the argument
The onboard text generator producing spatial and semantic summaries combined with the ground-based text-conditioned image restoration model that uses cross-modal learning to recover details from low-resolution inputs.
If this is right
- Transmission data volume drops to approximately 2% of the full high-resolution image size.
- Reconstruction achieves PSNRs of 16.36 dB on Alsat-2B, 26.87 dB on UC Merced Land Use, and 27.41 dB on Aerial Image datasets.
- The restored images maintain semantic coherence for tasks such as land cover analysis.
- The framework supports efficient image transfer for environmental monitoring and urban mapping under limited bandwidth.
Where Pith is reading between the lines
- The approach could be combined with adaptive coding to send only the text component during severe bandwidth drops.
- Extending the text generator to handle multi-spectral bands might preserve additional diagnostic information without increasing payload size.
- Deployment on actual satellite links would need to account for transmission errors in the text stream that could degrade restoration.
Load-bearing premise
Compact textual descriptions produced by an onboard generator contain enough spatial and semantic information for a restoration model to recover fine details and maintain coherence from low-resolution images.
What would settle it
Applying the full pipeline to a fourth remote sensing dataset and measuring whether average reconstruction PSNR falls below 15 dB or land-cover classification accuracy drops sharply compared with full-resolution transmission.
Figures






read the original abstract
High-resolution remote sensing imagery is critical for environmental monitoring, urban mapping, and land cover analysis, but its transmission is often hindered by limited bandwidth and high communication costs. Conventional pipelines transmit full-resolution pixel data, resulting in redundant and inefficient delivery. This paper proposes a text-guided remote sensing image transmission system that replaces complete high-resolution data with low-resolution images accompanied by compact textual descriptions. An onboard text generator produces spatial and semantic summaries, reducing the transmitted data volume to approximately 2\% of the original size. For ground-based reconstruction, a text-conditioned image restoration model is introduced, which leverages cross-modal learning to recover fine spatial details and maintain semantic coherence. Experimental results on the Alsat-2B, UC Merced Land Use, and Aerial Image datasets demonstrate that the proposed framework achieves reconstruction PSNRs of 16.36 dB, 26.87 dB, and 27.41 dB, respectively, enabling efficient and information-preserving image transfer for remote sensing applications. The implementation will be made publicly available at \href{https://github.com/haoyangofficial/textrssr}{GitHub}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Text-RSIR, a text-guided framework for remote sensing image transmission and reconstruction. It replaces full high-resolution pixel data with low-resolution images plus compact textual descriptions generated onboard (claimed to reduce transmitted volume to ~2% of original), then uses a ground-based text-conditioned restoration network leveraging cross-modal learning to recover details and semantic coherence. Experiments on Alsat-2B, UC Merced Land Use, and Aerial Image datasets report reconstruction PSNRs of 16.36 dB, 26.87 dB, and 27.41 dB.
Significance. If the central sufficiency assumption holds and reconstruction quality proves adequate for downstream remote-sensing tasks, the approach could enable substantial bandwidth reduction in bandwidth-constrained satellite or UAV scenarios. The public GitHub release of code would further strengthen reproducibility. However, the notably lower PSNR on Alsat-2B already signals that performance may be scene-dependent and insufficient for applications requiring fine spatial fidelity.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experimental Results): The reported PSNR of 16.36 dB on Alsat-2B is low enough to question whether compact textual descriptions plus low-resolution input can recover the fine-grained spatial structures (sub-pixel textures, small-object geometries) that dominate remote-sensing utility; no ablation isolating the text component versus low-resolution input alone is presented to support the sufficiency claim.
- [§3.1] §3.1 (Onboard Text Generator): The description of the text generator as producing 'spatial and semantic summaries' lacks any mechanism (e.g., dense patch-level captions, geometric tokens, or explicit spatial encoding) that would demonstrably bridge the modality gap between discrete text and continuous high-frequency image content; without such detail or quantitative validation, the 2% data-volume claim rests on an unverified assumption.
- [§4.3] §4.3 (Comparison and Baselines): No quantitative comparison to standard compression baselines (e.g., JPEG2000, learned codecs) or to a low-resolution-only reconstruction model is provided; this omission makes it impossible to isolate the incremental benefit of the text guidance and to assess whether the framework truly preserves information beyond what a low-resolution image alone could achieve.
minor comments (2)
- [Abstract] The abstract states that implementation will be made publicly available but provides no link or commit hash; this should be added for reproducibility.
- [Figures in §4] Figure captions and axis labels in the results section use inconsistent font sizes and lack error bars or standard-deviation shading, reducing clarity of the quantitative claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Results): The reported PSNR of 16.36 dB on Alsat-2B is low enough to question whether compact textual descriptions plus low-resolution input can recover the fine-grained spatial structures (sub-pixel textures, small-object geometries) that dominate remote-sensing utility; no ablation isolating the text component versus low-resolution input alone is presented to support the sufficiency claim.
Authors: We acknowledge that the PSNR of 16.36 dB on Alsat-2B is lower than on the other datasets and may indicate limitations in recovering fine spatial details for certain complex scenes. The framework prioritizes semantic preservation for downstream tasks such as land-use classification over pixel-perfect fidelity. To directly address the absence of an ablation study, we will add a new experiment in the revised §4 comparing the full text-conditioned model against a low-resolution-only baseline (e.g., bicubic upsampling followed by a standard restoration network). This will isolate the contribution of the text component. revision: yes
-
Referee: [§3.1] §3.1 (Onboard Text Generator): The description of the text generator as producing 'spatial and semantic summaries' lacks any mechanism (e.g., dense patch-level captions, geometric tokens, or explicit spatial encoding) that would demonstrably bridge the modality gap between discrete text and continuous high-frequency image content; without such detail or quantitative validation, the 2% data-volume claim rests on an unverified assumption.
Authors: The onboard text generator is based on a fine-tuned vision-language model that produces concise captions emphasizing object categories, approximate spatial layouts, and semantic attributes derived from remote-sensing-specific training data. While it does not employ dense patch-level captions, the generated text incorporates relational descriptors (e.g., 'building cluster in upper-left quadrant') to help bridge the modality gap. We will expand §3.1 with additional implementation details, example text outputs, and a quantitative breakdown of transmitted data sizes (low-resolution image plus text) to substantiate the ~2% claim. revision: yes
-
Referee: [§4.3] §4.3 (Comparison and Baselines): No quantitative comparison to standard compression baselines (e.g., JPEG2000, learned codecs) or to a low-resolution-only reconstruction model is provided; this omission makes it impossible to isolate the incremental benefit of the text guidance and to assess whether the framework truly preserves information beyond what a low-resolution image alone could achieve.
Authors: We agree that direct comparisons to established baselines are necessary to quantify the benefit of text guidance. In the revised manuscript we will augment §4.3 with results for JPEG2000 at comparable bit rates, a learned compression baseline, and a low-resolution-only reconstruction model. These additions will clarify the incremental value of the text-conditioned restoration network. revision: yes
Circularity Check
No significant circularity; framework claims rest on experimental validation rather than self-referential derivation
full rationale
The paper introduces a text-guided transmission and reconstruction pipeline for remote sensing images, replacing full-resolution data with low-resolution images plus compact textual summaries generated onboard. Reconstruction relies on a cross-modal restoration network whose performance is demonstrated via reported PSNR values on three public datasets (Alsat-2B, UC Merced, Aerial Image). No equations, uniqueness theorems, or fitted parameters are shown to reduce by construction to the inputs; the 2% data-volume claim and PSNR figures are presented as empirical outcomes rather than tautological predictions. Self-citations, if present, are not load-bearing for the central sufficiency assumption, which is instead tested through standard dataset experiments. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cross-modal learning can effectively combine textual and visual information for image reconstruction in remote sensing
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
text-guided remote sensing image transmission system that replaces complete high-resolution data with low-resolution images accompanied by compact textual descriptions... Text-RSIR, a text-conditioned reconstruction network that leverages CLIP image and text embeddings and semantic guidance maps
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
iterative text-guided feature aligning and refinement strategy with a dual-head design
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A. N. Netravali and B. G. Haskell , title =. Springer , year =
-
[2]
Z. Wang and A. Bovik and H. Sheikh and E. Simoncelli , title =. IEEE Transactions on Image Processing , volume =. 2004 , publisher =
work page 2004
-
[3]
D. Kingma and J. Ba , title =. International Conference on Learning Representations (ICLR) , year =
-
[4]
H. Zhao and O. Gallo and I. Frosio and J. Kautz , title =. IEEE Transactions on Computational Imaging , volume =
-
[5]
Achraf Djerida and Khelifa Djerriri and Moussa Sofiane Karoui and Mohammed El Amin larabi , archivePrefix =. A New Public. 2103.12547 , year =
-
[6]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
A. Paszke and S. Gross and F. Massa and A. Lerer and J. Bradbury and G. Chanan and T. Killeen and Z. Lin and N. Gimelshein and L. Antiga and A. Desmaison and A. Köpf and E. Yang and Z. DeVito and M. Raison and A. Tejani and S. Chilamkurthy and B. Steiner and L. Fang and J. Bai and S. Chintala , archivePrefix =. 1912.01703 , year =
work page internal anchor Pith review Pith/arXiv arXiv 1912
- [7]
-
[8]
Y. Xiao and Q. Yuan and K. Jiang and J. He and C. -W. Lin and L. Zhang , title =. IEEE Transactions on Image Processing , volume =
-
[9]
A. Vaswani and N. Shazeer and N. Parmar and J. Uszkoreit and L. Jones and A. Gomez and. Attention Is All You Need , booktitle =
-
[10]
S. Ravi and H. Larochelle , title =. International Conference on Learning Representations (ICLR) , year =
- [11]
-
[12]
A. Radford and J. W. Kim and C. Hallacy and A. Ramesh and G. Goh and S. Agarwal and G. Sastry and A. Askell and P. Mishkin and J. Clark and G. Krueger and I. Sutskever , title =
- [13]
-
[14]
Y. Xiao and Q. Yuan and K. Jiang and Y. Chen and Q. Zhang and C.-W. Lin , journal=. Frequency-Assisted Mamba for Remote Sensing Image Super-Resolution , year=
-
[15]
Y. Yang and S. Newsam , title =. ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM GIS) , year =
- [16]
-
[17]
IEEE Transactions on Geoscience and Remote Sensing , year=
Mitigating texture bias: A remote sensing super-resolution method focusing on high-frequency texture reconstruction , author=. IEEE Transactions on Geoscience and Remote Sensing , year=
-
[18]
IEEE Transactions on Geoscience and Remote Sensing , volume=
Two-Stage Spatial-Frequency Joint Learning for Large-Factor Remote Sensing Image Super-Resolution , author=. IEEE Transactions on Geoscience and Remote Sensing , volume=
-
[19]
R. Keys , title =. IEEE Transactions on Acoustics, Speech, and Signal Processing , volume =
-
[20]
Image Super-Resolution Using Deep Convolutional Networks
C. Dong and C. C. Loy and K. He and X. Tang , title =. 1501.00092 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
- [21]
-
[22]
C. Ledig and L. Theis and F. Huszar and J. Caballero and A. Cunningham and A. Acosta and A. Aitken and A. Tejani and J. Totz and Z. Wang and W. Shi , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
- [23]
- [24]
-
[25]
B. Kawar and M. Elad and S. Ermon and J. Song , title =. 2201.11793 , year =
- [26]
-
[27]
J. Yang and J. Wright and T. S. Huang and L. Yu , title =. IEEE Transactions on Image Processing , volume =. 2010 , publisher =
work page 2010
-
[28]
Y. Yuan and X. Meng and W. Sun and G. Yang and L. Wang and J. Peng and Y. Wang , title =. Remote Sensing , volume =
- [29]
-
[30]
K. V. Gandikota and P. Chandramouli , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[31]
U. Jain and A. Wilson and V. Gulshan , title =. Proceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS) , year =
-
[32]
A. Fuller and K. Millard and J. R. Green , title =. Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS) , year =
-
[33]
Z. A. Pierrat and others , title =. New Phytologist , year =
-
[34]
A. Y. A. Abdelmajeed and R. Juszczak , title =. Remote Sensing , volume =. 2024 , article =
work page 2024
- [35]
- [36]
-
[37]
J. Kong and Y. Ryu and S. Jeong and Z. Zhong and W. Choi and J. Kim and K. Lee and J. Lim and K. Jang and J. Chun and K.-M. Kim and R. Houborg , title =. ISPRS Journal of Photogrammetry and Remote Sensing , volume =. 2023 , pages =
work page 2023
- [38]
- [39]
-
[40]
R. Rombach and A. Blattmann and D. Lorenz and P. Esser and B. Ommer , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
- [41]
-
[42]
Olga Russakovsky and Jia Deng and Hao Su and Jonathan Krause and Sanjeev Satheesh and Sean Ma and Zhiheng Huang and Andrej Karpathy and Aditya Khosla and Michael Bernstein and Alexander C. Berg and F.-F. Li , Title =. 2015 , journal =
work page 2015
-
[43]
D. K. Mahanta and T. K. Bhoi and J. Komal and I. Samal and A. Mastinu , title =. Plant Stress , year =
-
[44]
Q. Huang and X. Lu and F. Chen and Q. Zhang and H. Zhang , title =. Remote Sensing , year =
- [45]
-
[46]
J. Rolla and A. Khuller and K. An and R. Emberson and E. Fielding and L. Schultz and K. Miner , title =. AGU Advances , year =
-
[47]
W. Zhang and Z. Tan and Q. Lv and J. Li and B. Zhu and Y. Liu , title =. Remote Sensing , year =
-
[48]
W. Zhang and X. Yang and Z. Yuan and Z. Chen and Y. Xu , title =. Remote Sensing , year =
-
[49]
Vision-Language Modeling Meets Remote Sensing: Models, Datasets and Perspectives , author=
-
[50]
When Large Vision-Language Model Meets Large Remote Sensing Imagery: Coarse-to-Fine Text-Guided Token Pruning , author=
-
[51]
Referring Remote Sensing Image Segmentation via Bidirectional Alignment Guided Joint Prediction , author=
- [52]
- [53]
- [54]
-
[55]
F. Rong and M. Lan and Q. Zhang and L. Zhang , archivePrefix=. 2503.07266 , year=
-
[56]
Y. Wang and W. Yu and P. Ghamisi , archivePrefix=. Change Captioning in Remote Sensing: Evolution to. 2501.08114 , year=
-
[57]
MsEdF: A Multi-stream Encoder-decoder Framework for Remote Sensing Image Captioning
S. Das and R. Sharma , archivePrefix=. 2502.09282 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [58]
-
[59]
H. Yang and Z. Jiang and D. Ma and Q. Wang , year =. Multimodal Difference Augmentation Learning for Remote Sensing Change Detection , journal =
- [60]
- [61]
- [62]
-
[63]
International Conference on Learning Representations (ICLR) , year =
Variational Image Compression with a Scale Hyperprior , author =. International Conference on Learning Representations (ICLR) , year =
-
[64]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Joint Autoregressive and Hierarchical Priors for Learned Image Compression , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[65]
Task-Oriented Image Transmission for Scene Classification in Unmanned Aerial Systems , author =. arXiv preprint , year =. 2112.10948 , archiveprefix=
-
[66]
2022 , institution =
work page 2022
-
[67]
Savitha Viswanadh Kandala and Pramuka Medaranga and Ambuj Varshney , year=. 2412.15304 , archivePrefix=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.